require(ggplot2)require(dplyr)require(lubridate) # Pour manipuler les dates plus facilementrequire(zoo) # Pour as.yearmon et as.Daterequire(tidyr) # Pour pivot_longerrequire(patchwork) # Pour arranger les graphiques (optionnel)# Fonction utilitaire MODIFIÉE pour convertir un objet ts en dataframe avec colonne Datets_to_dataframe <-function(ts_obj) {# Utilise zoo pour convertir le temps en objet Date (premier jour du mois/trimestre) time_index <-tryCatch({# Pour mensuel ou trimestriel, as.Date(as.yearmon(...)) fonctionne# frequency() récupère la fréquence de l'objet tsif (frequency(ts_obj) %in%c(4, 12)) {as.Date(as.yearmon(time(ts_obj))) } elseif (frequency(ts_obj) ==1) {as.Date(paste0(floor(time(ts_obj)), "-01-01")) # Annuel: 1er Jan } else {# Si fréquence inconnue ou autre, utiliser index numériqueas.numeric(time(ts_obj)) } }, error =function(e) {# Fallback si conversion échoueas.numeric(time(ts_obj)) }) is_numeric_time <-is.numeric(time_index) df <-data.frame(Time = time_index,Value =as.numeric(ts_obj) ) df <-na.omit(df)attr(df, "is_numeric_time") <- is_numeric_timereturn(df)}# Fonction pour convertir les résultats de decompose en dataframe long (MODIFIÉE pour Date)decompose_to_long_df <-function(decomp_obj, series_name ="Value") {# Utilise zoo pour convertir le temps en objet Date time_index <-tryCatch({if (frequency(decomp_obj$x) %in%c(4, 12)) {as.Date(as.yearmon(time(decomp_obj$x))) } elseif (frequency(decomp_obj$x) ==1) {as.Date(paste0(floor(time(decomp_obj$x)), "-01-01")) } else {as.numeric(time(decomp_obj$x)) } }, error =function(e) {as.numeric(time(decomp_obj$x)) }) is_numeric_time <-is.numeric(time_index) df <-data.frame(Time = time_index,Observed =as.numeric(decomp_obj$x),Trend =as.numeric(decomp_obj$trend),Seasonal =as.numeric(decomp_obj$seasonal),Random =as.numeric(decomp_obj$random) ) %>%pivot_longer(cols =-Time, names_to ="Component", values_to = series_name) %>%mutate(Component =factor(Component, levels =c("Observed", "Trend", "Seasonal", "Random"))) %>%na.omit() # Enlève les NA dus aux calculs de tendance/résidusattr(df, "is_numeric_time") <- is_numeric_timereturn(df)}# Helper function pour choisir l'échelle Xchoose_scale_x <-function(df) {if (is.null(attr(df, "is_numeric_time")) ||!attr(df, "is_numeric_time")) {# Si le temps est Date (ou par défaut si attribut absent) freq <-frequency(df$Time) # Ceci peut échouer si Time n'est pas ts/zoo# Heuristique simple basée sur l'intervalle moyen si freq non dispo interval <-mean(diff(as.numeric(df$Time)), na.rm =TRUE)if(interval >25&& interval <40) freq <-12# Probablement mensuelelseif(interval >80&& interval <100) freq <-4# Probablement trimestrielelse freq <-0# Autreif (freq ==4) { # Trimestrielreturn(scale_x_date(date_labels ="%Y-Q%q", date_breaks ="1 year")) } elseif (freq ==12) { # Mensuelreturn(scale_x_date(date_labels ="%Y-%m", date_breaks ="1 year")) } else { # Annuel ou autrereturn(scale_x_date(date_labels ="%Y", date_breaks ="2 years")) } } else {# Si le temps est numériquereturn(scale_x_continuous()) }}# Adaptation pour scale_x_date qui ne connait pas %q pour trimestre# On utilisera %Y-%m (début du trimestre) ou juste %Yscale_x_date_auto <-function(df, format_q ="%Y-%m", format_m ="%Y-%m", format_a ="%Y", breaks_q ="1 year", breaks_m ="1 year", breaks_a ="2 years") { time_class <-class(df$Time)[1]if (time_class =="Date") {# Estimer la fréquence basé sur les diffs diff_days <-mean(diff(df$Time), na.rm=TRUE)if (diff_days >80&& diff_days <100) { # Trimestrielscale_x_date(date_labels = format_q, date_breaks = breaks_q) } elseif (diff_days >25&& diff_days <35) { # Mensuelscale_x_date(date_labels = format_m, date_breaks = breaks_m) } else { # Annuel ou autrescale_x_date(date_labels = format_a, date_breaks = breaks_a) } } else { # Si numérique ou autrescale_x_continuous() }}
Introduction aux Séries Temporelles
Définition et Exemples
Qu’est-ce qu’une série temporelle (ou chronologique) ?
Une série temporelle (ou série chronologique) est une suite d’observations d’une variable mesurée à différents instants dans le temps. Ces observations sont généralement ordonnées chronologiquement. On note une telle série : \[ y_1, y_2, ..., y_t, ..., y_T \] où \(y_t\) représente la valeur de la variable observée à l’instant \(t\), et \(T\) est le nombre total d’observations (la longueur de la série). L’ensemble des instants d’observation est noté \(\{1, 2, ..., t, ..., T\}\).
Hypothèse d’intervalles de temps équidistants
Dans la plupart des analyses de séries temporelles, on fait l’hypothèse que les observations sont collectées à intervalles de temps réguliers et égaux[cite: 760]. Par exemple, les données peuvent être journalières, hebdomadaires, mensuelles, trimestrielles ou annuelles. Cette régularité simplifie de nombreuses méthodes d’analyse.
Représentation graphique
La première étape de l’analyse d’une série temporelle consiste presque toujours à la visualiser. La représentation graphique la plus courante est un graphique linéaire où l’axe horizontal représente le temps (\(t\)) et l’axe vertical représente les valeurs observées (\(y_t\)). Ce graphique permet d’identifier visuellement les caractéristiques principales de la série, comme la tendance générale, les variations saisonnières ou d’éventuels points atypiques (voir Figures 6.1 à 6.6 dans le document PDF pour des exemples [cite: 1034, 1035, 1036, 1039]).
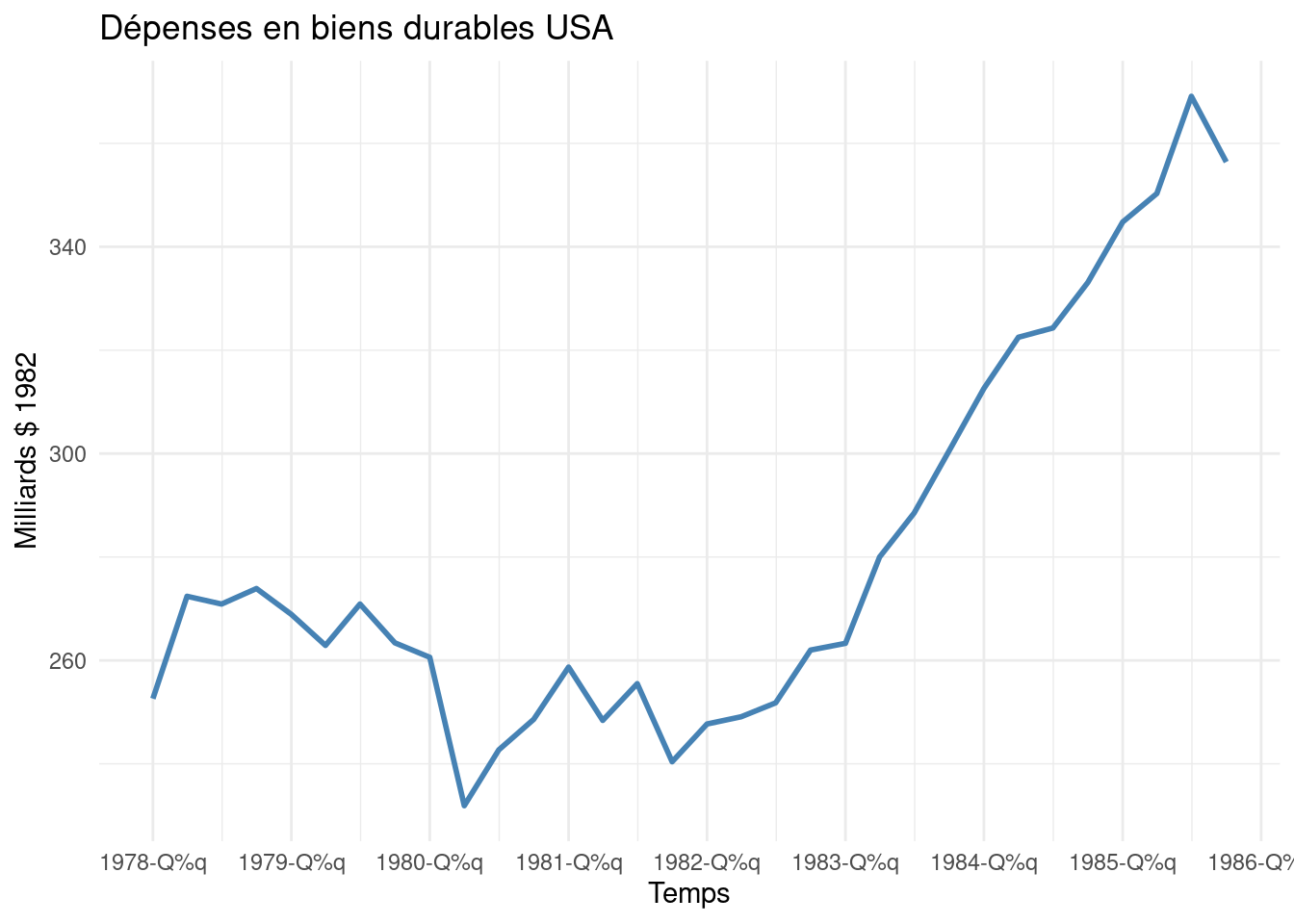
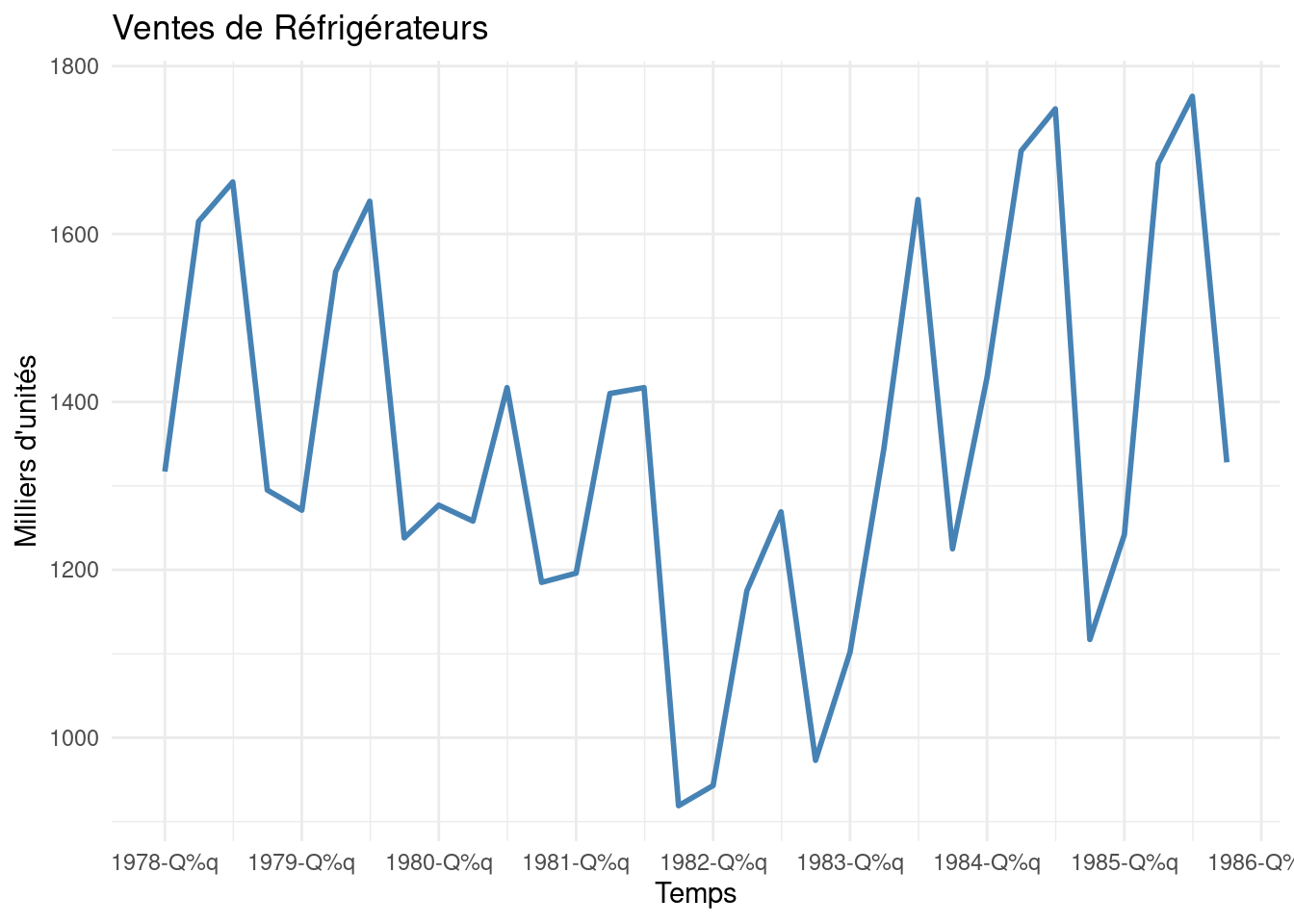
# Assurez-vous que df_DUR et df_FRIG sont créés comme dans les étapes précédentes# et que la colonne 'Time' est de type Date.# Graphique DUR (similaire Figure 6.1)p1 <-ggplot(df_DUR, aes(x = Time, y = Value)) +geom_line(colour ="steelblue", linewidth=1) +# Utiliser linewidth# Utiliser scale_x_date avec un format standardscale_x_date_auto(df_DUR, format_q="%Y-Q%q") +labs(title ="Dépenses en biens durables USA",y ="Milliards $ 1982", x ="Temps") +theme_minimal()# Graphique FRIG (similaire Figure 6.2)p2 <-ggplot(df_FRIG, aes(x = Time, y = Value)) +geom_line(colour ="steelblue", linewidth=1) +# Utiliser linewidth# Utiliser scale_x_date avec un format standardscale_x_date_auto(df_FRIG, format_q="%Y-Q%q") +labs(title ="Ventes de Réfrigérateurs",y ="Milliers d'unités", x ="Temps") +theme_minimal()# Affichage des graphiques côte à côte avec leurs sous-légendesprint(p1)print(p2)
(a) Dépenses en biens durables (similaire Fig 6.1)
(b) Ventes de réfrigérateurs (similaire Fig 6.2)
Figure 1: Séries temporelles des biens manufacturés aux USA (1978-1985)
Example 2
Code
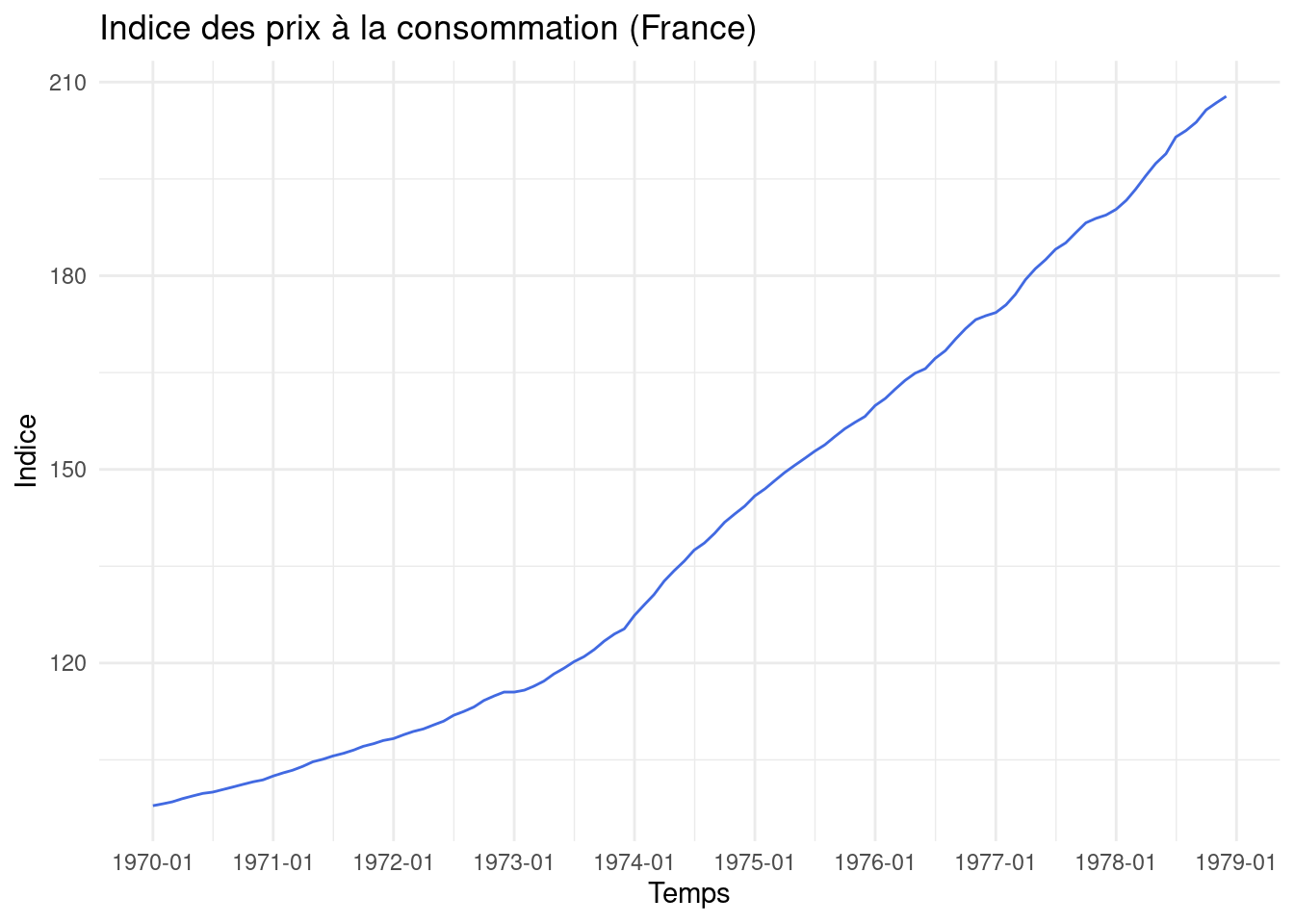
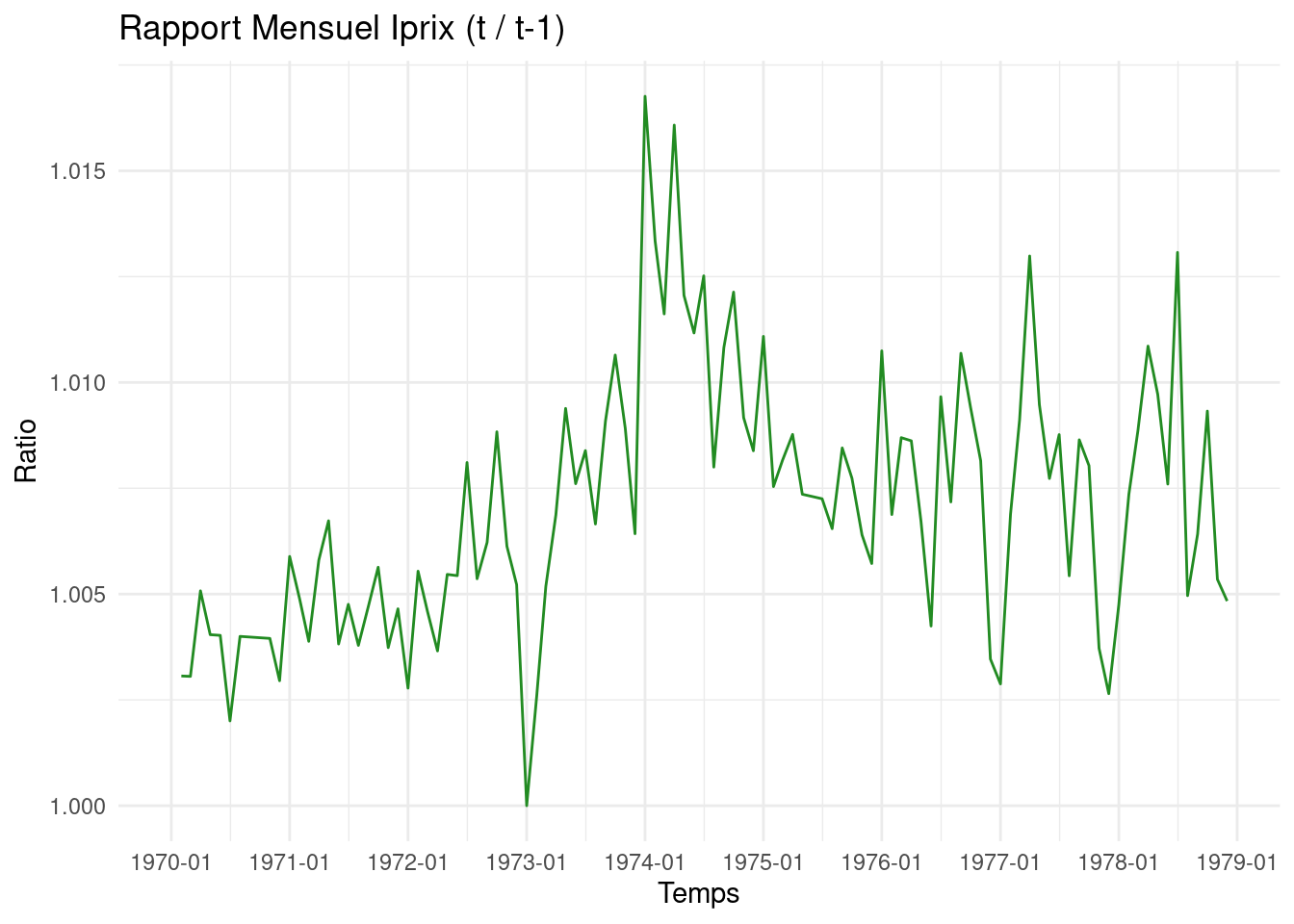
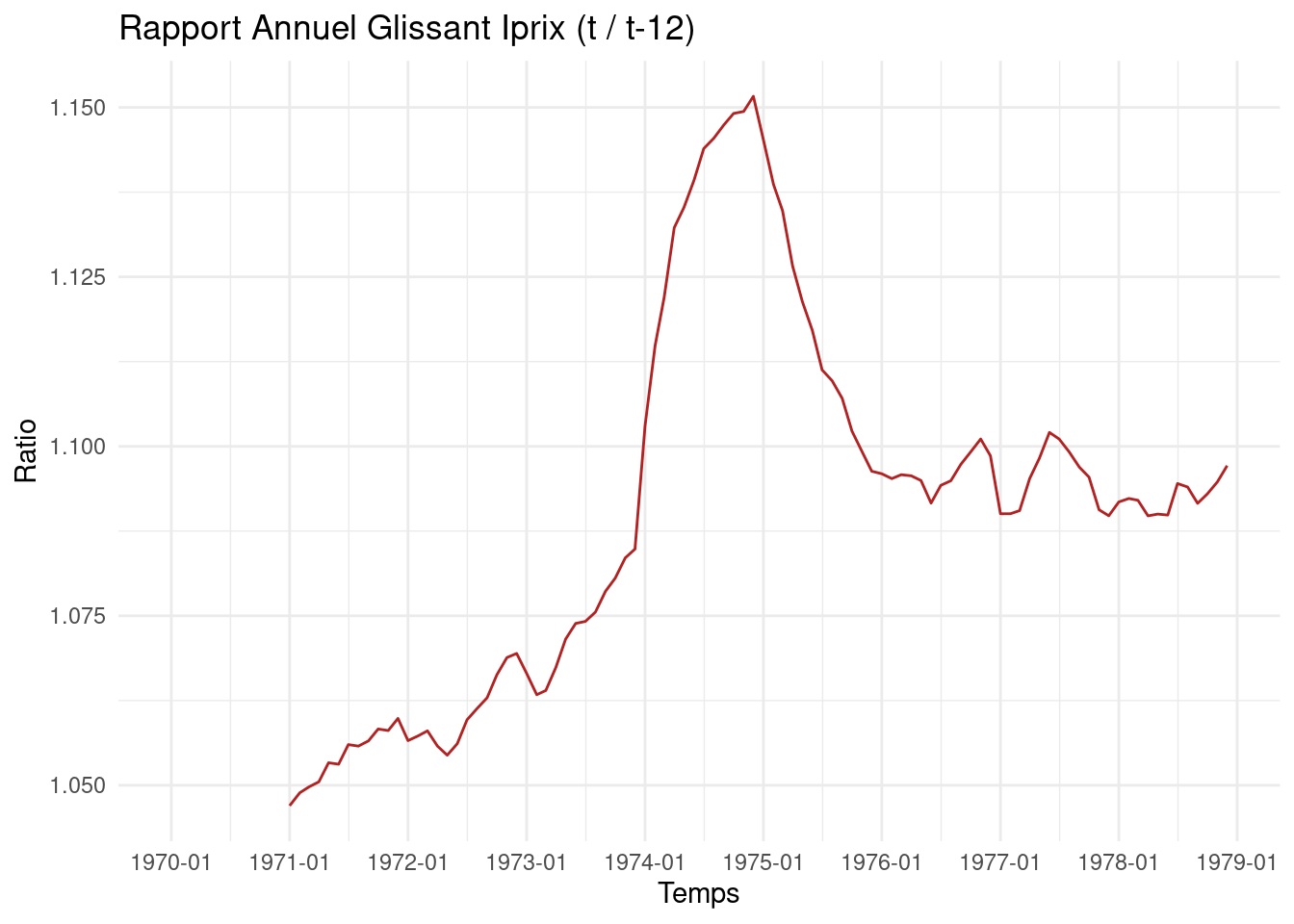
Iprix_data <-c(97.9, 98.2, 98.5, 99, 99.4, 99.8, 100, 100.4, 100.8, 101.2, 101.6, 101.9,102.5, 103, 103.4, 104, 104.7, 105.1, 105.6, 106, 106.5, 107.1, 107.5, 108,108.3, 108.9, 109.4, 109.8, 110.4, 111, 111.9, 112.5, 113.2, 114.2, 114.9, 115.5,115.5, 115.8, 116.4, 117.2, 118.3, 119.2, 120.2, 121, 122.1, 123.4, 124.5, 125.3,127.4, 129.1, 130.6, 132.7, 134.3, 135.8, 137.5, 138.6, 140.1, 141.8, 143.1, 144.3,145.9, 147, 148.2, 149.5, 150.6, 151.7, 152.8, 153.8, 155.1, 156.3, 157.3, 158.2,159.9, 161, 162.4, 163.8, 164.9, 165.6, 167.2, 168.4, 170.2, 171.8, 173.2, 173.8,174.3, 175.5, 177.1, 179.4, 181.1, 182.5, 184.1, 185.1, 186.7, 188.2, 188.9, 189.4,190.3, 191.7, 193.4, 195.5, 197.4, 198.9, 201.5, 202.5, 203.8, 205.7, 206.8, 207.8)# Création d'un objet time series (début Jan 1970)Iprix <-ts(Iprix_data, start =c(1970, 1), frequency =12)# Conversion en dataframe et calcul des ratiosdf_Iprix <-ts_to_dataframe(Iprix) %>%mutate(RatioMensuel = Value /lag(Value, 1),RatioAnnuel = Value /lag(Value, 12) )# Graphique de la série originale (Figure 6.3)p_iprix_orig <-ggplot(df_Iprix, aes(x = Time, y = Value)) +geom_line(colour="royalblue") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Indice des prix à la consommation (France)", y ="Indice", x ="Temps") +theme_minimal()# Graphique du rapport mensuel (Figure 6.4)p_iprix_mens <-ggplot(df_Iprix, aes(x = Time, y = RatioMensuel)) +geom_line(colour="forestgreen") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Rapport Mensuel Iprix (t / t-1)", y ="Ratio", x ="Temps") +theme_minimal()# Graphique du rapport annuel glissant (Figure 6.5)p_iprix_ann <-ggplot(df_Iprix, aes(x = Time, y = RatioAnnuel)) +geom_line(colour="firebrick") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Rapport Annuel Glissant Iprix (t / t-12)", y ="Ratio", x ="Temps") +theme_minimal()# Afficher les graphiques (ils apparaîtront l'un après l'autre par défaut)print(p_iprix_orig)print(p_iprix_mens)print(p_iprix_ann)# Optionnel: utiliser patchwork pour les arranger autrement si besoin# library(patchwork)# p_iprix_orig / p_iprix_mens / p_iprix_ann # Pour les afficher verticalement
(a) Série originale (similaire Fig 6.3)
(b) Rapport mensuel (similaire Fig 6.4)
(c) Rapport annuel glissant (similaire Fig 6.5)
Figure 2: Graphiques de l’indice des prix à la consommation (France)
Économie et Finance : Ventes trimestrielles d’une entreprise, indice des prix à la consommation mensuel, cours quotidien de la bourse, PIB annuel d’un pays, taux de chômage mensuel.
Transport : Nombre de voyageurs-kilomètres mensuels de la SNCF.
Environnement et Météorologie : Température moyenne journalière à Yaoundé, précipitations mensuelles, niveau annuel d’un fleuve.
Santé : Nombre quotidien de cas d’une maladie, admissions hebdomadaires dans un hôpital.
Industrie : Production mensuelle d’électricité, nombre de pannes journalières sur une chaîne de production.
Démographie : Population annuelle d’une ville ou d’un pays.
Objectifs de l’analyse temporelle
L’étude des séries temporelles vise plusieurs objectifs complémentaires, permettant de mieux comprendre et utiliser les informations contenues dans les données évoluant au fil du temps. Les principaux buts sont :
Description : Il s’agit de la première étape fondamentale. Elle consiste à visualiser la série (par un graphique temporel) et à identifier ses caractéristiques principales : existe-t-il une tendance générale à la hausse ou à la baisse ? Observe-t-on des fluctuations répétitives à intervalles réguliers (saisonnalité) ? Y a-t-il des points particulièrement inhabituels (valeurs aberrantes) ou des ruptures dans le comportement de la série ?
Isolation de composantes : Comme vu précédemment, une série temporelle peut être vue comme la résultante de plusieurs composantes sous-jacentes (tendance \(T_t\), saisonnalité \(S_t\), résidu \(E_t\)). Un objectif majeur est d’isoler et d’estimer chacune de ces composantes. Cela permet, par exemple, de quantifier la croissance moyenne à long terme (tendance) ou l’ampleur des variations saisonnières.
Désaisonnalisation : Liée à l’objectif précédent, la désaisonnalisation consiste spécifiquement à supprimer la composante saisonnière \(S_t\) de la série originale. On obtient ainsi une série dite “Corrigée des Variations Saisonnières” (CVS). Cette série CVS est utile pour analyser les évolutions conjoncturelles (la tendance-cycle) sans être “brouillé” par les effets saisonniers, ou pour comparer des périodes différentes de l’année de manière plus pertinente (par exemple, comparer les ventes de décembre à celles de janvier après désaisonnalisation).
Prévision : C’est l’un des objectifs les plus appliqués de l’analyse des séries temporelles. Il s’agit d’utiliser les informations contenues dans les observations passées (\(y_1, ..., y_T\)) pour prédire les valeurs futures (\(y_{T+1}, y_{T+2}, ...\)) de la série. Les prévisions sont cruciales dans de nombreux domaines comme l’économie (prévision de croissance, d’inflation), la gestion (prévision des ventes, des stocks) ou la météorologie. L’analyse peut aussi viser à estimer des valeurs passées ou manquantes.
D’autres objectifs peuvent également être poursuivis, comme la construction de modèles explicatifs reliant l’évolution d’une série à celle d’autres variables (modèles de causalité) ou la détermination de la durée et de l’amplitude des cycles économiques ou autres[cite: 767, 768]. Cependant, dans le cadre descriptif, les quatre points ci-dessus sont généralement considérés comme essentiels.
Composantes d’une Série Temporelle
Pour analyser une série temporelle \(y_t\), il est utile de la décomposer en plusieurs éléments sous-jacents qui expliquent son comportement. Classiquement, on distingue quatre composantes principales:
Tendance (\(T_t\)) : C’est l’évolution fondamentale de la série sur le long terme. Elle représente la direction générale des données : croissance, décroissance ou stabilité relative. On parle parfois de tendance séculaire. Par exemple, la tendance peut montrer l’augmentation progressive de la population d’un pays sur plusieurs décennies ou la diminution de la part d’un secteur dans l’économie.
Composante Saisonnière (\(S_t\)) : Elle représente les fluctuations périodiques qui se répètent à intervalles fixes et réguliers, généralement au cours d’une année (mais la période peut aussi être le trimestre, le mois, la semaine, voire le jour). Ces variations sont souvent liées au calendrier ou aux saisons climatiques.
Exemples : Les ventes de jouets qui augmentent fortement avant Noël chaque année, la consommation d’électricité plus élevée en saison froide à Yaoundé, le trafic aérien plus important pendant les vacances scolaires, ou le nombre d’appels dans un centre d’assistance variant selon le jour de la semaine.
Composante Cyclique (\(C_t\)) : Il s’agit de fluctuations autour de la tendance sur des périodes plus longues que la saisonnalité (généralement plusieurs années). Ces cycles sont souvent liés aux cycles économiques généraux (phases d’expansion, de récession). Contrairement à la saisonnalité, les cycles n’ont pas une périodicité fixe et leur amplitude peut varier, ce qui les rend plus difficiles à modéliser (elle ne sera pas étudiée en détail)
Composante Résiduelle/Irrégulière (\(E_t\)) : Aussi appelée “bruit” ou “aléa”, cette composante représente tout ce qui reste dans la série une fois que la tendance, la saisonnalité et le cycle ont été pris en compte. Elle capture les variations aléatoires, les événements imprévisibles (grève, catastrophe naturelle, crise soudaine), les erreurs de mesure ou toute autre fluctuation non systématique. On la suppose souvent comme une composante aléatoire centrée autour de zéro (modèle additif) ou de un (modèle multiplicatif).
Ces composantes ne sont généralement pas observées directement mais sont estimées à partir des données \(y_t\). Elles interagissent pour former la série observée, le plus souvent selon un schéma additif ou multiplicatif, comme nous le verrons dans la section suivante.
Ex: \(MM(12)\) (MM d’ordre 12 suivie d’une MM d’ordre 2)
Moyennes/Médianes Mobiles Particulières (mention)
Van Hann, Spencer, Henderson (propriétés spécifiques)
Médiane mobile (robustesse aux valeurs extrêmes)
Désaisonnalisation
Objectif : Obtenir une série Corrigée des Variations Saisonnières (CVS)
Estimation de la composante saisonnière (\(S_m\))
Basée sur l’écart (additif) ou le ratio (multiplicatif) à la tendance estimée (par MM).
Méthode Additive
Calcul des écarts bruts \(d_{am} = Y_{am} - T_{am}\)
Estimation des coefficients saisonniers \(S_m = \text{moyenne}(d_{am})\) pour chaque saison \(m\)
Ajustement additif : \(S'_m = S_m - \bar{S}\) pour que \(\sum S'_m = 0\)
Série CVS : \(Y^e_{am} = Y_{am} - S'_m\)
Méthode Multiplicative
Calcul des ratios bruts \(r_{am} = Y_{am} / T_{am}\)
Estimation des coefficients saisonniers \(S_m = \text{moyenne}(r_{am})\) pour chaque saison \(m\)
Ajustement multiplicatif : \(S'_m = S_m / \bar{S}\) pour que \(\frac{1}{M}\sum S'_m = 1\)
Série CVS : \(Y^e_{am} = Y_{am} / S'_m\)
Exemple de décomposition (graphique)
Lissage Exponentiel (Introduction à la prévision)
Principe : Pondération exponentiellement décroissante des observations passées.
Lissage Exponentiel Simple (LES)
Adapté aux séries sans tendance (stationnaires en moyenne).
Formule récursive : \(\hat{X}_t(1) = (1-\beta)X_t + \beta \hat{X}_{t-1}(1)\)
Prévision : \(\hat{X}_T(k) = \hat{X}_T(1)\) pour \(k \ge 1\).
Lissage Exponentiel Double (LED) de Holt
Adapté aux séries avec tendance linéaire.
Système de lissage pour le niveau (\(S^1_t\)) et la tendance (\(b_t\)).
Prévision : \(\hat{X}_T(k) = a_T + b_T k\)
Calcul de \(a_T\) et \(b_T\) via LES simple et double (\(S^1_T, S^2_T\))
Exercices
Exercise 1 (Identification des Composantes et Modèles) Le tableau suivant présente les ventes trimestrielles (en milliers d’euros) d’une entreprise sur 3 ans :
Année
Trimestre 1
Trimestre 2
Trimestre 3
Trimestre 4
1
150
175
210
160
2
165
190
230
175
3
180
205
250
190
Représentez graphiquement cette série temporelle.
Identifiez visuellement la présence éventuelle d’une tendance et d’une composante saisonnière.
Quel type de modèle (additif ou multiplicatif) vous semble le plus approprié pour cette série ? Justifiez votre réponse.
Exercise 2 (Opérateurs de Différence) Considérez la série temporelle \(y_t\) suivante : 5, 8, 12, 17, 23, 30, 38, 47.
Calculez la série des différences d’ordre 1 : \(\nabla y_t = y_t - y_{t-1}\). Que remarquez-vous ? Quelle type de tendance cet opérateur permet-il d’éliminer?
Calculez la série des différences d’ordre 2 : \(\nabla^2 y_t = \nabla(\nabla y_t)\). Qu’observez-vous ? Quelle type de tendance cet opérateur permet-il d’éliminer?
Exercise 3 (Moyennes Mobiles) Reprenons les données de l’Exercice 1 (ventes trimestrielles).
Calculez la moyenne mobile centrée d’ordre 4 (adaptée aux données trimestrielles) pour lisser la série. Rappel : \(MM(4)_t = \frac{1}{8}(y_{t-2} + 2y_{t-1} + 2y_t + 2y_{t+1} + y_{t+2})\).
Représentez graphiquement la série originale et la série lissée par la moyenne mobile. Que constatez-vous concernant la composante saisonnière ?
Exercise 4 (Désaisonnalisation) Utilisez les données de l’Exercice 1 et la moyenne mobile calculée dans l’Exercice 3 (qui estime la tendance \(T_{am}\)).
Calculez les coefficients saisonniers bruts \(S_m\) en utilisant la méthode additive (\(S_m = \frac{1}{A-1}\sum_a (Y_{am} - T_{am})\)).
Ajustez ces coefficients pour que leur somme soit nulle (\(S'_m = S_m - \frac{1}{M}\sum_m S_m\)).
Calculez la série désaisonnalisée (CVS) additive : \(Y^e_{am} = Y_{am} - S'_m\).
Recommencez les étapes 1 à 3 en utilisant la méthode multiplicative (Coefficients bruts : \(S_m = \frac{1}{A-1}\sum_a \frac{Y_{am}}{T_{am}}\), Ajustement : \(S'_m = S_m / (\frac{1}{M}\sum_m S_m)\), Série CVS : \(Y^e_{am} = Y_{am} / S'_m\)).
Comparez les séries désaisonnalisées obtenues par les deux méthodes.
Exercise 5 (Lissage Exponentiel Simple) Voici le nombre mensuel de visiteurs d’un site web pendant 10 mois : 1200, 1250, 1180, 1230, 1260, 1210, 1240, 1270, 1190, 1220.
Appliquez un lissage exponentiel simple (LES) à cette série avec un coefficient de lissage \(\beta = 0.3\). Utilisez la formule récursive : \(\hat{X}_t(1) = (1-\beta)X_t + \beta \hat{X}_{t-1}(1)\), en initialisant \(\hat{X}_0(1) = X_1\).
Quelle est la prévision pour le 11ème mois, \(\hat{X}_{10}(1)\) ?
Pourquoi le LES est-il adapté à une série sans tendance marquée?
Exercise 6 (Lissage Exponentiel Double) Considérez la série suivante qui présente une tendance linéaire : 50, 55, 58, 62, 65, 70, 72, 78.
Appliquez un lissage exponentiel simple (LES) \(S^1_t\) avec \(\beta = 0.4\).
Appliquez un second lissage exponentiel simple \(S^2_t\) à la série \(S^1_t\) obtenue, avec le même \(\beta = 0.4\).
Calculez les estimateurs de la tendance \(a_t = 2S^1_t - S^2_t\) et \(b_t = \frac{1-\beta}{\beta}(S^1_t - S^2_t)\) pour la dernière période (t=8).
Faites une prévision pour les deux prochaines périodes (t=9 et t=10) en utilisant la formule \(\hat{X}_T(k) = a_T + b_T k\).
Exercise 7 (Comparaison de Moyennes Mobiles) Soit la série temporelle mensuelle suivante : 15, 18, 14, 20, 22, 18, 15, 19, 21, 17, 23, 25.
Calculez une moyenne mobile simple (non-pondérée) d’ordre 3.
Calculez la moyenne mobile de Van Hann \(MMVH = \frac{1}{4}(L + 2I + F)\).
Représentez graphiquement la série originale et les deux séries lissées. Comparez l’effet des deux moyennes mobiles. Laquelle semble produire un lissage plus “doux” ?
Exercise 8 (Modélisation de Tendance Non-Linéaire) Le nombre de plaintes reçues par un service client sur 8 trimestres est : 10, 12, 15, 14, 16, 19, 24, 30.
Représentez graphiquement la série. Une tendance linéaire simple vous semble-t-elle appropriée ?
Ajustez une tendance quadratique \(T_t = a + bt + ct^2\) par la méthode des moindres carrés (considérez t=1 pour le premier trimestre).
Interprétez les signes des coefficients \(b\) et \(c\).
Quelle est la valeur de la tendance estimée pour le 9ème trimestre ?
Exercise 9 (Différenciation pour Stationnarisation) Considérez la série du trafic voyageurs SNCF présentée dans l’exemple 6.4 du document. Le graphique 6.11 montre une tendance croissante et une saisonnalité.
Appliquez d’abord une différence saisonnière d’ordre 12 : \(z_t = \nabla_{12} y_t = y_t - y_{t-12}\). Représentez graphiquement \(z_t\). La saisonnalité a-t-elle disparu ? Reste-t-il une tendance ?
Appliquez ensuite une différence d’ordre 1 à la série \(z_t\) : \(w_t = \nabla z_t = z_t - z_{t-1}\). Représentez graphiquement \(w_t\). La série \(w_t\) semble-t-elle stationnaire (sans tendance ni saisonnalité claire) ?
Exprimez \(w_t\) directement en fonction de \(y_t\) en utilisant les opérateurs \(L\).
Exercise 10 (Effet d’un Filtre Linéaire) Considérez le filtre linéaire \(\mathcal{F} = 0.25 L + 0.5 I + 0.25 F\).
Appliquez ce filtre à une série représentant une tendance linéaire parfaite : \(y_t = a + bt\). Montrez que le filtre conserve la tendance linéaire (c’est-à-dire que \(\mathcal{F}y_t = a' + b't\), trouvez \(a'\) et \(b'\)).
Appliquez ce filtre à une série représentant une tendance quadratique parfaite : \(y_t = a + bt + ct^2\). Le filtre conserve-t-il la tendance quadratique ? (Calculez \(\mathcal{F}y_t\)).
Exercise 11 (Choix de la Méthode de Lissage Exponentiel) Examinez les deux séries temporelles suivantes :
Série A : 105, 103, 106, 104, 107, 105, 108, 106 (fluctuations autour d’un niveau stable)
Série B : 20, 24, 27, 31, 35, 38, 42, 45 (tendance croissante)
Pour quelle série le lissage exponentiel simple (LES) serait-il le plus approprié pour faire une prévision à court terme ? Pourquoi ?
Pour quelle série le lissage exponentiel double (LED) serait-il préférable ? Pourquoi ?
Quel type de prévision (constante ou avec tendance) obtiendrait-on en appliquant le LED à la Série A ?
Exercise 12 (Interprétation de la Désaisonnalisation Multiplicative) Reprenons les résultats de la désaisonnalisation multiplicative de la série des ventes de réfrigérateurs (Exemple 6.9, Tableaux 6.6 et 6.7 du document PDF). Les coefficients saisonniers ajustés \(S'_m\) sont approximativement : \(S'_1 \approx 0.91\) (Trim 1), \(S'_2 \approx 1.08\) (Trim 2), \(S'_3 \approx 1.16\) (Trim 3), \(S'_4 \approx 0.85\) (Trim 4).
Interprétez la valeur de \(S'_3 \approx 1.16\). Que signifie-t-elle par rapport à la tendance ?
Interprétez la valeur de \(S'_1 \approx 0.91\).
Comment utiliseriez-vous ces coefficients pour “resaisonnaliser” une prévision de la tendance pour le 2ème trimestre de l’année suivante ?
Vérifiez que la moyenne de ces coefficients est bien égale à 1 (ou très proche, aux erreurs d’arrondi près).
Source Code
---title: "Séries Chronologiques"execute: warning: false message: false---```{r}#| label: setuprequire(ggplot2)require(dplyr)require(lubridate) # Pour manipuler les dates plus facilementrequire(zoo) # Pour as.yearmon et as.Daterequire(tidyr) # Pour pivot_longerrequire(patchwork) # Pour arranger les graphiques (optionnel)# Fonction utilitaire MODIFIÉE pour convertir un objet ts en dataframe avec colonne Datets_to_dataframe <-function(ts_obj) {# Utilise zoo pour convertir le temps en objet Date (premier jour du mois/trimestre) time_index <-tryCatch({# Pour mensuel ou trimestriel, as.Date(as.yearmon(...)) fonctionne# frequency() récupère la fréquence de l'objet tsif (frequency(ts_obj) %in%c(4, 12)) {as.Date(as.yearmon(time(ts_obj))) } elseif (frequency(ts_obj) ==1) {as.Date(paste0(floor(time(ts_obj)), "-01-01")) # Annuel: 1er Jan } else {# Si fréquence inconnue ou autre, utiliser index numériqueas.numeric(time(ts_obj)) } }, error =function(e) {# Fallback si conversion échoueas.numeric(time(ts_obj)) }) is_numeric_time <-is.numeric(time_index) df <-data.frame(Time = time_index,Value =as.numeric(ts_obj) ) df <-na.omit(df)attr(df, "is_numeric_time") <- is_numeric_timereturn(df)}# Fonction pour convertir les résultats de decompose en dataframe long (MODIFIÉE pour Date)decompose_to_long_df <-function(decomp_obj, series_name ="Value") {# Utilise zoo pour convertir le temps en objet Date time_index <-tryCatch({if (frequency(decomp_obj$x) %in%c(4, 12)) {as.Date(as.yearmon(time(decomp_obj$x))) } elseif (frequency(decomp_obj$x) ==1) {as.Date(paste0(floor(time(decomp_obj$x)), "-01-01")) } else {as.numeric(time(decomp_obj$x)) } }, error =function(e) {as.numeric(time(decomp_obj$x)) }) is_numeric_time <-is.numeric(time_index) df <-data.frame(Time = time_index,Observed =as.numeric(decomp_obj$x),Trend =as.numeric(decomp_obj$trend),Seasonal =as.numeric(decomp_obj$seasonal),Random =as.numeric(decomp_obj$random) ) %>%pivot_longer(cols =-Time, names_to ="Component", values_to = series_name) %>%mutate(Component =factor(Component, levels =c("Observed", "Trend", "Seasonal", "Random"))) %>%na.omit() # Enlève les NA dus aux calculs de tendance/résidusattr(df, "is_numeric_time") <- is_numeric_timereturn(df)}# Helper function pour choisir l'échelle Xchoose_scale_x <-function(df) {if (is.null(attr(df, "is_numeric_time")) ||!attr(df, "is_numeric_time")) {# Si le temps est Date (ou par défaut si attribut absent) freq <-frequency(df$Time) # Ceci peut échouer si Time n'est pas ts/zoo# Heuristique simple basée sur l'intervalle moyen si freq non dispo interval <-mean(diff(as.numeric(df$Time)), na.rm =TRUE)if(interval >25&& interval <40) freq <-12# Probablement mensuelelseif(interval >80&& interval <100) freq <-4# Probablement trimestrielelse freq <-0# Autreif (freq ==4) { # Trimestrielreturn(scale_x_date(date_labels ="%Y-Q%q", date_breaks ="1 year")) } elseif (freq ==12) { # Mensuelreturn(scale_x_date(date_labels ="%Y-%m", date_breaks ="1 year")) } else { # Annuel ou autrereturn(scale_x_date(date_labels ="%Y", date_breaks ="2 years")) } } else {# Si le temps est numériquereturn(scale_x_continuous()) }}# Adaptation pour scale_x_date qui ne connait pas %q pour trimestre# On utilisera %Y-%m (début du trimestre) ou juste %Yscale_x_date_auto <-function(df, format_q ="%Y-%m", format_m ="%Y-%m", format_a ="%Y", breaks_q ="1 year", breaks_m ="1 year", breaks_a ="2 years") { time_class <-class(df$Time)[1]if (time_class =="Date") {# Estimer la fréquence basé sur les diffs diff_days <-mean(diff(df$Time), na.rm=TRUE)if (diff_days >80&& diff_days <100) { # Trimestrielscale_x_date(date_labels = format_q, date_breaks = breaks_q) } elseif (diff_days >25&& diff_days <35) { # Mensuelscale_x_date(date_labels = format_m, date_breaks = breaks_m) } else { # Annuel ou autrescale_x_date(date_labels = format_a, date_breaks = breaks_a) } } else { # Si numérique ou autrescale_x_continuous() }}```## Introduction aux Séries Temporelles### Définition et Exemples* **Qu'est-ce qu'une série temporelle (ou chronologique) ?** Une série temporelle (ou série chronologique) est une suite d'observations d'une variable mesurée à différents instants dans le temps. Ces observations sont généralement ordonnées chronologiquement. On note une telle série : $$ y_1, y_2, ..., y_t, ..., y_T $$ où $y_t$ représente la valeur de la variable observée à l'instant $t$, et $T$ est le nombre total d'observations (la longueur de la série). L'ensemble des instants d'observation est noté $\{1, 2, ..., t, ..., T\}$.* **Hypothèse d'intervalles de temps équidistants** Dans la plupart des analyses de séries temporelles, on fait l'hypothèse que les observations sont collectées à intervalles de temps réguliers et égaux[cite: 760]. Par exemple, les données peuvent être journalières, hebdomadaires, mensuelles, trimestrielles ou annuelles. Cette régularité simplifie de nombreuses méthodes d'analyse.* **Représentation graphique** La première étape de l'analyse d'une série temporelle consiste presque toujours à la visualiser. La représentation graphique la plus courante est un graphique linéaire où l'axe horizontal représente le temps ($t$) et l'axe vertical représente les valeurs observées ($y_t$). Ce graphique permet d'identifier visuellement les caractéristiques principales de la série, comme la tendance générale, les variations saisonnières ou d'éventuels points atypiques (voir Figures 6.1 à 6.6 dans le document PDF pour des exemples [cite: 1034, 1035, 1036, 1039]).* **Exemples concrets**:::{#exm-}## Biens Manufactirés aux USA```{r}# Définition des données (identique à avant)QTR <-1:32DISH <-c(841, 957, 999, 960, 894, 851, 863, 878, 792, 589, 657, 699, 675, 652, 628,529, 480, 530, 557, 602, 658, 749, 827, 858, 808, 840, 893, 950, 838, 884, 905, 909)DISP <-c(798, 837, 821, 858, 837, 838, 832, 818, 868, 623, 662, 822, 871, 791, 759, 734, 706,582, 659, 837, 867, 860, 918, 1017, 1063, 955, 973, 1096, 1086, 990, 1028, 1003)FRIG <-c(1317, 1615, 1662, 1295, 1271, 1555, 1639, 1238, 1277, 1258, 1417, 1185, 1196,1410, 1417, 919, 943, 1175, 1269, 973, 1102, 1344, 1641, 1225, 1429, 1699, 1749, 1117,1242, 1684, 1764, 1328)WASH <-c(1271, 1295, 1313, 1150, 1289, 1245, 1270, 1103, 1273, 1031, 1143, 1101, 1181,1116, 1190, 1125, 1036, 1019, 1047, 918, 1137, 1167, 1230, 1081, 1326, 1228, 1297,1198, 1292, 1342, 1323, 1274)DUR <-c(252.6, 272.4, 270.9, 273.9, 268.9, 262.9, 270.9, 263.4, 260.6, 231.9, 242.7, 248.6,258.7, 248.4, 255.5, 240.4, 247.7, 249.1, 251.8, 262, 263.3, 280, 288.5, 300.5,312.6, 322.5, 324.3, 333.1, 344.8, 350.3, 369.1, 356.4)RES <-c(172.9, 179.8, 180.8, 178.6, 174.6, 172.4, 170.6, 165.7, 154.9, 124.1, 126.8,142.2, 139.3, 134.1, 122.3, 110.4, 101.2, 103.4, 100.1, 115.8, 127.8, 147.4, 161.9,159.9, 170.5, 173.1, 170.3, 169.6, 170.3, 172.9, 175, 179.4)# Création d'objets time seriesDUR_ts <-ts(DUR, start =c(1978, 1), frequency =4)FRIG_ts <-ts(FRIG, start =c(1978, 1), frequency =4)# Conversion en dataframesdf_DUR <-ts_to_dataframe(DUR_ts)df_FRIG <-ts_to_dataframe(FRIG_ts)``````{r}#| label: fig-biens-manufactures#| fig-cap: "Séries temporelles des biens manufacturés aux USA (1978-1985)"#| layout-ncol: 2#| fig-subcap: #| - "Dépenses en biens durables (similaire Fig 6.1)"#| - "Ventes de réfrigérateurs (similaire Fig 6.2)"# Assurez-vous que df_DUR et df_FRIG sont créés comme dans les étapes précédentes# et que la colonne 'Time' est de type Date.# Graphique DUR (similaire Figure 6.1)p1 <-ggplot(df_DUR, aes(x = Time, y = Value)) +geom_line(colour ="steelblue", linewidth=1) +# Utiliser linewidth# Utiliser scale_x_date avec un format standardscale_x_date_auto(df_DUR, format_q="%Y-Q%q") +labs(title ="Dépenses en biens durables USA",y ="Milliards $ 1982", x ="Temps") +theme_minimal()# Graphique FRIG (similaire Figure 6.2)p2 <-ggplot(df_FRIG, aes(x = Time, y = Value)) +geom_line(colour ="steelblue", linewidth=1) +# Utiliser linewidth# Utiliser scale_x_date avec un format standardscale_x_date_auto(df_FRIG, format_q="%Y-Q%q") +labs(title ="Ventes de Réfrigérateurs",y ="Milliers d'unités", x ="Temps") +theme_minimal()# Affichage des graphiques côte à côte avec leurs sous-légendesprint(p1)print(p2)```::::::{#exm-}```{r indice_prix_plots_corrected}#| label: fig-indice-prix#| fig-cap: "Graphiques de l'indice des prix à la consommation (France)"#| layout-ncol: 1 #| fig-subcap:#| - "Série originale (similaire Fig 6.3)"#| - "Rapport mensuel (similaire Fig 6.4)"#| - "Rapport annuel glissant (similaire Fig 6.5)"Iprix_data <-c(97.9, 98.2, 98.5, 99, 99.4, 99.8, 100, 100.4, 100.8, 101.2, 101.6, 101.9,102.5, 103, 103.4, 104, 104.7, 105.1, 105.6, 106, 106.5, 107.1, 107.5, 108,108.3, 108.9, 109.4, 109.8, 110.4, 111, 111.9, 112.5, 113.2, 114.2, 114.9, 115.5,115.5, 115.8, 116.4, 117.2, 118.3, 119.2, 120.2, 121, 122.1, 123.4, 124.5, 125.3,127.4, 129.1, 130.6, 132.7, 134.3, 135.8, 137.5, 138.6, 140.1, 141.8, 143.1, 144.3,145.9, 147, 148.2, 149.5, 150.6, 151.7, 152.8, 153.8, 155.1, 156.3, 157.3, 158.2,159.9, 161, 162.4, 163.8, 164.9, 165.6, 167.2, 168.4, 170.2, 171.8, 173.2, 173.8,174.3, 175.5, 177.1, 179.4, 181.1, 182.5, 184.1, 185.1, 186.7, 188.2, 188.9, 189.4,190.3, 191.7, 193.4, 195.5, 197.4, 198.9, 201.5, 202.5, 203.8, 205.7, 206.8, 207.8)# Création d'un objet time series (début Jan 1970)Iprix <-ts(Iprix_data, start =c(1970, 1), frequency =12)# Conversion en dataframe et calcul des ratiosdf_Iprix <-ts_to_dataframe(Iprix) %>%mutate(RatioMensuel = Value /lag(Value, 1),RatioAnnuel = Value /lag(Value, 12) )# Graphique de la série originale (Figure 6.3)p_iprix_orig <-ggplot(df_Iprix, aes(x = Time, y = Value)) +geom_line(colour="royalblue") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Indice des prix à la consommation (France)", y ="Indice", x ="Temps") +theme_minimal()# Graphique du rapport mensuel (Figure 6.4)p_iprix_mens <-ggplot(df_Iprix, aes(x = Time, y = RatioMensuel)) +geom_line(colour="forestgreen") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Rapport Mensuel Iprix (t / t-1)", y ="Ratio", x ="Temps") +theme_minimal()# Graphique du rapport annuel glissant (Figure 6.5)p_iprix_ann <-ggplot(df_Iprix, aes(x = Time, y = RatioAnnuel)) +geom_line(colour="firebrick") +# Utilisation directe de scale_x_datescale_x_date_auto(df_Iprix, format_q="%Y-Q%q") +labs(title ="Rapport Annuel Glissant Iprix (t / t-12)", y ="Ratio", x ="Temps") +theme_minimal()# Afficher les graphiques (ils apparaîtront l'un après l'autre par défaut)print(p_iprix_orig)print(p_iprix_mens)print(p_iprix_ann)# Optionnel: utiliser patchwork pour les arranger autrement si besoin# library(patchwork)# p_iprix_orig / p_iprix_mens / p_iprix_ann # Pour les afficher verticalement```:::* **Économie et Finance :** Ventes trimestrielles d'une entreprise, indice des prix à la consommation mensuel, cours quotidien de la bourse, PIB annuel d'un pays, taux de chômage mensuel.* **Transport :** Nombre de voyageurs-kilomètres mensuels de la SNCF.* **Environnement et Météorologie :** Température moyenne journalière à Yaoundé, précipitations mensuelles, niveau annuel d'un fleuve.* **Santé :** Nombre quotidien de cas d'une maladie, admissions hebdomadaires dans un hôpital.* **Industrie :** Production mensuelle d'électricité, nombre de pannes journalières sur une chaîne de production.* **Démographie :** Population annuelle d'une ville ou d'un pays.### Objectifs de l'analyse temporelleL'étude des séries temporelles vise plusieurs objectifs complémentaires, permettant de mieux comprendre et utiliser les informations contenues dans les données évoluant au fil du temps. Les principaux buts sont :* **Description :** Il s'agit de la première étape fondamentale. Elle consiste à visualiser la série (par un graphique temporel) et à identifier ses caractéristiques principales : existe-t-il une tendance générale à la hausse ou à la baisse ? Observe-t-on des fluctuations répétitives à intervalles réguliers (saisonnalité) ? Y a-t-il des points particulièrement inhabituels (valeurs aberrantes) ou des ruptures dans le comportement de la série ?* **Isolation de composantes :** Comme vu précédemment, une série temporelle peut être vue comme la résultante de plusieurs composantes sous-jacentes (tendance $T_t$, saisonnalité $S_t$, résidu $E_t$). Un objectif majeur est d'isoler et d'estimer chacune de ces composantes. Cela permet, par exemple, de quantifier la croissance moyenne à long terme (tendance) ou l'ampleur des variations saisonnières.* **Désaisonnalisation :** Liée à l'objectif précédent, la désaisonnalisation consiste spécifiquement à **supprimer** la composante saisonnière $S_t$ de la série originale. On obtient ainsi une série dite "Corrigée des Variations Saisonnières" (CVS). Cette série CVS est utile pour analyser les évolutions conjoncturelles (la tendance-cycle) sans être "brouillé" par les effets saisonniers, ou pour comparer des périodes différentes de l'année de manière plus pertinente (par exemple, comparer les ventes de décembre à celles de janvier après désaisonnalisation).* **Prévision :** C'est l'un des objectifs les plus appliqués de l'analyse des séries temporelles. Il s'agit d'utiliser les informations contenues dans les observations passées ($y_1, ..., y_T$) pour prédire les valeurs futures ($y_{T+1}, y_{T+2}, ...$) de la série. Les prévisions sont cruciales dans de nombreux domaines comme l'économie (prévision de croissance, d'inflation), la gestion (prévision des ventes, des stocks) ou la météorologie. L'analyse peut aussi viser à estimer des valeurs passées ou manquantes.D'autres objectifs peuvent également être poursuivis, comme la construction de modèles explicatifs reliant l'évolution d'une série à celle d'autres variables (modèles de causalité) ou la détermination de la durée et de l'amplitude des cycles économiques ou autres[cite: 767, 768]. Cependant, dans le cadre descriptif, les quatre points ci-dessus sont généralement considérés comme essentiels.### Composantes d'une Série TemporellePour analyser une série temporelle $y_t$, il est utile de la décomposer en plusieurs éléments sous-jacents qui expliquent son comportement. Classiquement, on distingue quatre composantes principales:* **Tendance ($T_t$) :** C'est l'évolution fondamentale de la série sur le long terme. Elle représente la direction générale des données : croissance, décroissance ou stabilité relative. On parle parfois de tendance séculaire. Par exemple, la tendance peut montrer l'augmentation progressive de la population d'un pays sur plusieurs décennies ou la diminution de la part d'un secteur dans l'économie.* **Composante Saisonnière ($S_t$) :** Elle représente les fluctuations périodiques qui se répètent à intervalles fixes et réguliers, généralement au cours d'une année (mais la période peut aussi être le trimestre, le mois, la semaine, voire le jour). Ces variations sont souvent liées au calendrier ou aux saisons climatiques. * *Exemples :* Les ventes de jouets qui augmentent fortement avant Noël chaque année, la consommation d'électricité plus élevée en saison froide à Yaoundé, le trafic aérien plus important pendant les vacances scolaires, ou le nombre d'appels dans un centre d'assistance variant selon le jour de la semaine.* **Composante Cyclique ($C_t$) :** Il s'agit de fluctuations autour de la tendance sur des périodes plus longues que la saisonnalité (généralement plusieurs années). Ces cycles sont souvent liés aux cycles économiques généraux (phases d'expansion, de récession). Contrairement à la saisonnalité, les cycles n'ont pas une périodicité fixe et leur amplitude peut varier, ce qui les rend plus difficiles à modéliser (elle ne sera pas étudiée en détail)* **Composante Résiduelle/Irrégulière ($E_t$) :** Aussi appelée "bruit" ou "aléa", cette composante représente tout ce qui reste dans la série une fois que la tendance, la saisonnalité et le cycle ont été pris en compte. Elle capture les variations aléatoires, les événements imprévisibles (grève, catastrophe naturelle, crise soudaine), les erreurs de mesure ou toute autre fluctuation non systématique. On la suppose souvent comme une composante aléatoire centrée autour de zéro (modèle additif) ou de un (modèle multiplicatif).Ces composantes ne sont généralement pas observées directement mais sont estimées à partir des données $y_t$. Elles interagissent pour former la série observée, le plus souvent selon un schéma additif ou multiplicatif, comme nous le verrons dans la section suivante.### 1.4. Modèles de Composition* Modèle additif : $y_t = T_t + S_t (+ C_t) + E_t$* Modèle multiplicatif : $y_t = T_t \times S_t (\times C_t) \times E_t$ (peut être linéarisé par log)## Analyse de la Tendance ($T_t$)### Modèles de tendance dépendant du temps* Tendance linéaire : $T_t = a + bt$* Tendance quadratique/polynomiale : $T_t = a + bt + ct^2 + ...$* Tendance logistique (pour phénomènes bornés) : $T_t = \frac{c}{1 + be^{-at}}$### Estimation de la tendance* Ajustement par régression (Moindres Carrés) sur le temps ($t, t^2, ...$)* Lissage (voir section 4)## Opérateurs Temporels et Différenciation### Opérateurs de décalage : Retard (L) et Avance (F)* $Ly_t = y_{t-1}$, $L^k y_t = y_{t-k}$### Opérateur de différence ($\nabla = I - L$)* $\nabla y_t = y_t - y_{t-1}$* Effet sur tendance linéaire ($\nabla y_t \approx b$)* Différence d'ordre q ($\nabla^q$) et tendance polynomiale### Opérateur de différence saisonnière ($\nabla_s = I - L^s$)* $\nabla_s y_t = y_t - y_{t-s}$ (où s = période saisonnière : 4, 12, etc.)* Utilisation pour éliminer la saisonnalité## Lissage par Moyennes Mobiles (MM)### Filtres linéaires et Moyennes Mobiles* Définition et objectif : lisser la série, estimer la tendance/cycle-tendance.### Moyennes Mobiles Symétriques* MM simple (non pondérée) d'ordre impair $m=2p+1$: $\frac{1}{m} \sum_{j=-p}^{p} y_{t+j}$### Moyennes Mobiles pour données saisonnières (estimation Tendance-Cycle)* Période impaire (ex: m=7) : MM simple d'ordre m* Période paire (ex: m=4 ou 12) : MM centrées spécifiques * Ex: $MM(4) = \frac{1}{8}(y_{t-2} + 2y_{t-1} + 2y_t + 2y_{t+1} + y_{t+2})$ * Ex: $MM(12)$ (MM d'ordre 12 suivie d'une MM d'ordre 2)### Moyennes/Médianes Mobiles Particulières (mention)* Van Hann, Spencer, Henderson (propriétés spécifiques)* Médiane mobile (robustesse aux valeurs extrêmes)## Désaisonnalisation### Objectif : Obtenir une série Corrigée des Variations Saisonnières (CVS)### Estimation de la composante saisonnière ($S_m$)* Basée sur l'écart (additif) ou le ratio (multiplicatif) à la tendance estimée (par MM).### Méthode Additive* Calcul des écarts bruts $d_{am} = Y_{am} - T_{am}$* Estimation des coefficients saisonniers $S_m = \text{moyenne}(d_{am})$ pour chaque saison $m$* Ajustement additif : $S'_m = S_m - \bar{S}$ pour que $\sum S'_m = 0$* Série CVS : $Y^e_{am} = Y_{am} - S'_m$### Méthode Multiplicative* Calcul des ratios bruts $r_{am} = Y_{am} / T_{am}$* Estimation des coefficients saisonniers $S_m = \text{moyenne}(r_{am})$ pour chaque saison $m$* Ajustement multiplicatif : $S'_m = S_m / \bar{S}$ pour que $\frac{1}{M}\sum S'_m = 1$* Série CVS : $Y^e_{am} = Y_{am} / S'_m$### Exemple de décomposition (graphique)## Lissage Exponentiel (Introduction à la prévision)### Principe : Pondération exponentiellement décroissante des observations passées.### Lissage Exponentiel Simple (LES)* Adapté aux séries sans tendance (stationnaires en moyenne).* Formule récursive : $\hat{X}_t(1) = (1-\beta)X_t + \beta \hat{X}_{t-1}(1)$* Prévision : $\hat{X}_T(k) = \hat{X}_T(1)$ pour $k \ge 1$.### Lissage Exponentiel Double (LED) de Holt* Adapté aux séries avec tendance linéaire.* Système de lissage pour le niveau ($S^1_t$) et la tendance ($b_t$).* Prévision : $\hat{X}_T(k) = a_T + b_T k$* Calcul de $a_T$ et $b_T$ via LES simple et double ($S^1_T, S^2_T$)## Exercices:::{#exr-}## Identification des Composantes et ModèlesLe tableau suivant présente les ventes trimestrielles (en milliers d'euros) d'une entreprise sur 3 ans :| Année | Trimestre 1 | Trimestre 2 | Trimestre 3 | Trimestre 4 || :----| :----------| :----------| :----------| :----------|| 1 | 150 | 175 | 210 | 160 || 2 | 165 | 190 | 230 | 175 || 3 | 180 | 205 | 250 | 190 |1. Représentez graphiquement cette série temporelle.2. Identifiez visuellement la présence éventuelle d'une tendance et d'une composante saisonnière.3. Quel type de modèle (additif ou multiplicatif) vous semble le plus approprié pour cette série ? Justifiez votre réponse.::::::{#exr-}## Opérateurs de DifférenceConsidérez la série temporelle $y_t$ suivante : 5, 8, 12, 17, 23, 30, 38, 47.1. Calculez la série des différences d'ordre 1 : $\nabla y_t = y_t - y_{t-1}$. Que remarquez-vous ? Quelle type de tendance cet opérateur permet-il d'éliminer?2. Calculez la série des différences d'ordre 2 : $\nabla^2 y_t = \nabla(\nabla y_t)$. Qu'observez-vous ? Quelle type de tendance cet opérateur permet-il d'éliminer?::::::{#exr-}## Moyennes MobilesReprenons les données de l'Exercice 1 (ventes trimestrielles).1. Calculez la moyenne mobile centrée d'ordre 4 (adaptée aux données trimestrielles) pour lisser la série. Rappel : $MM(4)_t = \frac{1}{8}(y_{t-2} + 2y_{t-1} + 2y_t + 2y_{t+1} + y_{t+2})$.2. Représentez graphiquement la série originale et la série lissée par la moyenne mobile. Que constatez-vous concernant la composante saisonnière ?::::::{#exr-}## DésaisonnalisationUtilisez les données de l'Exercice 1 et la moyenne mobile calculée dans l'Exercice 3 (qui estime la tendance $T_{am}$).1. Calculez les coefficients saisonniers bruts $S_m$ en utilisant la méthode **additive** ($S_m = \frac{1}{A-1}\sum_a (Y_{am} - T_{am})$).2. Ajustez ces coefficients pour que leur somme soit nulle ($S'_m = S_m - \frac{1}{M}\sum_m S_m$).3. Calculez la série désaisonnalisée (CVS) additive : $Y^e_{am} = Y_{am} - S'_m$.4. Recommencez les étapes 1 à 3 en utilisant la méthode **multiplicative** (Coefficients bruts : $S_m = \frac{1}{A-1}\sum_a \frac{Y_{am}}{T_{am}}$, Ajustement : $S'_m = S_m / (\frac{1}{M}\sum_m S_m)$, Série CVS : $Y^e_{am} = Y_{am} / S'_m$).5. Comparez les séries désaisonnalisées obtenues par les deux méthodes.::::::{#exr-}## Lissage Exponentiel SimpleVoici le nombre mensuel de visiteurs d'un site web pendant 10 mois : 1200, 1250, 1180, 1230, 1260, 1210, 1240, 1270, 1190, 1220.1. Appliquez un lissage exponentiel simple (LES) à cette série avec un coefficient de lissage $\beta = 0.3$. Utilisez la formule récursive : $\hat{X}_t(1) = (1-\beta)X_t + \beta \hat{X}_{t-1}(1)$, en initialisant $\hat{X}_0(1) = X_1$.2. Quelle est la prévision pour le 11ème mois, $\hat{X}_{10}(1)$ ?3. Pourquoi le LES est-il adapté à une série sans tendance marquée?::::::{#exr-}## Lissage Exponentiel DoubleConsidérez la série suivante qui présente une tendance linéaire : 50, 55, 58, 62, 65, 70, 72, 78.1. Appliquez un lissage exponentiel simple (LES) $S^1_t$ avec $\beta = 0.4$.2. Appliquez un second lissage exponentiel simple $S^2_t$ à la série $S^1_t$ obtenue, avec le même $\beta = 0.4$.3. Calculez les estimateurs de la tendance $a_t = 2S^1_t - S^2_t$ et $b_t = \frac{1-\beta}{\beta}(S^1_t - S^2_t)$ pour la dernière période (t=8).4. Faites une prévision pour les deux prochaines périodes (t=9 et t=10) en utilisant la formule $\hat{X}_T(k) = a_T + b_T k$.::::::{#exr-}## Comparaison de Moyennes MobilesSoit la série temporelle mensuelle suivante : 15, 18, 14, 20, 22, 18, 15, 19, 21, 17, 23, 25.1. Calculez une moyenne mobile simple (non-pondérée) d'ordre 3.2. Calculez la moyenne mobile de Van Hann $MMVH = \frac{1}{4}(L + 2I + F)$.3. Représentez graphiquement la série originale et les deux séries lissées. Comparez l'effet des deux moyennes mobiles. Laquelle semble produire un lissage plus "doux" ?::::::{#exr-}## Modélisation de Tendance Non-LinéaireLe nombre de plaintes reçues par un service client sur 8 trimestres est : 10, 12, 15, 14, 16, 19, 24, 30.1. Représentez graphiquement la série. Une tendance linéaire simple vous semble-t-elle appropriée ?2. Ajustez une tendance quadratique $T_t = a + bt + ct^2$ par la méthode des moindres carrés (considérez t=1 pour le premier trimestre).3. Interprétez les signes des coefficients $b$ et $c$.4. Quelle est la valeur de la tendance estimée pour le 9ème trimestre ?::::::{#exr-}## Différenciation pour StationnarisationConsidérez la série du trafic voyageurs SNCF présentée dans l'exemple 6.4 du document. Le graphique 6.11 montre une tendance croissante et une saisonnalité.1. Appliquez d'abord une différence saisonnière d'ordre 12 : $z_t = \nabla_{12} y_t = y_t - y_{t-12}$. Représentez graphiquement $z_t$. La saisonnalité a-t-elle disparu ? Reste-t-il une tendance ?2. Appliquez ensuite une différence d'ordre 1 à la série $z_t$ : $w_t = \nabla z_t = z_t - z_{t-1}$. Représentez graphiquement $w_t$. La série $w_t$ semble-t-elle stationnaire (sans tendance ni saisonnalité claire) ?3. Exprimez $w_t$ directement en fonction de $y_t$ en utilisant les opérateurs $L$.::::::{#exr-}## Effet d'un Filtre LinéaireConsidérez le filtre linéaire $\mathcal{F} = 0.25 L + 0.5 I + 0.25 F$.1. Appliquez ce filtre à une série représentant une tendance linéaire parfaite : $y_t = a + bt$. Montrez que le filtre conserve la tendance linéaire (c'est-à-dire que $\mathcal{F}y_t = a' + b't$, trouvez $a'$ et $b'$).2. Appliquez ce filtre à une série représentant une tendance quadratique parfaite : $y_t = a + bt + ct^2$. Le filtre conserve-t-il la tendance quadratique ? (Calculez $\mathcal{F}y_t$).::::::{#exr-}## Choix de la Méthode de Lissage ExponentielExaminez les deux séries temporelles suivantes :* Série A : 105, 103, 106, 104, 107, 105, 108, 106 (fluctuations autour d'un niveau stable)* Série B : 20, 24, 27, 31, 35, 38, 42, 45 (tendance croissante)1. Pour quelle série le lissage exponentiel simple (LES) serait-il le plus approprié pour faire une prévision à court terme ? Pourquoi ?2. Pour quelle série le lissage exponentiel double (LED) serait-il préférable ? Pourquoi ?3. Quel type de prévision (constante ou avec tendance) obtiendrait-on en appliquant le LED à la Série A ?::::::{#exr-}## Interprétation de la Désaisonnalisation MultiplicativeReprenons les résultats de la désaisonnalisation multiplicative de la série des ventes de réfrigérateurs (Exemple 6.9, Tableaux 6.6 et 6.7 du document PDF). Les coefficients saisonniers ajustés $S'_m$ sont approximativement :$S'_1 \approx 0.91$ (Trim 1), $S'_2 \approx 1.08$ (Trim 2), $S'_3 \approx 1.16$ (Trim 3), $S'_4 \approx 0.85$ (Trim 4).1. Interprétez la valeur de $S'_3 \approx 1.16$. Que signifie-t-elle par rapport à la tendance ?2. Interprétez la valeur de $S'_1 \approx 0.91$.3. Comment utiliseriez-vous ces coefficients pour "resaisonnaliser" une prévision de la tendance pour le 2ème trimestre de l'année suivante ?4. Vérifiez que la moyenne de ces coefficients est bien égale à 1 (ou très proche, aux erreurs d'arrondi près).:::