Soit une variable quantitative d’intérêt mesurée sur \(n\) individus. Les données observées sont notées : \[ x_1, x_2, \dots, x_i, \dots, x_n, \quad x_i \in \mathbb{R}, \]
où \(x_i\in\mathbb{R}\) est la donnée observée sur l’individu \(i\).
Paramètres de tendance centrale
Les paramètres de tendance centrale permettent de caractériser une série quantitative en fournissant une valeur représentative des données.
Les principales mesures de tendance centrale sont :
Moyenne arithmétique
La moyenne arithmétique est définie comme la somme des observations divisée par leur nombre : \[
\bar{x} = \dfrac{1}{n} \sum_{i=1}^{n} x_i.
\] Elle représente le point d’équilibre des données et est très utilisée en analyse statistique.
Example 1 Un enseignant collecte les notes de 5 étudiants à un examen : \[ 12, 15, 14, 10, 18. \] La moyenne est calculée comme suit : \[
\bar{x} = \dfrac{1}{5}\left(12 + 15 + 14 + 10 + 18\right) = \dfrac{69}{5} = 13.8.
\]
Moyenne pondérée
La moyenne pondérée est utilisée lorsque certaines observations ont plus d’importance que d’autres.
Elle est définie par : \[
\bar{x}_p = \sum_{i=1}^{n} w_i x_i
\] où les \(w_i>0\) sont les poids associés aux observations, avec \(\sum_{i=1}^nw_i=1\).
Cette moyenne est particulièrement utile dans les cas suivants :
Calcul de notes (avec des coefficients différents pour chaque épreuve).
Indicateurs économiques (par exemple, le PIB ajusté par la population).
Example 2 Un étudiant passe trois épreuves avec des coefficients différents :
La moyenne géométrique est utilisée lorsqu’on travaille avec des taux de croissance ou des ratios, et est définie par : \[
\bar{x}_g = \left( \prod_{i=1}^{n} x_i \right)^{\frac{1}{n}}.
\]Remarque
Calculer une croissance moyenne sur plusieurs années.
Agréger des ratios ou indices financiers.
Example 3 Un investissement a des taux de rendement annuels successifs de 5%, 10% et 15%.
Les valeurs relatives sont \(1.05, 1.10, 1.15\), donc la moyenne géométrique est : \[
\bar{x}_g = \left(1.05 \times 1.10 \times 1.15\right)^{\frac{1}{3}} \approx 1.096.
\] Le rendement moyen est donc 9.6%.
Moyenne harmonique
La moyenne harmonique est utilisée pour calculer des moyennes de vitesses ou de ratios inverses, et est définie par : \[
\bar{x}_h = \dfrac{n}{\sum_{i=1}^{n} \dfrac{1}{x_i}}.
\]Remarque
Il s’agit de l’inverse de la moyenne des inverses.
Elle est utile dans :
La moyenne des vitesses (ex. vitesse moyenne sur un trajet).
L’analyse économique (moyenne des prix unitaires).
Example 4 Un véhicule parcourt 100 km à 60 km/h puis 100 km à 100 km/h.
La vitesse moyenne n’est pas la moyenne arithmétique mais la moyenne harmonique : \[
\bar{x}_h = \dfrac{2}{\dfrac{1}{60} + \dfrac{1}{100}} = \dfrac{2}{\dfrac{10}{600}} = 75 \text{ km/h}.
\]
Moyenne quadratique
La moyenne quadratique est définie par : \[
\bar{x}_q = \sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2}.
\] Elle est utilisée en traitement du signal et en statistique des erreurs.
Example 5 Les tensions électriques mesurées sont 3V, 4V et 5V.
La moyenne quadratique est : \[
\bar{x}_q = \sqrt{\frac{3^2 + 4^2 + 5^2}{3}} = \sqrt{\frac{9 + 16 + 25}{3}} = \sqrt{16.67} \approx 4.08.
\]
Médiane
La médiane est la valeur qui partage la série en deux parties égales :
Si \(n\) est impair, la médiane est l’élément central.
Si \(n\) est pair, la médiane est la moyenne des deux valeurs centrales.
La médiane est moins sensible aux valeurs extrêmes que la moyenne.
Example 6 Soit la série triée \(8, 10, 12, 15, 18\).
- \(n=5\) (impair) → médiane = 12.
Si la série est \(8, 10, 12, 15, 18, 20\) (\(n=6\), pair), la médiane est : \[
\dfrac{12 + 15}{2} = 13.5.
\]
Note
De façon plus formelle, la médiane est tout réel \(q_{\frac{1}{2}}\) tel que \[
\left\{
\begin{array}{lll}
\dfrac{1}{n}\sum_{i=1}^n1_{[x_i\leq q_{\frac{1}{2}}]}&\geq&\dfrac{1}{2}\\
\dfrac{1}{n}\sum_{i=1}^n1_{[x_i\geq q_{\frac{1}{2}}]}&\geq&\dfrac{1}{2}\\
\end{array}
\right.
\]
Ainsi, une série statistique peut avoir plusieurs médiane. C’est en général le cas lorsque \(n\) est pair.
Mode
On appelle mode toute modalité d’effectif ou de fréquente maximale.
Une série peut être unimodale (un seul mode) ou multimodale (plusieurs modes).
Si toutes les valeurs sont uniques, il n’y a pas de mode.
Example 7 Dans la série \(12, 15, 14, 10, 15, 18, 15\), le mode est \(15\) car c’est la valeur la plus fréquente.
Remarque sur les mesures de tendance centrale
La moyenne est influencée par les valeurs extrêmes, contrairement à la médiane.
La médiane est plus robuste dans les distributions asymétriques.
Le mode est surtout utilisé pour des données discrètes ou lorsque l’on cherche une catégorie dominante.
Choisir la bonne mesure
Moyenne arithmétique : pour des données homogènes.
Médiane : en cas de valeurs extrêmes.
Moyennes géométrique, harmonique, quadratique : pour des cas spécifiques.
Mode : utile pour identifier les valeurs les plus courantes.
Paramètres de dispersion
Les paramètres de dispersion permettent de mesurer la variabilité des données autour d’une valeur centrale (comme la moyenne). Ils indiquent dans quelle mesure les valeurs sont dispersées et aident à interpréter la distribution d’une variable.
Les principaux indicateurs de dispersion sont :
Étendue
L’étendue est la différence entre la plus grande et la plus petite valeur d’un ensemble de données : \[
E = x_{\max} - x_{\min}.
\] Elle donne une indication rapide sur l’amplitude des valeurs, mais elle est très sensible aux valeurs extrêmes.
Example 8 Soit la série \(5, 8, 12, 15, 20\).
L’étendue est : \[
E = 20 - 5 = 15.
\]
Variance
La variance mesure la moyenne des carrés des écarts à la moyenne : \[
S^2 = \dfrac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2.
\] Elle est exprimée dans le carré de l’unité des données (ex. : si \(x_i\) est en cm, \(S^2\) est en cm²).
Lorsque les données sont pondérées par les poids \(w_i\), on a: \[
S^2 = \sum_{i=1}^nw_i\left(x_i-\bar{x}\right)^2.
\]
Écart-type
L’écart-type est la racine carrée de la variance, il s’exprime dans la même unité que les données : \[
S = \sqrt{S^2}.
\] Il permet d’interpréter plus facilement la dispersion des valeurs.
Coefficient de variation
Le coefficient de variation (CV) permet de comparer la dispersion entre deux séries de données de nature différente : \[
CV = \dfrac{S}{\bar{x}} \times 100.
\] Il est exprimé en pourcentage et indique le degré relatif de dispersion.
Example 10
Série A : \(\bar{x} = 50\), \(S = 5 \Rightarrow CV = \dfrac{5}{50} \times 100 = 10\%\).
Série B : \(\bar{x} = 200\), \(S = 25 \Rightarrow CV = \dfrac{25}{200} \times 100 = 12.5\%\).
Bien que l’écart-type de la série B soit plus grand, son CV est plus faible, ce qui signifie que les valeurs sont moins dispersées par rapport à la moyenne.
Intervalle interquartile et écart interquartile
Definition 1 (Quantile d’ordre \(\alpha\)) Pour tout \(\alpha\in]0,1[\), on appelle quantile d’ordre \(\alpha\) tout réel \(q_{\alpha}\) qui vérifie \[
\left\{
\begin{array}{lll}
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq q_{\alpha}\right]}&\geq&\alpha\\
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq q_{\alpha}\right]}&\geq&1-\alpha\\
\end{array}
\right.
\]
Note
Dans la pratique, pour déterminer \(q_{\alpha}\), on procède comme suit:
Déterminer les statistiques d’ordre (ranger les données dans l’ordre croisant): \[x_{(1)}\leq x_{(2)}\leq\cdots\leq x_{(n)}.\]
Déterminer le plus petit \(n_g\) tel que \[
\left\{
\begin{array}{lll}
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq x_{(n_g)}\right]}&\geq&\alpha\\
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq x_{(n_g)}\right]}&\geq&1-\alpha\\
\end{array}
\right.
\]
Déterminer le plus grand \(n_d\) tel que \[
\left\{
\begin{array}{lll}
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq x_{(n_d)}\right]}&\geq&\alpha\\
\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq x_{(n_d)}\right]}&\geq&1-\alpha\\
\end{array}
\right.
\]
\(q_{\dfrac{1}{4}}\) (1er quartile) : Valeur sous laquelle se trouvent 25% des observations.
\(q_{\dfrac{3}{4}}\) (3e quartile) : Valeur sous laquelle se trouvent 75% des observations.
Example 11 Déterminer les quartiles de la série précédente.
Definition 3 (Intervalle inter-quartile) L’intervalle inter-quartile est la plage contenant les 50% des valeurs centrales d’une distribution : \[
IIQ = q_{\frac{3}{4}} - q_{\frac{1}{4}}.
\]
Cet indicateur est robuste aux valeurs extrêmes et permet de mieux comprendre la dispersion dans la zone centrale des données.
Example 12 Série : \(5, 8, 10, 12, 15, 18, 20\) (triée).
Les données \(x_i\notin\left[b_-,b_+\right]\) sont en générale considérées comme atypiques, et sont parfois être retirées de l’étude.
Résumé des indicateurs
Indicateur
Formule
Interprétation
Étendue
\(E = x_{\max} - x_{\min}\)
Indique la dispersion globale, très sensible aux valeurs extrêmes.
Variance
\(S^2 = \dfrac{1}{n} \sum (x_i - \bar{x})^2\)
Mesure la dispersion moyenne, exprimée au carré des unités des données.
Écart-type
\(S = \sqrt{S^2}\)
Indique la dispersion absolue, dans la même unité que les données.
Coefficient de variation
\(CV = \dfrac{S}{\bar{x}} \times 100\)
Permet de comparer la dispersion relative entre différentes séries.
Intervalle interquartile
\(IIQ = q_{\frac{3}{4}} - q_{\frac1{4}}\)
Indique la dispersion centrale, moins sensible aux valeurs extrêmes.
Remarque sur l’interprétation des indicateurs
Plus l’écart-type est grand, plus les données sont dispersées autour de la moyenne.
Un coefficient de variation élevé indique une forte variabilité par rapport à la moyenne.
L’intervalle interquartile est plus robuste que l’écart-type en présence de valeurs aberrantes.
Choisir le bon indicateur
Écart-type / Variance : pertinents pour des données sans valeurs extrêmes.
Intervalle interquartile : recommandé pour des distributions asymétriques ou avec valeurs aberrantes.
Coefficient de variation : utile pour comparer des distributions de natures différentes.
Tableau statistique d’une série quantitative discrète
Définition et intérêt
Lorsqu’on dispose d’une série quantitative discrète, il est souvent utile de regrouper les valeurs sous forme d’un tableau statistique. Celui-ci permet de résumer les données, d’en faciliter l’analyse et de calculer des indicateurs statistiques.
Soit une série de \(n\) individus pour lesquels on mesure une variable quantitative discrète \(X\), prenant \(K\) valeurs distinctes\(x_1, x_2, \dots, x_K\) (les modalités).
Le tableau statistique associe à chaque valeur \(x_k\) son effectif et sa fréquence :
Valeur \(x_i\)
Effectif \(n_i\)
Fréquence \(f_i\)
\(x_1\)
\(n_1\)
\(f_1 = \frac{n_1}{n}\)
\(x_2\)
\(n_2\)
\(f_2 = \frac{n_2}{n}\)
\(\vdots\)
\(\vdots\)
\(\vdots\)
\(x_K\)
\(n_K\)
\(f_K = \frac{n_k}{n}\)
Total
\(n\)
\(1\)
\(n_k\) est l’effectif de la modalité \(x_k\)
L’effectif total est \(n=\sum_{k=1}^Kn_k\)
\(f_k=\dfrac{n_k}{n}\) est la proportion de la modalité \(x_k\)
Example 13 Un enseignant note 10 élèves sur 20 points et obtient la série : \[ 12, 15, 14, 12, 10, 15, 12, 16, 14, 15. \]
On regroupe les valeurs dans un tableau :
Valeur \(x_i\)
Effectif \(n_i\)
Fréquence \(f_i\)
\(10\)
\(1\)
\(0.10\)
\(12\)
\(3\)
\(0.30\)
\(14\)
\(2\)
\(0.20\)
\(15\)
\(3\)
\(0.30\)
\(16\)
\(1\)
\(0.10\)
Total
10
1.00
On peut observer que la note la plus fréquente est 12 et 15, avec une fréquence de 30%.
Interprétation du tableau
Un tableau statistique permet de :
Visualiser les valeurs les plus fréquentes (mode de la distribution).
Faciliter les calculs de moyenne et de variance en ajoutant une colonne \(n_k\times x_k\).
Identifier la distribution des données (répartition uniforme ou non).
Ajout des effectifs cumulés
Il peut être utile d’ajouter une colonne des effectifs cumulés croissants pour mieux analyser la distribution :
Valeur \(x_i\)
Effectif \(n_k\)
Fréquence \(f_k\)
Effectif cumulé \(N_k\)
\(10\)
\(1\)
\(0.10\)
\(1\)
\(12\)
\(3\)
\(0.30\)
\(1 + 3 = 4\)
\(14\)
\(2\)
\(0.20\)
\(4 + 2 = 6\)
\(15\)
\(3\)
\(0.30\)
\(6 + 3 = 9\)
\(16\)
\(1\)
\(0.10\)
\(9 + 1 = 10\)
Total
10
1.00
10
Les effectifs cumulés permettent de répondre rapidement aux questions comme : “Combien d’élèves ont une note inférieure ou égale à 14 ?” → 6 élèves.
Note
Un tableau statistique est un outil fondamental pour analyser une série quantitative discrète.
Il permet de structurer les données, d’en faciliter la compréhension et sert de base pour les calculs statistiques (moyenne, médiane, variance, etc.).
Représentations graphiques
L’analyse graphique d’une série quantitative permet d’obtenir une vue d’ensemble des données et de repérer des tendances ou anomalies. Différents types de graphiques peuvent être utilisés selon le type de données (discrètes ou continues) et l’objectif de l’analyse.
Diagramme en bâtons
Le diagramme en bâtons est adapté aux données discrètes. Il représente chaque valeur \(x_k\) par une barre verticale dont la hauteur est proportionnelle à son effectif\(n_k\) ou sa fréquence\(f_k\).
Note
En abscisse : les valeurs de la variable.
En ordonnée : les effectifs ou fréquences.
Les bâtons ne sont pas collés (contrairement à l’histogramme).
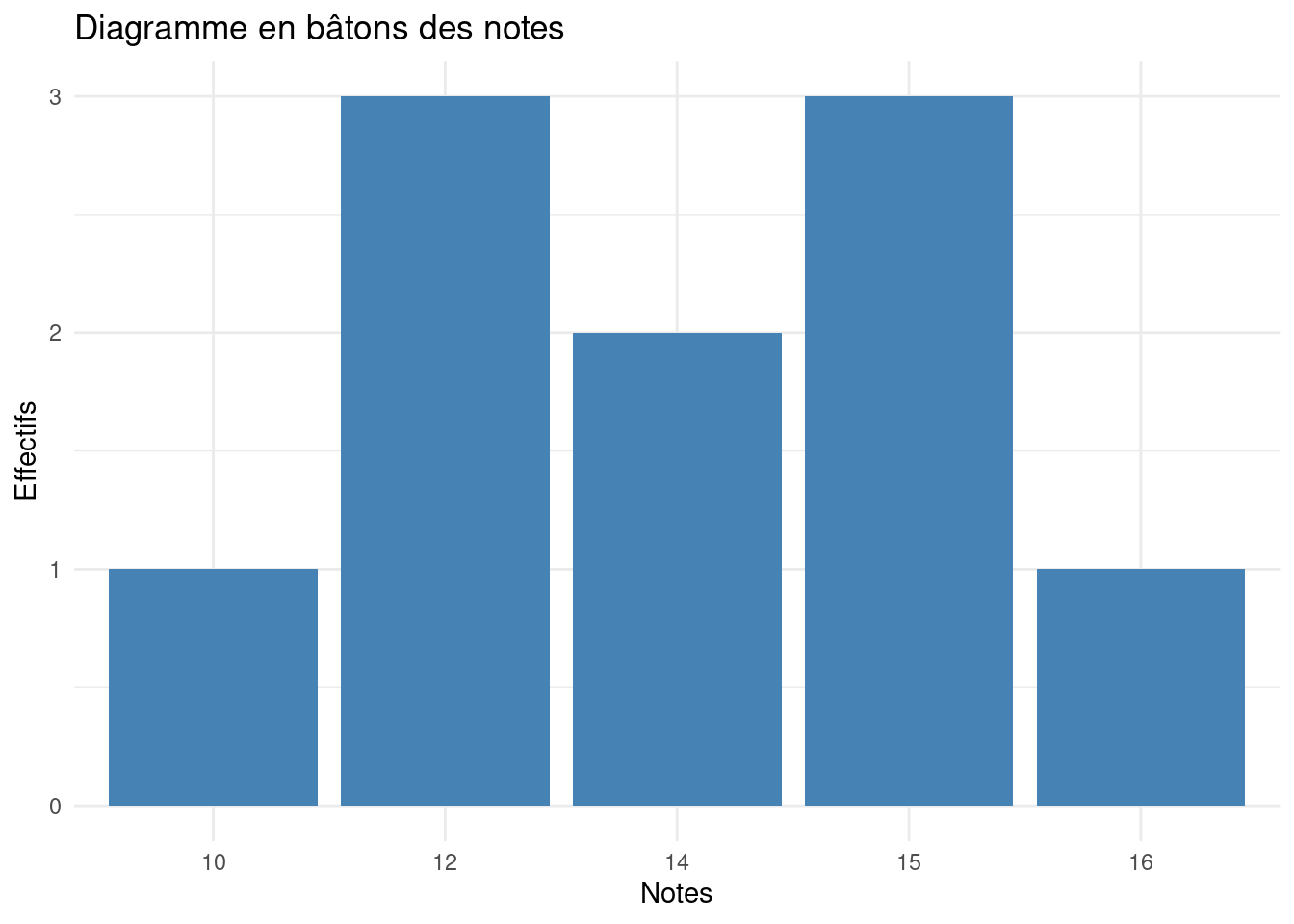
Example 14 Un enseignant note 10 élèves et obtient la distribution suivante :
Note (\(x_k\))
Effectif (\(n_k\))
10
1
12
3
14
2
15
3
16
1
Le diagramme en bâtons permet de visualiser les valeurs les plus fréquentes.
Code
library(ggplot2)data <-data.frame(Note =c(10, 12, 14, 15, 16),Effectif =c(1, 3, 2, 3, 1))ggplot(data, aes(x =factor(Note), y = Effectif)) +geom_bar(stat ="identity", fill ="steelblue") +labs(title ="Diagramme en bâtons des notes",x ="Notes",y ="Effectifs") +theme_minimal()
Histogramme
L’histogramme est adapté aux données continues regroupées en classes.
Construction :
En abscisse : les classes.
En ordonnée : la densité d’effectif (effectif divisé par l’amplitude de la classe).
Les barres sont collées pour indiquer la continuité des données.
La surface d’une barre est proportionnelle à son effectif (ou fréquence).
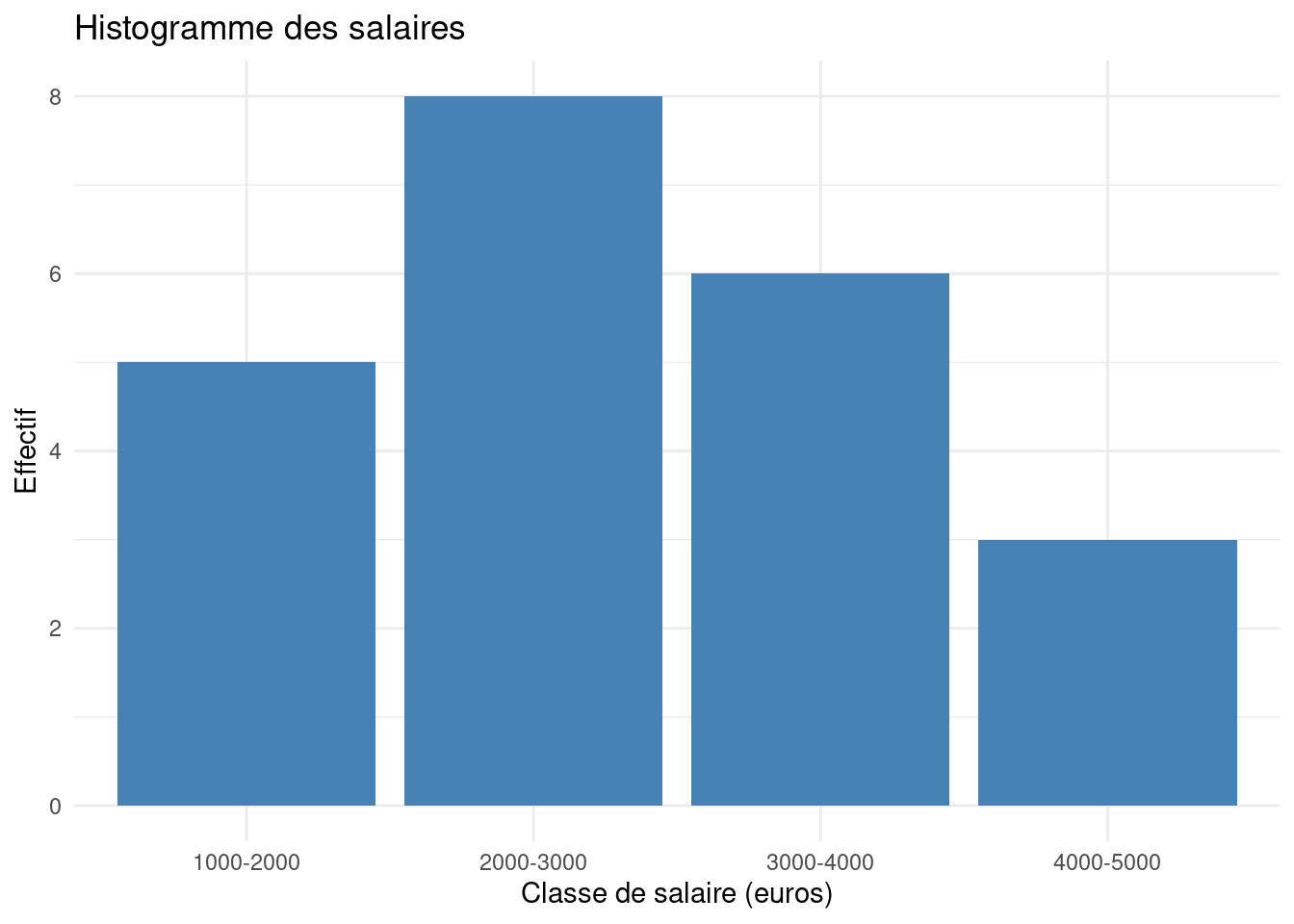
Example 15 Soit une étude des salaires en euros avec les classes suivantes :
Classe (en euros)
Effectif
[1000 - 2000[
5
[2000 - 3000[
8
[3000 - 4000[
6
[4000 - 5000[
3
L’histogramme permet de visualiser la répartition des salaires et de repérer les classes les plus fréquentes.
Code
library(ggplot2)data <-data.frame(Classe =factor(c("1000-2000", "2000-3000", "3000-4000", "4000-5000"),levels =c("1000-2000", "2000-3000", "3000-4000", "4000-5000")),Effectif =c(5, 8, 6, 3))ggplot(data, aes(x = Classe, y = Effectif)) +geom_histogram(stat ="identity", fill ="steelblue") +labs(title ="Histogramme des salaires",x ="Classe de salaire (euros)",y ="Effectif") +theme_minimal()
Warning in geom_histogram(stat = "identity", fill = "steelblue"): Ignoring
unknown parameters: `binwidth`, `bins`, and `pad`
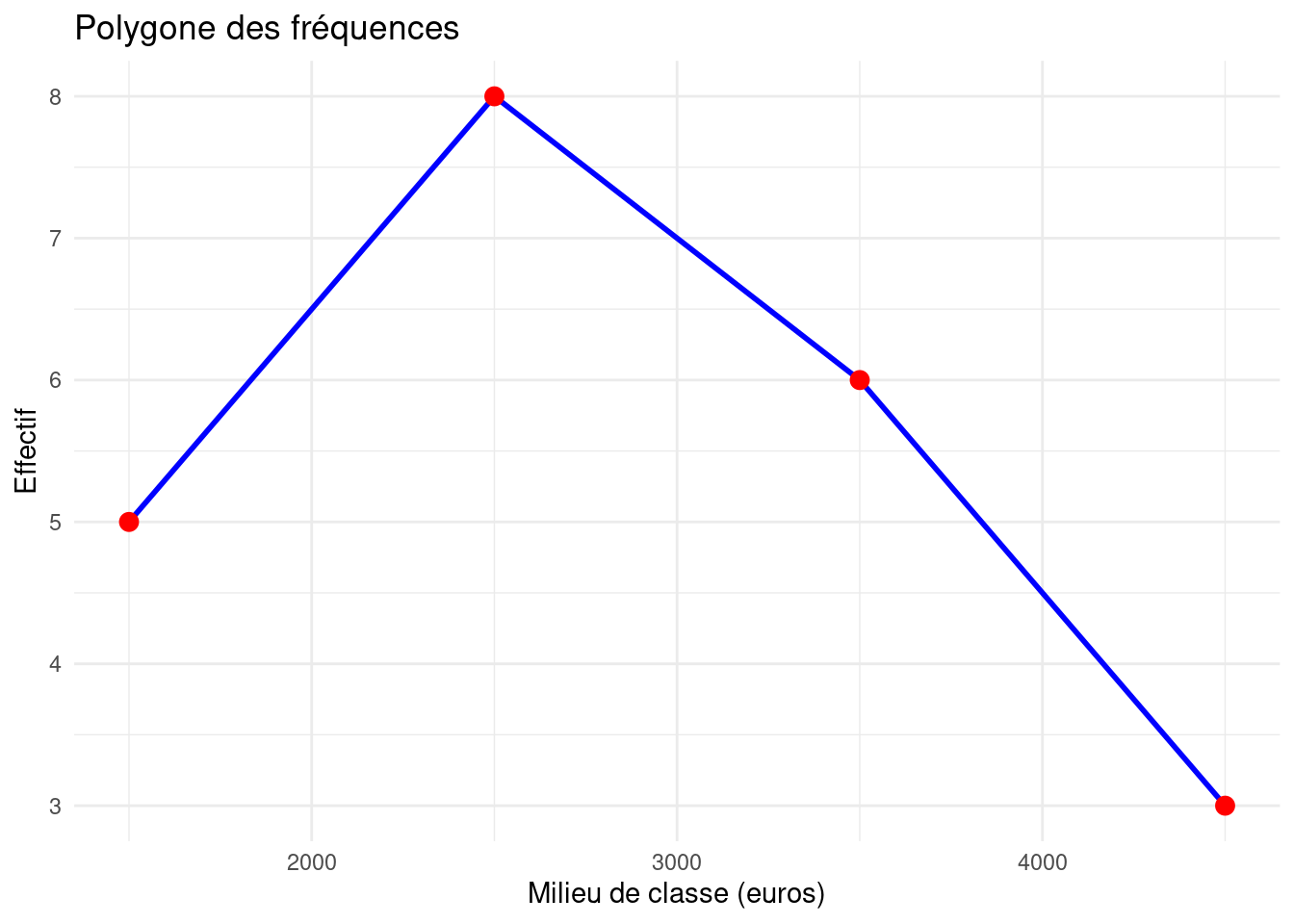
Polygone des fréquences
Le polygone des fréquences relie les milieux des classes d’un histogramme par des segments.
Utilité :
Permet une visualisation fluide de la distribution.
Met en évidence les tendances générales.
Exercise 1
Code
library(ggplot2)data <-data.frame(Milieu =c(1500, 2500, 3500, 4500),Effectif =c(5, 8, 6, 3))ggplot(data, aes(x = Milieu, y = Effectif)) +geom_line(group =1, color ="blue", size =1) +geom_point(color ="red", size =3) +labs(title ="Polygone des fréquences",x ="Milieu de classe (euros)",y ="Effectif") +theme_minimal()
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
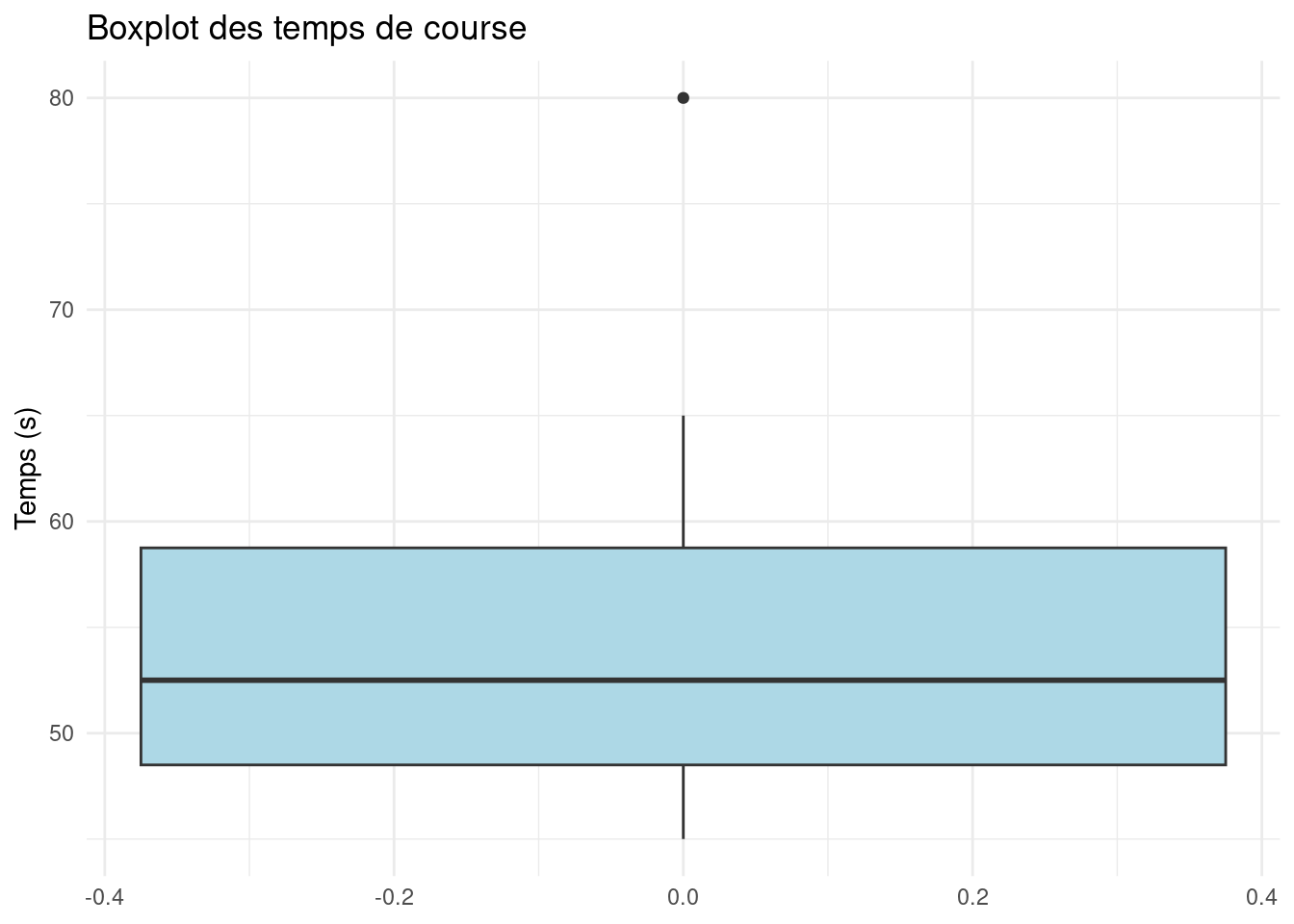
Boîte à moustaches (Boxplot)
La boîte à moustaches est un graphique adapté pour visualiser la dispersion des données et détecter les valeurs extrêmes.
Note
La boîte est délimitée par le 1er quartile (\(Q_1\)) et le 3e quartile (\(Q_3\)).
La médiane est représentée à l’intérieur de la boîte.
Les moustaches s’étendent jusqu’aux valeurs extrêmes non aberrantes.
Les valeurs aberrantes sont indiquées par des points isolés.
Example 16 Un boxplot appliqué à des temps de course en secondes (\(n = 10\)) :
Temps (s)
45
47
48
50
52
53
55
60
65
80
Le boxplot permet d’identifier rapidement la médiane, la dispersion et les valeurs extrêmes.
Code
library(ggplot2)data <-data.frame(Temps =c(45, 47, 48, 50, 52, 53, 55, 60, 65, 80))ggplot(data, aes(y = Temps)) +geom_boxplot(fill ="lightblue") +labs(title ="Boxplot des temps de course",y ="Temps (s)") +theme_minimal()
Fonction de répartition
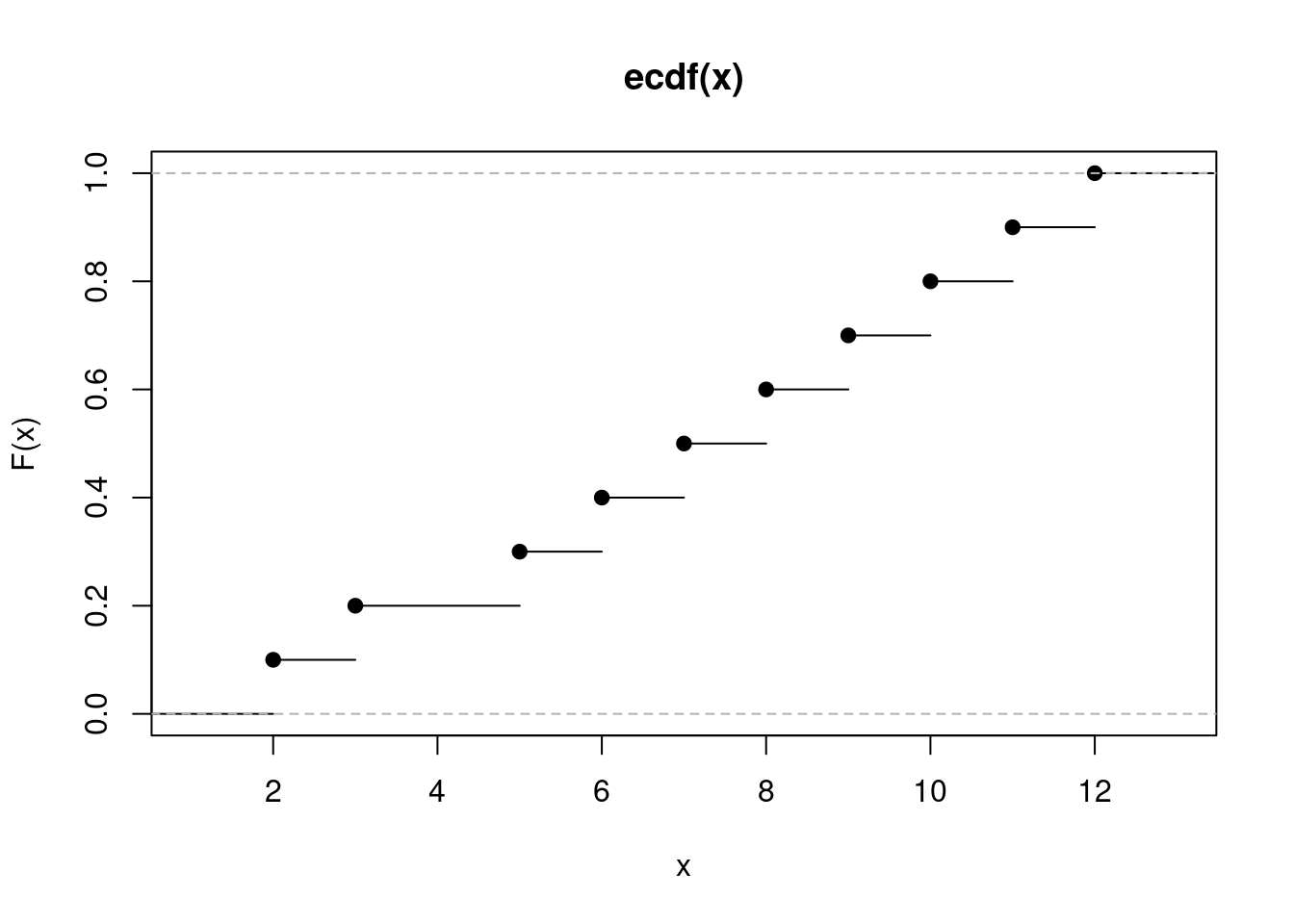
Definition 4 (Fonction de répartition) La fonction de répartition, notée \(F_{x_{1:n}}\), est un outil essentiel en statistique descriptive pour analyser la distribution d’un échantillon \(x_1, \ldots, x_n\). Elle indique pour tout réel \(x\), la proportion d’observations de l’échantillon qui sont inférieures ou égales à \(x\). Cette fonction est définie pour tout réel \(x\) par :
Continuité à droite : \(F_{x_{1:n}}\) est continue à droite en tout point \(x\).
Example 17 Considérons un échantillon de valeurs \(x_1, \ldots, x_n\) et calculons sa fonction de répartition. Voici comment cette fonction peut être estimée et représentée en R pour un échantillon hypothétique :
Code
# Échantillon hypothétiquex <-c(2, 3, 5, 6, 7, 8, 9, 10, 11, 12)# Calcul de la fonction de répartitionFx <-ecdf(x)# Représentation graphique de la fonction de répartitionplot(Fx, xlab="x", ylab="F(x)")
Remarque
Quel graphique choisir ?
Données discrètes : Diagramme en bâtons.
Données continues : Histogramme.
Comparaison de distributions : Polygone des fréquences.
Détection des valeurs extrêmes : Boîte à moustaches.
Exercices
Exercise 2Vrai ou Faux :
Une “variable” est tout caractère étudié dans une étude statistique.
La statistique descriptive recueille les données.
Elle résume les données via des tableaux, graphiques et indicateurs.
Une variable quantitative mesure une qualité.
Elle peut prendre des valeurs dans \(\mathbb{N}\).
La variance donne une idée de la valeur moyenne étudiée.
L’écart-type s’exprime dans l’unité de la variable étudiée.
Le mode est la modalité la moins fréquente.
La moyenne arithmétique d’une variable qualitative est la modalité la plus fréquente.
Exercise 3 Pour les sujets d’étude qui suivent, spécifier : l’unité statistique, la variable étuduée et son type,
Étude du temps de validité des lampes électriques.
Étude de l’absentéisme des ouvriers, en jours, dans une usine.
Répartition des étudiants d’une promotion selon la mention obtenue sur le diplôme du Bac.
On cherche à modéliser^1 le nombre de collisions impliquant deux voitures sur un ensemble de 100 intersections routières choisies au hasard dans une ville. Les données sont collectées sur une période d’un an et le nombre d’accidents pour chaque intersection est ainsi mesuré.
Exercise 4 On considère une série statistique représentant les revenus mensuels (en euros) de 20 individus dans une ville donnée :
Exercise 7 Le gérant d’un magasin vendant des articles de consommation courante a relevé pour un article particulier qui semble connaître une très forte popularité, le nombre d’articles vendus par jour. Son relevé a porté sur les ventes des mois de Mars et Avril, ce qui correspond à \(52\) jours de vente. Le relevé des observations se présente comme suit :
Histogramme des effectifs, fonction de répartition.
Quartiles et boîte à moustaches.
Source Code
---title: "Description d'une Série Quantitative"---Soit une variable quantitative d’intérêt mesurée sur **$n$ individus**. Les données observées sont notées : $$ x_1, x_2, \dots, x_i, \dots, x_n, \quad x_i \in \mathbb{R}, $$ où $x_i\in\mathbb{R}$ est la donnée observée sur l'individu $i$.## Paramètres de tendance centraleLes **paramètres de tendance centrale** permettent de caractériser une série quantitative en fournissant une valeur représentative des données.Les principales **mesures de tendance centrale** sont :### Moyenne arithmétiqueLa **moyenne arithmétique** est définie comme la somme des observations divisée par leur nombre :$$\bar{x} = \dfrac{1}{n} \sum_{i=1}^{n} x_i.$$Elle représente le **point d’équilibre** des données et est très utilisée en analyse statistique.::: {#exm-} Un enseignant collecte les notes de **5 étudiants** à un examen :$$ 12, 15, 14, 10, 18. $$La moyenne est calculée comme suit :$$\bar{x} = \dfrac{1}{5}\left(12 + 15 + 14 + 10 + 18\right) = \dfrac{69}{5} = 13.8.$$:::### Moyenne pondéréeLa **moyenne pondérée** est utilisée lorsque certaines observations ont plus d'importance que d'autres. Elle est définie par :$$\bar{x}_p = \sum_{i=1}^{n} w_i x_i$$où les $w_i>0$ sont les **poids** associés aux observations, avec $\sum_{i=1}^nw_i=1$.Cette moyenne est particulièrement utile dans les cas suivants :- **Calcul de notes** (avec des coefficients différents pour chaque épreuve). - **Indicateurs économiques** (par exemple, le PIB ajusté par la population). ::: {#exm-}Un étudiant passe **trois épreuves** avec des coefficients différents :- Mathématiques (coefficient **3**) : **14** - Physique (coefficient **2**) : **16** - Français (coefficient **1**) : **12** La moyenne pondérée est :$$\bar{x}_p = \dfrac{(3 \times 14) + (2 \times 16) + (1 \times 12)}{3 + 2 + 1} = \frac{42 + 32 + 12}{6} = 14.33.$$:::### Moyenne géométriqueLa **moyenne géométrique** est utilisée lorsqu'on travaille avec des **taux de croissance** ou des **ratios**, et est définie par :$$\bar{x}_g = \left( \prod_{i=1}^{n} x_i \right)^{\frac{1}{n}}.$$**Remarque**$$\ln \bar{x}_g=\dfrac{1}{n}\sum_{i=1}^n\ln x_i$$Elle est particulièrement utile pour :- Calculer une **croissance moyenne** sur plusieurs années. - Agréger des **ratios** ou **indices financiers**. ::: {#exm-}Un investissement a des taux de rendement annuels successifs de **5%**, **10%** et **15%**. Les valeurs relatives sont **$1.05, 1.10, 1.15$**, donc la moyenne géométrique est :$$\bar{x}_g = \left(1.05 \times 1.10 \times 1.15\right)^{\frac{1}{3}} \approx 1.096.$$Le rendement moyen est donc **9.6%**.:::### Moyenne harmoniqueLa **moyenne harmonique** est utilisée pour **calculer des moyennes de vitesses ou de ratios inverses**, et est définie par :$$\bar{x}_h = \dfrac{n}{\sum_{i=1}^{n} \dfrac{1}{x_i}}.$$**Remarque**Il s'agit de l'inverse de la moyenne des inverses.Elle est utile dans :- La moyenne des **vitesses** (ex. vitesse moyenne sur un trajet). - L’**analyse économique** (moyenne des prix unitaires). ::: {#exm-}Un véhicule parcourt **100 km** à **60 km/h** puis **100 km** à **100 km/h**. La vitesse moyenne n’est pas la moyenne arithmétique mais la **moyenne harmonique** :$$\bar{x}_h = \dfrac{2}{\dfrac{1}{60} + \dfrac{1}{100}} = \dfrac{2}{\dfrac{10}{600}} = 75 \text{ km/h}.$$:::### Moyenne quadratiqueLa **moyenne quadratique** est définie par :$$\bar{x}_q = \sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2}.$$Elle est utilisée en **traitement du signal** et en **statistique des erreurs**.::: {#exm-}Les tensions électriques mesurées sont **3V, 4V et 5V**. La moyenne quadratique est :$$\bar{x}_q = \sqrt{\frac{3^2 + 4^2 + 5^2}{3}} = \sqrt{\frac{9 + 16 + 25}{3}} = \sqrt{16.67} \approx 4.08.$$:::### MédianeLa **médiane** est la valeur qui partage la série en deux parties égales :- Si **$n$ est impair**, la médiane est l’élément central. - Si **$n$ est pair**, la médiane est la moyenne des deux valeurs centrales.La médiane est **moins sensible aux valeurs extrêmes** que la moyenne.::: {#exm-}Soit la série triée **$8, 10, 12, 15, 18$**. - **$n=5$** (impair) → médiane = **12**. Si la série est **$8, 10, 12, 15, 18, 20$** (**$n=6$**, pair), la médiane est :$$\dfrac{12 + 15}{2} = 13.5.$$::::::{.callout-note}- De façon plus formelle, la médiane est tout réel $q_{\frac{1}{2}}$ tel que $$\left\{\begin{array}{lll}\dfrac{1}{n}\sum_{i=1}^n1_{[x_i\leq q_{\frac{1}{2}}]}&\geq&\dfrac{1}{2}\\\dfrac{1}{n}\sum_{i=1}^n1_{[x_i\geq q_{\frac{1}{2}}]}&\geq&\dfrac{1}{2}\\\end{array}\right.$$- Ainsi, une série statistique peut avoir plusieurs médiane. C'est en général le cas lorsque $n$ est pair.:::### ModeOn appelle **mode** toute modalité d'**effectif** ou de **fréquente** maximale. - Une série peut être **unimodale** (un seul mode) ou **multimodale** (plusieurs modes). - Si **toutes les valeurs sont uniques**, il n’y a pas de mode.::: {#exm-}Dans la série **$12, 15, 14, 10, 15, 18, 15$**, le **mode est $15$** car c'est la valeur la plus fréquente.:::### Remarque sur les mesures de tendance centrale- La **moyenne** est influencée par les valeurs extrêmes, contrairement à la **médiane**. - La **médiane** est plus robuste dans les distributions asymétriques. - Le **mode** est surtout utilisé pour des **données discrètes** ou lorsque l'on cherche une catégorie dominante.::: {.callout-tip}### Choisir la bonne mesure- **Moyenne arithmétique** : pour des données homogènes. - **Médiane** : en cas de valeurs extrêmes. - **Moyennes géométrique, harmonique, quadratique** : pour des cas spécifiques. - **Mode** : utile pour identifier les valeurs les plus courantes.:::## Paramètres de dispersionLes **paramètres de dispersion** permettent de mesurer **la variabilité des données** autour d’une valeur centrale (comme la moyenne). Ils indiquent **dans quelle mesure les valeurs sont dispersées** et aident à interpréter la distribution d’une variable.Les principaux **indicateurs de dispersion** sont :### ÉtendueL’**étendue** est la **différence entre la plus grande et la plus petite valeur** d’un ensemble de données :$$E = x_{\max} - x_{\min}.$$Elle donne une indication rapide sur l’amplitude des valeurs, mais elle est très **sensible aux valeurs extrêmes**.::: {#exm-} Soit la série **$5, 8, 12, 15, 20$**. L’étendue est :$$E = 20 - 5 = 15.$$:::### VarianceLa **variance** mesure la **moyenne des carrés des écarts** à la moyenne :$$S^2 = \dfrac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2.$$Elle est exprimée dans **le carré de l’unité des données** (ex. : si $x_i$ est en cm, $S^2$ est en cm²).::: {#exm-}Pour les données **$5, 8, 12, 15, 20$**, on calcule d'abord la moyenne :$$\bar{x} = \dfrac{5 + 8 + 12 + 15 + 20}{5} = 12.$$Puis, la variance :$$S^2 = \frac{(5-12)^2 + (8-12)^2 + (12-12)^2 + (15-12)^2 + (20-12)^2}{5}.$$$$S^2 = \frac{49 + 16 + 0 + 9 + 64}{5} = \frac{138}{5} = 27.6.$$::::::{#prp-}$$S^2=\dfrac{1}{n}\sum_{i=1}^nx_i^2-\bar{x}^2.$$::::::{.callout.tip}### Pour les données pondéréesLorsque les données sont pondérées par les poids $w_i$, on a:$$S^2 = \sum_{i=1}^nw_i\left(x_i-\bar{x}\right)^2.$$:::### Écart-typeL’**écart-type** est la **racine carrée de la variance**, il s’exprime **dans la même unité que les données** :$$S = \sqrt{S^2}.$$Il permet d’interpréter plus facilement la dispersion des valeurs.### Coefficient de variationLe **coefficient de variation** (CV) permet de comparer la dispersion entre **deux séries de données de nature différente** :$$CV = \dfrac{S}{\bar{x}} \times 100.$$Il est exprimé en **pourcentage** et indique **le degré relatif de dispersion**.::: {#exm-}- Série A : $\bar{x} = 50$, $S = 5 \Rightarrow CV = \dfrac{5}{50} \times 100 = 10\%$. - Série B : $\bar{x} = 200$, $S = 25 \Rightarrow CV = \dfrac{25}{200} \times 100 = 12.5\%$. Bien que l’écart-type de la série B soit plus grand, son **CV est plus faible**, ce qui signifie que **les valeurs sont moins dispersées par rapport à la moyenne**.:::### Intervalle interquartile et écart interquartile:::{#def-}### Quantile d'ordre $\alpha$Pour tout $\alpha\in]0,1[$, on appelle **quantile d'ordre $\alpha$** tout réel $q_{\alpha}$ qui vérifie$$\left\{\begin{array}{lll}\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq q_{\alpha}\right]}&\geq&\alpha\\\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq q_{\alpha}\right]}&\geq&1-\alpha\\\end{array}\right.$$::::::{.callout-note}Dans la pratique, pour déterminer $q_{\alpha}$, on procède comme suit:1. Déterminer les statistiques d'ordre (ranger les données dans l'ordre croisant): $$x_{(1)}\leq x_{(2)}\leq\cdots\leq x_{(n)}.$$2. Déterminer le plus petit $n_g$ tel que $$\left\{\begin{array}{lll}\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq x_{(n_g)}\right]}&\geq&\alpha\\\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq x_{(n_g)}\right]}&\geq&1-\alpha\\\end{array}\right.$$3. Déterminer le plus grand $n_d$ tel que$$\left\{\begin{array}{lll}\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\leq x_{(n_d)}\right]}&\geq&\alpha\\\dfrac{1}{n}\sum_{i=1}^n1_{\left[x_i\geq x_{(n_d)}\right]}&\geq&1-\alpha\\\end{array}\right.$$4. Prendre $q_{\alpha}=x_{(n_g)}+\alpha\left(x_{(n_d)}-x_{(n_g)}\right)$::::::{#def-}### Les quartiles- Premier quartile: $q_{\frac{1}{4}}$- Deuxième quartile (médiane): $q_{\frac{1}{2}}$- Troisième quartile: $q_{\frac{3}{4}}$::::::{.callout-note}- **$q_{\dfrac{1}{4}}$ (1er quartile)** : Valeur sous laquelle se trouvent 25% des observations.- **$q_{\dfrac{3}{4}}$ (3e quartile)** : Valeur sous laquelle se trouvent 75% des observations.::::::{#exm-}Déterminer les quartiles de la série précédente.::::::{#def-}### Intervalle inter-quartileL’**intervalle inter-quartile** est la plage contenant les **50% des valeurs centrales** d’une distribution :$$IIQ = q_{\frac{3}{4}} - q_{\frac{1}{4}}.$$:::Cet indicateur est **robuste aux valeurs extrêmes** et permet de mieux comprendre la dispersion **dans la zone centrale des données**.::: {#exm-}Série : **$5, 8, 10, 12, 15, 18, 20$** (triée). - **$q_{\frac{1}{4}}$ = 8**, **$q_{\frac{3}{4}}$ = 18** - Intervalle interquartile :$$IIQ = 18 - 8 = 10.$$::::::{.callout-note}- Posons $$\left\{\begin{array}{lll}b_-&=&q_{\frac{1}{4}}-1.5\times IIQ\\b_+&=&q_{\frac{3}{4}}+1.5\times IIQ\\\end{array}\right.$$- Les données $x_i\notin\left[b_-,b_+\right]$ sont en générale considérées comme atypiques, et sont parfois être retirées de l'étude.:::### Résumé des indicateurs| **Indicateur** | **Formule** | **Interprétation** ||---------------|------------|--------------------|| Étendue | $E = x_{\max} - x_{\min}$ | Indique la **dispersion globale**, très sensible aux valeurs extrêmes. || Variance | $S^2 = \dfrac{1}{n} \sum (x_i - \bar{x})^2$ | Mesure la **dispersion moyenne**, exprimée au carré des unités des données. || Écart-type | $S = \sqrt{S^2}$ | Indique la **dispersion absolue**, dans la même unité que les données. || Coefficient de variation | $CV = \dfrac{S}{\bar{x}} \times 100$ | Permet de comparer la **dispersion relative** entre différentes séries. || Intervalle interquartile | $IIQ = q_{\frac{3}{4}} - q_{\frac1{4}}$ | Indique la **dispersion centrale**, moins sensible aux valeurs extrêmes. |:::{.callout-tip}### Remarque sur l'interprétation des indicateurs- **Plus l’écart-type est grand**, plus les données sont dispersées autour de la moyenne.- **Un coefficient de variation élevé** indique une forte variabilité par rapport à la moyenne.- **L’intervalle interquartile** est plus robuste que l’écart-type en présence de valeurs aberrantes.:::::: {.callout-tip}### Choisir le bon indicateur- **Écart-type / Variance** : pertinents pour des données **sans valeurs extrêmes**. - **Intervalle interquartile** : recommandé pour des distributions **asymétriques ou avec valeurs aberrantes**. - **Coefficient de variation** : utile pour **comparer des distributions de natures différentes**.:::## Tableau statistique d'une série quantitative discrète### Définition et intérêtLorsqu’on dispose d’une **série quantitative discrète**, il est souvent utile de **regrouper les valeurs** sous forme d’un **tableau statistique**. Celui-ci permet de **résumer les données**, d’en faciliter l’analyse et de calculer des indicateurs statistiques.Soit une série de **$n$ individus** pour lesquels on mesure une variable quantitative discrète **$X$**, prenant **$K$ valeurs distinctes** $x_1, x_2, \dots, x_K$ (les modalités). Le **tableau statistique** associe à chaque valeur **$x_k$** son **effectif** et sa **fréquence** :| Valeur $x_i$ | Effectif $n_i$ | Fréquence $f_i$ ||--------------|---------------|----------------|| $x_1$ | $n_1$ | $f_1 = \frac{n_1}{n}$ || $x_2$ | $n_2$ | $f_2 = \frac{n_2}{n}$ || $\vdots$ | $\vdots$ | $\vdots$ || $x_K$ | $n_K$ | $f_K = \frac{n_k}{n}$ || **Total** | **$n$** | **$1$** |- $n_k$ est l'effectif de la modalité $x_k$- L'effectif total est $n=\sum_{k=1}^Kn_k$- $f_k=\dfrac{n_k}{n}$ est la proportion de la modalité $x_k$::: {#exm-}Un enseignant note **10 élèves** sur **20 points** et obtient la série : $$ 12, 15, 14, 12, 10, 15, 12, 16, 14, 15. $$On regroupe les valeurs dans un tableau :| Valeur $x_i$ | Effectif $n_i$ | Fréquence $f_i$ ||--------------|---------------|----------------|| $10$ | $1$ | $0.10$ || $12$ | $3$ | $0.30$ || $14$ | $2$ | $0.20$ || $15$ | $3$ | $0.30$ || $16$ | $1$ | $0.10$ || **Total** | **10** | **1.00** |On peut observer que **la note la plus fréquente est 12 et 15**, avec une fréquence de **30%**.:::### Interprétation du tableauUn tableau statistique permet de :1. **Visualiser les valeurs les plus fréquentes** (mode de la distribution). 2. **Faciliter les calculs de moyenne et de variance** en ajoutant une colonne $n_k\times x_k$. 3. **Identifier la distribution des données** (répartition uniforme ou non). ### Ajout des effectifs cumulésIl peut être utile d’ajouter une colonne des **effectifs cumulés croissants** pour mieux analyser la distribution :| Valeur $x_i$ | Effectif $n_k$ | Fréquence $f_k$ | Effectif cumulé $N_k$ ||--------------|---------------|----------------|---------------------|| $10$ | $1$ | $0.10$ | $1$ || $12$ | $3$ | $0.30$ | $1 + 3 = 4$ || $14$ | $2$ | $0.20$ | $4 + 2 = 6$ || $15$ | $3$ | $0.30$ | $6 + 3 = 9$ || $16$ | $1$ | $0.10$ | $9 + 1 = 10$ || **Total** | **10** | **1.00** | **10** |Les effectifs cumulés permettent de répondre rapidement aux questions comme : *"Combien d’élèves ont une note inférieure ou égale à 14 ?"* → **6 élèves**.::: {.callout-note}Un **tableau statistique** est un outil fondamental pour analyser une **série quantitative discrète**. Il permet de structurer les données, d’en faciliter la compréhension et sert de base pour les calculs statistiques (moyenne, médiane, variance, etc.).:::## Représentations graphiquesL’analyse graphique d’une **série quantitative** permet d’obtenir une **vue d’ensemble** des données et de repérer des tendances ou anomalies.Différents types de graphiques peuvent être utilisés selon le type de **données** (discrètes ou continues) et l’objectif de l’analyse.### Diagramme en bâtonsLe **diagramme en bâtons** est adapté aux **données discrètes**. Il représente chaque valeur $x_k$ par une **barre verticale** dont la hauteur est proportionnelle à son **effectif** $n_k$ ou sa **fréquence** $f_k$.:::{.callout-note}- En abscisse : les **valeurs de la variable**.- En ordonnée : les **effectifs** ou **fréquences**.- Les bâtons ne sont pas collés (contrairement à l'histogramme).:::::: {#exm-}Un enseignant note **10 élèves** et obtient la distribution suivante :| Note ($x_k$) | Effectif ($n_k$) ||-------------|----------------|| 10 | 1 || 12 | 3 || 14 | 2 || 15 | 3 || 16 | 1 |Le diagramme en bâtons permet de visualiser **les valeurs les plus fréquentes**.```{r}library(ggplot2)data <-data.frame(Note =c(10, 12, 14, 15, 16),Effectif =c(1, 3, 2, 3, 1))ggplot(data, aes(x =factor(Note), y = Effectif)) +geom_bar(stat ="identity", fill ="steelblue") +labs(title ="Diagramme en bâtons des notes",x ="Notes",y ="Effectifs") +theme_minimal()```:::### HistogrammeL’**histogramme** est adapté aux **données continues** regroupées en classes.**Construction** :- En abscisse : les **classes**.- En ordonnée : la **densité d’effectif** (effectif divisé par l’amplitude de la classe).- Les barres sont **collées** pour indiquer la continuité des données.- La surface d'une barre est proportionnelle à son effectif (ou fréquence).::: {#exm-}Soit une étude des salaires en euros avec les classes suivantes :| Classe (en euros) | Effectif ||------------------|---------|| [1000 - 2000[ | 5 || [2000 - 3000[ | 8 || [3000 - 4000[ | 6 || [4000 - 5000[ | 3 |L’histogramme permet de visualiser **la répartition des salaires** et de repérer les **classes les plus fréquentes**.```{r}library(ggplot2)data <-data.frame(Classe =factor(c("1000-2000", "2000-3000", "3000-4000", "4000-5000"),levels =c("1000-2000", "2000-3000", "3000-4000", "4000-5000")),Effectif =c(5, 8, 6, 3))ggplot(data, aes(x = Classe, y = Effectif)) +geom_histogram(stat ="identity", fill ="steelblue") +labs(title ="Histogramme des salaires",x ="Classe de salaire (euros)",y ="Effectif") +theme_minimal()```:::### Polygone des fréquencesLe **polygone des fréquences** relie les **milieux des classes** d’un histogramme par des segments.**Utilité** :- Permet une **visualisation fluide** de la distribution.- Met en évidence **les tendances générales**.:::{#exr-}```{r}library(ggplot2)data <-data.frame(Milieu =c(1500, 2500, 3500, 4500),Effectif =c(5, 8, 6, 3))ggplot(data, aes(x = Milieu, y = Effectif)) +geom_line(group =1, color ="blue", size =1) +geom_point(color ="red", size =3) +labs(title ="Polygone des fréquences",x ="Milieu de classe (euros)",y ="Effectif") +theme_minimal()```:::### Boîte à moustaches (Boxplot)La **boîte à moustaches** est un graphique adapté pour visualiser la **dispersion des données** et détecter les **valeurs extrêmes**.:::{.callout-note}- La **boîte** est délimitée par le **1er quartile ($Q_1$)** et le **3e quartile ($Q_3$)**.- La **médiane** est représentée à l’intérieur de la boîte.- Les **moustaches** s’étendent jusqu’aux valeurs extrêmes non aberrantes.- Les **valeurs aberrantes** sont indiquées par des points isolés.:::::: {#exm-}Un boxplot appliqué à des temps de course en secondes ($n = 10$) :| Temps (s) | 45 | 47 | 48 | 50 | 52 | 53 | 55 | 60 | 65 | 80 ||-----------|----|----|----|----|----|----|----|----|----|----|Le **boxplot permet d’identifier rapidement la médiane, la dispersion et les valeurs extrêmes.**```{r}library(ggplot2)data <-data.frame(Temps =c(45, 47, 48, 50, 52, 53, 55, 60, 65, 80))ggplot(data, aes(y = Temps)) +geom_boxplot(fill ="lightblue") +labs(title ="Boxplot des temps de course",y ="Temps (s)") +theme_minimal()```:::### Fonction de répartition:::{#def-}## Fonction de répartitionLa fonction de répartition, notée $F_{x_{1:n}}$, est un outil essentiel en statistique descriptive pour analyser la distribution d'un échantillon $x_1, \ldots, x_n$. Elle indique pour tout réel $x$, la proportion d'observations de l'échantillon qui sont inférieures ou égales à $x$. Cette fonction est définie pour tout réel $x$ par :$$ F_{x_{1:n}}(x) = \dfrac{\text{Nombre d'observations} \leq x}{n} = \dfrac{1}{n}\sum_{i=1}^n1_{[x_i\leq x]}. $$::::::{#prp-}## Fonction de répartition- **Criossante** : Si $x \leq y$, alors $F_{x_{1:n}}(x) \leq F_{x_{1:n}}(y)$.- **Limites** : $\lim_{x \to -\infty} F_{x_{1:n}}(x) = 0$ et $\lim_{x \to +\infty} F_{x_{1:n}}(x) = 1$.- **Continuité à droite** : $F_{x_{1:n}}$ est continue à droite en tout point $x$.::::::{#exm-}Considérons un échantillon de valeurs $x_1, \ldots, x_n$ et calculons sa fonction de répartition. Voici comment cette fonction peut être estimée et représentée en R pour un échantillon hypothétique :```{r}# Échantillon hypothétiquex <-c(2, 3, 5, 6, 7, 8, 9, 10, 11, 12)# Calcul de la fonction de répartitionFx <-ecdf(x)# Représentation graphique de la fonction de répartitionplot(Fx, xlab="x", ylab="F(x)")```:::## Remarque::: {.callout-tip}### Quel graphique choisir ?- **Données discrètes** : Diagramme en bâtons.- **Données continues** : Histogramme.- **Comparaison de distributions** : Polygone des fréquences.- **Détection des valeurs extrêmes** : Boîte à moustaches.:::## Exercices:::{#exr-} **Vrai ou Faux :**1. Une "variable" est tout caractère étudié dans une étude statistique.2. La statistique descriptive recueille les données.3. Elle résume les données via des tableaux, graphiques et indicateurs.4. Une variable quantitative mesure une qualité.5. Elle peut prendre des valeurs dans $\mathbb{N}$.6. La variance donne une idée de la valeur moyenne étudiée.7. L'écart-type s'exprime dans l'unité de la variable étudiée.8. Le mode est la modalité la moins fréquente.9. La moyenne arithmétique d'une variable qualitative est la modalité la plus fréquente.::::::{#exr-}Pour les sujets d'étude qui suivent, spécifier : l'unité statistique, la variable étuduée et son type,1. Étude du temps de validité des lampes électriques.2. Étude de l'absentéisme des ouvriers, en jours, dans une usine.3. Répartition des étudiants d'une promotion selon la mention obtenue sur le diplôme du Bac.4. On cherche à modéliser^1 le nombre de collisions impliquant deux voitures sur un ensemble de 100 intersections routières choisies au hasard dans une ville. Les données sont collectées sur une période d'un an et le nombre d'accidents pour chaque intersection est ainsi mesuré.::::::{#exr-}On considère une série statistique représentant les **revenus mensuels (en euros)** de 20 individus dans une ville donnée :$$\begin{array}{l} 1200, 1500, 1350, 1800, 2000, 2500, 1600, 1700, 1550, 1400, \\ 2100, 2200, 2300, 1900, 1950, 1750, 1850, 2600, 2700, 2800\\\end{array}$$1. **Calcul des indicateurs de tendance centrale :** a. Déterminer la moyenne arithmétique de cette série. b. Calculer la médiane et interpréter sa signification. c. Trouver le mode de la distribution (si applicable). 2. **Mesures de dispersion :** a. Calculer l'étendue de la série. b. Déterminer la variance et l'écart-type. c. Calculer le coefficient de variation et interpréter la dispersion des revenus. 3. **Étude de la fonction de répartition :** a. Construire la fonction de répartition empirique $F(x)$. b. Représenter graphiquement $F(x)$ et expliquer son comportement. c. Déterminer les quartiles de la distribution et les représenter sur la courbe de $F(x)$. 4. **Interprétation des résultats :** - Comparer la moyenne et la médiane : que peut-on dire sur la symétrie de la distribution des revenus ? - Comment la dispersion des revenus influence-t-elle l'interprétation de la moyenne ? - Quel est l'intérêt de la fonction de répartition pour la prise de décision en économie ou en gestion des revenus ? ::::::{#exr-}Les données ci-dessous représentent le tableau des effectifs du nombre de pièces par appartement. | NbreDePieces | 1 | 2 | 3 | 4 | 5 | 6 | 7 ||--------------|---|----|---|---|---|---|---|| NbreAppartements | 48 | 72 | 96 | 64 | 39 | 25 | 3 |\begin{table}[ht]\begin{center}\begin{tabular}{rrrrrrrr} \hline NbreDePieces & 1 & 2 & 3 & 4 & 5 & 6 & 7 \\ NbreAppartements & 48 & 72 & 96 & 64 & 39 & 25 & 3 \\ \hline\end{tabular}\end{center}\end{table}1. Tracer les diagrammes en bâtons des effectifs et des effectifs cumulés.2. Déterminer le mode, la moyenne, l'étendue, la variance et l'écart-type.3. Déterminer les quartiles.4. Tracer la boîte à moustaches.5. Définir et tracer la fonction de répartition.::::::{#exr-} ```{r}NbreVoitures =1:12NbreObservations =c(2, 8, 14 , 20 , 19 , 15 , 9 , 6 , 2 , 3 , 1 , 1)df =data.frame(NbreVoitures, NbreObservations)print(df)```1. Table des fréquences et diagramme en bâtons.2. Calcul de la moyenne et écart-type.3. Médiane, quartiles, box-plot.4. Étude de la symétrie.::::::{#exr-}Le gérant d’un magasin vendant des articles de consommation courante a relevé pour un article particulier qui semble connaître une très forte popularité, le nombre d’articles vendus par jour. Son relevé a porté sur les ventes des mois de Mars et Avril, ce qui correspond à $52$ jours de vente. Le relevé des observations se présente comme suit :\begin{eqnarray*}7, & 13, & 8, & 10, & 9, & 12, & 10, & 8, & 9, & 10, \\6, & 14, & 7, & 15, & 9, & 11, & 12, & 11, & 12, & 5,\\14, & 11, & 8, & 10, & 14, & 12, & 8, & 5, & 7, & 13, \\12, & 16, & 11, & 9, & 11, & 11, & 12, & 12, & 15, & 14, \\5, & 14, & 9, & 9, & 14, & 13, & 11, & 10, & 11, & 12, \\9, & 15, & & & & & & & & \\\end{eqnarray*}Analyser le nombre d'articles vendus par jour sur $52$ jours.::::::{#exr-}Les données ci-dessous sont les poids (en $kg$) de $n=50$ individus.$$\begin{array}{rrrrr}43 & 43 & 43 & 47 & 48\\48 & 48 & 48 & 49 & 49\\49 & 50 & 50 & 51 & 51\\52 & 53 & 53 & 53 & 54\\54 & 56 & 56 & 56 & 57\\59 & 59 & 59 & 62 & 62\\63 & 63 & 65 & 65 & 67\\67 & 68 & 70 & 70 & 70\\72 & 72 & 73 & 77 & 77\\81 & 83 & 86 & 92 & 93\\\end{array}$$1. Type de la variable poids.2. Moyenne, variance, écart-type.3. Tableau statistique avec classes spécifiées.4. Histogramme des effectifs, fonction de répartition.5. Quartiles et boîte à moustaches.:::