En statistique descriptive, on est souvent amené à étudier des séries quantitatives. Lorsque le nombre de données est important ou que les données sont très dispersées, il peut être utile de les regrouper par intervalles, encore appelés classes. Cette opération permet de synthétiser l’information et de faciliter l’analyse de la série.
Dans ce cours, nous allons étudier les méthodes de description statistique d’une série quantitative groupée par intervalles. Nous verrons comment calculer et interpréter les paramètres de position (moyenne, médiane, mode) et de dispersion (variance, écart-type, étendue). Nous apprendrons également à représenter graphiquement une série quantitative groupée par intervalles à l’aide d’histogrammes et de polygones des fréquences cumulées.
Exemple
Considérons la série statistique suivante, représentant les tailles (en cm) de 100 étudiants :
Taille (cm)
Effectif
[150, 160[
10
[160, 170[
25
[170, 180[
35
[180, 190[
20
[190, 200[
10
Cette série est une série quantitative groupée par intervalles. Les classes sont les intervalles [150, 160[, [160, 170[, etc. Les effectifs sont le nombre d’étudiants dont la taille appartient à chaque classe.
Définition
Soit une série quantitative continue contenant \(n\) individus, notée : \[ x_1, x_2, \dots, x_n. \]
Les valeurs sont regroupées en \(K\) intervalles ou classes notées : \[ [a_0, a_1[, [a_1, a_2[, \dots, [a_{K-1}, a_K]. \]
Chaque classe est définie par :
\(a_{k-1}, a_k\) : Bornes de la classe.
\(c_k\) : Centre de classe, défini par : \[ c_k = \dfrac{a_k + a_{k+1}}{2}. \]
\(n_k\) : Effectif de la classe (nombre d’individus appartenant à cet intervalle).
\(f_k\) : Fréquence de la classe, définie par : \[ f_k = \frac{n_k}{n}. \]
Une série quantitative regroupée en intervalles est généralement représentée sous forme d’un tableau statistique structuré comme suit :
Classes
Bornes \([a_k, a_{k+1}[\)
Centre de classe \(c_k\)
Effectif \(n_k\)
Fréquence \(f_k\)
Effectif cumulé \(N_k\)
Fréquence cumulée \(F_k\)
1
\([a_0, a_1[\)
\(c_1\)
\(n_1\)
\(f_1\)
\(N_1\)
\(F_1\)
2
\([a_1, a_2[\)
\(c_2\)
\(n_2\)
\(f_2\)
\(N_2\)
\(F_2\)
…
…
…
…
…
…
…
K
\([a_{K-1}, a_K[\)
\(c_K\)
\(n_K\)
\(f_K\)
\(N_K\)
\(F_K\)
Total
-
-
\(n\)
1
-
-
Interprétation du tableau
L’effectif \(n_k\) représente le nombre d’observations dans chaque classe.
La fréquence \(f_k\) est le rapport entre l’effectif de la classe et le total des observations.
L’effectif cumulé \(N_k\) permet de connaître le nombre d’individus ayant une valeur inférieure à la borne supérieure de la classe \(k\).
La fréquence cumulée \(F_k\) donne la proportion cumulée des observations.
Example 1 On étudie les salaires de 100 employés, regroupés en 5 classes :
Classes
Bornes (en euros)
Centre \(m_k\)
Effectif \(n_k\)
Fréquence \(f_k\)
Effectif cumulé \(N_k\)
Fréquence cumulée \(F_k\)
1
\([1000, 2000[\)
1500
15
0.15
15
0.15
2
\([2000, 3000[\)
2500
30
0.30
45
0.45
3
\([3000, 4000[\)
3500
25
0.25
70
0.70
4
\([4000, 5000[\)
4500
20
0.20
90
0.90
5
\([5000, 6000[\)
5500
10
0.10
100
1.00
Total
-
-
100
1.00
-
-
Remarque sur le choix des intervalles
Le choix du nombre de classes et de leurs bornes influence fortement l’interprétation des résultats. Il est généralement recommandé de : - Choisir un nombre raisonnable de classes (règle de Sturges : \(K \approx 1 + 3.3 \log_{10}(n)\)). - Opter pour des intervalles de même largeur sauf dans certains cas spécifiques. - Vérifier la cohérence des effectifs (éviter des classes avec très peu ou trop d’observations).
Paramètres de position
Les paramètres de position permettent de résumer la position centrale d’une série statistique. Pour une série quantitative groupée par intervalles, les principaux paramètres de position sont la moyenne, la médiane et le mode.
Moyenne arithmétique
La moyenne arithmétique d’une série quantitative groupée par intervalles est la somme des produits des centres de classe par les effectifs, divisée par l’effectif total :
\[\bar{x} = \dfrac{1}{n} \sum_{k=1}^K n_kc_k\]
où :
\(n\) est l’effectif total
\(K\) est le nombre de classes
\(c_k\) est le centre de la classe \(k\)
\(n_k\) est l’effectif de la classe \(k\)
La moyenne arithmétique est une mesure de tendance centrale qui représente la valeur moyenne des observations. Elle est sensible aux valeurs extrêmes.
Médiane
La médiane est la valeur qui sépare la population en deux groupes de même effectif. Pour une série quantitative groupée par intervalles, la médiane est estimée par interpolation linéaire dans la classe médiane, c’est-à-dire la classe qui contient l’observation médiane.
La classe médiane est la classe dont la fréquence cumulée dépasse 0,5 pour la première fois. La médiane est alors estimée par la formule :
\(a_{m-1}\) est la borne inférieure de la classe médiane
\(a_m\) est la borne supérieure de la classe médiane
\(f_m\) est la fréquence de la classe médiane
\(F_{m-1}\) est la fréquence cumulée de la classe précédant la classe médiane
La médiane est une mesure de tendance centrale robuste aux valeurs extrêmes.
Mode
Le mode est la valeur la plus fréquente de la série. Pour une série quantitative groupée par intervalles, le mode est estimé par le centre de la classe modale, c’est-à-dire la classe qui a l’effectif le plus élevé.
Le mode est une mesure de tendance centrale qui représente la valeur typique des observations. Il est utile pour les séries unimodales, c’est-à-dire les séries qui ont un seul pic.
Example 2 Reprenons l’exemple de la série statistique représentant les tailles de 100 étudiants :
Médiane : la classe médiane est [170, 180[, donc \(Me = 170 + \frac{0.5 - 0.35}{0.35} \times 10 = 174.29\) cm
Mode : la classe modale est [170, 180[, donc \(Mo = 175\) cm
Paramètres de dispersion
Les paramètres de dispersion permettent de mesurer la dispersion des valeurs d’une série statistique autour de la position centrale. Pour une série quantitative groupée par intervalles, les principaux paramètres de dispersion sont l’étendue, la variance, l’écart-type et le coefficient de variation.
Étendue
L’étendue est la différence entre la valeur maximale et la valeur minimale de la série :
\[e = x_{max} - x_{min}\]
L’étendue est une mesure simple de la dispersion, mais elle est très sensible aux valeurs extrêmes.
Variance et écart-type
La variance est la moyenne des carrés des écarts à la moyenne :
L’écart-type est la racine carrée de la variance :
\[s = \sqrt{s^2}\]
La variance et l’écart-type sont des mesures de dispersion plus robustes que l’étendue. Ils sont sensibles à toutes les valeurs de la série, mais ils sont moins affectés par les valeurs extrêmes.
Coefficient de variation
Le coefficient de variation est le rapport de l’écart-type à la moyenne :
\[CV = \dfrac{s}{\bar{x}}\]
Le coefficient de variation est une mesure de dispersion relative. Il permet de comparer la dispersion de deux séries qui n’ont pas la même unité de mesure ou la même moyenne.
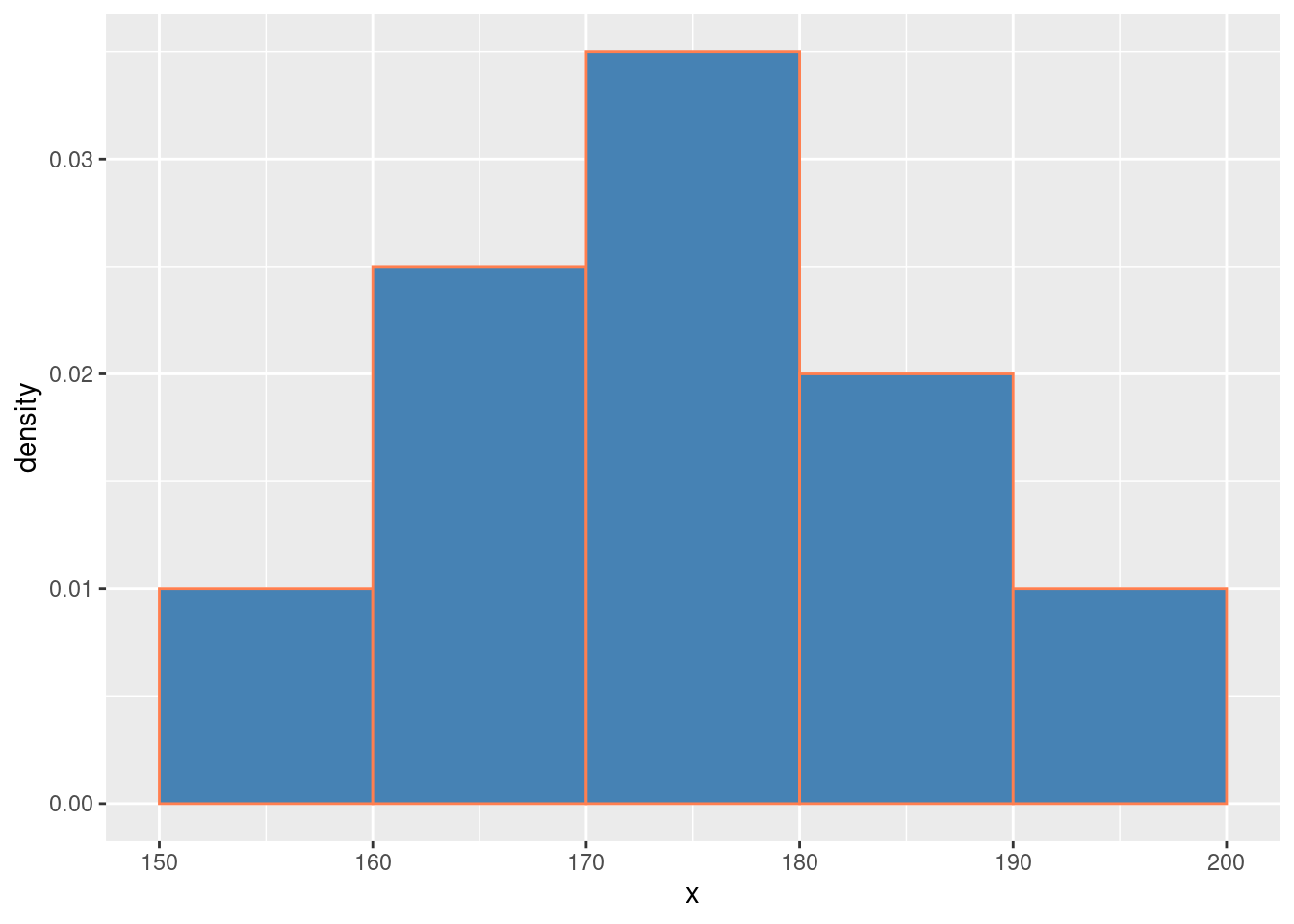
Example 3 Reprenons l’exemple de la série statistique représentant les tailles de 100 étudiants :
Coefficient de variation : \(CV = \frac{12.05}{174.5} = 0.069\)
La série des tailles des étudiants a une étendue de 50 cm, une variance de 145.25 cm\(^2\), un écart-type de 12.05 cm et un coefficient de variation de 0.069.
Example 4 Reprenons l’exemple de la série statistique représentant les tailles de \(n=100\) étudiants :
Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.
Représentations graphiques
Les représentations graphiques permettent de visualiser la distribution des données regroupées en classes. Les principales méthodes utilisées sont l’histogramme, le diagramme circulaire et la fonction de répartition.
Histogramme
L’histogramme est une représentation graphique où chaque classe est représentée par un rectangle dont :
La base correspond à l’intervalle de la classe.
La hauteur est telle que la surface du rectanle associé est proportionnelle à l’effectif ou à la densité de fréquence.
Histogramme des éffectifs
\[
h_k = \dfrac{n_k}{a_k},
\] où
\(a_k\) est l’amplitude de la classe
\(h_k\) sa hauteur
Histogramme des fréquences\[
h_k = \dfrac{f_k}{a_k}.
\]
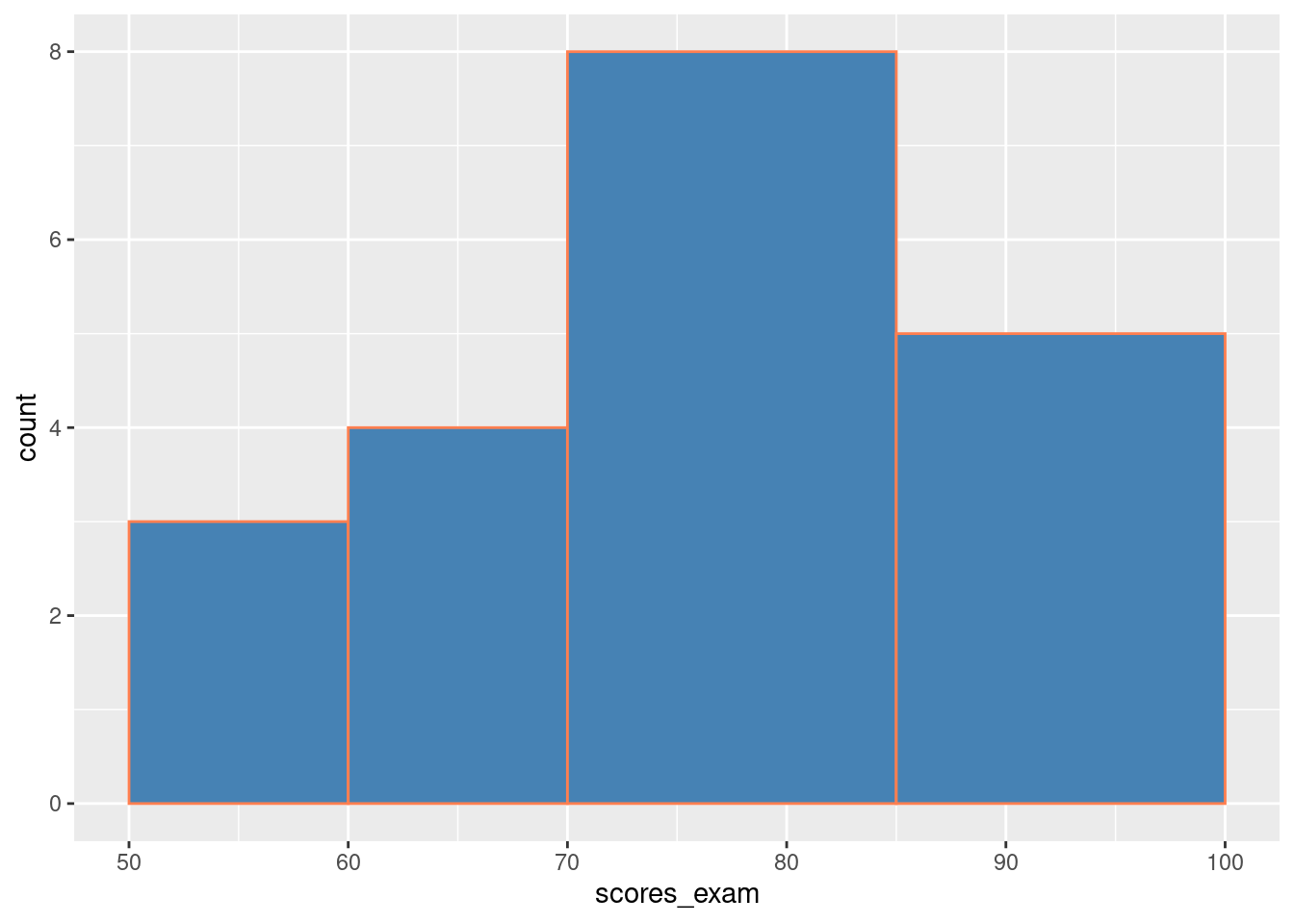
Example 5 (Scores à un examen) On considère les scores obtenus par un groupe d’étudiants lors d’un examen:
Le diagramme circulaire (ou camembert) représente les fréquences relatives sous forme de secteurs proportionnels. L’angle associé à chaque classe est donné par : \[
\alpha_k = f_k \times 360^\circ.
\]
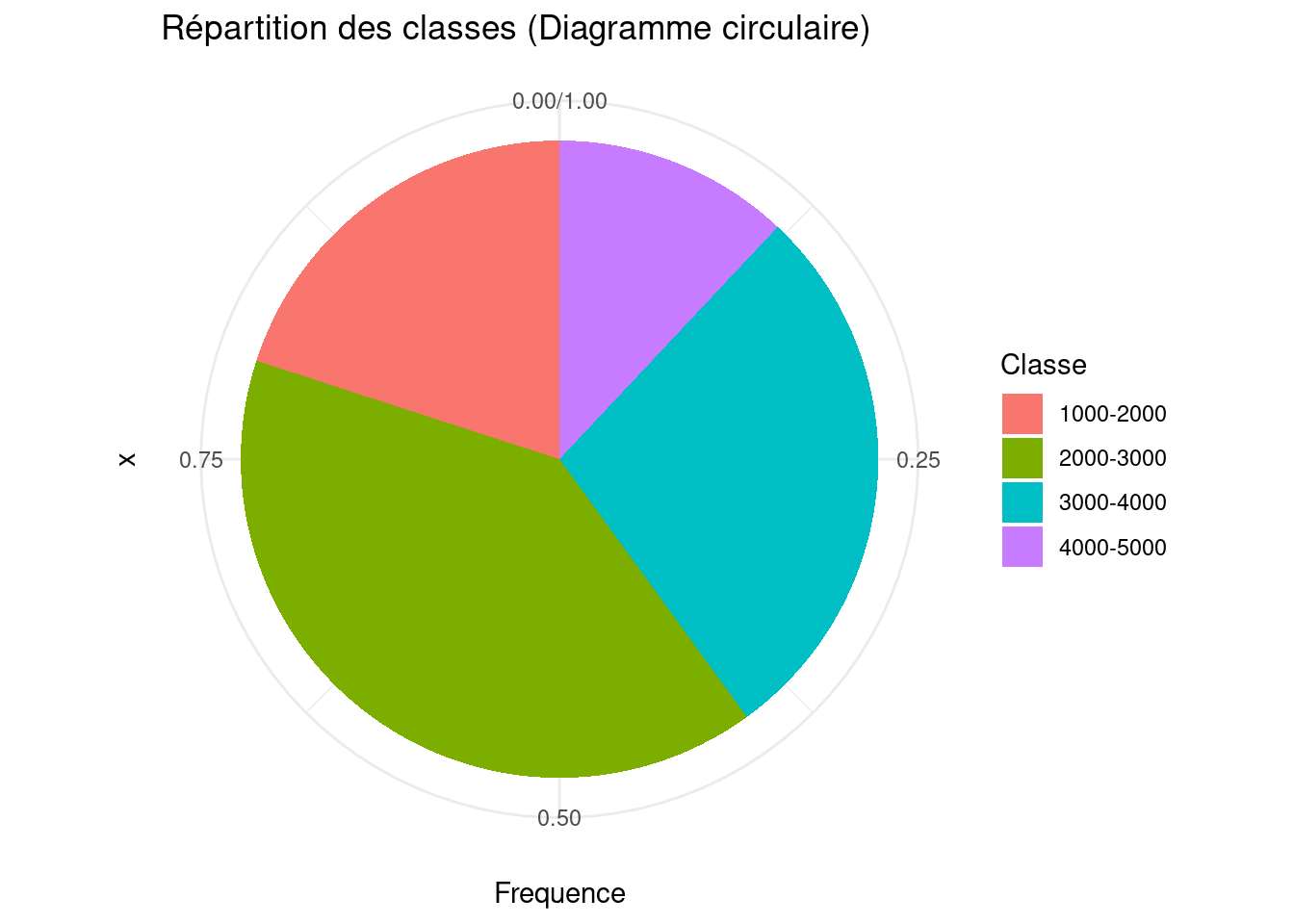
Example 6
Code
library(ggplot2)data <-data.frame(Classe =factor(c("1000-2000", "2000-3000", "3000-4000", "4000-5000"),levels =c("1000-2000", "2000-3000", "3000-4000", "4000-5000")),Effectif =c(5, 10, 7, 3))data$Frequence <- data$Effectif /sum(data$Effectif)ggplot(data, aes(x ="", y = Frequence, fill = Classe)) +geom_bar(width =1, stat ="identity") +coord_polar("y") +labs(title ="Répartition des classes (Diagramme circulaire)") +theme_minimal()
Fonction de répartition
Considérons le regroupement en intervalles selon les bornes \(b_0<b_1<\cdots<b_K\), que nous notons \(b_{0:K}\). Pour \(\left(b_{k-1}; b_k\right)\) l’intervalle, notons:
\(n_k\), son effectif;
\(f_k=\dfrac{n_k}{n}\), sa fréquence;
\(F_k = \sum_{h=1}^kf_h\), sa fréquence cumulée, avec \(F_0=0\).
Definition 1 Alors la fonction de répartition vérifie:
\(F_{b_{0:K}}(x)=0\) si \(x\leq b_0\);
\(F_{b_{0:K}}(x)=1\) si \(x\geq b_K\);
Pour tout \(x\in\left(b_{k-1}; b_k\right)\), le point \(\left(x, F_{b_{0:K}}(x)\right)\) appartient à la droite passant par \(\left(b_{k-1}, F_{k-1}\right)\) et \(\left(b_k, F_k\right)\).
Example 7 Définir et tracer la fonction de répartition associée aux données sur les scores à un examen données dans un exemple précédent.
Note
Quel graphique choisir ? - Histogramme : Visualisation de la répartition des effectifs. - Diagramme circulaire : Comparaison des proportions entre classes. - Fonction de répartition : Analyse cumulative des données.
Exercices
Exercise 1
Construction d’un tableau statistique
Un échantillon de 150 individus a été étudié en fonction de leur revenu mensuel. Complétez le tableau suivant en calculant les fréquences et les fréquences cumulées :
Classe (Revenu en €)
Effectif \(n_k\)
Fréquence \(f_k\)
Effectif cumulé \(N_k\)
Fréquence cumulée \(F_k\)
[1000-2000[
30
?
?
?
[2000-3000[
50
?
?
?
[3000-4000[
40
?
?
?
[4000-5000[
20
?
?
?
[5000-6000[
10
?
?
?
Calcul des paramètres statistiques
À partir du tableau précédent, calculez :
La moyenne arithmétique.
L’écart-type.
La médiane estimée.
La classe modale et le mode estimé.
Représentation graphique et analyse
À l’aide de ggplot2, réalisez les graphiques suivants :
Un histogramme représentant la répartition des revenus.
Un diagramme circulaire illustrant les proportions de chaque classe.
Une courbe de répartition cumulative.
Interprétez ces graphiques en expliquant la tendance centrale et la dispersion des revenus.
Exercise 2 On pèse les 50 élèves d’une classe et nous obtenons les résultats résumés dans le tableau suivant :
43
43
43
47
48
48
48
48
49
49
49
50
50
51
51
52
53
53
53
54
54
56
56
56
57
59
59
59
62
62
63
63
65
65
67
67
68
70
70
70
72
72
73
77
77
81
83
86
92
93
De quel type est la variable poids ?
Construisez le tableau statistique en adoptant les classes suivantes :
[40;45] [45;50] [50;55] [55;60] [60;65] [65;70] [70;80] [80;100]
Construisez l’histogramme des effectifs ainsi que la fonction de répartition.
Exercise 3 (Salaires des employés) Le tableau ci-dessous présente la répartition des salaires mensuels (en euros) des employés d’une entreprise :
Salaire (euros)
Effectif
[1500, 2000[
20
[2000, 2500[
30
[2500, 3000[
25
[3000, 3500[
15
[3500, 4000[
10
Calculer la moyenne et la médiane des salaires.
Calculer l’écart-type des salaires.
Représenter graphiquement la répartition des salaires à l’aide d’un histogramme.
Exercise 4 (Notes à un examen) Les notes obtenues par 100 étudiants à un examen sont réparties comme suit :
Note
Effectif
[0, 5[
10
[5, 10[
20
[10, 15[
40
[15, 20[
30
Calculer la moyenne et la médiane des notes.
Calculer l’écart-type des notes.
Représenter graphiquement la répartition des notes à l’aide d’un histogramme et d’un polygone des fréquences cumulées.
Exercise 5 (Temps de trajet domicile-travail) Le temps de trajet domicile-travail (en minutes) de 50 employés est réparti comme suit :
Temps (minutes)
Effectif
[0, 15[
5
[15, 30[
15
[30, 45[
20
[45, 60[
10
Calculer la moyenne et la médiane du temps de trajet.
Calculer l’écart-type du temps de trajet.
Représenter graphiquement la répartition du temps de trajet à l’aide d’un histogramme et d’une boîte à moustaches.
Exercise 6 (Âge des clients d’un magasin) L’âge des clients d’un magasin est réparti comme suit :
Âge
Effectif
[18, 25[
30
[25, 35[
40
[35, 50[
20
[50, 70[
10
Calculer la moyenne
Calculer l’écart-type de l’âge des clients.
Représenter graphiquement la répartition de l’âge des clients à l’aide d’un histogramme et d’un diagramme en bâtons.
Définir et tracer la fonction de répartition.
Déterminer les quartiles.
Exercise 7 (Production de pièces) Le nombre de pièces produites par jour par une machine est réparti comme suit :
Production
Effectif
[100, 120[
10
[120, 140[
20
[140, 160[
30
[160, 180[
20
[180, 200[
10
Calculer la moyenne et la médiane de la production.
Calculer l’écart-type de la production.
Représenter graphiquement la répartition de la production à l’aide d’un histogramme et d’un diagramme circulaire.
Source Code
---title: "Description d'une Série Quantitative Regroupée en Intervalles"---## IntroductionEn statistique descriptive, on est souvent amené à étudier des séries quantitatives. Lorsque le nombre de données est important ou que les données sont très dispersées, il peut être utile de les regrouper par **intervalles**, encore appelés **classes**. Cette opération permet de synthétiser l'information et de faciliter l'analyse de la série.Dans ce cours, nous allons étudier les méthodes de description statistique d'une série quantitative groupée par intervalles. Nous verrons comment calculer et interpréter les paramètres de position (moyenne, médiane, mode) et de dispersion (variance, écart-type, étendue). Nous apprendrons également à représenter graphiquement une série quantitative groupée par intervalles à l'aide d'histogrammes et de polygones des fréquences cumulées.### ExempleConsidérons la série statistique suivante, représentant les tailles (en cm) de 100 étudiants :| Taille (cm) | Effectif ||---|---|| [150, 160[ | 10 || [160, 170[ | 25 || [170, 180[ | 35 || [180, 190[ | 20 || [190, 200[ | 10 |Cette série est une série quantitative groupée par intervalles. Les classes sont les intervalles [150, 160[, [160, 170[, etc. Les effectifs sont le nombre d'étudiants dont la taille appartient à chaque classe.### DéfinitionSoit une **série quantitative continue** contenant **$n$ individus**, notée :$$ x_1, x_2, \dots, x_n. $$Les valeurs sont regroupées en **$K$ intervalles** ou **classes** notées :$$ [a_0, a_1[, [a_1, a_2[, \dots, [a_{K-1}, a_K]. $$Chaque classe est définie par :- **$a_{k-1}, a_k$** : Bornes de la classe.- **$c_k$** : Centre de classe, défini par : $$ c_k = \dfrac{a_k + a_{k+1}}{2}. $$- **$n_k$** : Effectif de la classe (nombre d’individus appartenant à cet intervalle).- **$f_k$** : Fréquence de la classe, définie par : $$ f_k = \frac{n_k}{n}. $$- **$N_k$** : Effectif cumulé croissant : $$ N_k = \sum_{i=1}^{k} n_i. $$- **$F_k$** : Fréquence cumulée croissante : $$ F_k = \sum_{i=1}^{k} f_i. $$## Construction du tableau statistiqueUne série quantitative regroupée en intervalles est généralement représentée sous forme d’un **tableau statistique** structuré comme suit :| Classes | Bornes $[a_k, a_{k+1}[$ | Centre de classe $c_k$ | Effectif $n_k$ | Fréquence $f_k$ | Effectif cumulé $N_k$ | Fréquence cumulée $F_k$ ||---------|----------------------|-----------------|--------------|----------------|---------------------|----------------------|| 1 | $[a_0, a_1[$ | $c_1$ | $n_1$ | $f_1$ | $N_1$ | $F_1$ || 2 | $[a_1, a_2[$ | $c_2$ | $n_2$ | $f_2$ | $N_2$ | $F_2$ || ... | ... | ... | ... | ... | ... | ... || K | $[a_{K-1}, a_K[$ | $c_K$ | $n_K$ | $f_K$ | $N_K$ | $F_K$ || **Total** | - | - | **$n$** | **1** | - | - |### Interprétation du tableau- **L’effectif $n_k$** représente le nombre d’observations dans chaque classe.- **La fréquence $f_k$** est le rapport entre l’effectif de la classe et le total des observations.- **L’effectif cumulé $N_k$** permet de connaître le nombre d’individus ayant une valeur inférieure à la borne supérieure de la classe $k$.- **La fréquence cumulée $F_k$** donne la proportion cumulée des observations.::: {#exm-}On étudie les salaires de **100 employés**, regroupés en 5 classes :| Classes | Bornes (en euros) | Centre $m_k$ | Effectif $n_k$ | Fréquence $f_k$ | Effectif cumulé $N_k$ | Fréquence cumulée $F_k$ ||---------|------------------|-------------|--------------|----------------|---------------------|----------------------|| 1 | $[1000, 2000[$ | 1500 | 15 | 0.15 | 15 | 0.15 || 2 | $[2000, 3000[$ | 2500 | 30 | 0.30 | 45 | 0.45 || 3 | $[3000, 4000[$ | 3500 | 25 | 0.25 | 70 | 0.70 || 4 | $[4000, 5000[$ | 4500 | 20 | 0.20 | 90 | 0.90 || 5 | $[5000, 6000[$ | 5500 | 10 | 0.10 | 100 | 1.00 || **Total** | - | - | **100** | **1.00** | - | - |:::### Remarque sur le choix des intervallesLe choix du **nombre de classes** et de leurs **bornes** influence fortement l’interprétation des résultats. Il est généralement recommandé de :- **Choisir un nombre raisonnable de classes** (règle de Sturges : $K \approx 1 + 3.3 \log_{10}(n)$).- **Opter pour des intervalles de même largeur** sauf dans certains cas spécifiques.- **Vérifier la cohérence des effectifs** (éviter des classes avec très peu ou trop d’observations).## Paramètres de positionLes paramètres de position permettent de résumer la position centrale d'une série statistique. Pour une série quantitative groupée par intervalles, les principaux paramètres de position sont la moyenne, la médiane et le mode.### Moyenne arithmétiqueLa moyenne arithmétique d'une série quantitative groupée par intervalles est la somme des produits des centres de classe par les effectifs, divisée par l'effectif total :$$\bar{x} = \dfrac{1}{n} \sum_{k=1}^K n_kc_k$$où :* $n$ est l'effectif total* $K$ est le nombre de classes* $c_k$ est le centre de la classe $k$* $n_k$ est l'effectif de la classe $k$La moyenne arithmétique est une mesure de tendance centrale qui représente la valeur moyenne des observations. Elle est sensible aux valeurs extrêmes.### MédianeLa médiane est la valeur qui sépare la population en deux groupes de même effectif. Pour une série quantitative groupée par intervalles, la médiane est estimée par interpolation linéaire dans la classe médiane, c'est-à-dire la classe qui contient l'observation médiane.La classe médiane est la classe dont la fréquence cumulée dépasse 0,5 pour la première fois. La médiane est alors estimée par la formule :$$Me = a_{m-1} + \dfrac{0.5 - F_{m-1}}{f_m} \times (a_m - a_{m-1})$$où :* $a_{m-1}$ est la borne inférieure de la classe médiane* $a_m$ est la borne supérieure de la classe médiane* $f_m$ est la fréquence de la classe médiane* $F_{m-1}$ est la fréquence cumulée de la classe précédant la classe médianeLa médiane est une mesure de tendance centrale robuste aux valeurs extrêmes.### ModeLe mode est la valeur la plus fréquente de la série. Pour une série quantitative groupée par intervalles, le mode est estimé par le centre de la **classe modale**, c'est-à-dire la classe qui a l'effectif le plus élevé.Le mode est une mesure de tendance centrale qui représente la valeur typique des observations. Il est utile pour les séries unimodales, c'est-à-dire les séries qui ont un seul pic.:::{#exm-}Reprenons l'exemple de la série statistique représentant les tailles de 100 étudiants :| Taille (cm) | Effectif | Centre de classe ||---|---|---|| [150, 160[ | 10 | 155 || [160, 170[ | 25 | 165 || [170, 180[ | 35 | 175 || [180, 190[ | 20 | 185 || [190, 200[ | 10 | 195 |* Moyenne : $\bar{x} = \frac{1}{100} (155 \times 10 + 165 \times 25 + 175 \times 35 + 185 \times 20 + 195 \times 10) = 174.5$ cm* Médiane : la classe médiane est [170, 180[, donc $Me = 170 + \frac{0.5 - 0.35}{0.35} \times 10 = 174.29$ cm* Mode : la classe modale est [170, 180[, donc $Mo = 175$ cm:::## Paramètres de dispersionLes paramètres de dispersion permettent de mesurer la dispersion des valeurs d'une série statistique autour de la position centrale. Pour une série quantitative groupée par intervalles, les principaux paramètres de dispersion sont l'étendue, la variance, l'écart-type et le coefficient de variation.### ÉtendueL'étendue est la différence entre la valeur maximale et la valeur minimale de la série :$$e = x_{max} - x_{min}$$L'étendue est une mesure simple de la dispersion, mais elle est très sensible aux valeurs extrêmes.### Variance et écart-typeLa variance est la moyenne des carrés des écarts à la moyenne :$$s^2 = \dfrac{1}{n} \sum_{k=1}^K n_k (c_k - \bar{x})^2$$L'écart-type est la racine carrée de la variance :$$s = \sqrt{s^2}$$La variance et l'écart-type sont des mesures de dispersion plus robustes que l'étendue. Ils sont sensibles à toutes les valeurs de la série, mais ils sont moins affectés par les valeurs extrêmes.### Coefficient de variationLe coefficient de variation est le rapport de l'écart-type à la moyenne :$$CV = \dfrac{s}{\bar{x}}$$Le coefficient de variation est une mesure de dispersion relative. Il permet de comparer la dispersion de deux séries qui n'ont pas la même unité de mesure ou la même moyenne.:::{#exm-}Reprenons l'exemple de la série statistique représentant les tailles de 100 étudiants :| Taille (cm) | Effectif | Centre de classe ||---|---|---|| [150, 160[ | 10 | 155 || [160, 170[ | 25 | 165 || [170, 180[ | 35 | 175 || [180, 190[ | 20 | 185 || [190, 200[ | 10 | 195 |* Étendue : $e = 200 - 150 = 50$ cm* Variance : $s^2 = \frac{1}{100} (10 \times (155 - 174.5)^2 + 25 \times (165 - 174.5)^2 + 35 \times (175 - 174.5)^2 + 20 \times (185 - 174.5)^2 + 10 \times (195 - 174.5)^2) = 145.25$ cm$^2$* Écart-type : $s = \sqrt{145.25} = 12.05$ cm* Coefficient de variation : $CV = \frac{12.05}{174.5} = 0.069$La série des tailles des étudiants a une étendue de 50 cm, une variance de 145.25 cm$^2$, un écart-type de 12.05 cm et un coefficient de variation de 0.069.::::::{#exm-}Reprenons l'exemple de la série statistique représentant les tailles de $n=100$ étudiants :| Taille (cm) | Effectif | Centre de classe ||---|---|---|| [150, 160[ | 10 | 155 || [160, 170[ | 25 | 165 || [170, 180[ | 35 | 175 || [180, 190[ | 20 | 185 || [190, 200[ | 10 | 195 |Traçons l'histogramme des fréquences.```{r}require(ggplot2)x =c(rep(155, 10), rep(165, 25), rep(175, 35), rep(185, 20), rep(195, 10))ggplot(mapping =aes(x=x, y=..density..)) +geom_histogram(color ="coral", fill ="steelblue", breaks =c(150, 160, 170, 180, 190, 200), closed ="left")```:::## Représentations graphiquesLes représentations graphiques permettent de visualiser la distribution des données regroupées en classes. Les principales méthodes utilisées sont l’**histogramme**, le **diagramme circulaire** et la **fonction de répartition**.### HistogrammeL’**histogramme** est une représentation graphique où chaque classe est représentée par un rectangle dont :- La **base** correspond à l’intervalle de la classe.- La **hauteur** est telle que la surface du rectanle associé est proportionnelle à l’effectif ou à la densité de fréquence.**Histogramme des éffectifs**$$h_k = \dfrac{n_k}{a_k},$$où - $a_k$ est l’amplitude de la classe- $h_k$ sa hauteur- **Histogramme des fréquences**$$h_k = \dfrac{f_k}{a_k}.$$:::{#exm-}## Scores à un examenOn considère les scores obtenus par un groupe d'étudiants lors d'un examen:```{r}require(ggplot2)scores_exam <-c(55, 70, 68, 82, 90, 74, 61, 77, 85, 93, 69, 70, 75, 88, 92, 56, 65, 74, 58, 80)ggplot(mapping =aes(x=scores_exam, )) +geom_histogram(color ="coral", fill ="steelblue", breaks =c(50, 60, 70, 85, 100), closed ="left", )```:::### Diagramme circulaireLe **diagramme circulaire** (ou camembert) représente les **fréquences relatives** sous forme de secteurs proportionnels.L’angle associé à chaque classe est donné par :$$\alpha_k = f_k \times 360^\circ.$$:::{#exm-}```{r}library(ggplot2)data <-data.frame(Classe =factor(c("1000-2000", "2000-3000", "3000-4000", "4000-5000"),levels =c("1000-2000", "2000-3000", "3000-4000", "4000-5000")),Effectif =c(5, 10, 7, 3))data$Frequence <- data$Effectif /sum(data$Effectif)ggplot(data, aes(x ="", y = Frequence, fill = Classe)) +geom_bar(width =1, stat ="identity") +coord_polar("y") +labs(title ="Répartition des classes (Diagramme circulaire)") +theme_minimal()```:::### Fonction de répartitionConsidérons le regroupement en intervalles selon les bornes $b_0<b_1<\cdots<b_K$, que nous notons $b_{0:K}$. Pour $\left(b_{k-1}; b_k\right)$ l'intervalle, notons:- $n_k$, son effectif;- $f_k=\dfrac{n_k}{n}$, sa fréquence;- $F_k = \sum_{h=1}^kf_h$, sa fréquence cumulée, avec $F_0=0$.:::{#def-}Alors la fonction de répartition vérifie:- $F_{b_{0:K}}(x)=0$ si $x\leq b_0$;- $F_{b_{0:K}}(x)=1$ si $x\geq b_K$;- Pour tout $x\in\left(b_{k-1}; b_k\right)$, le point $\left(x, F_{b_{0:K}}(x)\right)$ appartient à la droite passant par $\left(b_{k-1}, F_{k-1}\right)$ et $\left(b_k, F_k\right)$.::::::{#exm-}Définir et tracer la fonction de répartition associée aux données sur les scores à un examen données dans un exemple précédent.::::::{.callout-note}**Quel graphique choisir ?**- **Histogramme** : Visualisation de la répartition des effectifs.- **Diagramme circulaire** : Comparaison des proportions entre classes.- **Fonction de répartition** : Analyse cumulative des données.:::## Exercices:::{#exr-}1. **Construction d'un tableau statistique** Un échantillon de **150 individus** a été étudié en fonction de leur revenu mensuel. Complétez le tableau suivant en calculant les fréquences et les fréquences cumulées : | Classe (Revenu en €) | Effectif $n_k$ | Fréquence $f_k$ | Effectif cumulé $N_k$ | Fréquence cumulée $F_k$ | |----------------------|---------------|----------------|-----------------|-----------------| | [1000-2000[ | 30 | ? | ? | ? | | [2000-3000[ | 50 | ? | ? | ? | | [3000-4000[ | 40 | ? | ? | ? | | [4000-5000[ | 20 | ? | ? | ? | | [5000-6000[ | 10 | ? | ? | ? |2. **Calcul des paramètres statistiques** À partir du tableau précédent, calculez : - La **moyenne arithmétique**. - L’**écart-type**. - La **médiane estimée**. - La **classe modale et le mode estimé**.3. **Représentation graphique et analyse** À l’aide de **ggplot2**, réalisez les graphiques suivants : - Un **histogramme** représentant la répartition des revenus. - Un **diagramme circulaire** illustrant les proportions de chaque classe. - Une **courbe de répartition cumulative**. Interprétez ces graphiques en expliquant la tendance centrale et la dispersion des revenus.::::::{#exr-}On pèse les 50 élèves d'une classe et nous obtenons les résultats résumés dans le tableau suivant :|||||||-----|-----|-----|-----|-----|| 43 | 43 | 43 | 47 | 48 || 48 | 48 | 48 | 49 | 49 || 49 | 50 | 50 | 51 | 51 || 52 | 53 | 53 | 53 | 54 || 54 | 56 | 56 | 56 | 57 || 59 | 59 | 59 | 62 | 62 || 63 | 63 | 65 | 65 | 67 || 67 | 68 | 70 | 70 | 70 || 72 | 72 | 73 | 77 | 77 || 81 | 83 | 86 | 92 | 93 |1. De quel type est la variable poids ?2. Construisez le tableau statistique en adoptant les classes suivantes : \[40;45\]\[45;50\]\[50;55\]\[55;60\]\[60;65\]\[65;70\]\[70;80\]\[80;100\]3. Construisez l'histogramme des effectifs ainsi que la fonction de répartition.::::::{#exr-}## Salaires des employésLe tableau ci-dessous présente la répartition des salaires mensuels (en euros) des employés d'une entreprise :| Salaire (euros) | Effectif ||---|---|| [1500, 2000[ | 20 || [2000, 2500[ | 30 || [2500, 3000[ | 25 || [3000, 3500[ | 15 || [3500, 4000[ | 10 |1. Calculer la moyenne et la médiane des salaires.2. Calculer l'écart-type des salaires.3. Représenter graphiquement la répartition des salaires à l'aide d'un histogramme.::::::{#exr-}## Notes à un examenLes notes obtenues par 100 étudiants à un examen sont réparties comme suit :| Note | Effectif ||---|---|| [0, 5[ | 10 || [5, 10[ | 20 || [10, 15[ | 40 || [15, 20[ | 30 |1. Calculer la moyenne et la médiane des notes.2. Calculer l'écart-type des notes.3. Représenter graphiquement la répartition des notes à l'aide d'un histogramme et d'un polygone des fréquences cumulées.::::::{#exr-}## Temps de trajet domicile-travailLe temps de trajet domicile-travail (en minutes) de 50 employés est réparti comme suit :| Temps (minutes) | Effectif ||---|---|| [0, 15[ | 5 || [15, 30[ | 15 || [30, 45[ | 20 || [45, 60[ | 10 |1. Calculer la moyenne et la médiane du temps de trajet.2. Calculer l'écart-type du temps de trajet.3. Représenter graphiquement la répartition du temps de trajet à l'aide d'un histogramme et d'une boîte à moustaches.::::::{#exr-}## Âge des clients d'un magasinL'âge des clients d'un magasin est réparti comme suit :| Âge | Effectif ||---|---|| [18, 25[ | 30 || [25, 35[ | 40 || [35, 50[ | 20 || [50, 70[ | 10 |1. Calculer la moyenne2. Calculer l'écart-type de l'âge des clients.3. Représenter graphiquement la répartition de l'âge des clients à l'aide d'un histogramme et d'un diagramme en bâtons.4. Définir et tracer la fonction de répartition.5. Déterminer les quartiles.::::::{#exr-}## Production de piècesLe nombre de pièces produites par jour par une machine est réparti comme suit :| Production | Effectif ||---|---|| [100, 120[ | 10 || [120, 140[ | 20 || [140, 160[ | 30 || [160, 180[ | 20 || [180, 200[ | 10 |1. Calculer la moyenne et la médiane de la production.2. Calculer l'écart-type de la production.3. Représenter graphiquement la répartition de la production à l'aide d'un histogramme et d'un diagramme circulaire.:::