Dans le cadre de l’analyse bivariée, nous travaillons avec des données qui se présentent sous la forme d’une série de couples \((x_i, y_i)\), où :
\(x_i\) représente la valeur de la variable \(X\) pour l’individu \(i\).
\(y_i\) représente la valeur de la variable \(Y\) pour le même individu \(i\).
\(i\) varie de 1 à \(n\), où \(n\) est le nombre total d’observations ou d’individus.
Cette structure de données nous permet d’étudier la façon dont les variables \(X\) et \(Y\) varient conjointement.
Le Nuage de Points : Visualisation des Relations Quantitatives
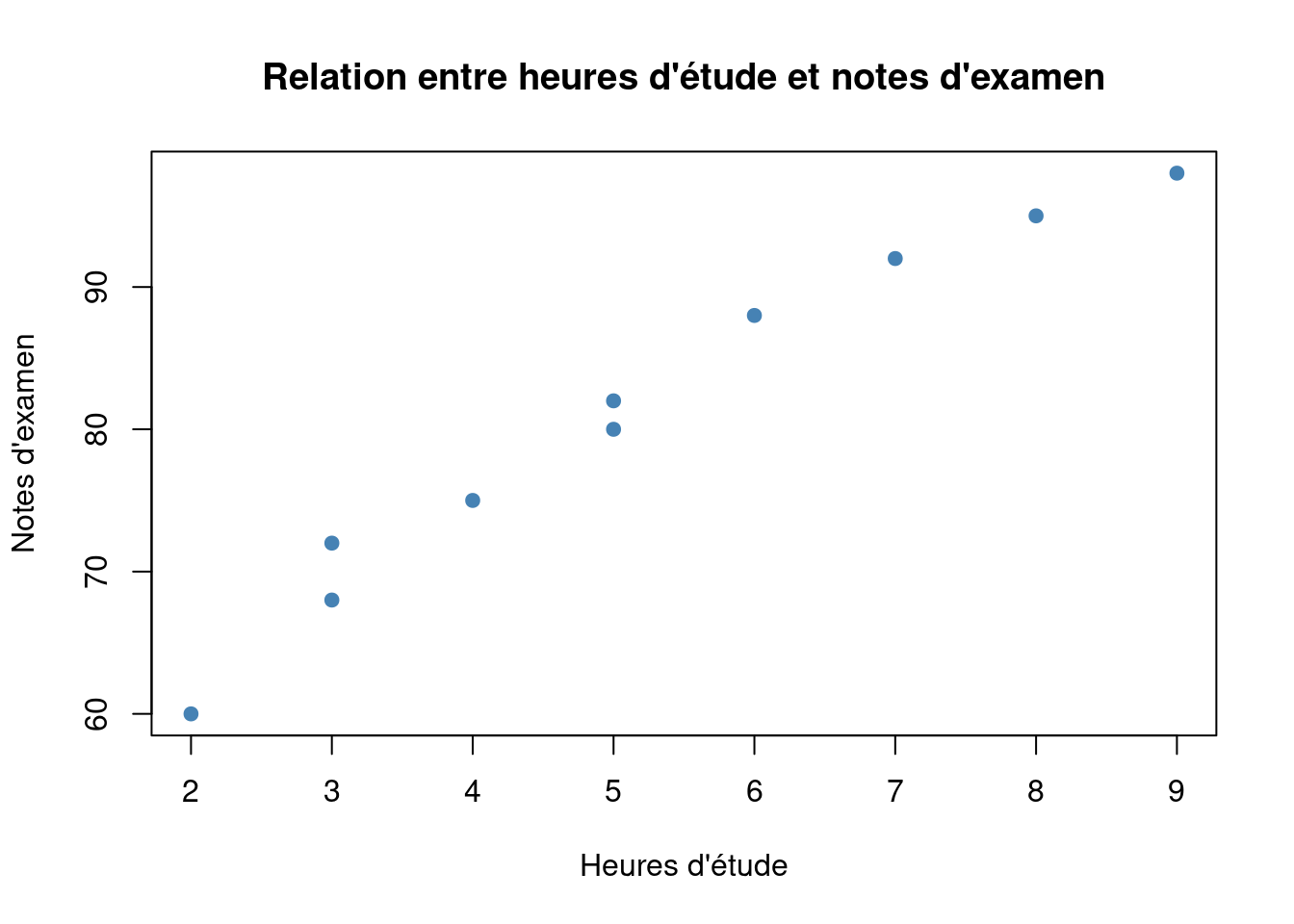
Lorsque nous avons deux variables quantitatives, le nuage de points (ou diagramme de dispersion) est un outil essentiel pour visualiser leur relation.
Construction : Chaque couple \((x_i, y_i)\) est représenté par un point dans un plan cartésien, où l’axe des abscisses représente la variable \(X\) et l’axe des ordonnées représente la variable \(Y\).
Interprétation :
La forme générale du nuage de points peut révéler la présence d’une relation linéaire, non linéaire, ou l’absence de relation.
La direction de la relation (positive ou négative) peut être observée.
La dispersion des points autour d’une éventuelle tendance peut indiquer la force de la relation.
Les valeurs aberrantes (points éloignés des autres) peuvent être identifiées.
Example 1 Imaginons une étude sur la relation entre le nombre d’heures d’étude (\(X\)) et la note obtenue à un examen (\(Y\)). Les données pourraient se présenter comme suit : \((2, 65)\), \((3, 70)\), \((4, 80)\), \((5, 90)\).
Code
# Exemple de données bivariées (heures d'étude, notes d'examen)heures_etude <-c(2, 3, 4, 5, 6, 7, 8, 3, 5, 9)notes_examen <-c(60, 68, 75, 82, 88, 92, 95, 72, 80, 98)# Nuage de pointsplot(heures_etude, notes_examen,main ="Relation entre heures d'étude et notes d'examen",xlab ="Heures d'étude",ylab ="Notes d'examen", pch=20, col="steelblue", lwd=3)
Les Tableaux de Contingence : Analyse des Relations Qualitatives
Tableau de contingence
Lorsque nous avons deux variables qualitatives, les tableaux de contingence (ou tableaux croisés) sont utilisés pour analyser leur relation.
Construction : Les lignes du tableau représentent les catégories de l’une des variables, et les colonnes représentent les catégories de l’autre variable. Chaque cellule du tableau contient le nombre d’observations qui appartiennent à la fois à la catégorie de la ligne et à la catégorie de la colonne.
Interprétation :
Les fréquences marginales (sommes des lignes et des colonnes) donnent des informations sur la distribution de chaque variable individuellement.
Les fréquences conditionnelles (pourcentages dans les lignes ou les colonnes) permettent de comparer les distributions des variables selon les catégories de l’autre variable.
Les écarts entre les fréquences observées et les fréquences attendues en cas d’indépendance peuvent indiquer la présence d’une association entre les variables.
Représentations Graphiques
Pour visualiser les informations contenues dans un tableau de contingence, plusieurs types de graphiques peuvent être utilisés :
Diagrammes en barres groupées ou empilées :
Permettent de comparer les fréquences ou les pourcentages de chaque catégorie d’une variable pour chaque catégorie de l’autre variable.
Par exemple, on peut comparer le nombre d’hommes et de femmes qui préfèrent chaque type de film (comédie ou drame).
Diagrammes en mosaïque :
Représentent visuellement les tableaux de contingence en utilisant des rectangles dont la taille est proportionnelle aux fréquences observées. Permettent de visualiser facilement les relations entre les variables, en mettant en évidence les écarts par rapport à l’indépendance.
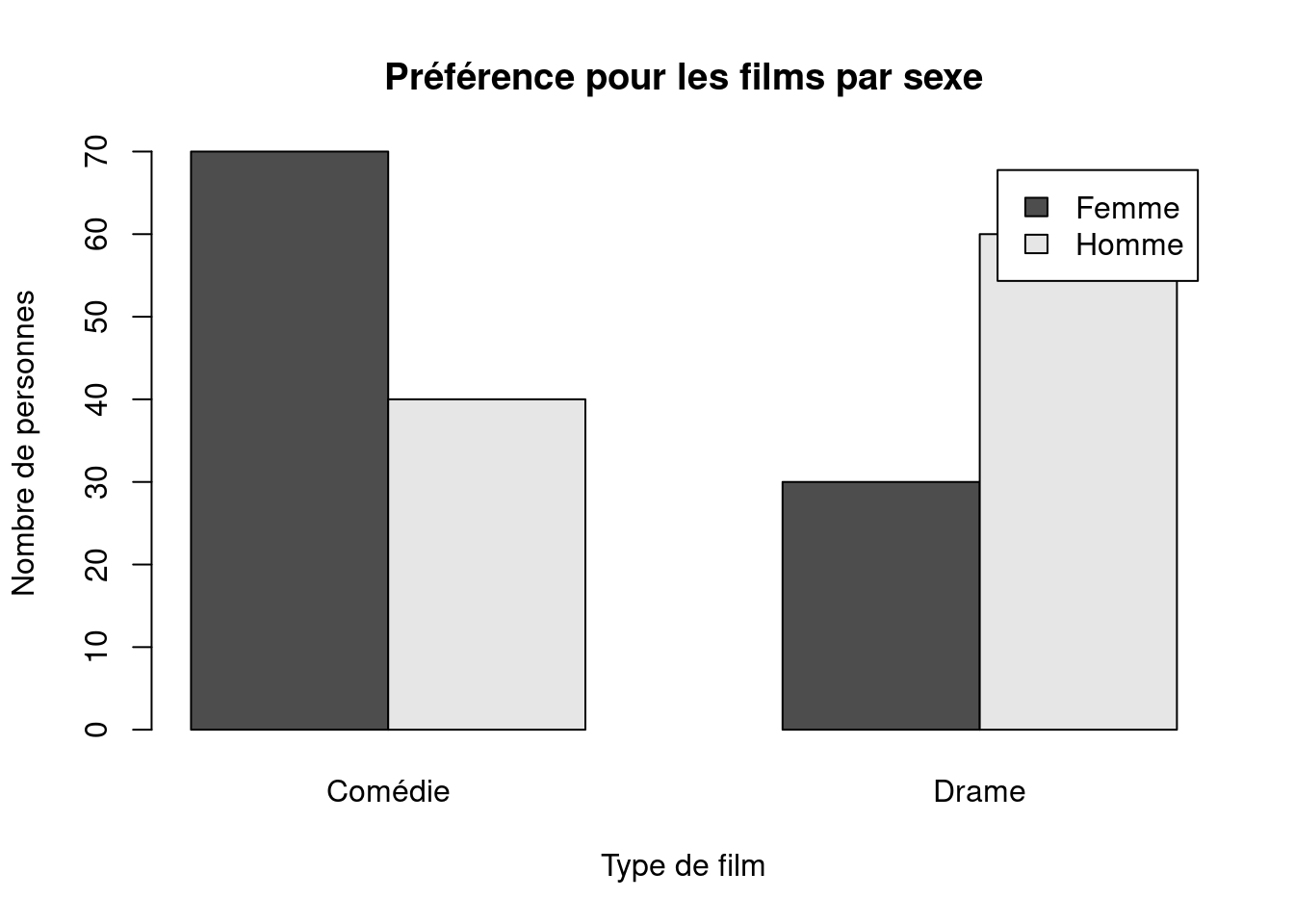
Example 2 Imaginons une étude sur la relation entre le sexe (homme/femme) et la préférence pour un type de film (comédie/drame). Un tableau de contingence pourrait se présenter comme suit :
Sexe
Comédie
Drame
Total
Homme
40
60
100
Femme
70
30
100
Total
110
90
200
Code
# Exemple de tableau de contingence (sexe, préférence pour les films)donnees_films <-data.frame(sexe =rep(c("Homme", "Femme"), c(100, 100)),preference =c(rep("Comédie", 40), rep("Drame", 60),rep("Comédie", 70), rep("Drame", 30)))tableau_contingence <-table(donnees_films$sexe, donnees_films$preference)print(tableau_contingence)
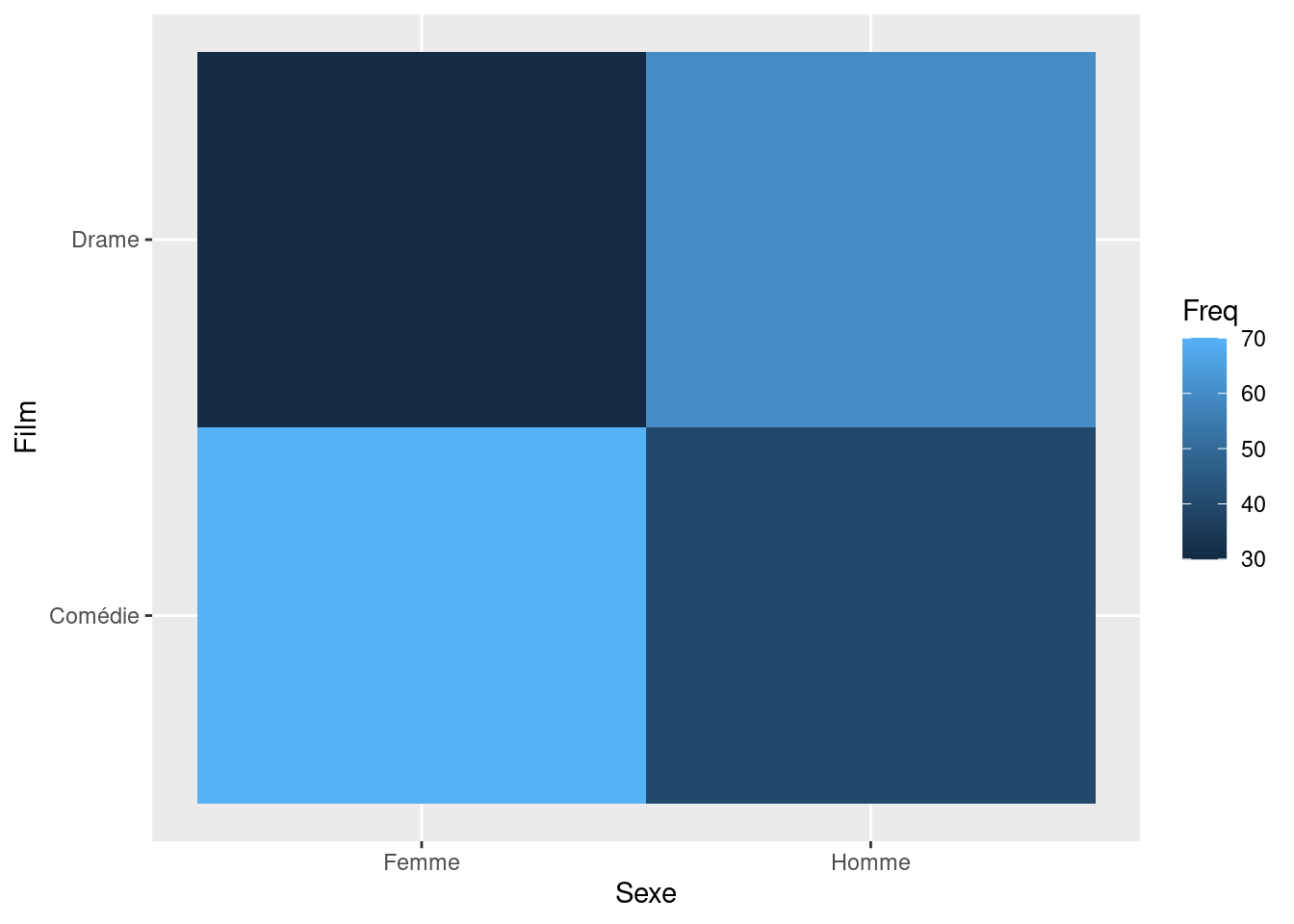
Comédie Drame
Femme 70 30
Homme 40 60
Diagramme ;à barres groupés
Code
# Diagramme en barres groupéesbarplot(tableau_contingence, beside =TRUE,legend.text =TRUE,main ="Préférence pour les films par sexe",xlab ="Type de film",ylab ="Nombre de personnes")
Diagramme en mosaïques
Code
# Diagramme en mosaïquemosaicplot(tableau_contingence,main ="Préférence pour les films par sexe",color =TRUE)
Heatmap
Code
require(ggplot2)
Le chargement a nécessité le package : ggplot2
Code
require(dplyr)
Le chargement a nécessité le package : dplyr
Attachement du package : 'dplyr'
Les objets suivants sont masqués depuis 'package:stats':
filter, lag
Les objets suivants sont masqués depuis 'package:base':
intersect, setdiff, setequal, union
Code
tableau_contingence %>%as.data.frame(col.names =c("Sexe", "Film", "Freq")) %>%ggplot(mapping =aes(x = Var1, y = Var2, fill = Freq)) +geom_tile() +labs(x="Sexe", y="Film")
Boîtes à Moustaches Groupées : Comparaison d’une Variable Quantitative selon les Catégories d’une Variable Qualitative
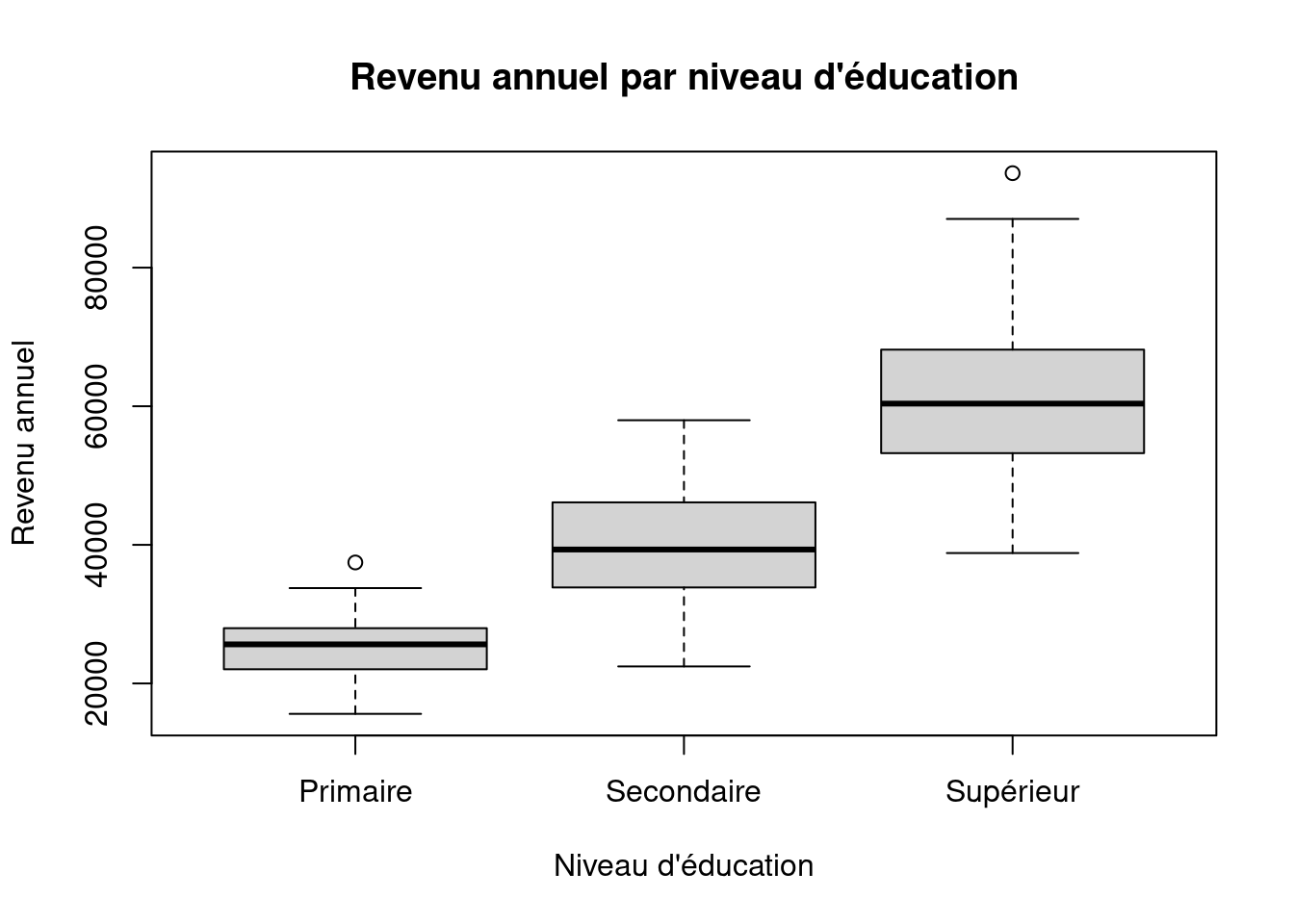
Lorsque nous avons une variable quantitative et une variable qualitative, les boîtes à moustaches groupées sont un outil puissant pour comparer les distributions de la variable quantitative selon les catégories de la variable qualitative.
Construction : Pour chaque catégorie de la variable qualitative, nous construisons une boîte à moustaches qui représente la distribution de la variable quantitative pour cette catégorie.
Interprétation :
La comparaison des médianes des boîtes à moustaches permet de comparer les tendances centrales des distributions.
La comparaison des étendues et des quartiles des boîtes à moustaches permet de comparer les dispersions des distributions.
La comparaison des formes des boites permet de comparer les distributions.
Example 3 Imaginons une étude sur la relation entre le niveau d’éducation (primaire, secondaire, supérieur) et le revenu annuel. Nous pourrions utiliser des boîtes à moustaches groupées pour comparer les distributions des revenus pour chaque niveau d’éducation.
En fonction des types de variables et des objectifs de l’analyse, d’autres représentations graphiques peuvent être utilisées, telles que :
Diagrammes en barres groupées ou empilées : pour comparer les fréquences ou les moyennes de différentes catégories.
Histogrammes bivariés : pour visualiser la distribution conjointe de deux variables quantitatives.
Ce chapitre a présenté les principales méthodes de représentation graphique des données bivariées. Dans les chapitres suivants, nous explorerons les mesures numériques qui permettent de quantifier les relations entre les variables.
region produit ventes
1 Nord A 100
2 Sud A 120
3 Est A 150
4 Ouest A 90
5 Nord B 110
6 Sud B 130
Code
require(ggplot2)require(plotly)
Le chargement a nécessité le package : plotly
Attachement du package : 'plotly'
L'objet suivant est masqué depuis 'package:ggplot2':
last_plot
L'objet suivant est masqué depuis 'package:stats':
filter
L'objet suivant est masqué depuis 'package:graphics':
layout
Code
ggplot(donnees_barres, aes(x = region, y = ventes, fill = produit)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Ventes par région et produit",x ="Région",y ="Ventes") -> ggggplotly(gg)
Example 5 (Histogramme bivarié)
Code
# Histogramme bivarié (exemple fictif)donnees_histogramme <-data.frame(x =rnorm(1000, 50, 10),y =rnorm(1000, 70, 15))ggplot(donnees_histogramme, aes(x = x, y = y)) +geom_bin2d() +labs(title ="Distribution conjointe de X et Y",x ="Variable X",y ="Variable Y")
Exercices
Exercise 1 (Relation entre Taille et Poids) Un chercheur a collecté les données suivantes sur la taille (en cm) et le poids (en kg) d’un groupe d’individus :
Taille (cm)
Poids (kg)
165
60
170
65
175
70
180
75
160
58
185
80
172
68
168
62
178
73
182
78
Créez un nuage de points pour visualiser la relation entre la taille et le poids.
Décrivez la forme de la relation (linéaire, non linéaire, etc.).
Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.
Interprétez la relation entre la taille et le poids (positive, négative, forte, faible).
Exercise 2 (Relation entre Température et Ventes de Glaces) Un vendeur de glaces a enregistré les données suivantes sur la température quotidienne (en °C) et le nombre de glaces vendues :
Température (°C)
Glaces vendues
25
150
28
180
30
200
22
120
26
160
29
190
24
140
31
210
23
130
27
170
Créez un nuage de points pour visualiser la relation entre la température et les ventes de glaces.
Décrivez la forme de la relation.
Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.
Interprétez la relation entre la température et les ventes de glaces.
Exercise 3 (Relation entre Âge et Revenu) Un économiste a collecté les données suivantes sur l’âge et le revenu annuel (en milliers d’euros) d’un groupe de personnes :
Âge
Revenu (k€)
25
30
30
35
35
40
40
45
45
50
50
55
55
60
60
65
65
70
70
75
Créez un nuage de points pour visualiser la relation entre l’âge et le revenu.
Décrivez la forme de la relation.
Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.
Interprétez la relation entre l’âge et le revenu.
Exercise 4 (Relation entre Publicité et Ventes) Une entreprise a enregistré les données suivantes sur le budget publicitaire (en milliers d’euros) et les ventes (en milliers d’unités) :
Publicité (k€)
Ventes (k unités)
10
80
15
120
20
150
25
180
30
220
35
260
40
300
Créez un nuage de points pour visualiser la relation entre la publicité et les ventes.
Décrivez la forme de la relation.
Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.
Interprétez la relation entre la publicité et les ventes.
Exercise 5 (Comparaison des Salaires par Département) Une entreprise souhaite comparer les salaires (en milliers d’euros) de ses employés dans trois départements différents : Marketing, Ventes et Recherche. Les données sont les suivantes :
Marketing
Ventes
Recherche
45
50
60
50
55
65
55
60
70
60
65
75
65
70
80
70
75
85
75
80
90
Créez un boxplot pour comparer les salaires dans les trois départements.
Comparez les médianes des salaires entre les départements.
Comparez les étendues interquartiles (IQR) des salaires entre les départements.
Y a-t-il des valeurs aberrantes dans l’un des départements ? Si oui, identifiez-les.
Interprétez les différences de distribution des salaires entre les départements.
Exercise 6 (Comparaison des Performances des Étudiants par Groupe) Un professeur souhaite comparer les performances de deux groupes d’étudiants (Groupe A et Groupe B) à un examen. Les notes obtenues par les étudiants sont les suivantes :
Groupe A
Groupe B
70
80
75
85
80
90
85
95
90
100
65
75
78
88
82
92
88
98
95
100
Créez un boxplot pour comparer les performances des deux groupes.
Comparez les médianes des notes entre les groupes.
Comparez les étendues interquartiles (IQR) des notes entre les groupes.
Y a-t-il des valeurs aberrantes dans l’un des groupes ? Si oui, identifiez-les.
Interprétez les différences de distribution des notes entre les groupes.
Source Code
---title: "Données et Représentations Graphiques Bivariées"---## Les Données Bivariées : Une Série de CouplesDans le cadre de l'analyse bivariée, nous travaillons avec des données qui se présentent sous la forme d'une série de couples $(x_i, y_i)$, où :* $x_i$ représente la valeur de la variable $X$ pour l'individu $i$.* $y_i$ représente la valeur de la variable $Y$ pour le même individu $i$.* $i$ varie de 1 à $n$, où $n$ est le nombre total d'observations ou d'individus.Cette structure de données nous permet d'étudier la façon dont les variables $X$ et $Y$ varient conjointement.## Le Nuage de Points : Visualisation des Relations QuantitativesLorsque nous avons deux variables quantitatives, le nuage de points (ou diagramme de dispersion) est un outil essentiel pour visualiser leur relation.* **Construction **: Chaque couple $(x_i, y_i)$ est représenté par un point dans un plan cartésien, où l'axe des abscisses représente la variable $X$ et l'axe des ordonnées représente la variable $Y$.* **Interprétation **: * La forme générale du nuage de points peut révéler la présence d'une relation linéaire, non linéaire, ou l'absence de relation. * La direction de la relation (positive ou négative) peut être observée. * La dispersion des points autour d'une éventuelle tendance peut indiquer la force de la relation. * Les valeurs aberrantes (points éloignés des autres) peuvent être identifiées.:::{#exm-}Imaginons une étude sur la relation entre le nombre d'heures d'étude ($X$) et la note obtenue à un examen ($Y$). Les données pourraient se présenter comme suit : $(2, 65)$, $(3, 70)$, $(4, 80)$, $(5, 90)$.```{r}# Exemple de données bivariées (heures d'étude, notes d'examen)heures_etude <-c(2, 3, 4, 5, 6, 7, 8, 3, 5, 9)notes_examen <-c(60, 68, 75, 82, 88, 92, 95, 72, 80, 98)# Nuage de pointsplot(heures_etude, notes_examen,main ="Relation entre heures d'étude et notes d'examen",xlab ="Heures d'étude",ylab ="Notes d'examen", pch=20, col="steelblue", lwd=3)```:::## Les Tableaux de Contingence : Analyse des Relations Qualitatives### Tableau de contingenceLorsque nous avons deux variables qualitatives, les tableaux de contingence (ou tableaux croisés) sont utilisés pour analyser leur relation.* **Construction **: Les lignes du tableau représentent les catégories de l'une des variables, et les colonnes représentent les catégories de l'autre variable. Chaque cellule du tableau contient le nombre d'observations qui appartiennent à la fois à la catégorie de la ligne et à la catégorie de la colonne.* **Interprétation **: * Les fréquences marginales (sommes des lignes et des colonnes) donnent des informations sur la distribution de chaque variable individuellement. * Les fréquences conditionnelles (pourcentages dans les lignes ou les colonnes) permettent de comparer les distributions des variables selon les catégories de l'autre variable. * Les écarts entre les fréquences observées et les fréquences attendues en cas d'indépendance peuvent indiquer la présence d'une association entre les variables.### Représentations GraphiquesPour visualiser les informations contenues dans un tableau de contingence, plusieurs types de graphiques peuvent être utilisés :* **Diagrammes en barres groupées ou empilées **:Permettent de comparer les fréquences ou les pourcentages de chaque catégorie d'une variable pour chaque catégorie de l'autre variable.Par exemple, on peut comparer le nombre d'hommes et de femmes qui préfèrent chaque type de film (comédie ou drame).* **Diagrammes en mosaïque **:Représentent visuellement les tableaux de contingence en utilisant des rectangles dont la taille est proportionnelle aux fréquences observées. Permettent de visualiser facilement les relations entre les variables, en mettant en évidence les écarts par rapport à l'indépendance.:::{#exm-}Imaginons une étude sur la relation entre le sexe (homme/femme) et la préférence pour un type de film (comédie/drame). Un tableau de contingence pourrait se présenter comme suit :| Sexe | Comédie | Drame | Total || :------| :------| :----| :----|| Homme | 40 | 60 | 100 || Femme | 70 | 30 | 100 || **Total** | **110** | **90** | **200** |```{r}# Exemple de tableau de contingence (sexe, préférence pour les films)donnees_films <-data.frame(sexe =rep(c("Homme", "Femme"), c(100, 100)),preference =c(rep("Comédie", 40), rep("Drame", 60),rep("Comédie", 70), rep("Drame", 30)))tableau_contingence <-table(donnees_films$sexe, donnees_films$preference)print(tableau_contingence)```**Diagramme ;à barres groupés**```{r}# Diagramme en barres groupéesbarplot(tableau_contingence, beside =TRUE,legend.text =TRUE,main ="Préférence pour les films par sexe",xlab ="Type de film",ylab ="Nombre de personnes")```**Diagramme en mosaïques**```{r}# Diagramme en mosaïquemosaicplot(tableau_contingence,main ="Préférence pour les films par sexe",color =TRUE)```**Heatmap**```{r}require(ggplot2)require(dplyr)tableau_contingence %>%as.data.frame(col.names =c("Sexe", "Film", "Freq")) %>%ggplot(mapping =aes(x = Var1, y = Var2, fill = Freq)) +geom_tile() +labs(x="Sexe", y="Film")```:::## Boîtes à Moustaches Groupées : Comparaison d'une Variable Quantitative selon les Catégories d'une Variable QualitativeLorsque nous avons une variable quantitative et une variable qualitative, les boîtes à moustaches groupées sont un outil puissant pour comparer les distributions de la variable quantitative selon les catégories de la variable qualitative.* **Construction **: Pour chaque catégorie de la variable qualitative, nous construisons une boîte à moustaches qui représente la distribution de la variable quantitative pour cette catégorie.* **Interprétation **: * La comparaison des médianes des boîtes à moustaches permet de comparer les tendances centrales des distributions. * La comparaison des étendues et des quartiles des boîtes à moustaches permet de comparer les dispersions des distributions. * La comparaison des formes des boites permet de comparer les distributions.:::{#exm-}Imaginons une étude sur la relation entre le niveau d'éducation (primaire, secondaire, supérieur) et le revenu annuel. Nous pourrions utiliser des boîtes à moustaches groupées pour comparer les distributions des revenus pour chaque niveau d'éducation.```{r}# Boîtes à moustaches groupées (niveau d'éducation, revenu annuel)niveau_education <-rep(c("Primaire", "Secondaire", "Supérieur"), c(50, 75, 100))revenu_annuel <-c(rnorm(50, 25000, 5000),rnorm(75, 40000, 8000),rnorm(100, 60000, 12000))boxplot(revenu_annuel ~ niveau_education,main ="Revenu annuel par niveau d'éducation",xlab ="Niveau d'éducation",ylab ="Revenu annuel")```:::## Autres Représentations GraphiquesEn fonction des types de variables et des objectifs de l'analyse, d'autres représentations graphiques peuvent être utilisées, telles que :* Diagrammes en barres groupées ou empilées : pour comparer les fréquences ou les moyennes de différentes catégories.* Histogrammes bivariés : pour visualiser la distribution conjointe de deux variables quantitatives.Ce chapitre a présenté les principales méthodes de représentation graphique des données bivariées. Dans les chapitres suivants, nous explorerons les mesures numériques qui permettent de quantifier les relations entre les variables.:::{#exm-}## Diagramme à barres regroupées```{r}# Diagrammes en barres groupées (exemple fictif)donnees_barres <-data.frame(region =rep(c("Nord", "Sud", "Est", "Ouest"), 2),produit =rep(c("A", "B"), each =4),ventes =c(100, 120, 150, 90, 110, 130, 160, 100))donnees_barres |>head()``````{r}require(ggplot2)require(plotly)ggplot(donnees_barres, aes(x = region, y = ventes, fill = produit)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Ventes par région et produit",x ="Région",y ="Ventes") -> ggggplotly(gg)```::::::{#exm-}## Histogramme bivarié```{r}# Histogramme bivarié (exemple fictif)donnees_histogramme <-data.frame(x =rnorm(1000, 50, 10),y =rnorm(1000, 70, 15))ggplot(donnees_histogramme, aes(x = x, y = y)) +geom_bin2d() +labs(title ="Distribution conjointe de X et Y",x ="Variable X",y ="Variable Y")```:::## Exercices:::{#exr-}## Relation entre Taille et PoidsUn chercheur a collecté les données suivantes sur la taille (en cm) et le poids (en kg) d'un groupe d'individus :| Taille (cm) | Poids (kg) ||---|---|| 165 | 60 || 170 | 65 || 175 | 70 || 180 | 75 || 160 | 58 || 185 | 80 || 172 | 68 || 168 | 62 || 178 | 73 || 182 | 78 |1. Créez un nuage de points pour visualiser la relation entre la taille et le poids.2. Décrivez la forme de la relation (linéaire, non linéaire, etc.).3. Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.4. Interprétez la relation entre la taille et le poids (positive, négative, forte, faible).::::::{#exr-}## Relation entre Température et Ventes de GlacesUn vendeur de glaces a enregistré les données suivantes sur la température quotidienne (en °C) et le nombre de glaces vendues :| Température (°C) | Glaces vendues ||---|---|| 25 | 150 || 28 | 180 || 30 | 200 || 22 | 120 || 26 | 160 || 29 | 190 || 24 | 140 || 31 | 210 || 23 | 130 || 27 | 170 |1. Créez un nuage de points pour visualiser la relation entre la température et les ventes de glaces.2. Décrivez la forme de la relation.3. Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.4. Interprétez la relation entre la température et les ventes de glaces.::::::{#exr-}## Relation entre Âge et RevenuUn économiste a collecté les données suivantes sur l'âge et le revenu annuel (en milliers d'euros) d'un groupe de personnes :| Âge | Revenu (k€) ||---|---|| 25 | 30 || 30 | 35 || 35 | 40 || 40 | 45 || 45 | 50 || 50 | 55 || 55 | 60 || 60 | 65 || 65 | 70 || 70 | 75 |1. Créez un nuage de points pour visualiser la relation entre l'âge et le revenu.2. Décrivez la forme de la relation.3. Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.4. Interprétez la relation entre l'âge et le revenu.::::::{#exr-}## Relation entre Publicité et VentesUne entreprise a enregistré les données suivantes sur le budget publicitaire (en milliers d'euros) et les ventes (en milliers d'unités) :| Publicité (k€) | Ventes (k unités) ||---|---|| 10 | 80 || 15 | 120 || 20 | 150 || 25 | 180 || 30 | 220 || 35 | 260 || 40 | 300 |1. Créez un nuage de points pour visualiser la relation entre la publicité et les ventes.2. Décrivez la forme de la relation.3. Y a-t-il des valeurs aberrantes ? Si oui, identifiez-les.4. Interprétez la relation entre la publicité et les ventes.::::::{#exr-}## Comparaison des Salaires par DépartementUne entreprise souhaite comparer les salaires (en milliers d'euros) de ses employés dans trois départements différents : Marketing, Ventes et Recherche. Les données sont les suivantes :| Marketing | Ventes | Recherche ||---|---|---|| 45 | 50 | 60 || 50 | 55 | 65 || 55 | 60 | 70 || 60 | 65 | 75 || 65 | 70 | 80 || 70 | 75 | 85 || 75 | 80 | 90 |1. Créez un boxplot pour comparer les salaires dans les trois départements.2. Comparez les médianes des salaires entre les départements.3. Comparez les étendues interquartiles (IQR) des salaires entre les départements.4. Y a-t-il des valeurs aberrantes dans l'un des départements ? Si oui, identifiez-les.5. Interprétez les différences de distribution des salaires entre les départements.::::::{#exr-}## Comparaison des Performances des Étudiants par GroupeUn professeur souhaite comparer les performances de deux groupes d'étudiants (Groupe A et Groupe B) à un examen. Les notes obtenues par les étudiants sont les suivantes :| Groupe A | Groupe B ||---|---|| 70 | 80 || 75 | 85 || 80 | 90 || 85 | 95 || 90 | 100 || 65 | 75 || 78 | 88 || 82 | 92 || 88 | 98 || 95 | 100 |1. Créez un boxplot pour comparer les performances des deux groupes.2. Comparez les médianes des notes entre les groupes.3. Comparez les étendues interquartiles (IQR) des notes entre les groupes.4. Y a-t-il des valeurs aberrantes dans l'un des groupes ? Si oui, identifiez-les.5. Interprétez les différences de distribution des notes entre les groupes.:::