La classification des textes est une branche essentielle du traitement automatique du langage naturel (NLP) qui consiste à attribuer une ou plusieurs catégories à un document écrit, en fonction de son contenu. Cette technique s’applique dans de nombreux domaines, allant de la détection de spam dans les emails à la gestion des relations clients, en passant par l’organisation de larges bases de données documentaires.
Les applications de la classification de textes sont vastes et variées :
Filtrage de spam : Identifier et séparer les emails indésirables des communications légitimes.
Analyse de sentiments : Déterminer si le ton d’un texte est positif, négatif, ou neutre, particulièrement utile dans l’analyse de feedback client.
Catégorisation de contenu : Classer automatiquement les articles ou les posts dans des catégories prédéfinies pour faciliter la recherche et la navigation.
6.2 Formalisation de la classification supervisée
La classification supervisée (analyse discriminante) s’intéresse à l’explication ou la prédiction d’une variable qualitative\(Y\) dite à expliquer (outcome) par un vecteur \(X\) de variables dites explicatives. Les données données d’apprentissage se présentent donc sous la forme: \[
\mathcal{A}_n=\left\{\left(x_i,y_i\right)_{i=1}^n\right\}.
\]
Nous nous intéressons à la classification des documents d’un corpus donné. Alors, \(\left(x_i,y_i\right)\) représente les données du document \(i\) dans le corpus. Les données explicatives sont alors représentées par la matrice DTF (Document Term Frequency). Rappelons qu’un exemple de cette matrice est \(\mathbb{X}=\left(x_{i,j}\right)_{i=1,\cdots,n; j=1,\cdots,v}\), où
\(n\) est le nombre de documents dans le corpus
\(v\) le nombre de mots dans le dictionnaire.
\(x_{i,j}=tf\_idf_{j,i}\) est la fréquence du terme (token) \(j\) dans le document \(i\).
\(y_i\) représente alors la classe ou le label du document \(i\).
6.3 Quelques mesures d’évaluation
Soit \(\widehat{y}_i\) la classe prédite document \(i\) par une méthode donnée.
6.3.1 Matrice de confusion
Il s’agit de la table de contingence qui croise les labels observés et ceux prédits.
Le coeeficient \(k, l\) de la matrice de confusion est \(c_{k,l}\) qui représente le nombre d’individus tels que \(y_i=k\) et \(\widehat{y}_i=l\): \[c_{k,l}=\sum_k\sum_l1_{y_i=c_k}1_{\widehat{y}_i=c_l}.\]
6.3.2 Accuracy (Precision)
Il s’agit de la proportion des labels bien prédits \[
\dfrac{\sum_kc_{k,k}}{n}
\]
6.3.3 Error rate
Il’s’agit de la proportion de mal classés: \[
\dfrac{\sum_{k,l|k\neq l}c_{k,l}}{n}=1-\dfrac{\sum_kc_{k,k}}{n}
\]
6.3.4 Recall
La proportion des bien classés dans une classe donnée:
Recall et \(F\)-Mesure sont adaptées à la classification binaire.
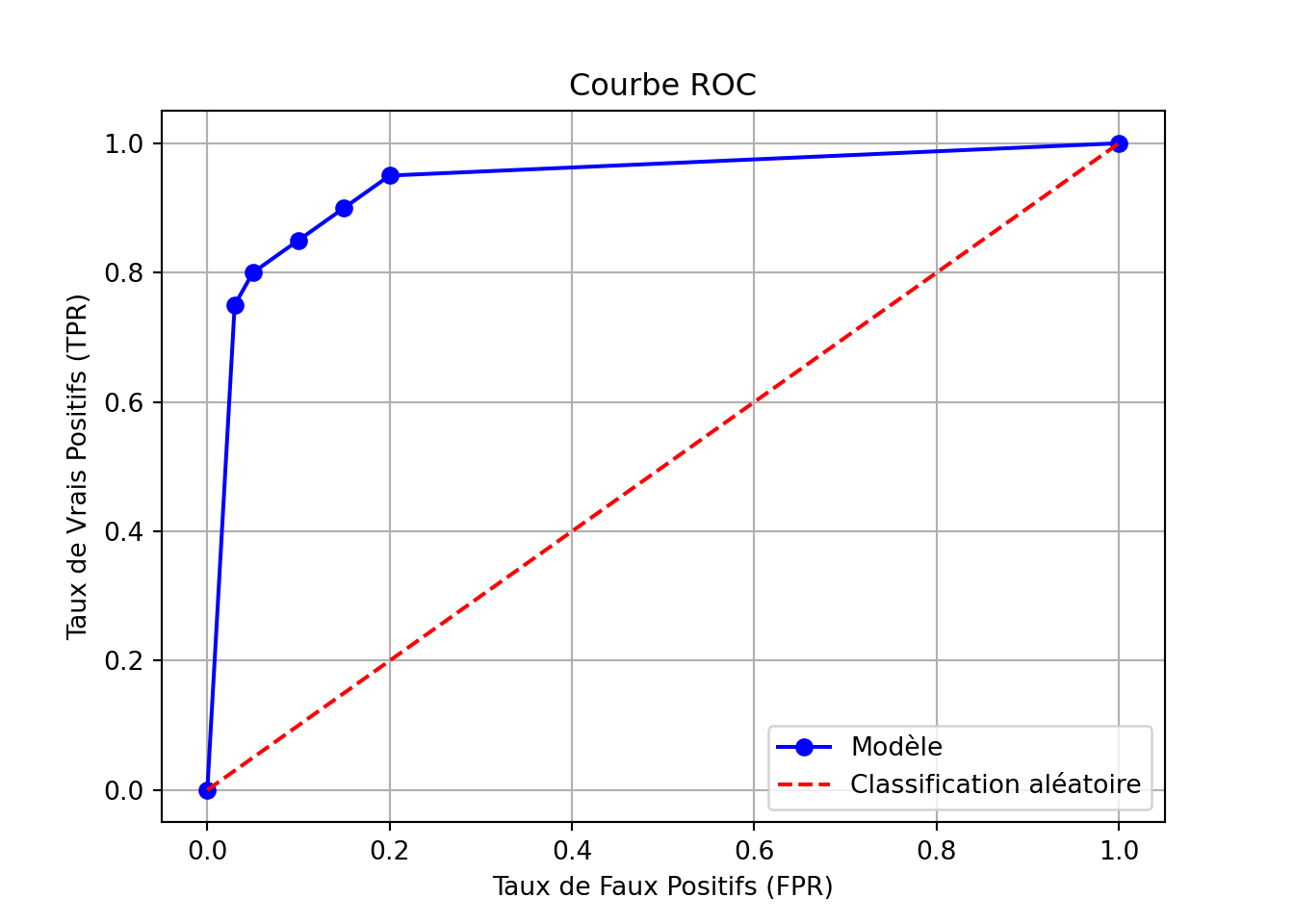
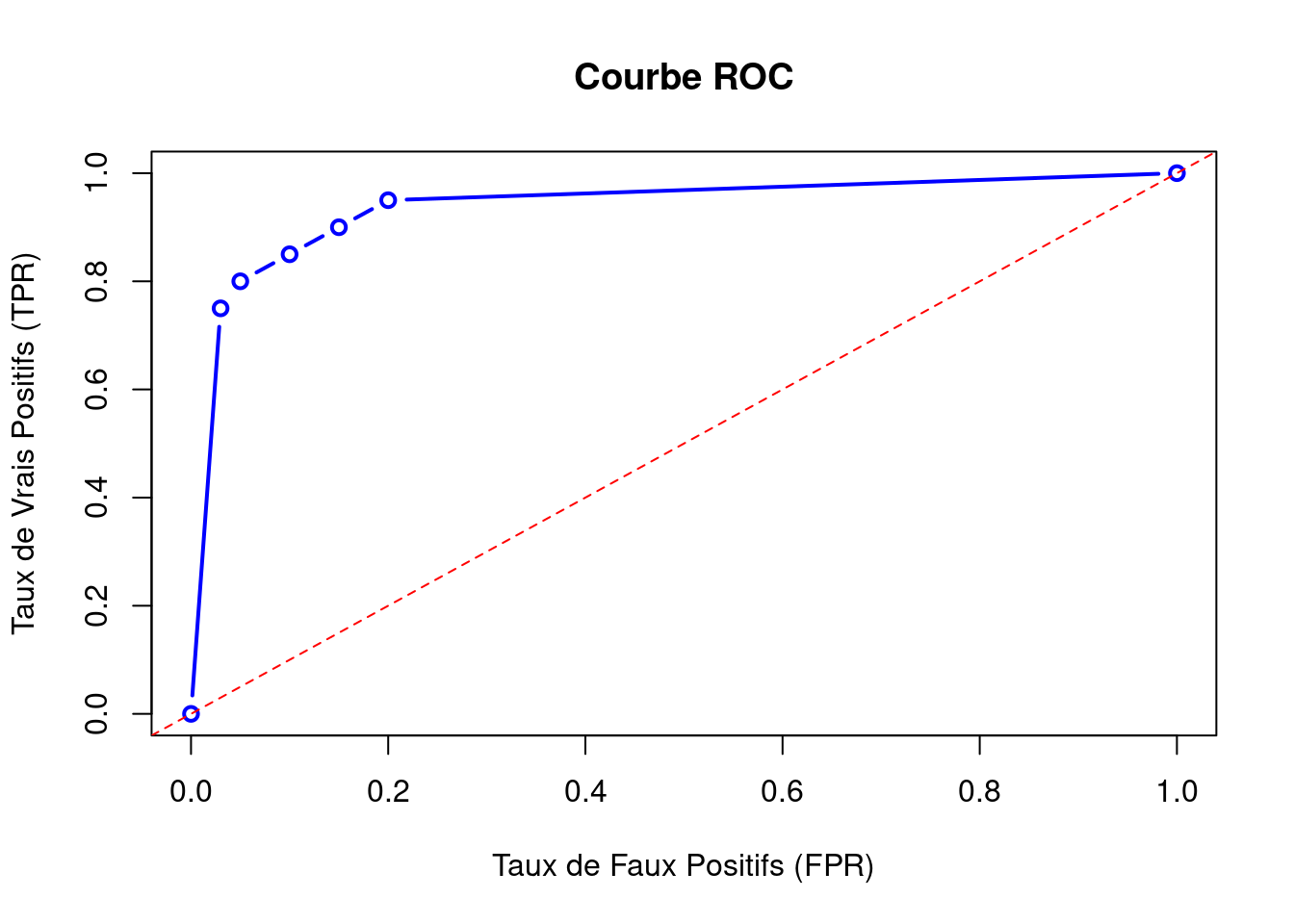
6.3.6 Aire sous la courbe ROC
La courbe ROC (Receiver Operating Characteristic) est un outil graphique utilisé pour évaluer la performance d’un modèle de classification binaire. Elle représente le compromis entre la sensibilité (True Positive Rate) et la spécificité (1 - False Positive Rate) à différents seuils de décision.
6.3.6.1 Définition des Termes
Sensibilité (True Positive Rate, TPR) : \[
TPR = \dfrac{TP}{TP + FN}
\] où \(TP\) est le nombre de vrais positifs et \(FN\) est le nombre de faux négatifs.
Spécificité (True Negative Rate, TNR) : \[
TNR = \dfrac{TN}{TN + FP}
\] où \(TN\) est le nombre de vrais négatifs et \(FP\) est le nombre de faux positifs.
Calcul des Paires (FPR, TPR) : Pour chaque seuil de décision \(t\), calculez les valeurs de ( FPR(t) ) et ( TPR(t) ).
Tracer la Courbe : Sur un graphique, placez ( FPR(t) ) sur l’axe des abscisses et ( TPR(t) ) sur l’axe des ordonnées. La courbe ROC est obtenue en reliant les points correspondants à différents seuils.
6.3.6.3 Interprétation de la Courbe ROC
Ligne Diagonale \(y = x\) : Une courbe ROC le long de la diagonale indique une performance de classification aléatoire.
Aire sous la Courbe (AUC) : \[
AUC = \int_0^1 ROC(t) \, dt
\] Une AUC de 0.5 indique une performance aléatoire, tandis qu’une AUC de 1 indique une classification parfaite.
Note
Les performances d’une méthode sont d’autant bonnes que l’AUC est proche de \(1\).
En traçant ces points, nous obtenons une courbe ROC qui nous permet de visualiser la performance de notre modèle à différents seuils et de choisir le seuil optimal en fonction de l’équilibre souhaité entre sensibilité et spécificité.
import matplotlib.pyplot as plt# Seuils et valeurs de TPR et FPRseuils = [0.1, 0.2, 0.3, 0.4, 0.5]TPR = [1.0, 0.95, 0.90, 0.85, 0.80, 0.75, 0.0]FPR = [1.0, 0.20, 0.15, 0.10, 0.05, 0.03, 0.0]# Tracer la courbe ROCplt.plot(FPR, TPR, marker='o', linestyle='-', color='b', label='Modèle')plt.plot([0, 1], [0, 1], linestyle='--', color='r', label='Classification aléatoire')plt.xlabel('Taux de Faux Positifs (FPR)')plt.ylabel('Taux de Vrais Positifs (TPR)')plt.title('Courbe ROC')plt.legend()plt.grid()plt.show()
Code
# Installer et charger le package pROC#install.packages("pROC")#library(pROC)# Seuils et valeurs de TPR et FPRseuils <-c(0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 1.0)TPR <-c(1.0, 0.95, 0.90, 0.85, 0.80, 0.75, 0.0)FPR <-c(1.0, 0.20, 0.15, 0.10, 0.05, 0.03, 0.0)# Créer un dataframedata <-data.frame(seuils, TPR, FPR)# Tracer la courbe ROCplot(data$FPR, data$TPR, type ="b", col ="blue", lwd =2,xlab ="Taux de Faux Positifs (FPR)", ylab ="Taux de Vrais Positifs (TPR)",main ="Courbe ROC")abline(0, 1, col ="red", lty =2) # Ajouter la ligne diagonale
6.4 Méthodes usuelles de classification
Rappelons que pour le risque usuel \(0-1\) défini par \[
\mathcal{R}(g)=\mathbb{E}\left[1_{g(X)\neq Y}\right]=\mathbb{P}\left(g(X)\neq Y\right),
\] le classifisieur idéal est défini par \[
g^*(x)\in\arg\max_{l=1,\cdots,L}\mathbb{P}\left(Y=l|X=x\right),\ x\in X\left(\Omega\right)
\]
Note:
\(g^*\) est appelé classifieur idéal ou classifieur cible
\(g^*\) n’est pas calculable dans la pratique car la loi jointe de \(\left(X, Y\right)\) n’est pas connue.
Différents algorithmes ou méthodes estiment différemment la loi conditionnelle de \(Y|X\).
6.4.1 Algo. des \(k\) plus proches voisins (\(k\)-nn)
On suppose que \(Y\left(\Omega\right)=\left\{0, 1\right\}\) non-ordonné. Estimer le classifieur de Bayes \(g^*\) consiste à estimer \(\eta(x)=\mathbb{P}\left(Y=1|X=x\right)\), car \[
g^*(x)=1_{\left[\eta(x)\geq 1- \eta(x)\right]}
\] Le modèle en question suppose que: \[
\eta(x)=\eta_{\beta}(x)=\dfrac{e^{\beta_0+\sum_{j=1}^p\beta_jx_{\cdot,j}}}{1+e^{\beta_0+\sum_{j=1}^p\beta_jx_{\cdot,j}}},
\]
où \(\beta={}^t\left(\beta_j\right)_{j=1}^p\in\mathbb{R}^{p+1}\) est le vecteur des paramètres à estimer.
Soit \(\widehat{\beta}\) le paramètre estimé. Le classifieur estimé associé est alors donné par: \[
\widehat{g}(x)=1_{\left[\eta_{\widehat{\beta}}(x)\geq \dfrac{1}{2}\right]}
\]
6.4.3 Analyses discriminantes gaussiennes
Supposons que la variable \(X\) est continue de densités marginale \(f_X\) et conditionnelle \(f_{X|Y}\). Remarquons que \[
\begin{aligned}
\mathbb{P}\left(Y=k|X=x\right)&=\dfrac{\mathbb{P}\left(Y=k\right)f_{X|Y=k}(x)}{f_X(x)}\\
&\propto \mathbb{P}\left(Y=k\right)f_{X|Y=k}(x)=:\exp\left(\delta_k(x)\right).
\end{aligned}
\]
Definition 6.1 (Fonction discriminante) La fonction \(\delta_k\) est appelée fonction discriminante de la classe \(k\).
On a: \[
\delta_k(x)=\ln \mathbb{P}\left(Y=k\right)+\ln f_{X|Y=k}(x)
\]
Équation de la fronctière
L’équation de la fronctière entre deux classes \(k\) et \(k'\) est \[
\delta_k(x)=\delta_{k'}(x).
\]
Les modèles d’analyse discriminante gaussienne consistent à supposer que \[
X|Y=k\sim\mathcal{N}\left(\mu_k, \Lambda_k\right).
\]
6.4.3.1 Analyse discriminante quadratique
Si on suppose que pour au moins deux classes \(k\) et \(k'\) on a \(\Lambda_k\neq \Lambda_{k'}\), alors l’équation \(\delta_k(x)=\delta_{k'}(x)\) est quadratique en \(x\):
Definition 6.2 On parle alord d’analyse discriminante quadratique.
Note
L’hypothèse \(\Lambda_k\neq \Lambda_{k'}\) est appelée hétéroscédasticité.
6.4.3.2 Analyse discriminante linéaire
Si on suppose que toutes les classes ont la même variance \(\Lambda:=\Lambda_k\), alors l’équation \(\delta_k(x)=\delta_{k'}(x)\) est linéaire en \(x\):
Definition 6.3 On parle alord d’analyse discriminante linéaire.
Note
L’hypothèse \(\Lambda_k= \Lambda_{k'}=:\Lambda\) est appelée homoscédasticité.
6.4.4 Classifieur naïf de Bayes
Nous avons vu plus haut qu’il suffit de pouvoir calculer les \(\mathbb{P}(Y=k)f_{X|Y=k}(x)\) pour pouvoir classer \(x\).
Definition 6.4 Le classifieur naïf de Bayes consiste à faire l’hypothèse d’indépendance conditionnelle des coordonnées de \(X\), sachant \(Y\): \[
f_{X|Y=k}(x)=\prod_{j=1}^pf_{X^j|Y=k}(x^j),
\] où \(x=\left(x^j\right)_{j=1}^p\).
Note
L’hypothèse d’indépendance conditionnelle des coordonnées de \(X\) permet de simplifier le modèle en réduisant le nombre de paramètres à estimer.
Le modèle obtenu peut être trop simple et tombé sous le coût du under-fitting.
Un tel modèle est très souvent utilisé comme modèle de base préalable à d’autres plus complexes.
6.4.5 Arbre binaire de classification
Le but est de construire un arbre binaire descendant, de sorte que les feuilles (noeuds terminaux) soient les plus purs (de façon équivalente, les moins impurs) possibles. Pour cela, on a besoin d’une mesure de la pureté (ou d’impureté) d’un neoud.
6.4.5.1 Mesures usuelles d’impureté en classification
Indice de Gini:?\(1-\sum_lp_l^2\)
Entropie:\(-\sum_lp_l\ln p_l\), où \(p_l\) est la proportion du label \(l\) (sous la convention \(0\ln 0=0\)).
Note: L’indice de Gini et l’entropie valent \(0\) lorsqu’un seul label est représenté.
6.4.5.2 Split
Ce terme désigne le fait de scinder un noeud en deux noeuds fils. Un Split consiste en:
Une variable explicative
Un seuil si la variable explicative est quantitative, ou un sous-ensemble de modalités si la variable est qualitative; nous notons \(s\) pour seuil ou sous-ensembles de modalités
Nototion:\(split=split(j, s)\), où \(j\) est l’indice d’une variable explicative
Meilleur split:
Notons \(I\) la mesure d’impureté considérée
Un critère de sélection du meileur split est \[
\dfrac{n_g*I(N_g)+n_dI(N_d)}{n_g+n_d}\ (*),
\] où
\(N_g\) et \(N_d\) sont les noeuds fils gauche et droite respectivement
\(n_g\) et \(n_d\) leurs cardinaux.
6.4.5.3 Partitionnement d’un noeud
Un partitionnement est fait à l’aide d’un split
Le split pour partitionner est celui qui minimise \((*)\) ci-dessus
6.4.5.3.1 Cas d’un split avec variable quantitative
\(N_g=\) les données pour lesquelles \(x_{i,j}\leq s\)
\(N_d=\) les données pour lesquelles \(x_{i,j}> s\).
6.4.5.3.2 Cas d’un split avec variable qualitative
\(N_g=\) les données pour lesquelles \(x_{i,j}\in s\)
\(N_d=\) les données pour lesquelles \(x_{i,j}\notin s\).
6.4.5.4 Élaguer l’arbre
L’arbre initial est le plus profond possible: en général, le critère pour partitionner un noeud est qu’il soit pur ou que son cardinal soit \(\geq\) à un certain seuil (en général \(5\)).
L’arbre initial sur apprend: Se comporte bien (parfois parfaitement) sur les données d’apprentissage et très mal sur de nouvelles données;
Il est très souvent nécessaire d’élaguer (de couper) l’arbre pour réaliser le meilleur compromis Biais-Variance.
Note
Il existe des critères d’élaguage dans la litérature (chercher des références!).
6.4.6 Forêt aléatoire
Todo
6.5 Validation croisée
Nous considérons plus généralement un problème d’apprentissage supervisé à partir de données d’apprentissage \[
\mathcal{A}_n=\left\{(x_i, y_i)\right\}_{i=1}^n.
\] Du point de vue statistique, les données sont modélisées par des vecteurs aléatoires \((X_i, Y_i)\) indépendantes et identiquement distribuées comme un vecteur aléatoire générique \((X, Y)\).
Rappelons que le but de l’apprentissage supervisé est de construire un prédicteur\(g\) qui est une application mesurable de l’espace \(X(\Omega)\) des valeurs de \(X\) dans l’espace \(Y(\Omega)\) des valeurs de \(Y\).
Le prédicteur idéal est donné par: \[
g^*=\arg\min_{g}\mathcal{R}(g)
\] où \(\mathcal{R}\) est un risque qu’on s’est donné. Les risque sont sous la forme \[
\mathcal{R}=\mathbb{E}\left[L\left(g(X), Y\right)\right],
\] où \(L\) est une fonction de perte.
Notons que \(g^*\) n’est pas calculable du fait que la loi jointe de \((X, Y)\) est inconnu. Il reste alors estimer \(g^*\) à partir des données d’apprentissage: \[
\widehat{g}=\widehat{g}\left(\mathcal{A}_n\right).
\]
6.5.1 Position du problème
Comment estimer de façon “honnête” le risque \(\mathcal{R}\left(\widehat{g}\right)\) de \(\widehat{g}=\widehat{g}\left(\mathcal{A}_n\right)\)?
Note
En effet, le risque empirique \[
\widehat{\mathcal{R}}\left(\widehat{g}, \mathcal{A}_n\right):=\dfrac{1}{n}\sum_{i=1}^nL\left(\widehat{g}(X_i), Y_i\right)
\] est une mésure “optimiste” des performances de \(\widehat{g}\); car on teste un prédicteur sur les données qui l’ont estimé.
6.5.2 Méthodes usuelles
Il est important de voir \(\widehat{g}=\widehat{g}\left(\mathcal{A}_n\right)\) comme une règle de prédiction.
6.5.2.1 Train-Test
Partitionner de façon aléatoire\(\left\{1,\cdots,n\right\}=:[n]=I_{train}\cup I_{test}\)
Cette méthode est adaptée pour les données de petites tailles, et déconseillée pour les données de grandes tailles.
6.6 Exemple
Le fichier tweets.cvs contient plus de \(11\ 000\) tweets associés à des mots-clés de catastrophe tels que « crash », « quarantaine » et « feux de brousse », ainsi que la localisation et le mot-clé lui-même. Ensuite, les textes ont été classés manuellement pour déterminer si le tweet faisait réellement référence à un événement catastrophique ou non (une blague avec le mot, une critique de film ou quelque chose de non catastrophique).
Ces données se prêtent bien à la classification supervisée.
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as plt## For text pre-processingimport re, stringimport nltkfrom nltk.tokenize import word_tokenizefrom nltk.corpus import stopwordsfrom nltk.stem import SnowballStemmerfrom nltk.corpus import wordnetfrom nltk.stem import WordNetLemmatizer## Only #nltk.download('punkt')#nltk.download('averaged_perceptron_tagger')#nltk.download('wordnet')#nltk.download('stopwords')#for model-buildingfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.linear_model import SGDClassifierfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.metrics import classification_report, f1_score, accuracy_score, confusion_matrixfrom sklearn.metrics import roc_curve, auc, roc_auc_score# bag of wordsfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_extraction.text import CountVectorizer#for word embeddingimport gensimfrom gensim.models import Word2Vec #Word2Vec is mostly used for huge datasets
Help functions for preprocessing
Code
def preprocess(text):""" Convert to lowercase and remove punctuations and characters and then strip """#lowercase text text = text.lower() #get rid of leading/trailing whitespace text=text.strip() #Remove HTML tags/markups text=re.compile('<.*?>').sub('', text) text = re.compile('[%s]'% re.escape(string.punctuation)).sub(' ', text) #Replace punctuation with space. Careful since punctuation can sometime be useful text = re.sub('\s+', ' ', text) #Remove extra space and tabs text = re.sub(r'\[[0-9]*\]',' ',text) #[0-9] matches any digit (0 to 10000...) text=re.sub(r'[^\w\s]', '', str(text).lower().strip()) text = re.sub(r'\d',' ',text) #matches any digit from 0 to 100000..., \D matches non-digits text = re.sub(r'\s+',' ',text) #\s matches any whitespace, \s+ matches multiple whitespace, \S matches non-whitespace return text#3. LEXICON-BASED TEXT PROCESSING EXAMPLES#1. STOPWORD REMOVALdef stopword(string): a= [i for i in string.split() if i notin stopwords.words('english')]return' '.join(a)#2. STEMMING# Initialize the stemmersnow = SnowballStemmer('english')def stemming(string): a=[snow.stem(i) for i in word_tokenize(string) ]return" ".join(a)# This is a helper function to map NTLK position tags# Full list is available here: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.htmldef get_wordnet_pos(tag):if tag.startswith('J'):return wordnet.ADJelif tag.startswith('V'):return wordnet.VERBelif tag.startswith('N'):return wordnet.NOUNelif tag.startswith('R'):return wordnet.ADVelse:return wordnet.NOUN#3. LEMMATIZATION# Initialize the lemmatizerwl = WordNetLemmatizer()# Tokenize and lemmatize the sentencedef lemmatizer(string): word_pos_tags = nltk.pos_tag(word_tokenize(string)) # Get position tags a=[wl.lemmatize(tag[0], get_wordnet_pos(tag[1])) for idx, tag inenumerate(word_pos_tags)] # Map the position tag and lemmatize the word/tokenreturn" ".join(a)#FINAL PREPROCESSINGdef finalpreprocess(string):return lemmatizer(stopword(preprocess(string)))
Test of preprocessing
Code
#1. Common text preprocessingrawText =" This is a message to be cleaned. It may involve some things like: <br>, ?, :, '' adjacent spaces and tabs . "text=stopword(rawText)print(f"No stopwords: {text}")print(f"Stemmed text: {stemming(text)}")print(f"Lemmetized text: {lemmatizer(text)}")
print(f"Index of the best predictor:{gridSearch.best_index_}")# Indice du meilleur estimateur: 7print(f"Accuracy of the pest estimator: {gridSearch.best_score_}")
\(k\)-nn sur les données word2vec en exercice
Code
from gensim.models.doc2vec import Doc2Vec, TaggedDocument# Tagging des documentstagged_data = [TaggedDocument(words=doc.split(), tags=[str(i)]) for i, doc inenumerate(tweets["clean_text"])]# Configuration et entraînement du modèlemodel = Doc2Vec(vector_size=500, window=2, min_count=1, workers=4, epochs=40)model.build_vocab(tagged_data)model.train(tagged_data, total_examples=model.corpus_count, epochs=model.epochs)# Données vectorisées dans model.dv.vectors
Code
# Instancierknn = KNeighborsClassifier(algorithm ="auto")gridSearch = GridSearchCV( estimator=knn, param_grid={"n_neighbors": [k for k inrange(1, 10)]}, cv =10,)gridSearch.fit(model.dv.vectors, tweets["target"])
Code
print(f"Index of the best predictor:{gridSearch.best_index_}")# Indice du meilleur estimateur: 7print(f"Accuracy of the pest estimator: {gridSearch.best_score_}")
6.7 Travaux pratiques
Exercise 6.1 (Tavaux pratiques sur les spams) Considérer les données du fichier spam.csv.
Préparer les documents pour l’analyse, en les nettoyant et en appliquant la tokenisation.
Déterminer la matrice DT des \(tf\)-\(idf\).
Puis comparer différentes méthodes de classification supervisée à partir de DT.
Utilisez Gensim pour créer et entraîner un modèle Doc2Vec avec les documents.
Puis comparer différentes méthodes de classification supervisée des données précédentes.
Comparer le meilleur classifieur obtenu au meilleur de la question précédente.