Code
['awesome' 'is' 'learning' 'machine' 'mining' 'purpose' 'text' 'too'][[1 1 1 0 1 1 1 0]
[1 1 1 1 0 0 0 1]]La représentation des documents vise à encoder des textes de manière à préserver l’information significative tout en étant compatible avec les algorithmes de machine learning et d’analyse de données. Ce chapitre explore les différentes méthodes de représentation des documents, leurs avantages, leurs inconvénients, et leurs applications pratiques.
Le modèle Bag of Words représente le texte en tant que sac de mots sans tenir compte de l’ordre des mots mais en conservant leur fréquence.
Example 3.1
['awesome' 'is' 'learning' 'machine' 'mining' 'purpose' 'text' 'too'][[1 1 1 0 1 1 1 0]
[1 1 1 1 0 0 0 1]]Le TF-IDF mesure l’importance d’un mot dans un document en rapport à une collection de documents. C’est une amélioration du modèle BoW. C’est une mesure de l’importance d’un mot dans un document par rapport à une collection de documents. Elle aide à différencier la fréquence des termes à l’intérieur des documents et à travers un corpus documentaire.
Notations:
\(n_{t, d}\): Nombre d’occurences du terme \(t\) dans le document \(d\);
\(n_{+,d}\): Nombre de termes dans le document \(d\);
\[ \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) \] où
\[ \text{TF}(t, d) = \dfrac{n_{t, d}}{n_{+,d}} \]
\[ \text{IDF}(t, D) = \ln \left(\dfrac{|D|}{|\left\{d\in D;\ t\in d\right\}|}\right) \]
TF (Fréquence de Terme) : Cela mesure la fréquence à laquelle un terme apparaît dans un document. Comme chaque document est différent en longueur, il est possible qu’un terme apparaisse beaucoup plus de fois dans des documents longs que dans des documents plus courts. Ainsi, la fréquence des termes est souvent divisée par la longueur du document (le nombre total de termes dans le document) comme moyen de normalisation.
IDF (Fréquence de Document Inverse) : Cela mesure combien un terme est important. Alors que le calcul de TF considère tous les termes également importants, certains termes, tels que “est”, “de” et “que”, peuvent apparaître de nombreuses fois mais avoir peu d’importance. Ainsi, nous devons réduire le poids des termes fréquents tout en augmentant celui des termes rares, en calculant le score IDF suivant.
TF-IDF capte efficacement les statistiques locales et globales des mots à travers les documents et peut être utilisée dans diverses tâches de fouille de texte comme la classification de documents et le classement des moteurs de recherche.
Example 3.2
['and' 'awesome' 'is' 'learning' 'machine' 'mining' 'text'][[0. 0.53309782 0.53309782 0. 0.37930349 0.37930349
0.37930349]
[0.53309782 0. 0. 0.53309782 0.37930349 0.37930349
0.37930349]]Les word embeddings, encore appelés word2vec sont des modèles développés par une équipe de recherche de Google, utilisés pour le plongement lexical des mots (word embedding). Ces modèles représentent les mots dans un espace vectoriel continu où des mots ayant des significations similaires sont proches l’un de l’autre.
Deux modèles ont été initialement proposées pour apprendre les Word2vec:
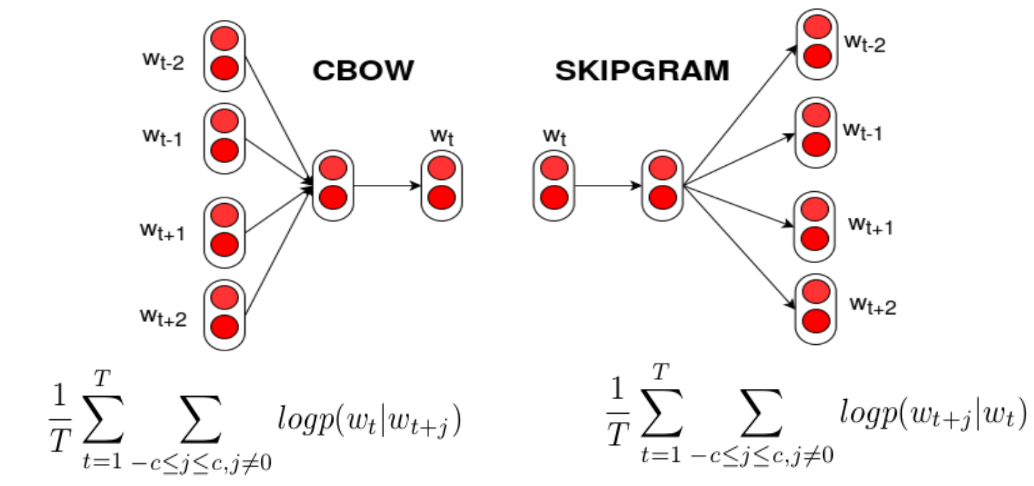
Le modèle CBOW prédit un mot cible à partir des mots contextuels environnants. Bien qu’il n’utilise pas une formule mathématique simple, il suit un processus itératif pour ajuster les poids afin de maximiser la probabilité du mot cible étant donné les mots de contexte. La fonction objectif est de minimiser la log-likelihood négative suivante :
\[ \text{Loss} = -\dfrac{1}{T}\sum_{t=1}^T\sum_{j=-c; j\neq 0}^c\ln \mathbb{P}(w_t | w_{t+j}) \]
Inversement, le modèle Skip-gram utilise un mot cible pour prédire les mots du contexte. Il est efficace même avec des ensembles de données plus petits, car il met davantage l’accent sur chaque contexte de mot.
La fonction objectif est également de minimiser la log-likelihood négative, mais appliquée aux mots de contexte
\[ \text{Loss} = -\dfrac{1}{T}\sum_{t=1}^T\sum_{j=-c; j\neq 0}^c\ln \mathbb{P}(w_{t+j} | w_{t}) \]
Example 3.3 (Word2vec)
Example 3.4 (Word2vec using CBOW trained on our data)
from gensim.models import Word2Vec
import gensim.downloader as api
# Load dataset
dataset = api.load("text8") # Loading a sample dataset
data = [d for d in dataset]
## Build model from data for size 100
#model = Word2Vec(sentences=data, vector_size=100, window=5, min_count=5, workers=4, sg=1)
## Save model localy
# model.save("word2vec.model")
## Loading a pre-trained model saved localy
model = Word2Vec.load("word2vec.model")
## Output vector for "machine"
print(model.wv['computers']) # Output the vector for 'machine'[-0.08177646 -0.04721823 -0.0084288 -0.5440348 -0.49569806 -0.82671654
0.45709997 0.14457856 -0.2976585 -0.7010779 0.35507697 -0.15874383
-0.35707662 -0.06684335 -0.41187024 -0.21161482 -0.26212868 -0.3531346
0.14464274 -0.3762366 -0.15199009 0.28958023 -0.01335368 -0.4740719
-0.14699289 0.42096254 -0.18640143 -0.25325784 0.09473351 0.490456
0.23942786 0.22735459 0.01591891 -0.5481382 -0.23617388 0.18345018
0.1165956 -0.30012906 0.06395388 -0.1231276 0.07019033 -0.69295317
0.47381857 0.5015437 0.18693608 -0.49193674 0.21535106 0.06887287
0.89489233 -0.4699952 -0.0837277 -0.23584175 -0.29335603 -0.6844307
-0.1754298 -0.211238 0.11446599 -0.5221362 0.02190363 0.39874783
0.77176154 0.06587946 0.73108566 0.16316323 0.16296148 0.22495109
-0.03173758 0.25898948 0.25877053 0.17289722 -0.27477127 0.3868899
-0.08321273 0.3228152 0.71440005 0.09718404 0.39029294 0.26212582
0.04121456 -0.08270923 0.04002508 -0.26657498 -0.32126236 -0.1005071
0.3536845 -0.15622264 0.53301615 0.35931632 0.75743634 0.35412425
0.22862287 0.566741 -0.01272407 0.5784754 0.15826175 0.47877672
0.11986806 -0.11080297 -0.85132957 -0.18185179]Le Doc2Vec, également connu sous le nom de Paragraph Vector, est une extension du modèle Word2Vec, développée pour générer des représentations vectorielles de passages de texte plus longs, tels que des phrases, des paragraphes ou des documents entiers. Cette méthode permet de capturer le contexte du document dans un vecteur dense, offrant une représentation riche et significative pour les tâches de NLP.
Applications de Doc2Vec
Classification de documents : Utiliser les vecteurs de documents comme caractéristiques d’entrée pour les classificateurs.
Systèmes de recommandation : Recommander des documents similaires basés sur la similarité des vecteurs.
Clustering de documents : Regrouper des documents similaires ensemble dans des clusters.
Il existe deux principales architectures de Doc2Vec :
Dans le modèle Distributed Memory (DM), le vecteur du document est combiné avec les vecteurs des mots pour prédire le prochain mot dans un contexte donné. Cette approche est similaire à CBOW dans Word2Vec, mais inclut un vecteur unique pour le document entier.
Le modèle DBOW fonctionne de manière similaire au modèle Skip-gram de Word2Vec. Il prédit les mots aléatoires à partir du vecteur de document, sans tenir compte de l’ordre des mots, ce qui en fait une sorte de modèle de prédiction de contexte à partir du document.
Example 3.5 (Doc2Vec avec Gensim) Voici comment vous pouvez utiliser Gensim pour entraîner un modèle Doc2Vec sur un ensemble de documents.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
# Préparation des documents
documents = ["Intelligence artificielle et apprentissage automatique",
"Analyse de données et statistiques",
"Réseaux de neurones pour le traitement du langage naturel"]
# Tagging des documents
tagged_data = [TaggedDocument(words=doc.split(), tags=[str(i)]) for i, doc in enumerate(documents)]
# Configuration et entraînement du modèle
model = Doc2Vec(vector_size=50, window=2, min_count=1, workers=4, epochs=40)
model.build_vocab(tagged_data)
model.train(tagged_data, total_examples=model.corpus_count, epochs=model.epochs)
# Utilisation des vecteurs de document
vector = model.dv['0'] # Vecteur pour le premier document
print(vector)[-0.01071054 -0.01215361 -0.02007367 0.01725166 0.0069106 0.00049752
-0.01998681 -0.01024272 -0.01955914 0.00412338 0.0058042 0.00927281
-0.00861882 -0.00652446 -0.00596788 -0.01780449 0.00427601 0.01870152
-0.01921242 -0.00684576 -0.00746745 0.00548462 -0.01165934 0.00543643
0.01134803 -0.01623436 -0.01702837 -0.02007534 0.01003998 -0.01858194
0.011931 0.0137205 -0.01327367 -0.0090181 -0.00261293 0.00324049
-0.00282095 -0.01719937 -0.00749509 0.00336366 -0.00393404 -0.01453625
0.00842661 -0.01765681 0.0054681 -0.00916087 0.00145246 -0.00398234
0.01106439 -0.01622829]La similarité entre termes est une mesure qui évalue à quel point deux mots sont proches en termes de signification ou d’usage dans un langage ou dans un corpus. Cette mesure est cruciale pour de nombreuses applications de NLP telles que la synonymie, la recherche sémantique, et l’amélioration des interfaces de dialogue.
La représentation des termes en vecteur se prête bien à l’évaluation de la similarité entre termes. On utilise très souvent la similarité cosinus:
\[ \cos\left(t_1, t_2\right)=\dfrac{\langle t_1,t_2\rangle}{\|t_1\|\|t_2\|} \]
Example 3.6 (Simiarité entre termes)
from gensim.models import Word2Vec
# Supposons que 'model' est votre modèle Word2Vec chargé
word1 = "computer"
word2 = "machine"
## Loading a pre-trained model saved localy
model = Word2Vec.load("word2vec.model")
# Calcul de la similarité cosinus entre les vecteurs des deux mots
similarity = model.wv.similarity(word1, word2)
print(f"La similarité entre '{word1}' et '{word2}' est de : {similarity:.2f}")La similarité entre 'computer' et 'machine' est de : 0.61Applications de la Similarité entre Termes
Systèmes de recommandation de mots clés : Améliorer la pertinence des mots clés suggérés en se basant sur leur similarité sémantique.
Interface de dialogue : Utiliser la similarité entre termes pour améliorer la compréhension des requêtes des utilisateurs.
Traduction automatique et localisation de contenu : Identifier des termes similaires dans différentes langues pour améliorer la qualité des traductions.
La similarité entre documents évalue à quel point deux textes sont proches en contenu ou en thème. Cette mesure est essentielle pour des applications comme:
La Recherche d’Information: Améliorer la pertinence des résultats de recherche en identifiant des documents similaires.
Détection de Plagiat: Identifier les similitudes textuelles qui peuvent indiquer du contenu copié.
Systèmes de Recommandation de Contenu: Suggérer des documents pertinents basés sur la similarité avec les documents consultés précédemment.
Example 3.7 (À partir de TF-IDF avec Scikit-Learn)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Définition des documents
documents = [
"L'intelligence artificielle transforme le monde.",
"Le monde change avec l'évolution de l'intelligence artificielle."
]
# Transformation TF-IDF
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
# Calcul de la similarité cosinus
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print(cosine_sim)[[1. 0.47433071]
[0.47433071 1. ]]Example 3.8 (À partir de Doc2Vec avec GenSim)
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
# Préparation des documents
documents = [
TaggedDocument(words=["intelligence", "artificielle", "monde", "transformer"], tags=[0]),
TaggedDocument(words=["monde", "changer", "évolution", "intelligence", "artificielle"], tags=[1])
]
# Entraînement du modèle Doc2Vec
model = Doc2Vec(documents, vector_size=40, window=2, min_count=1, workers=4)
# Calcul de la similarité
similarity = model.dv.similarity(0, 1)
print(f"Similarité entre les documents: {similarity:.2f}")Similarité entre les documents: 0.03Analyse de sentiments : Utiliser TF-IDF pour identifier des mots clés significatifs dans les avis.
Classification de documents : Utiliser les embeddings de mots pour améliorer la précision des modèles de classification de texte.
Récupération d’informations : Employer BoW pour construire des systèmes simples de recherche de documents.
Exercise 3.1 (TF-IDF) Objectif : Évaluer la similarité entre plusieurs documents pour identifier les documents qui traitent de sujets similaires.
Données : Utilisez l’extrait suivant de textes pour l’exercice.
Instructions :
Prétraitement des Textes : Nettoyez et préparez les documents pour l’analyse. Cela peut inclure la tokenisation et la suppression des mots vides.
Calcul de TF-IDF : Convertissez les documents nettoyés en une matrice TF-IDF.
Calcul de Similarité Cosinus : Calculez la similarité cosinus entre les documents pour déterminer quels documents sont les plus similaires entre eux.
Interprétation des Résultats : Analysez et discutez les résultats obtenus. Quels documents sont les plus similaires ? Est-ce conforme aux attentes basées sur leur contenu ?
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Liste des documents
documents = [
"Le machine learning est une branche de l'intelligence artificielle.",
"L'intelligence artificielle applique des algorithmes avancés pour résoudre des problèmes.",
"Les économies modernes se concentrent sur l'innovation technologique.",
"L'apprentissage profond améliore le machine learning."
]Exercise 3.2 (Doc2vec) Objectif : Utiliser le modèle Doc2Vec pour créer des embeddings de documents et évaluer la similarité entre différents documents afin d’identifier ceux qui traitent de sujets similaires.
Données : Utilisez l’extrait suivant de textes pour l’exercice.
Instructions :
Prétraitement des Textes : Préparez les documents pour l’analyse, en les nettoyant et en appliquant la tokenisation.
Création et Entraînement du Modèle Doc2Vec : Utilisez Gensim pour créer et entraîner un modèle Doc2Vec avec les documents.
Calcul de Similarité : Calculez la similarité entre les embeddings des documents pour déterminer quels documents sont les plus similaires.
Interprétation des Résultats : Discutez des résultats obtenus en termes de similarité des sujets traités dans les documents.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
# Documents
documents = [
"Exploration de l'espace avec des satellites et des missions habitées.",
"L'utilisation des drones pour la livraison de colis.",
"La technologie des satellites améliore la navigation globale.",
"Les missions spatiales habitées augmentent notre compréhension de l'univers."
]
# Préparation des documents taggés
tagged_data = [TaggedDocument(words=word_tokenize(doc.lower()), tags=[str(i)]) for i, doc in enumerate(documents)]
# Création du modèle Doc2Vec
model = Doc2Vec(vector_size=40, window=2, min_count=1, epochs=30)Questions de Réflexion :
Quels sont les avantages et les inconvénients de l’utilisation de Doc2Vec par rapport à d’autres méthodes comme TF-IDF?
Comment les paramètres du modèle Doc2Vec, tels que la taille du vecteur et le nombre d’epochs, influencent-ils les résultats?