Dans un des chapitres précédents, nous avons appris a transformé un corpus de documemnts en Term-Document Matrix, dans laquelle la dimension de représentation des tokens (termes) est le nombre \(d\) de documents, et celui de représentation des documents est le nombre \(n\) de tokens (mots par exemple).
L’Analyse Sémantique Latente (LSA = Latent Semantic Analysis) vise à réduire la dimension de représentation des termes en un nombre optimal de dimensions latentes, permettant ainsi une visualisation des similarités entre termes et documents. Cette analyse sert aussi d’étape préliminaire pour d’autre analyses telles que la classification non-supervisée des documents (Topic Analysis). On peut se servir pour cela de la similarité cosinus dans l’espace des termes.
4.1 LSA
La LSA est une application de la décomposition SVD de la Term-Document Matrix que nous notons \(A\) qui permet d’approximer cette dernière par une matrice \(B\) tel que \(rg([A]_q)< rg(A)\) au sens des moindres carrés, où \(rg([A]_q)=q<rg(A)=r\).
4.1.1 Décomposition SVD
Soit \(A\in\mathbb{R}^{t*d}\) de rang \(rg(A)=r_A\).
La décompoition SVD de \(A\) est donnée par \[
A = U\Lambda {}^tV,
\]
\(U\in\mathbb{R}^{t*d}\) est une matrice unitaire
\(\Lambda\in\mathbb{R}^{d*d}\) est une matrice diagonale ayant les coefficients diagonaux \(\lambda_k\geq 0\), dont exactement \(r\) sont \(>0\) et distincts
\({}^tV\in\mathbb{R}^{d*d}\) est une matrice unitaire
Propriétés
Les \(\lambda_k\) sont les valeurs singulières de \(A\), ie les racines des valeurs propres de \({}^tAA\).
Les colonnes de \({}^tV\) sont les vecteurs propres (orthonormés) associés aux valeurs propres \(\lambda_k^2\) de \({}^tAA\)
Les Les colonnes de \(^{}U\) sont les vecteurs propres (orthonormés) associés aux valeurs propres \(\lambda_k^2\) de \(A{}^tA\)
Notes
\({}^tAA\) et \(A{}^tA\) ont les mêmes valeurs propres \(>0\).
Les \(\lambda_k>0\) sont rangés dans l’ordre décroissant sur la diagonale de \(\Lambda\), et les permutation associées sont aussi appliquées aux colonnes de \({}^tV\) et aux lignes de \(U\).
Prop
Soit \(0<q<r\). Notons
\([U]_q\in\mathbb{R}^{t*q}\) la sous-matrice de \(U\) constituée des \(q\) premières colonnes
\([\Lambda]_q\in\mathbb{R}^{q*q}\) la sous-matrice de \(\Lambda\) constituée des \(q\) premières lignes et des \(q\) premières colonnes
\([{}^tV]_q\in\mathbb{R}^{q*d}\) la sous-matrice de \({}^tV\) constituée des \(q\) premières lignes.
Alors \([A]_q=[U]_q[\Lambda]_q[{}^tV]_q\) est une solution au pb d’optimisation
\[
\min_{rg(X)=q}\|A-X\|^2
\]
4.1.2 Représentation des termes et documents dans les dimensions latentes
Supposons que l’on retienne \(q\) dimensions latentes qu’on peut encore appelées concepts:
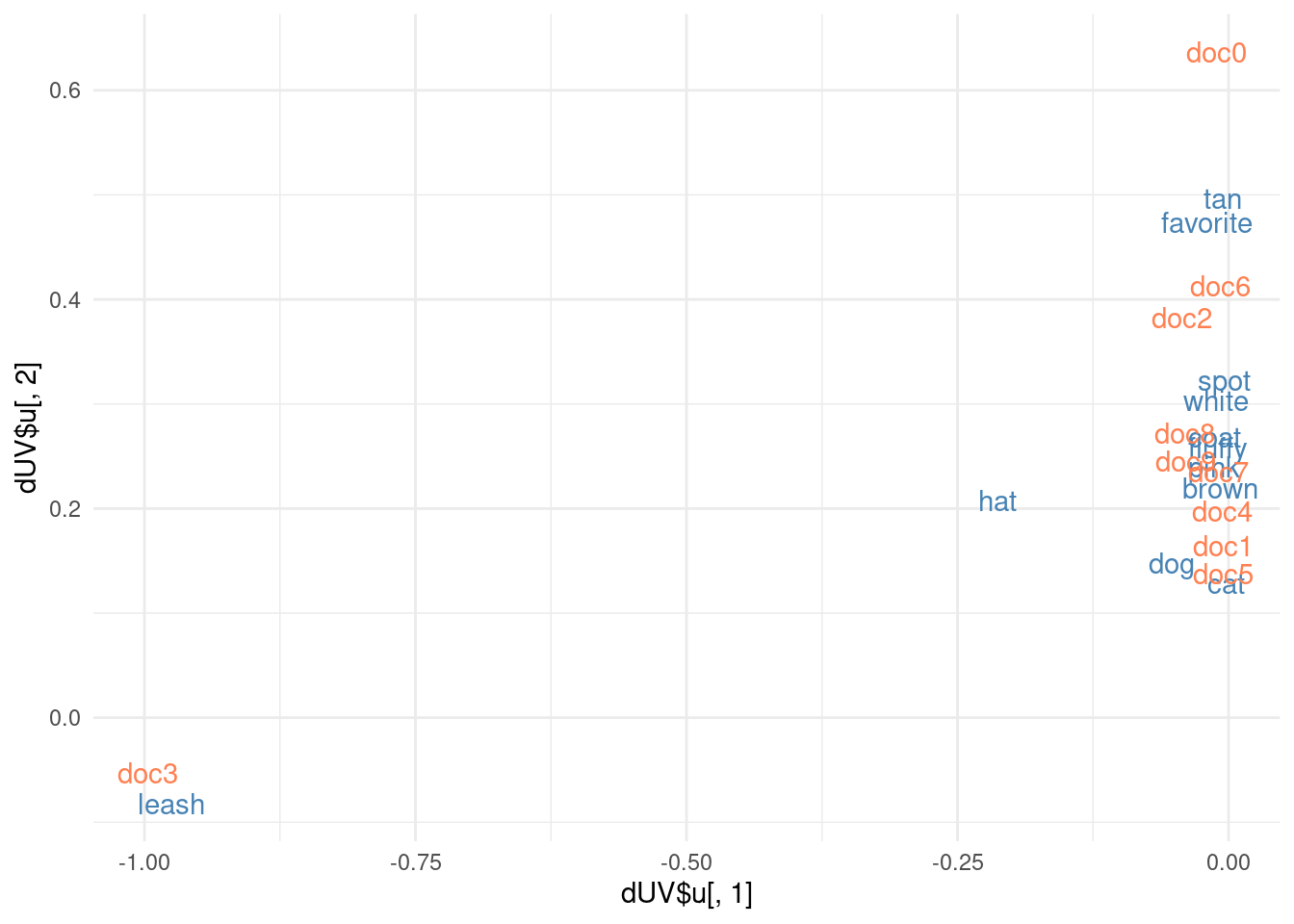
La ligne \(i\) de la matrice \([U]_q\), que nous notons \(\widehat{t}_i\) donne les importances du terme \(i\) pour les différents concepts
La colonne \(j\) de la matrice \([{}^tV]_q\), que nous notons \(\widehat{d}_j\) donne les importances du document \(j\) pour les différents concepts.
Notes: Dans l’espace \(\mathbb{R}^q\) des concepts:
Les termes sont représentés par les \(\widehat{t}_i\)
La matrice des similarités entre termes est \[
\left(\cos\left(\widehat{t}_i,\widehat{t}_{i'}\right)\right)_{i,i'}
\]
Celle des documents \[
\left(\cos\left(\widehat{d}_j,\widehat{d}_{j'}\right)\right)_{j,j'}
\]
4.2.3.1Query
L’analyse sémantique latente peut servir de base pour faire des recherches de documents dans un corpus à partir d’un ensemble de mots clés. Autrement dit, cette analyse permet de construire un moteur de recherche de documents par mots clés. Un mot clé est tout mot apparaissant dans les termes.
Principe
Soit \(w\) un ensemble de mots clés, c’est-à-dire un tuple de mots du dictionnare associé au corpus en question. Par exemple, si le dictionnaire de termes est dict=(cameroun, mange, montagne, marché, soleil), \(w\) peut être (mange, soleil).
\(w\) est un pseudo-document que l’on représente dans l’espace des documents par le tuple \(w = (0, 1, 0, 0, 1)\) d’indicatrices des mots.
Les coordonnées de \(w\) dans les dimensions latentes sont données par \[
query(w) = {}^tw[U]_q[\Lambda]_q^{-1}\in\mathbb{R}^q.
\]
On calcule alors les similarités entre le pseudo document \(w\) et les documents du corpus
Puis le classement des documents du corpus est obtenu selon les valeurs décroissantes des similarités précédentes.
4.2.3.2 Classification non-supervisée
Ces matrices peuvent servir à la classification (non-supervisée) des termes ou documents, par exemple une classification hiérarchique ascendante ou par la méthode des \(K\)-means.
4.3 Choix de la dimension \(q\)
Le choix de la dimension est très souvent fonction de la suite de l’analyse.
Par exemple:
Si le but est de visualiser les nuages de termes et|ou des documents, on choisira en général \(q=2\), ou maximum \(3\);
4.3.1 Par seuillage de la variabilité expliquée
Si LSA n’est qu’une étape intermédiaire de l’analyse du corpus en question, il vaut mieux tenir compte de la part de variabilité expliquée par les dimensions latentes retenues. Une mesure de la part de la vériabilité expliquée par les \(q\) dimensions latentes est \[
\dfrac{\sum_{k=1}^q\lambda_k}{\sum_{k=1}^d\lambda_k}.
\] Une idée intuitive est de sélectionner la plus petite dimension \(q\) pour laquelle la part de la variabilité expliquées est \(\geq\) à un seuil fixé à l’avance (par exemple \(75\%\)).
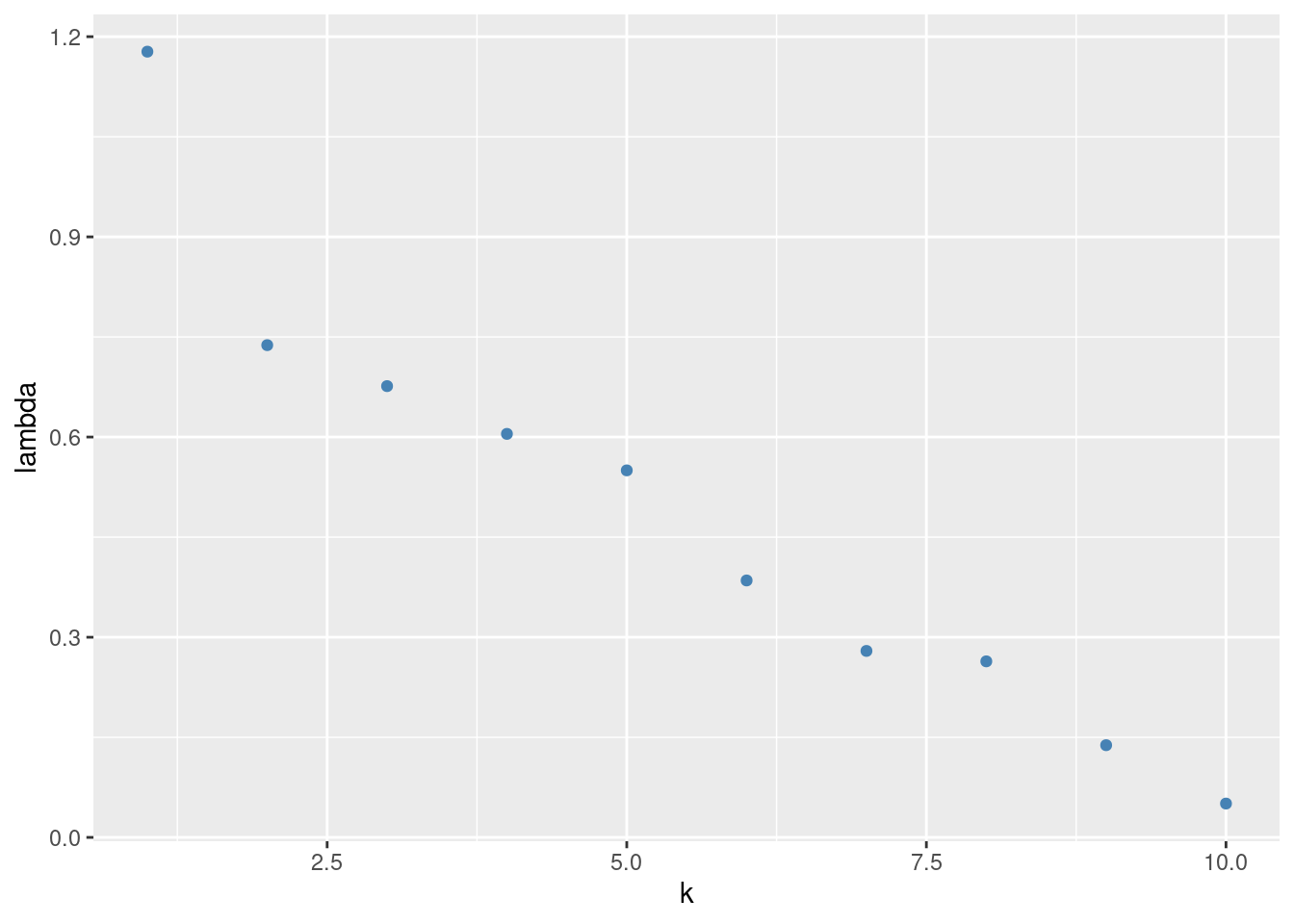
4.3.2 Éboulie des valeurs singulières
Il s’agit de rechercher un coude dans le graphique des valeurs singulières.
4.4 TP
On considère les documents suivants:
Code
docs =data.frame(docs =paste("doc", 0:9, sep=""),text =c("Favorite dog fluffy tan","Dog brown cat brown","Favorite hat brown coat pink","Dog hat leash leash","Fluffy coat brown coat","Dog brown fluffy brown coat","Dog white brown spot","White dog pink coat brown dog fluffy","Fluffy dog brown hat favorite","Fluffy dog white coat hat" ))
Tokenisation et construction de la Term-Document Matrix