L’estimation statistique repose sur des concepts fondamentaux de probabilités et de statistiques. Avant d’introduire les différentes méthodes d’estimation, il est essentiel de maîtriser les notions de variables aléatoires, lois de probabilité, moments et théorèmes fondamentaux qui justifient l’inférence statistique.
Ce chapitre a pour objectifs :
De rappeler les concepts clés en probabilités et statistiques nécessaires à l’estimation.
D’introduire les principales distributions de probabilité utilisées en statistique inférentielle.
De présenter les théorèmes fondamentaux qui justifient l’estimation statistique, notamment la loi des grands nombres et le théorème central limite.
Les connaissances acquises dans ce chapitre serviront de base pour les techniques d’estimation abordées dans les chapitres suivants.
Rappels sur les variables aléatoires et leurs distributions
Définition d’une variable aléatoire
Une variable aléatoire est une fonction qui associe une valeur numérique à chaque issue d’une expérience aléatoire. Elle est généralement définie sur un espace probabilisé \((\Omega, \mathcal{F}, P)\), où : - \(\Omega\) est l’ensemble des résultats possibles de l’expérience, - \(\mathcal{F}\) est une tribu d’événements sur \(\Omega\), - \(P\) est une mesure de probabilité associée.
On distingue principalement deux types de variables aléatoires : - Variables aléatoires discrètes : elles prennent un nombre fini ou dénombrable de valeurs possibles. - Variables aléatoires continues : elles peuvent prendre toutes les valeurs d’un intervalle réel.
Lois de probabilité
La loi de probabilité d’une variable aléatoire décrit la répartition de ses valeurs possibles et leurs probabilités associées.
Variables aléatoires discrètes
Une variable aléatoire discrète \(X\) est caractérisée par sa fonction de probabilité (ou fonction de masse de probabilité, FMP), définie par : \[
P(X = x_i) = p_i, \quad \text{avec} \quad \sum_{i} p_i = 1.
\]
Example 1 (Lois discrètes :)
Loi de Bernoulli \(B(p)\) : \(X\) prend les valeurs \(\{0,1\}\) avec \(P(X=1) = p\) et \(P(X=0) = 1-p\).
Loi binomiale \(B(n,p)\) : modélise le nombre de succès dans \(n\) essais indépendants de Bernoulli.
Loi de Poisson \(P(\lambda)\) : utilisée pour modéliser les événements rares sur une période donnée.
Variables aléatoires continues
Une variable aléatoire continue \(X\) est caractérisée par sa fonction de densité de probabilité (FDP) \(f_X(x)\), qui satisfait : \[
P(a \leq X \leq b) = \int_{a}^{b} f_X(x) \, dx.
\]
Example 2 (Lois continues)
Loi uniforme \(U(a, b)\) : densité constante sur \([a, b]\).
Loi normale \(N(\mu, \sigma^2)\) : distribution en forme de cloche définie par la densité : \[
f_X(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\dfrac{(x - \mu)^2}{2\sigma^2}}, \quad x \in \mathbb{R}.
\]
Loi exponentielle \(Exp(\lambda)\) : modélise le temps d’attente entre deux événements indépendants.
Fonction de répartition
La fonction de répartition d’une variable aléatoire \(X\) est définie par : \[
F_X(x) = P(X \leq x).
\] Elle permet de calculer les probabilités cumulées et caractérise complètement la distribution de \(X\).
Moments et caractéristiques des distributions
Les moments d’une variable aléatoire sont des valeurs numériques qui permettent de caractériser sa distribution. Ils fournissent des informations essentielles sur la tendance centrale, la dispersion et la forme de la distribution.
Espérance mathématique (Moyenne)
L’espérance d’une variable aléatoire \(X\), notée \(E(X)\), représente la moyenne théorique des valeurs prises par \(X\). Elle est définie comme :
Pour une variable discrète :\[
E(X) = \sum_{i} x_i P(X = x_i)
\]
Pour une variable continue :\[
E(X) = \int_{-\infty}^{+\infty} x f_X(x) \, dx
\]
L’espérance est un indicateur de tendance centrale qui donne une idée de la valeur moyenne autour de laquelle les observations sont réparties.
Variance et écart-type
La variance, notée \(V(X)\) ou \(\sigma^2\), mesure la dispersion des valeurs de \(X\) autour de sa moyenne. Elle est définie par :
\[
V(X) = E[(X - E[X])^2] = E[X^2] - (E[X])^2.
\]
L’écart-type, noté \(\sigma\), est la racine carrée de la variance :
\[
\sigma_X = \sqrt{V(X)}.
\]
Il exprime la dispersion en conservant l’unité de mesure de la variable \(X\). Une grande valeur de \(\sigma\) indique que les valeurs de \(X\) sont fortement dispersées autour de la moyenne.
Moments d’ordre supérieur
Les moments d’ordre supérieur permettent de caractériser la forme de la distribution.
Moment d’ordre \(k\) (par rapport à l’origine) : \[
E[X^k] = \sum_{i} x_i^k P(X = x_i) \quad \text{(discret)}
\]\[
E[X^k] = \int_{-\infty}^{+\infty} x^k f_X(x)dx \quad \text{(continu)}
\]
Les moments d’ordre supérieur, en particulier les moments d’ordre 3 et 4, sont utilisés pour décrire l’asymétrie et l’aplatissement d’une distribution.
Asymétrie (Coefficient de Skewness)
Le coefficient d’asymétrie, ou skewness, noté \(\gamma_1\), mesure la symétrie de la distribution par rapport à sa moyenne :
Théorèmes fondamentaux : loi des grands nombres, théorème central limite
L’estimation statistique repose sur des résultats fondamentaux en probabilités, notamment la loi des grands nombres (LGN) et le théorème central limite (TCL). Ces théorèmes garantissent que les estimations obtenues à partir d’un échantillon convergent vers la valeur réelle du paramètre recherché.
Loi des Grands Nombres (LGN)
La loi des grands nombres formalise l’idée intuitive selon laquelle la moyenne empirique d’un grand nombre d’observations indépendantes se rapproche de l’espérance mathématique.
Énoncé de la Loi des Grands Nombres
Soit \(X_1, X_2, \dots, X_n\) une suite de variables aléatoires indépendantes et identiquement distribuées (i.i.d.) ayant une espérance finie \(E(X) = \mu\). On définit la moyenne empirique :
Cela signifie que la moyenne empirique \(\overline{X}_n\)converge presque sûrement vers \(\mu\), c’est-à-dire que la probabilité que cette convergence ne se produise pas est nulle.
Interprétation et Conséquences
La LGN justifie l’utilisation de la moyenne empirique comme estimation de l’espérance.
Plus la taille de l’échantillon augmente, plus la moyenne empirique est proche de la moyenne théorique.
En pratique, pour un grand échantillon, la moyenne observée dans les données est une bonne approximation de l’espérance mathématique.
Théorème Central Limite (TCL)
Le théorème central limite (TCL) est l’un des résultats les plus importants en statistique. Il explique pourquoi de nombreuses distributions empiriques suivent une loi normale, même si les données individuelles ne sont pas distribuées normalement.
Énoncé du Théorème Central Limite
Soit \(X_1, X_2, \dots, X_n\) une suite de variables aléatoires i.i.d. de moyenne \(\mu\) et de variance finie \(\sigma^2\). Alors, lorsque \(n\) est grand, la variable centrée et réduite :
suit approximativement une loi normale standard \(\mathcal{N}(0,1)\) :
\[
Z_n \xrightarrow{d} \mathcal{N}(0,1), \quad \text{(convergence en loi)}.
\]
Cela signifie que, même si les \(X_i\) ne sont pas normalement distribuées, la moyenne empirique \(\overline{X}_n\) suit une distribution approximativement normale dès que \(n\) est suffisamment grand.
Conséquences du TCL
Pour des échantillons de grande taille, la distribution des moyennes empiriques est toujours normale, quelle que soit la distribution initiale des \(X_i\) (sous certaines conditions de moments finis).
Le TCL est à la base de la construction des intervalles de confiance et des tests statistiques.
Il explique pourquoi la loi normale apparaît si souvent en pratique (exemple : distribution des erreurs de mesure).
Comparaison entre la Loi des Grands Nombres et le Théorème Central Limite
Propriété
Loi des Grands Nombres
Théorème Central Limite
Type de convergence
En probabilité (faible) ou presque sûre (forte)
En loi
Condition principale
\(E(X) = \mu\) existe
\(V(X) = \sigma^2\) existe et est finie
Résultat
La moyenne empirique converge vers \(\mu\)
La distribution des moyennes empiriques devient normale
Utilisation
Estimation de paramètres
Inférence statistique, tests d’hypothèses
Applications et Illustrations
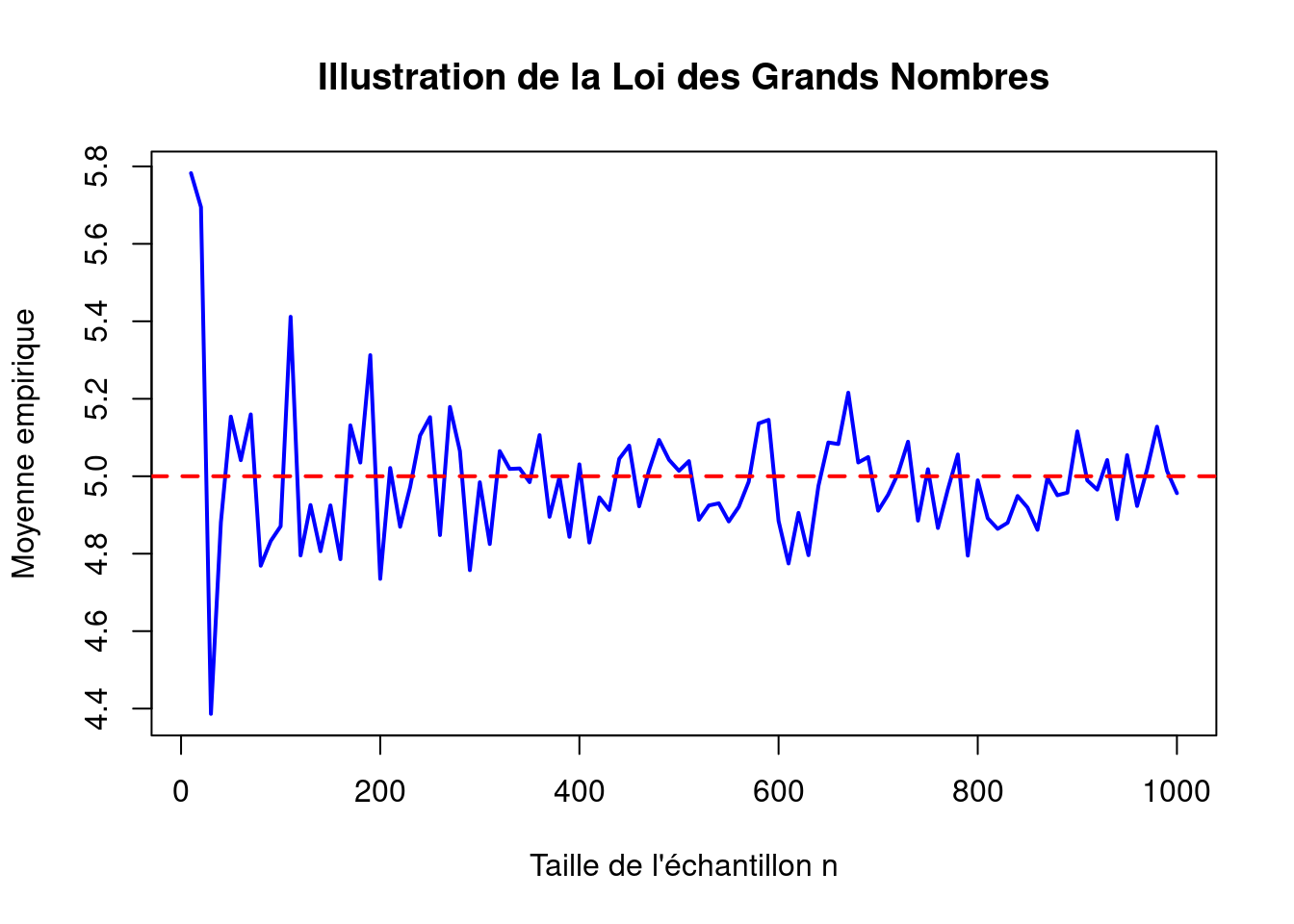
Illustration de la LGN
Prenons un jeu de données simulé représentant les gains moyens d’un casino. On effectue \(n\) tirages indépendants d’une loi uniforme entre \(0\) et \(10\), puis on observe comment la moyenne empirique évolue avec \(n\) :
set.seed(123)n_values <-seq(10, 1000, by=10)means <-sapply(n_values, function(n) mean(runif(n, min=0, max=10)))plot(n_values, means, type="l", col="blue", lwd=2,xlab="Taille de l'échantillon n",ylab="Moyenne empirique",main="Illustration de la Loi des Grands Nombres")abline(h=5, col="red", lwd=2, lty=2) # Espérance théorique
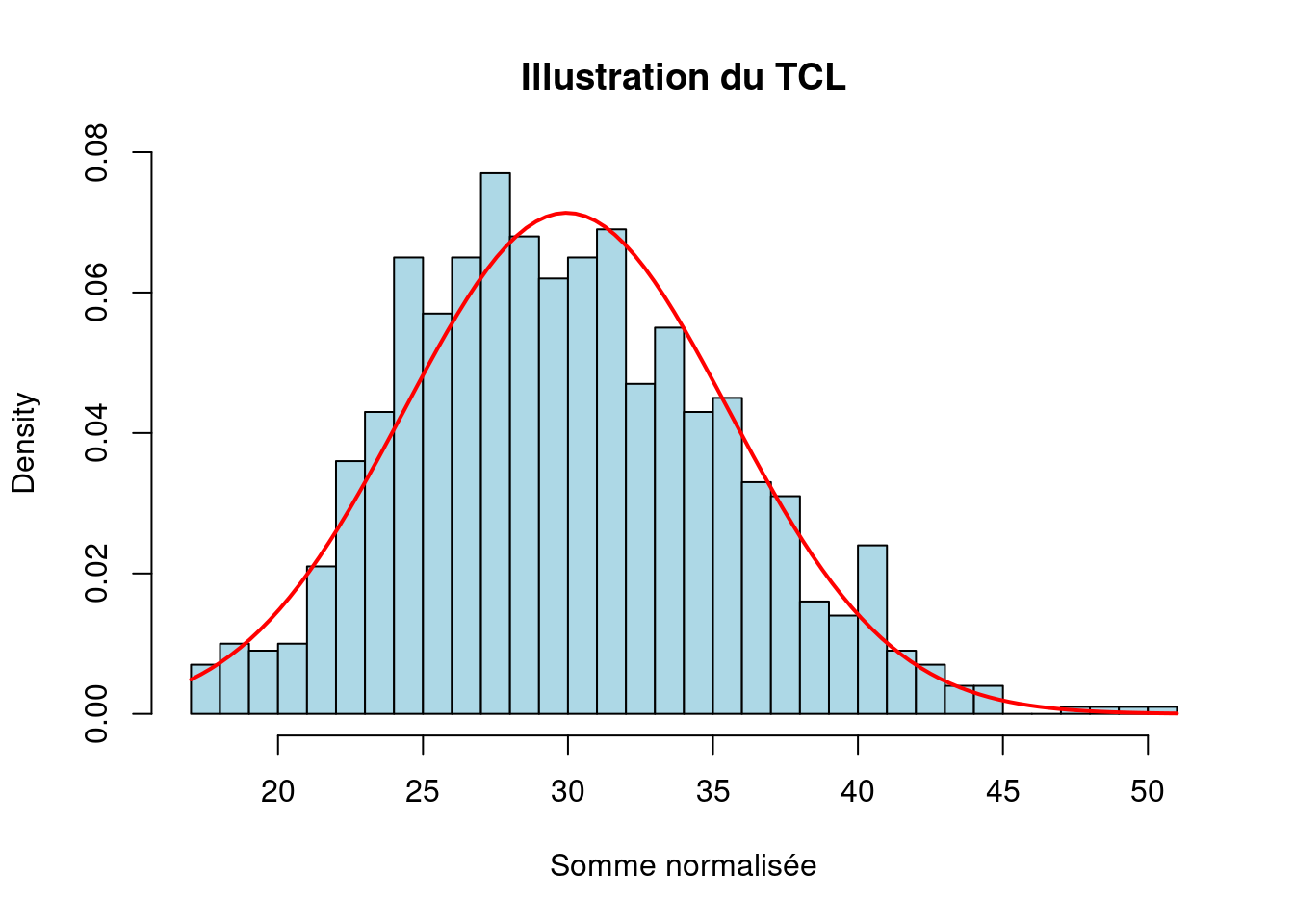
Illustration du TCL
On simule la somme de \(n\) variables de loi exponentielle et on compare la distribution normalisée à une loi normale :
L’inégalité de Markov fournit une borne supérieure pour la probabilité qu’une variable aléatoire prenne des valeurs supérieures à un certain seuil. Elle est particulièrement utile pour démontrer la loi des grands nombres et pour obtenir des résultats de concentration.
Énoncé de l’inégalité de Markov
Soit \(X\) une variable aléatoire positive, et soit \(a > 0\). Alors :
\[
P(X \geq a) \leq \frac{E[X]}{a}.
\]
Autrement dit, la probabilité que \(X\) dépasse un seuil \(a\) est au plus égale à l’espérance de \(X\) divisée par \(a\).
Proof. Par définition de l’espérance :
\[
E[X] = \int_0^{+\infty} P(X \geq x) \, dx.
\]
On peut décomposer cette intégrale en deux parties : pour \(x < a\) et pour \(x \geq a\). En remarquant que \(P(X \geq x) \geq P(X \geq a)\) pour tout \(x \geq a\), on obtient :
\[
E[X] \geq \int_{a}^{+\infty} a \cdot P(X \geq a) \, dx.
\]
Ce qui donne directement :
\[
E[X] \geq a \cdot P(X \geq a).
\]
D’où l’inégalité :
\[
P(X \geq a) \leq \frac{E[X]}{a}.
\]
Applications de l’inégalité de Markov
Contrôle de la probabilité des valeurs extrêmes
L’inégalité de Markov permet d’obtenir une borne supérieure sur la probabilité que \(X\) soit très grand. Par exemple, si \(E[X] = 10\), alors :
\[
P(X \geq 50) \leq \frac{10}{50} = 0.2.
\]
Cela signifie que la probabilité que \(X\) soit supérieur à 50 est au plus de 20%.
Démonstration de la loi faible des grands nombres
L’inégalité de Markov est utilisée pour prouver que la moyenne empirique \(\overline{X}_n\) converge en probabilité vers l’espérance \(E[X]\).
Cas particuliers : inégalité de Tchebychev
Une version plus forte de l’inégalité de Markov, l’inégalité de Tchebychev, s’obtient en appliquant l’inégalité de Markov à la variable aléatoire \((X - E[X])^2\) :
Cette inégalité montre que la probabilité qu’une variable aléatoire s’écarte de plus de \(k\) écarts-types de sa moyenne est bornée par \(1/k^2\), ce qui est essentiel pour comprendre la convergence des moyennes empiriques.
Lien avec la loi des grands nombres
L’inégalité de Markov et l’inégalité de Tchebychev sont des outils fondamentaux pour démontrer que :
Elles permettent de montrer que la probabilité d’un écart significatif entre la moyenne empirique et la moyenne théorique diminue lorsque \(n\) augmente.
Conclusion
La Loi des Grands Nombres (LGN) et le Théorème Central Limite (TCL) sont deux résultats fondamentaux en statistique :
La LGN garantit que la moyenne empirique converge vers la moyenne théorique. Le TCL montre que les moyennes d’échantillons suivent une loi normale pour un grand nombre d’observations, facilitant ainsi l’inférence statistique. Ces résultats justifient l’utilisation des techniques d’estimation et des tests statistiques que nous étudierons dans les prochains chapitres.
Exercices
Cette section propose une série d’exercices permettant de consolider les concepts abordés dans ce chapitre. Les exercices couvrent les notions de variables aléatoires, distributions, moments, et les théorèmes fondamentaux de la statistique.
Exercices sur les variables aléatoires et leurs distributions
Exercise 1 (Identification de variables aléatoires) Parmi les exemples suivants, déterminer si la variable est discrète ou continue et justifier votre réponse :
Le nombre de clients dans un magasin en une journée.
La température maximale enregistrée chaque jour.
Le nombre de buts marqués par une équipe de football lors d’un match.
La durée d’un appel téléphonique.
Exercise 2 (Fonction de probabilité et fonction de répartition) Soit \(X\) une variable aléatoire discrète prenant les valeurs \(\{0,1,2,3\}\) avec la fonction de probabilité suivante : \[
P(X=0) = 0.2, \quad P(X=1) = 0.4, \quad P(X=2) = 0.3, \quad P(X=3) = 0.1.
\]
Calculer la fonction de répartition \(F_X(x)\).
Représenter graphiquement la fonction de probabilité et la fonction de répartition.
Exercise 3 (Loi normale et loi exponentielle)
Montrer que si \(X \sim \mathcal{N}(\mu, \sigma^2)\), alors \(Z = \frac{X - \mu}{\sigma}\) suit une loi normale centrée réduite \(\mathcal{N}(0,1)\).
Soit \(X \sim \text{Exp}(\lambda)\) une variable exponentielle de paramètre \(\lambda\). Vérifier que \(E(X) = \frac{1}{\lambda}\) et \(V(X) = \frac{1}{\lambda^2}\).
Exercices sur les moments et caractéristiques des distributions
Exercise 4 (Calcul d’espérance et de variance) Soit \(X\) une variable aléatoire discrète de loi : \[
P(X = k) = \frac{c}{k^2}, \quad k = 1,2,3,4.
\] 1. Déterminer la constante \(c\). 2. Calculer l’espérance \(E(X)\) et la variance \(V(X)\).
Exercise 5 (Asymétrie et kurtosis)
Montrer que si \(X \sim \mathcal{N}(\mu, \sigma^2)\), alors le coefficient d’asymétrie \(\gamma_1\) est nul.
Calculer le kurtosis \(\gamma_2\) de la loi normale et interpréter le résultat.
Exercices sur les théorèmes fondamentaux
Exercise 6 (Vérification de l’inégalité de Markov) Soit \(X\) une variable aléatoire positive telle que \(E(X) = 5\). En utilisant l’inégalité de Markov, donner une borne supérieure pour :
\(P(X \geq 10)\).
\(P(X \geq 20)\).
Exercise 7 (Utilisation de l’inégalité de Tchebychev) Soit \(X\) une variable aléatoire de moyenne \(\mu = 10\) et d’écart-type \(\sigma = 2\). Appliquer l’inégalité de Tchebychev pour donner une borne supérieure pour :
\(P(|X - 10| \geq 4)\).
\(P(|X - 10| \geq 6)\).
Exercise 8 (Simulation de la loi des grands nombres) Écrire un programme en Python ou R qui génère un échantillon de taille \(n\) de variables uniformes sur \([0,1]\), puis calcule la moyenne empirique \(\overline{X}_n\) pour différentes valeurs de \(n\). Comparer cette moyenne avec l’espérance théorique.
Exercise 9 (Illustration du théorème central limite)
Générer 10 000 sommes de 30 variables exponentielles de paramètre \(\lambda = 1\) et représenter l’histogramme des résultats.
Superposer la densité de la loi normale obtenue par le théorème central limite et vérifier l’ajustement.
Problèmes avancés
Exercise 10 (Généralisation de l’inégalité de Markov) Montrer que pour toute fonction \(\varphi\) strictement croissante et positive : \[
P(X \geq a) \leq \frac{E[\varphi(X)]}{\varphi(a)}.
\] Appliquer ce résultat avec \(\varphi(X) = X^2\) pour obtenir une inégalité plus précise que celle de Markov.
Exercise 11 (Démonstration de la loi faible des grands nombres) Soit \(X_1, X_2, ..., X_n\) une suite de variables i.i.d. de moyenne \(\mu\) et de variance \(\sigma^2\). Montrer en utilisant l’inégalité de Tchebychev que pour tout \(\epsilon > 0\) : \[
P(|\overline{X}_n - \mu| \geq \epsilon) \leq \frac{\sigma^2}{n\epsilon^2}.
\] Conclure que \(\overline{X}_n\) converge en probabilité vers \(\mu\) lorsque \(n \to \infty\).