Votre Premier Test Statistique : Le t-test à un Échantillon
Partie 3 de notre série sur les tests statistiques
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 De la Théorie à la Pratique
Dans nos articles précédents, nous avons posé les fondations : la logique des tests d’hypothèses et le secret des lois d’échantillonnage. Nous savons maintenant pourquoi les tests fonctionnent. Il est temps de passer à la pratique !
Comment savoir si la performance moyenne de nos étudiants est significativement différente de la moyenne nationale ? Comment un producteur peut-il vérifier si ses paquets de café pèsent bien en moyenne 250g ?
Pour répondre à ces questions, nous allons utiliser notre premier véritable outil statistique : le t-test à un échantillon. C’est le test le plus simple et le plus fondamental pour comparer la moyenne d’un groupe à une valeur de référence.
2 Le Scénario Clé : Quand utiliser ce test ?
Le t-test à un échantillon est un outil de choix lorsque vous disposez d’une seule série statistique quantitative et que vous souhaitez la comparer à une valeur théorique de référence.
Example 1 (Une norme - Un objectif - Une ancienne mesure)Exemples concrets :
Contrôle Qualité : Une usine produit des vis qui doivent mesurer 50mm de long. On prélève un \(n\)-échantillon pour vérifier si la production est bien calibrée.
Analyse de Performance : Le temps de réponse moyen d’un site web était de 2 secondes. Après une mise à jour, on mesure le temps sur un nouvel échantillon pour voir s’il a changé.
Biologie : La température corporelle moyenne d’une espèce d’oiseau est supposée être de 41°C. Un chercheur mesure la température d’un échantillon pour confirmer cette hypothèse.
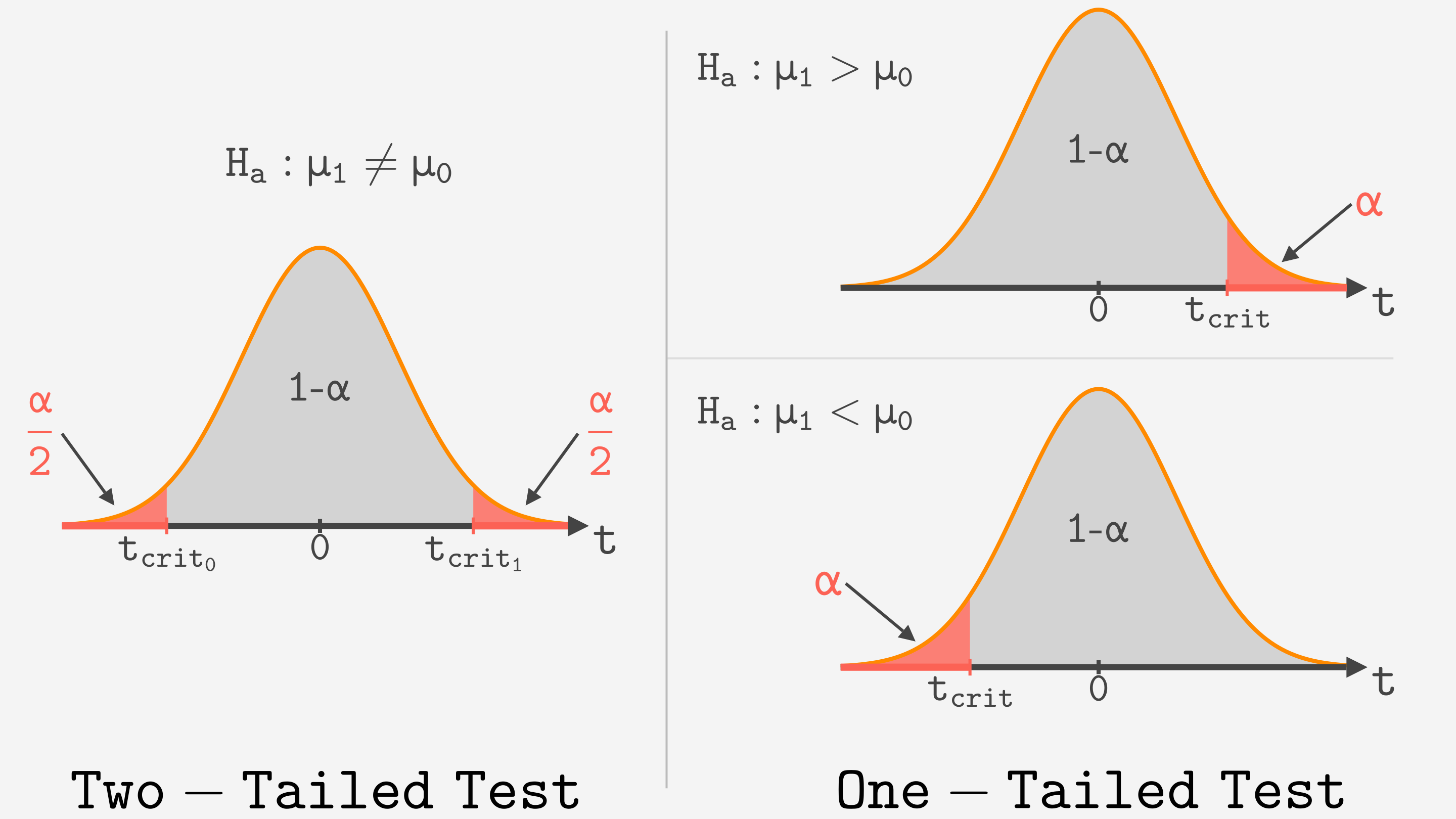
3 Pourquoi un “t-test” et pas un “Z-test” ?
Dans nos exemples théoriques sur les lois d’échantillonnage, nous avons utilisé la loi Normale (qui mène au Z-test) en supposant que nous connaissions l’écart-type de la population (\(\sigma\)).
Dans la vraie vie, c’est un luxe que nous n’avons presque jamais !
Le t-test est le test du praticien. Il est conçu pour les situations où l’écart-type de la population (\(\sigma\)) est inconnu. À la place, il utilise l’écart-type calculé à partir de notre échantillon (\(s\)).
Cette utilisation de \(s\) (une estimation) au lieu de \(\sigma\) (la vraie valeur) introduit un peu plus d’incertitude. Pour tenir compte de cette incertitude, nous n’utilisons pas la loi Normale, mais sa cousine : la distribution de Student.
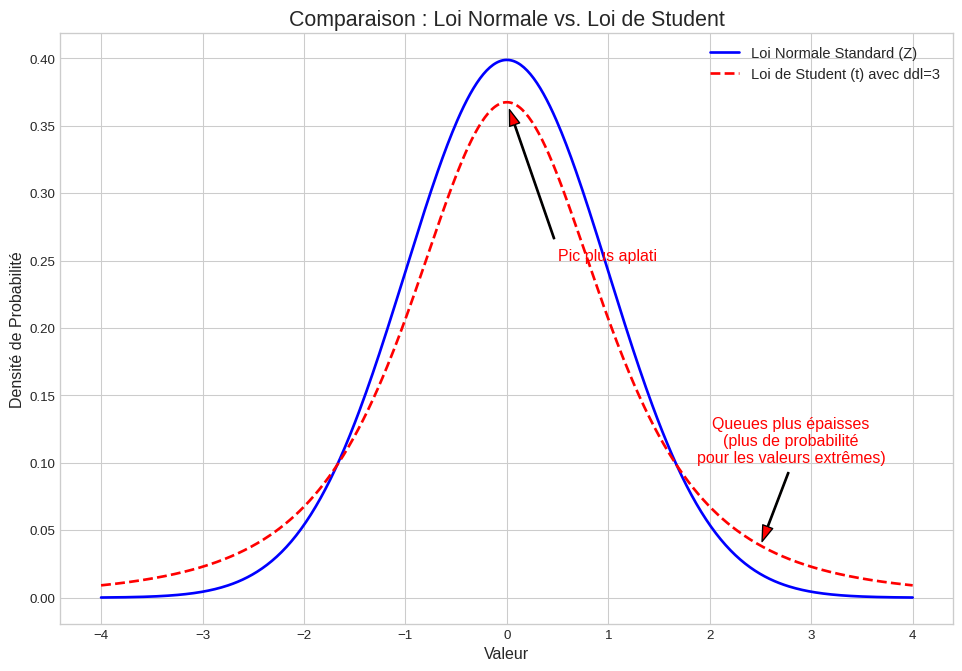
3.1 La Distribution de Student (ou loi de t)
Imaginez la loi de Student comme une loi Normale un peu plus humble. Elle est également en forme de cloche et symétrique autour de 0, mais elle est légèrement plus aplatie et ses “queues” sont plus épaisses.
Ces queues plus épaisses signifient qu’elle accorde une probabilité plus élevée aux valeurs extrêmes. C’est sa manière de dire : “Attention, nous travaillons avec une estimation (\(s\)), donc nous devons être un peu plus prudents avant de crier à la significativité !”
La forme exacte de la distribution de Student dépend d’un paramètre appelé les degrés de liberté (ddl), qui est simplement lié à la taille de l’échantillon (\(ddl = n - 1\)). Plus la taille de l’échantillon est grande, plus la distribution de Student se rapproche de la loi Normale.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import norm, t# --- Paramètres ---# Degrés de liberté pour la loi de Student.# Une petite valeur (comme 3) montre bien la différence.df =3# Création d'une plage de valeurs pour l'axe des xx = np.linspace(-4, 4, 500)# Calcul des densités de probabilité (PDF)pdf_normal = norm.pdf(x, loc=0, scale=1)pdf_student = t.pdf(x, df=df)# --- Création du graphique ---plt.style.use('seaborn-v0_8-whitegrid')fig, ax = plt.subplots(figsize=(12, 8))# Tracer les deux distributionsax.plot(x, pdf_normal, 'b-', linewidth=2, label='Loi Normale Standard (Z)')ax.plot(x, pdf_student, 'r--', linewidth=2, label=f'Loi de Student (t) avec ddl={df}')# --- Ajout des annotations pour clarifier les différences ---# Annotation pour le pic plus aplatiax.annotate('Pic plus aplati', xy=(0, t.pdf(0, df)), xytext=(0.5, 0.25), arrowprops=dict(facecolor='red', shrink=0.05, width=1, headwidth=8), fontsize=12, color='red')# Annotation pour les queues plus épaissesax.annotate('Queues plus épaisses\n(plus de probabilité\npour les valeurs extrêmes)', xy=(2.5, t.pdf(2.5, df)), xytext=(2.8, 0.1), ha='center', arrowprops=dict(facecolor='red', shrink=0.05, width=1, headwidth=8), fontsize=12, color='red')# --- Finalisation du graphique ---ax.set_title("Comparaison : Loi Normale vs. Loi de Student", fontsize=16)ax.set_xlabel("Valeur", fontsize=12)ax.set_ylabel("Densité de Probabilité", fontsize=12)ax.legend(loc='upper right', fontsize=11)ax.grid(True)plt.show()
Comparaison entre la distribution Normale standard et la distribution de Student (t).
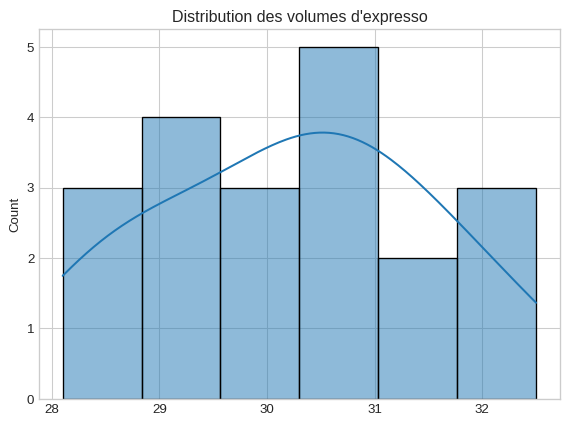
4 Atelier Pratique : La Machine à Café est-elle bien réglée ?
Un café de spécialité vient d’installer une nouvelle machine à expresso. Le fabricant assure qu’elle est réglée pour produire des “shots” de 30 ml en moyenne. Le propriétaire, sceptique, mesure le volume de 20 expressos pour vérifier.
Le volume moyen est-il significativement différent de 30 ml ?
import numpy as npfrom scipy import statsimport matplotlib.pyplot as pltimport seaborn as sns# --- Les données ---data = np.array([31.5, 28.9, 30.5, 32.1, 29.5, 30.1, 31.0, 28.5, 29.9, 30.8, 32.5, 28.1, 30.2, 31.2, 29.4, 30.9, 31.8, 29.0, 30.4, 28.2])# Valeur de référence à testermu_0 =30.0# --- Étape 1 : Poser les hypothèses ---# H0: La moyenne réelle est de 30 ml. (μ = 30)# H1: La moyenne réelle est différente de 30 ml. (μ ≠ 30)# C'est un test bilatéral car on cherche une différence dans n'importe quelle direction.print("--- Étape 1: Hypothèses ---")print(f"H0: μ = {mu_0}")print(f"H1: μ ≠ {mu_0}\n")# --- Étape 2 : Exploration et Vérification des hypothèses ---# Le t-test suppose que les données sont approximativement normales.# Une visualisation rapide est souvent suffisante pour un petit échantillon.sample_mean = np.mean(data)sample_std = np.std(data, ddof=1) # ddof=1 pour l'écart-type d'échantillonprint("--- Étape 2: Statistiques de l'échantillon ---")print(f"Taille de l'échantillon (n): {len(data)}")print(f"Moyenne de l'échantillon (x̄): {sample_mean:.2f} ml")print(f"Écart-type de l'échantillon (s): {sample_std:.2f} ml\n")# Visualisationsns.histplot(data, kde=True)plt.title("Distribution des volumes d'expresso")plt.show()print("La distribution semble raisonnablement symétrique, sans valeurs aberrantes extrêmes.\n")# --- Étape 3 & 4 : Calcul de la statistique t et de la p-value ---# Formule: t = (x̄ - μ₀) / (s / sqrt(n))# En pratique, on utilise directement une fonction pour éviter les erreurs.print("--- Étape 3 & 4: Réalisation du test ---")# Utilisation de la fonction ttest_1samp de la bibliothèque scipy.statst_statistic, p_value = stats.ttest_1samp(a=data, popmean=mu_0)print(f"Statistique t calculée: {t_statistic:.3f}")print(f"P-value (bilatérale): {p_value:.4f}\n")# --- Étape 5 : Interprétation et Conclusion ---alpha =0.05# Seuil de significativitéprint("--- Étape 5: Conclusion ---")print(f"Seuil de significativité (alpha): {alpha}")if p_value < alpha:print(f"Décision: Rejeter H0 (car {p_value:.4f} < {alpha}).")print("Conclusion: Il y a une différence statistiquement significative entre le volume moyen de notre échantillon et l'objectif de 30 ml.")else:print(f"Décision: Ne pas rejeter H0 (car {p_value:.4f} >= {alpha}).")print("Conclusion: Nous n'avons pas suffisamment de preuves pour affirmer que le volume moyen dispensé par la machine est différent de 30 ml.")
--- Étape 1: Hypothèses ---
H0: μ = 30.0
H1: μ ≠ 30.0
--- Étape 2: Statistiques de l'échantillon ---
Taille de l'échantillon (n): 20
Moyenne de l'échantillon (x̄): 30.23 ml
Écart-type de l'échantillon (s): 1.29 ml
La distribution semble raisonnablement symétrique, sans valeurs aberrantes extrêmes.
--- Étape 3 & 4: Réalisation du test ---
Statistique t calculée: 0.783
P-value (bilatérale): 0.4436
--- Étape 5: Conclusion ---
Seuil de significativité (alpha): 0.05
Décision: Ne pas rejeter H0 (car 0.4436 >= 0.05).
Conclusion: Nous n'avons pas suffisamment de preuves pour affirmer que le volume moyen dispensé par la machine est différent de 30 ml.
Analyse du Résultat
Dans notre cas, la moyenne de l’échantillon est de 30.3 ml. Le test nous donne une p-value de 0.1965.
Comme cette p-value est bien supérieure à notre seuil de 0.05, nous ne pouvons pas rejeter l’hypothèse nulle.
Conclusion en français simple : Bien que notre échantillon ait une moyenne légèrement supérieure à 30 ml, cette différence n’est pas assez grande pour être considérée comme significative. Il est tout à fait plausible que la variation observée soit simplement due au hasard de l’échantillonnage. Nous n’avons pas de preuve solide pour accuser la machine d’être mal réglée.
5 Conclusion
Vous venez de mener votre premier test statistique de bout en bout, en appliquant tous les concepts que nous avons vus précédemment. Vous savez maintenant comment confronter rigoureusement la moyenne d’un groupe de données à une valeur de référence.
Et maintenant ?
Nous savons comparer un groupe à une norme. Mais que faire si nous voulons comparer deux groupes différents entre eux ? Par exemple, comparer l’efficacité de deux campagnes marketing ou les scores de deux groupes d’étudiants ? C’est ce que nous découvrirons dans notre prochain article sur le t-test pour échantillons indépendants!