Le Secret des Tests Statistiques : Comprendre les Lois d’Échantillonnage
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Le Pont entre un Échantillon et l’Univers
Comment un sondage sur 1000 personnes peut-il prétendre représenter l’avis de millions d’électeurs ? Comment une entreprise peut-elle décider de lancer un nouveau produit en se basant sur les retours d’un petit groupe de testeurs ? Comment un data scientist peut-il être sûr que les résultats d’un test A/B ne sont pas simplement dus au hasard ?
La réponse à toutes ces questions repose sur l’un des concepts les plus puissants et les plus élégants des statistiques : la loi d’échantillonnage.
Dans notre précédent article, nous avons joué les détectives avec la logique des tests d’hypothèses (\(H_0\), p-value). Nous avons vu qu’un test nous aide à décider si nos résultats sont “surprenants” par rapport à une hypothèse de départ. Mais une question cruciale reste en suspens : comment définir ce qui est “surprenant” ? Pour cela, il nous faut comprendre comment notre échantillon se compare, non pas à la population entière (que nous ne connaissons pas), mais à tous les autres échantillons que nous aurions pu obtenir.
Ce post est le pont qui relie le monde limité de notre échantillon à l’univers infini des possibilités. C’est le moteur de l’inférence statistique.
Objectif de ce post
Notre mission est de démystifier la distribution d’échantillonnage et de vous présenter son super-héros, le Théorème Central Limite. À la fin de votre lecture, vous comprendrez pourquoi ce concept fondamental est la clé qui rend les tests statistiques non seulement possibles, mais aussi incroyablement puissants.
2 Population vs. Échantillon : Les Acteurs en Scène
Pour comprendre les lois d’échantillonnage, il faut d’abord être très clair sur les deux mondes entre lesquels nous naviguons : le monde de la population (ce que nous voulons connaître) et le monde de l’échantillon (ce que nous pouvons observer).
2.1 La Population
C’est l’univers complet de tous les individus, objets ou mesures qui nous intéressent. La population peut être concrète et finie, ou théorique et infinie.
Exemples : Tous les électeurs inscrits en France, toutes les ampoules produites par une usine, la température de chaque point d’un lac.
2.2 Le Paramètre (\(\mu, \sigma, p\))
Un paramètre est une caractéristique numérique qui décrit la population. C’est une valeur fixe, unique, mais généralement inconnue. C’est le “trésor” que nous cherchons.
Example 1
La moyenne d’âge réelle de tous les électeurs (\(\mu\)).
L’écart-type réel de la durée de vie de toutes les ampoules (\(\sigma\)).
La proportion réelle d’étudiants satisfaits (\(p\)).
2.3 L’Échantillon
Comme il est souvent impossible d’étudier toute la population, nous prélevons un échantillon : un sous-ensemble représentatif de cette population.
Exemples : Un groupe de 1000 électeurs interrogés, 200 ampoules testées en laboratoire, des relevés de température à 50 endroits du lac.
2.4 La Statistique (\(\bar{x}, s, \hat{p}\))
Une statistique est une caractéristique numérique calculée à partir de notre échantillon. C’est une valeur que nous connaissons, mais qui varie d’un échantillon à l’autre. C’est notre “indice” pour trouver le trésor.
Example 2
La moyenne d’âge de nos 1000 électeurs (\(\bar{x}\))
L’écart-type de la durée de vie de nos 200 ampoules (\(s\)).
La proportion d’étudiants satisfaits dans notre sondage (\(\hat{p}\)).
Le Défi Fondamental de l’Inférence
Notre statistique (\(\bar{x}\)) est variable. Si nous avions choisi un autre échantillon, nous aurions obtenu une autre valeur pour \(\bar{x}\).
Le problème est donc le suivant : Comment pouvons-nous utiliser cette seule valeur, notre statistique d’échantillon, pour dire quelque chose de fiable sur le paramètre de la population, qui lui est fixe mais inconnu ?
Pour répondre à cette question, nous devons comprendre la “personnalité” de notre statistique. Comment se comporterait-elle si nous pouvions répéter l’échantillonnage encore et encore ? C’est ce que nous allons explorer dans la section suivante.
3 L’Expérience de Pensée : La Distribution d’Échantillonnage 🧠
Nous avons établi que notre statistique d’échantillon (par exemple, la moyenne \(\bar{x}\)) varie d’un échantillon à l’autre. Pour comprendre cette variabilité de manière rigoureuse, nous allons faire une petite expérience de pensée. C’est le cœur de l’inférence statistique.
Imaginons que nous ayons un pouvoir magique : celui de pouvoir prélever non pas un seul, mais des milliers d’échantillons aléatoires de notre population, tous de la même taille (disons, \(n=50\)).
3.1 L’Expérience, Étape par Étape :
On pioche un premier échantillon de 50 personnes et on calcule leur moyenne d’âge : on obtient \(\bar{x}_1 = 38.2\) ans.
On pioche un deuxième échantillon de 50 autres personnes. On calcule leur moyenne : \(\bar{x}_2 = 41.5\) ans.
On pioche un troisième échantillon… \(\bar{x}_3 = 39.9\) ans.
… et ainsi de suite, des milliers de fois !
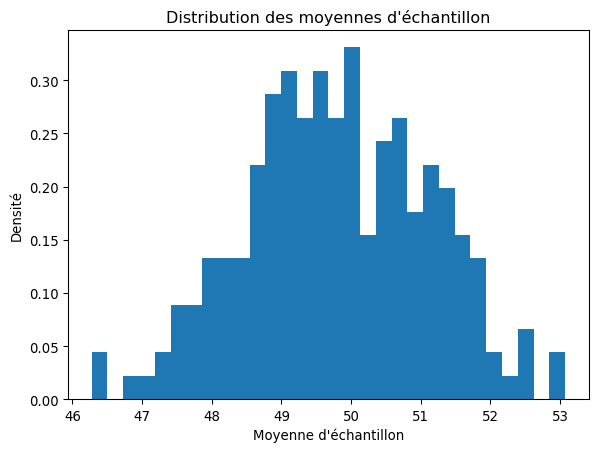
À la fin de cette expérience, nous nous retrouvons avec une toute nouvelle collection de données. Ce ne sont plus des âges d’individus, mais une très longue liste de moyennes d’échantillon :
import numpy as npimport matplotlib.pyplot as plt# Générer 10000 échantillonnp.random.seed(0)data = np.random.normal(loc=50, scale=10, size=10000).reshape(-1, 50)# Calcul des moyennes d'échantillonsample_means = data.mean(axis=1)# Tracer l'histogramme des moyennesplt.hist(sample_means, bins=30, density=True)plt.xlabel('Moyenne d\'échantillon')plt.ylabel('Densité')plt.title('Distribution des moyennes d\'échantillon')plt.show()
3.2 La Révélation : La Distribution d’Échantillonnage
Que se passerait-il si nous tracions l’histogramme de cette nouvelle collection de moyennes ? Nous verrions apparaître une distribution avec sa propre forme, son propre centre et sa propre dispersion.
Définition Fondamentale
La distribution d’échantillonnage d’une statistique (ici, la moyenne) est la distribution de probabilité de toutes les valeurs possibles que cette statistique peut prendre, pour une taille d’échantillon donnée.
En d’autres termes, c’est la “personnalité” de notre statistique. Elle nous dit quelles valeurs de \(\bar{x}\) sont probables, lesquelles sont rares, et quelle est la valeur la plus probable.
Cette distribution d’échantillonnage semble peut-être théorique, mais elle possède des propriétés remarquables et prévisibles, même si la population d’origine nous est inconnue. C’est ce que nous allons découvrir avec le Théorème Central Limite dans la section suivante.