Quand les Variables Collaborent : L’ANOVA à Deux Facteurs et la Magie de l’Interaction
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Le Monde n’est pas si Simple
Dans notre dernier article, nous avons vu comment l’ANOVA nous permet de comparer les moyennes de plusieurs groupes en fonction d’un seul facteur (par exemple, l’effet du département sur le salaire). C’est un outil puissant, mais la réalité est rarement si simple.
Le salaire d’un employé dépend-il seulement de son département ? Probablement pas. Son niveau d’expérience joue certainement un rôle. Mais la vraie question, plus subtile et plus intéressante, est : l’effet du niveau d’expérience sur le salaire est-il le même dans tous les départements ?
Pour répondre à ce type de question, nous devons passer à la vitesse supérieure avec l’ANOVA à deux facteurs (ou Two-Way ANOVA). Cet outil nous permet d’étudier simultanément l’effet de deux variables qualitatives (ou “facteurs”) sur une variable quantitative, et surtout, de déceler si ces facteurs interagissent entre eux.
2 Les Trois Questions d’une ANOVA à Deux Facteurs
Contrairement à l’ANOVA simple qui ne pose qu’une seule question, l’ANOVA à deux facteurs en pose trois, ce qui la rend beaucoup plus riche :
Y a-t-il un effet principal du Facteur A ?
Exemple : Le département a-t-il un effet sur le salaire, tous niveaux d’expérience confondus ?
Y a-t-il un effet principal du Facteur B ?
Exemple : Le niveau d'expérience a-t-il un effet sur le salaire, tous départements confondus ?
Y a-t-il un effet d’interaction entre A et B ?
Exemple : L’effet du niveau d'expérience sur le salaire dépend-il du département ? C’est la question la plus puissante et la plus importante.
3 Comprendre l’Interaction : Le Concept Clé
L’effet d’interaction est le cœur de l’ANOVA à deux facteurs. Il se produit lorsque l’effet d’un facteur sur la variable de résultat change en fonction du niveau de l’autre facteur.
Absence d’interaction : Les effets des deux facteurs sont simplement additifs. Sur un graphique, les lignes représentant les moyennes seront parallèles.
Exemple : “Passer de ‘Junior’ à ‘Senior’ augmente le salaire de 20 000€, et ce, que l’on soit en Vente, en IT ou en RH. L’effet de l’expérience est constant.”
Présence d’une interaction : Les effets ne sont pas additifs. Les lignes sur le graphique ne seront pas parallèles (elles peuvent se croiser, s’écarter ou se rapprocher).
Exemple : “Passer de ‘Junior’ à ‘Senior’ a un impact énorme sur le salaire en Vente, mais un impact beaucoup plus modeste en RH. L’effet de l’expérience n’est pas le même partout.”
La meilleure façon de visualiser une interaction est d’utiliser un graphique d’interaction.
4 Atelier Pratique : Salaire, Département et Expérience
L’entreprise Innovatech veut comprendre comment le département et le niveau_experience (‘Junior’, ‘Confirmé’, ‘Senior’) influencent le salaire_annuel.
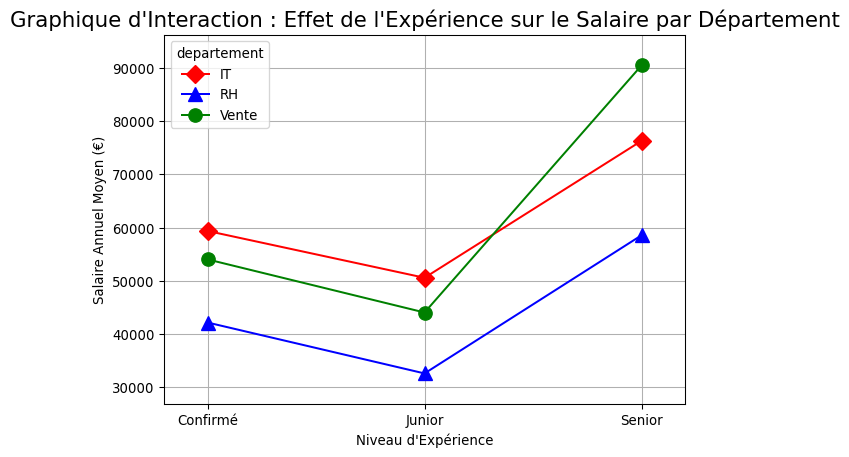
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport statsmodels.api as smfrom statsmodels.formula.api import ols# --- 1. Création de données avec un effet d'interaction ---np.random.seed(42)n =300data = pd.DataFrame({'departement': np.random.choice(['Vente', 'IT', 'RH'], n),'niveau_experience': np.random.choice(['Junior', 'Confirmé', 'Senior'], n),'salaire_annuel': np.random.normal(50000, 5000, n)})# Création des effets principauxexp_effect = {'Junior': -10000, 'Confirmé': 0, 'Senior': 15000}dep_effect = {'Vente': 5000, 'IT': 10000, 'RH': -8000}data['salaire_annuel'] += data['niveau_experience'].map(exp_effect) + data['departement'].map(dep_effect)# Création de l'EFFET D'INTERACTION# L'expérience a un impact beaucoup plus fort en Venteinteraction_mask = (data['departement'] =='Vente') & (data['niveau_experience'] =='Senior')data.loc[interaction_mask, 'salaire_annuel'] +=20000# --- 2. Visualisation : Le Graphique d'Interaction ---print("--- Étape 2: Visualisation de l'Interaction ---")plt.figure(figsize=(12, 8))# `interaction.plot` est un outil de statsmodels parfait pour celafig = sm.graphics.interaction_plot( x=data['niveau_experience'], trace=data['departement'], response=data['salaire_annuel'], colors=['red', 'blue', 'green'], markers=['D', '^', 'o'], ms=10)plt.title("Graphique d'Interaction : Effet de l'Expérience sur le Salaire par Département", fontsize=16)plt.ylabel("Salaire Annuel Moyen (€)")plt.xlabel("Niveau d'Expérience")plt.grid(True)plt.show()print("Observation: Les lignes ne sont pas parallèles ! La ligne 'Vente' (en rouge) monte beaucoup plus vite que les autres. C'est le signe visuel d'une interaction.\n")# --- 3. Réalisation de l'ANOVA à deux facteurs ---print("--- Étape 3: Test ANOVA à deux facteurs ---")# La formule est très expressive : on teste les effets de chaque facteur ET leur interaction (A:B)formula ='salaire_annuel ~ C(departement) + C(niveau_experience) + C(departement):C(niveau_experience)'model = ols(formula, data=data).fit()anova_table = sm.stats.anova_lm(model, typ=2)print(anova_table)# --- 4. Interprétation de la Table ANOVA ---print("\n--- Étape 4: Interprétation ---")p_value_interaction = anova_table.loc['C(departement):C(niveau_experience)', 'PR(>F)']alpha =0.05print(f"P-value de l'effet d'interaction: {p_value_interaction:.4e}")# Règle d'or : TOUJOURS interpréter l'interaction en premier !if p_value_interaction < alpha:print("\nConclusion Principale : L'effet d'interaction est statistiquement significatif.")print("Cela signifie que l'effet du niveau d'expérience sur le salaire n'est PAS le même pour tous les départements.")print("Il n'est donc pas pertinent d'interpréter les effets principaux de manière isolée.")else:print("\nL'effet d'interaction n'est pas significatif. Nous pouvons maintenant examiner les effets principaux.")# Code pour interpréter les effets principaux si l'interaction était non significative p_value_dep = anova_table.loc['C(departement)', 'PR(>F)'] p_value_exp = anova_table.loc['C(niveau_experience)', 'PR(>F)']if p_value_dep < alpha:print("- L'effet principal du département est significatif.")if p_value_exp < alpha:print("- L'effet principal du niveau d'expérience est significatif.")
--- Étape 2: Visualisation de l'Interaction ---
<Figure size 1152x768 with 0 Axes>
Observation: Les lignes ne sont pas parallèles ! La ligne 'Vente' (en rouge) monte beaucoup plus vite que les autres. C'est le signe visuel d'une interaction.
--- Étape 3: Test ANOVA à deux facteurs ---
sum_sq df F \
C(departement) 2.131710e+10 2.0 408.037944
C(niveau_experience) 5.621278e+10 2.0 1075.988448
C(departement):C(niveau_experience) 5.776487e+09 4.0 55.284873
Residual 7.601346e+09 291.0 NaN
PR(>F)
C(departement) 3.703560e-85
C(niveau_experience) 3.582309e-135
C(departement):C(niveau_experience) 1.217409e-34
Residual NaN
--- Étape 4: Interprétation ---
P-value de l'effet d'interaction: 1.2174e-34
Conclusion Principale : L'effet d'interaction est statistiquement significatif.
Cela signifie que l'effet du niveau d'expérience sur le salaire n'est PAS le même pour tous les départements.
Il n'est donc pas pertinent d'interpréter les effets principaux de manière isolée.
Analyse du Résultat
Le Graphique d’Interaction : Notre intuition visuelle était correcte. Les lignes ne sont pas parallèles. La pente de la ligne “Vente” est beaucoup plus forte, indiquant que l’expérience “paie” beaucoup plus dans ce département.
La Table ANOVA : La règle d’or est de toujours regarder la ligne de l’interaction en premier (C(departement):C(niveau_experience)). La p-value associée est extrêmement faible (bien en dessous de 0.05).
Conclusion : Nous avons une preuve statistique très solide de la présence d’un effet d’interaction. L’effet du niveau d’expérience sur le salaire dépend du département dans lequel l’employé travaille. À cause de cette interaction, il serait trompeur de conclure simplement “le département a un effet” ou “l’expérience a un effet”. La réalité est plus nuancée : les deux facteurs travaillent ensemble.
5 Conclusion
L’ANOVA à deux facteurs est un saut qualitatif dans votre capacité d’analyse. Elle vous permet de modéliser des relations plus complexes et plus proches de la réalité. Retenir le concept d’interaction est essentiel : c’est la clé pour comprendre que dans le monde des données, le tout est souvent différent de la somme des parties.