Au-delà de Deux Groupes : Introduction à l’Analyse de la Variance (ANOVA)
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 La Limite des t-tests
Vous savez maintenant comparer un groupe à une norme, et deux groupes entre eux. Mais que se passe-t-il si vous voulez comparer les scores de satisfaction moyens dans trois départements ? Ou l’efficacité de quatre campagnes marketing différentes ?
La première idée qui vient à l’esprit serait de faire des t-tests entre chaque paire possible (Groupe A vs B, A vs C, B vs C…). C’est une très mauvaise idée !
Pourquoi ? Car à chaque test, il y a un risque de se tromper (le fameux risque alpha de 5%). En multipliant les tests, ce risque s’accumule de manière explosive. Avec 4 groupes, vous feriez 6 tests, et votre risque de trouver une différence significative par pur hasard grimperait à près de 30% !
Pour résoudre ce problème, les statisticiens ont développé un outil plus élégant et plus puissant : l’Analyse de la Variance, plus connue sous son acronyme ANOVA.
2 La Logique de l’ANOVA : Analyser la Variance pour Comparer les Moyennes
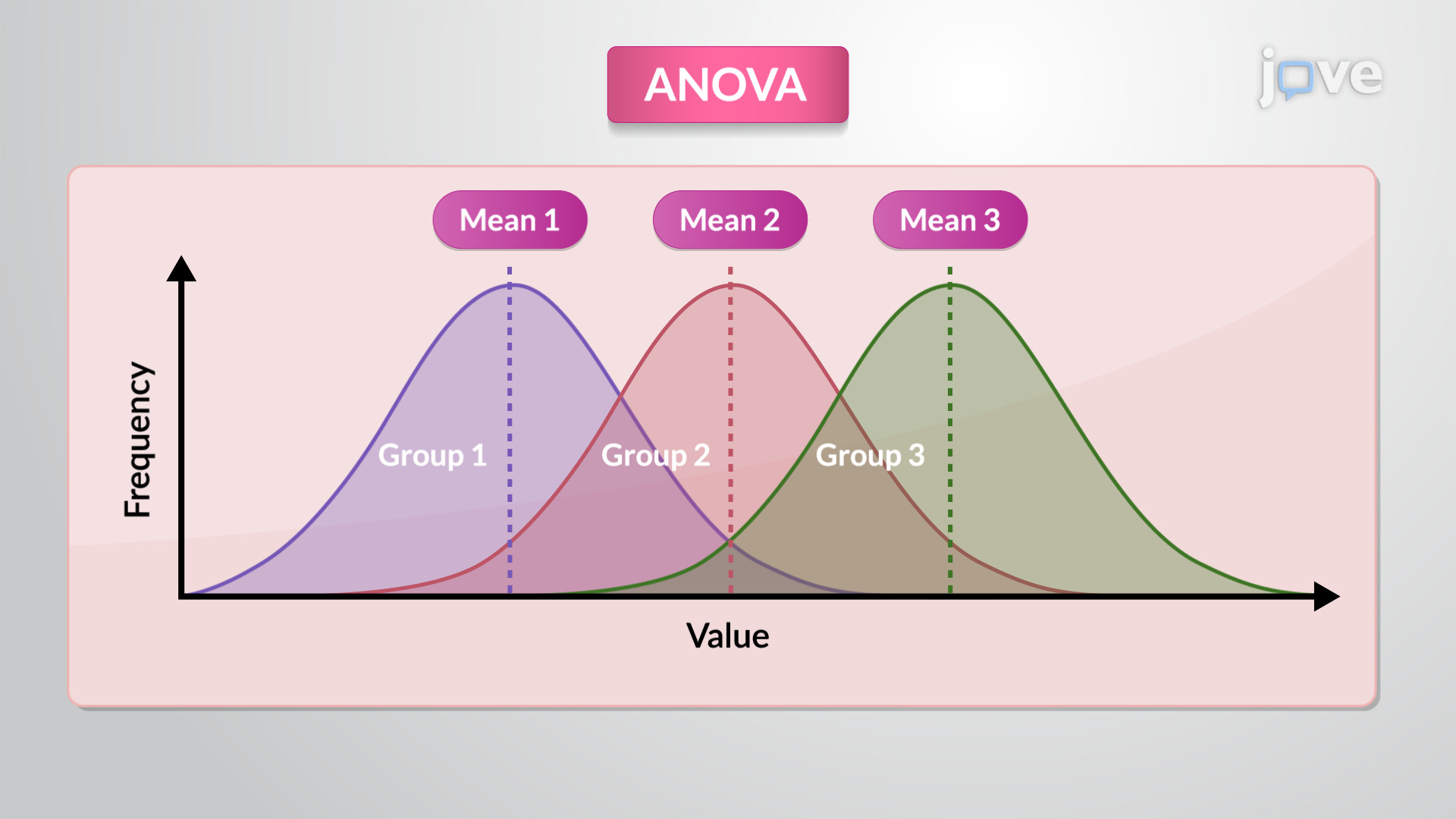
Le nom “Analyse de la Variance” peut sembler étrange, car notre but est de comparer des moyennes. Mais c’est là toute l’astuce de l’ANOVA. L’idée centrale est de comparer deux types de variance :
La Variance Inter-Groupes (Le “Signal”) : Elle mesure à quel point les moyennes de chaque groupe s’écartent de la moyenne générale de toutes les données. Si les moyennes des groupes sont très différentes les unes des autres, cette variance sera grande. C’est le signal que nous cherchons à détecter.
La Variance Intra-Groupes (Le “Bruit”) : Elle mesure la dispersion naturelle des données à l’intérieur de chaque groupe. C’est le “bruit” de fond, la variabilité aléatoire inhérente à nos données.
L’ANOVA pose alors une question très intuitive : “Est-ce que le signal (la différence entre les groupes) est suffisamment fort pour se distinguer du bruit de fond (la variation naturelle à l’intérieur des groupes) ?”
3 La Statistique F et les Hypothèses
Pour quantifier ce rapport “Signal / Bruit”, l’ANOVA utilise la statistique F.
\[F = \frac{\text{Variance Entre les Groupes}}{\text{Variance Intra-Groupe}}\]
Si F est proche de 1, le signal est aussi fort que le bruit. Les différences entre les groupes sont probablement dues au hasard.
Si F est grand, le signal domine le bruit. Il est probable qu’il y ait une réelle différence entre les moyennes des groupes.
Les hypothèses de l’ANOVA sont donc :
\(H_0\) (Hypothèse Nulle) : Toutes les moyennes des groupes sont égales. \[ H_0: \mu_1 = \mu_2 = \mu_3 = \dots = \mu_k \]
\(H_1\) (Hypothèse Alternative) : Au deux groupes ont des moyennes différentes.
Important
L’ANOVA est un test “omnibus”. Si la p-value est significative, elle nous dit qu’il y a une différence quelque part, mais elle ne nous dit pas quels groupes sont différents les uns des autres. Nous y reviendrons.
4 Atelier Pratique : Les Salaires dans les Différents Départements
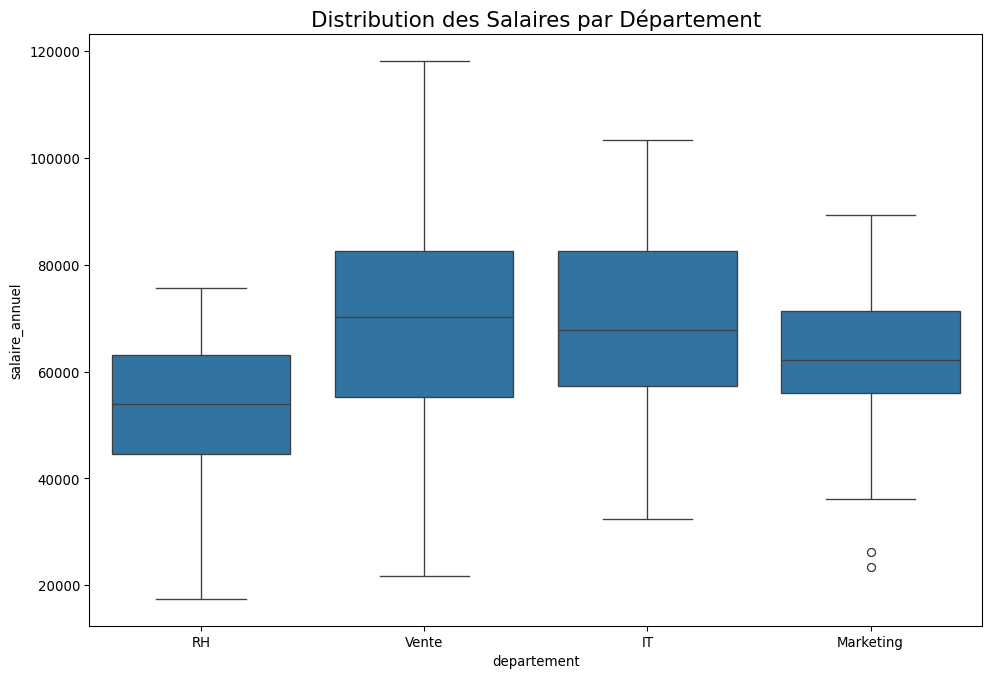
Comparons le salaire annuel moyen entre les quatre départements de l’entreprise Innovatech : ‘IT’, ‘Vente’, ‘RH’ et ‘Marketing’.
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltfrom scipy import statsimport statsmodels.api as smfrom statsmodels.formula.api import olsfrom statsmodels.stats.multicomp import pairwise_tukeyhsd# --- 1. Création des données ---np.random.seed(123)n =400data = pd.DataFrame({'departement': np.random.choice(['IT', 'Vente', 'RH', 'Marketing'], n, p=[0.25, 0.35, 0.15, 0.25]),'salaire_annuel': np.random.normal(60000, 15000, n)})# Introduire des différencesdata.loc[data['departement'] =='Vente', 'salaire_annuel'] *=1.2data.loc[data['departement'] =='IT', 'salaire_annuel'] *=1.15data.loc[data['departement'] =='RH', 'salaire_annuel'] *=0.85# --- 2. Visualisation ---plt.figure(figsize=(12, 8))sns.boxplot(x='departement', y='salaire_annuel', data=data)plt.title('Distribution des Salaires par Département', fontsize=16)plt.show()# --- 3. Vérification des hypothèses de l'ANOVA ---# a) Indépendance (supposée par le design de l'étude)# b) Normalité (l'ANOVA est robuste si les groupes sont assez grands)# c) Homogénéité des variances (à vérifier avec Levene)print("--- Étape 3: Test de Levene pour l'égalité des variances ---")# On prépare les données pour le testgroups = [data['salaire_annuel'][data['departement'] == d] for d in data['departement'].unique()]levene_stat, p_value_levene = stats.levene(*groups)print(f"P-value du test de Levene: {p_value_levene:.4f}")if p_value_levene >0.05:print("L'hypothèse d'égalité des variances est validée. On peut procéder à l'ANOVA.\n")else:print("Les variances sont différentes. Une ANOVA de Welch serait plus appropriée.\n")# --- 4. Réalisation du test ANOVA ---# On utilise la librairie statsmodels qui est très puissante pour celaprint("--- Étape 4: Test ANOVA ---")# On définit le modèle : on veut expliquer le salaire par le départementmodel = ols('salaire_annuel ~ C(departement)', data=data).fit()# On affiche la table ANOVAanova_table = sm.stats.anova_lm(model, typ=2)print(anova_table)# --- 5. Interprétation ---p_value_anova = anova_table['PR(>F)'][0]print("\n--- Étape 5: Interprétation de l'ANOVA ---")if p_value_anova <0.05:print(f"La p-value de l'ANOVA ({p_value_anova:.4e}) est significative.")print("Conclusion: Il y a une différence statistiquement significative de salaire moyen entre au moins deux départements.")else:print("Conclusion: Pas de différence significative détectée entre les départements.")
--- Étape 3: Test de Levene pour l'égalité des variances ---
P-value du test de Levene: 0.0002
Les variances sont différentes. Une ANOVA de Welch serait plus appropriée.
--- Étape 4: Test ANOVA ---
sum_sq df F PR(>F)
C(departement) 1.453081e+10 3.0 18.72258 2.241470e-11
Residual 1.024467e+11 396.0 NaN NaN
--- Étape 5: Interprétation de l'ANOVA ---
La p-value de l'ANOVA (2.2415e-11) est significative.
Conclusion: Il y a une différence statistiquement significative de salaire moyen entre au moins deux départements.
/tmp/ipykernel_111659/3995265410.py:53: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
5 Après l’ANOVA : Qui est différent de qui ? (Tests Post-Hoc)
Notre p-value est extrêmement faible, nous rejetons donc \(H\_0\). Super ! Mais cela ne nous dit pas si les salaires en Vente sont différents de ceux en IT, ou si les RH sont moins bien payés que tout le monde.
Pour savoir quelles paires de groupes sont significativement différentes, nous devons effectuer des tests post-hoc. Le plus courant est le test de Tukey HSD (Honestly Significant Difference), qui compare toutes les paires possibles tout en contrôlant le risque d’erreur global.
# --- Étape 6 : Test Post-Hoc de Tukey HSD ---print("\n--- Étape 6: Test Post-Hoc de Tukey pour les comparaisons par paires ---")tukey_results = pairwise_tukeyhsd(endog=data['salaire_annuel'], groups=data['departement'], alpha=0.05)print(tukey_results)
--- Étape 6: Test Post-Hoc de Tukey pour les comparaisons par paires ---
Multiple Comparison of Means - Tukey HSD, FWER=0.05
====================================================================
group1 group2 meandiff p-adj lower upper reject
--------------------------------------------------------------------
IT Marketing -6551.8459 0.0275 -12590.8828 -512.809 True
IT RH -16538.3565 0.0 -23353.9691 -9722.7439 True
IT Vente 426.8342 0.997 -4972.8463 5826.5147 False
Marketing RH -9986.5106 0.0012 -16872.5392 -3100.482 True
Marketing Vente 6978.6801 0.0062 1490.3867 12466.9734 True
RH Vente 16965.1907 0.0 10632.421 23297.9604 True
--------------------------------------------------------------------
5.1 Interprétation du Tableau de Tukey
Le tableau ci-dessus est très riche. La dernière colonne reject nous dit tout :
True : La différence de moyenne entre les deux groupes de la ligne est statistiquement significative.
False : La différence n’est pas significative.
On peut voir par exemple que la différence entre ‘RH’ et ‘Vente’ est significative (reject=True), mais pas celle entre ‘IT’ et ‘Vente’ (reject=False).
6 Conclusion de la Série
Vous êtes arrivé au bout de notre parcours sur les tests statistiques. En partant des concepts de base, vous avez progressé jusqu’à des outils puissants comme l’ANOVA et les tests post-hoc.
Vous disposez maintenant d’une boîte à outils solide pour comparer des moyennes dans la plupart des situations que vous rencontrerez. Plus important encore, vous comprenez la logique et les précautions qui sous-tendent ces tests, ce qui fait de vous un analyste de données plus complet et plus rigoureux.
Le monde des statistiques est vaste, mais les fondations que vous avez acquises ici vous serviront de tremplin pour explorer des sujets plus avancés comme la régression, les modèles linéaires généralisés et bien plus encore. Bonne analyse!