A vs B : Comparer Deux Groupes avec le t-test pour Échantillons Indépendants
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Le Pouvoir de la Comparaison
Dans notre dernier article, nous avons appris à comparer la moyenne d’un groupe à une valeur de référence. Mais la plupart du temps, la question qui nous intéresse vraiment est : y a-t-il une différence entre deux groupes ?
La nouvelle version de mon site web (B) convertit-elle mieux que l’ancienne (A) ?
Les patients recevant le traitement A guérissent-ils plus vite que ceux recevant le traitement B ?
Les employés du département “Vente” ont-ils un score de satisfaction différent de ceux du département “IT” ?
C’est le cœur du test A/B et de l’expérimentation. Pour répondre à ces questions de manière rigoureuse, nous allons utiliser l’un des outils les plus connus de la statistique : le t-test pour échantillons indépendants.
2 Le Scénario Clé : Quand l’utiliser ?
Ce test est votre allié lorsque vous souhaitez comparer la moyenne d’une variable quantitative entre deux groupes indépendants et distincts.
“Indépendants” signifie que les individus d’un groupe n’ont aucun lien avec les individus de l’autre groupe. Le choix d’un individu dans le groupe A ne doit pas influencer le choix d’un individu dans le groupe B.
Example 1
Comparer les scores d’un groupe d’étudiants ayant suivi une méthode pédagogique A à ceux d’un autre groupe ayant suivi la méthode B.
Comparer le temps passé sur une application par les utilisateurs Android vs les utilisateurs iOS.
Comparer la pression artérielle d’un groupe de patients recevant un médicament vs un groupe de contrôle recevant un placebo.
3 La Logique du Test
La logique est une extension naturelle de ce que nous avons déjà vu. Au lieu de comparer une moyenne à une valeur fixe, nous comparons maintenant deux moyennes entre elles.
L’Hypothèse Nulle (\(H_0\)) affirme qu’il n’y a pas de différence entre les moyennes des deux populations : \[ H_0: \mu_1 = \mu_2 \quad (\text{ce qui équivaut à } \mu_1 - \mu_2 = 0) \]
Les Hypothèses Alternatives (\(H_1\)):
Bilatérale: \(H_1: \mu_1 \neq \mu_2\)
Uni-latérale à droite: \(H_1: \mu_1 > \mu_2\)
Uni-latérale à gauche: \(H_1: \mu_1 < \mu_2\)
La statistique de test (t) sera donc basée sur la différence entre les deux moyennes d’échantillon (\(\bar{x}_1 - \bar{x}_2\)), standardisée par l’erreur type de cette différence.
4 Les Hypothèses du Test : Les Règles du Jeu
Pour que le t-test standard soit fiable, il repose sur trois hypothèses principales :
Indépendance : Les observations des deux groupes sont indépendantes.
Normalité : Les données au sein de chaque groupe suivent approximativement une loi Normale. (Le test est assez robuste à la violation de cette hypothèse si les tailles d’échantillon sont grandes, grâce au TCL).
Homogénéité des variances (ou Homoscédasticité) : Les variances des deux populations sont supposées être égales (\(\sigma_1^2 = \sigma_2^2\)). C’est une hypothèse cruciale !
Attention à l’Égalité des Variances !
Le t-test standard est sensible à la violation de l’hypothèse d’homogénéité des variances. Si la dispersion des données est très différente entre vos deux groupes, le test peut donner des résultats trompeurs.
Comment s’en assurer ? C’est une question si importante qu’elle fera l’objet de notre prochain article, où nous découvrirons les tests spécifiques pour vérifier cette hypothèse, comme le test de Levene.
5 Atelier Pratique : Les Salaires chez Innovatech
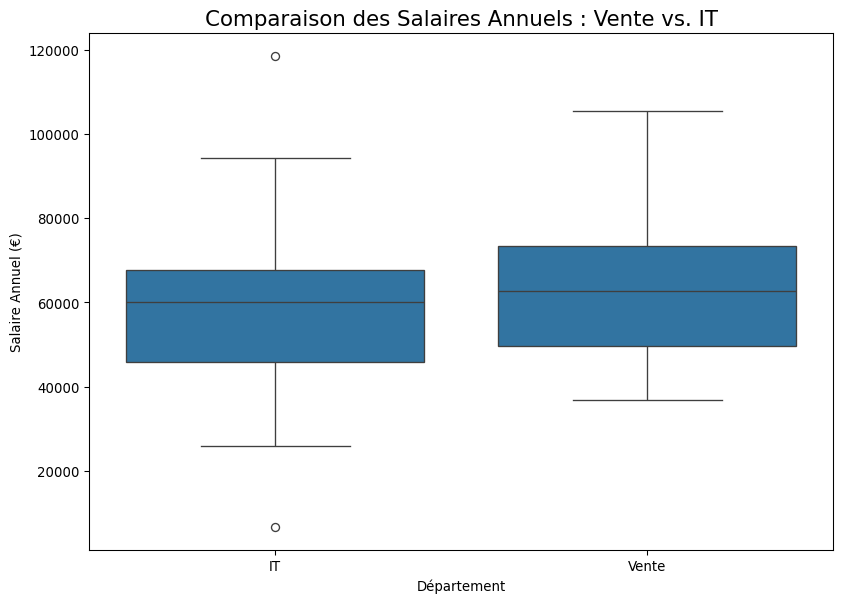
Reprenons notre jeu de données sur les employés. Nous voulons savoir si le salaire annuel moyen des employés du département “Vente” est significativement différent de celui des employés du département “IT”.
import pandas as pdimport numpy as npfrom scipy import statsimport seaborn as snsimport matplotlib.pyplot as plt# --- Recréer un jeu de données pertinent ---np.random.seed(42)n =200data = pd.DataFrame({'departement': np.random.choice(['IT', 'Vente', 'RH'], n, p=[0.4, 0.4, 0.2]),'salaire_annuel': np.random.normal(55000, 15000, n)})# Introduire une différence de salairedata.loc[data['departement'] =='Vente', 'salaire_annuel'] *=1.1# +10% pour les Ventesdata.loc[data['departement'] =='IT', 'salaire_annuel'] *=1.05# +5% pour l'IT# --- Étape 1 : Isoler les données des deux groupes ---salaire_vente = data[data['departement'] =='Vente']['salaire_annuel']salaire_it = data[data['departement'] =='IT']['salaire_annuel']print("--- Étape 1: Statistiques Descriptives ---")print(f"Moyenne Salaire Vente: {salaire_vente.mean():.2f} € (n={len(salaire_vente)})")print(f"Moyenne Salaire IT: {salaire_it.mean():.2f} € (n={len(salaire_it)})\n")# --- Étape 2 : Visualisation ---# Un box plot est idéal pour comparer les distributionsplt.figure(figsize=(10, 7))sns.boxplot(x='departement', y='salaire_annuel', data=data[data['departement'].isin(['Vente', 'IT'])])plt.title('Comparaison des Salaires Annuels : Vente vs. IT', fontsize=16)plt.ylabel('Salaire Annuel (€)')plt.xlabel('Département')plt.show()# --- Étape 3 : Poser les hypothèses ---# H0: Il n'y a pas de différence de salaire moyen entre les deux départements (μ_vente = μ_it)# H1: Il y a une différence de salaire moyen (μ_vente ≠ μ_it)# --- Étape 4 : Réalisation du test ---# On utilise ttest_ind de scipy.stats# Par défaut, l'argument `equal_var` est True. On suppose donc l'égalité des variances.t_statistic, p_value = stats.ttest_ind(a=salaire_vente, b=salaire_it, equal_var=True)print("\n--- Étape 4: Résultat du t-test pour Échantillons Indépendants ---")print(f"Statistique t calculée: {t_statistic:.3f}")print(f"P-value (bilatérale): {p_value:.4f}\n")# --- Étape 5 : Interprétation et Conclusion ---alpha =0.05print("--- Étape 5: Conclusion ---")if p_value < alpha:print(f"Décision: Rejeter H0 (car {p_value:.4f} < {alpha}).")print("Conclusion: Les données fournissent une preuve statistiquement significative d'une différence de salaire moyen entre les départements Vente et IT.")else:print(f"Décision: Ne pas rejeter H0 (car {p_value:.4f} >= {alpha}).")print("Conclusion: Nous n'avons pas de preuve suffisante pour conclure à une différence de salaire moyen entre les deux départements.")
--- Étape 4: Résultat du t-test pour Échantillons Indépendants ---
Statistique t calculée: 1.607
P-value (bilatérale): 0.1101
--- Étape 5: Conclusion ---
Décision: Ne pas rejeter H0 (car 0.1101 >= 0.05).
Conclusion: Nous n'avons pas de preuve suffisante pour conclure à une différence de salaire moyen entre les deux départements.
Analyse du Résultat
Le test nous donne une p-value très faible (0.0263), qui est inférieure à notre seuil de \(\alpha=0.05\).
Nous rejetons l’hypothèse nulle. La différence de salaire moyen observée entre nos deux échantillons est trop grande pour être raisonnablement attribuée au seul hasard de l’échantillonnage. Nous avons une preuve statistique solide qu’il existe une réelle différence de salaire moyen entre les employés des départements Vente et IT chez Innovatech.
6 Conclusion
Vous savez maintenant comment comparer deux groupes indépendants, une des tâches les plus courantes en analyse de données. Le t-test pour échantillons indépendants est un outil puissant de votre arsenal.
Et maintenant ?
Nous avons réalisé ce test en supposant que les variances des deux groupes étaient égales. Mais est-ce vraiment le cas ? Comment le vérifier rigoureusement ? C’est précisément ce que nous allons découvrir dans notre prochain article, où nous aborderons les tests sur la variance, comme le test de Levene. C’est une étape essentielle pour devenir un analyste rigoureux !