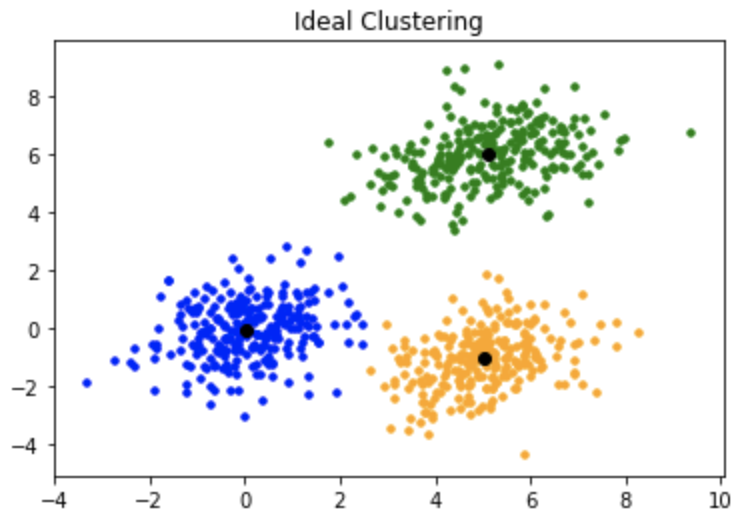
Dans notre introduction au clustering, nous avons vu que l’objectif est de regrouper des données similaires. Parmi les nombreuses façons de le faire, l’approche la plus intuitive et la plus utilisée est le clustering par partitionnement. L’idée est de diviser les données en un nombre prédéfini, \(K\), de groupes non-chevauchants.
L’algorithme roi de cette famille est, sans conteste, le K-Means. Sa popularité vient de sa simplicité conceptuelle, de sa rapidité d’exécution et de son efficacité sur une grande variété de problèmes.
Ce post va vous guider à travers la mécanique interne du K-Means, vous montrer comment aborder sa question la plus difficile (“Comment choisir \(K\) ?”), et illustrer sa mise en œuvre en Python.
2 L’Intuition et l’Algorithme : Un Processus Itératif
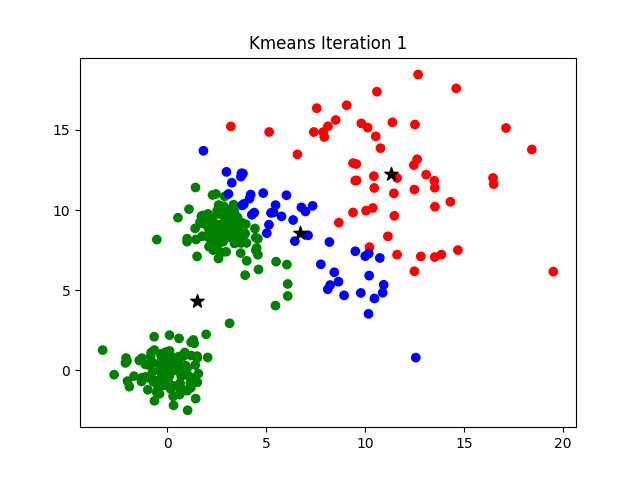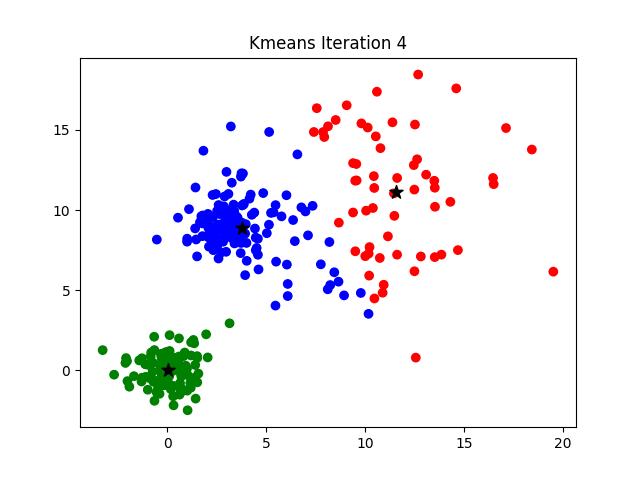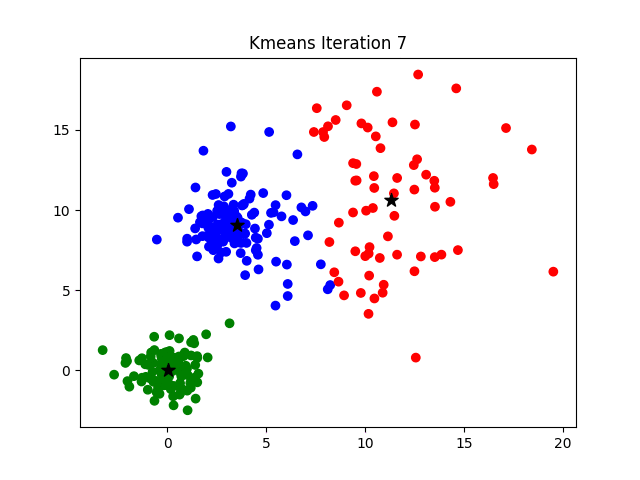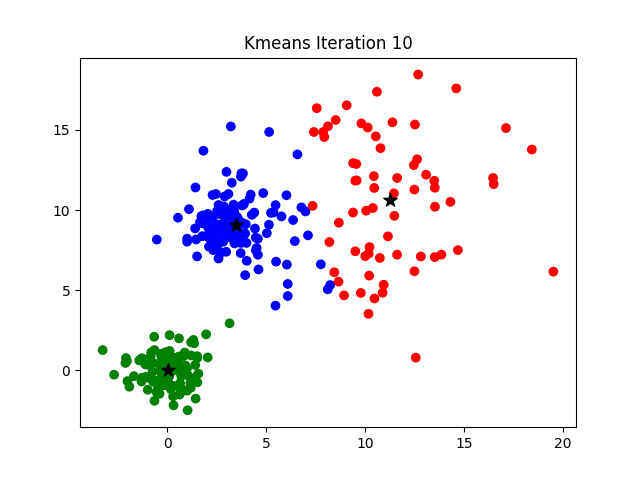
K-Means cherche à trouver \(K\) “centres” (ou centroïdes) et à assigner chaque point de données au centre le plus proche. Le processus est itératif et se déroule en deux étapes qui se répètent jusqu’à ce que plus rien ne bouge.
L’Algorithme :
Initialisation : Choisir aléatoirement \(K\) points de données qui serviront de centroïdes initiaux.
Répéter jusqu’à convergence :
Étape d’Assignation (E-Step) : Pour chaque point de données, calculer sa distance à chaque centroïde et l’assigner au cluster du centroïde le plus proche.
Étape de Mise à Jour (M-Step) : Recalculer la position de chaque centroïde en prenant la moyenne de tous les points qui lui ont été assignés.
Le processus s’arrête lorsque, d’une itération à l’autre, les assignations des points aux clusters ne changent plus.
3\(K\)-Means : Un Problème d’Optimisation
Au-delà de son processus itératif intuitif, l’algorithme K-Means peut être vu de manière plus formelle comme un problème d’optimisation. L’objectif est de trouver la partition des données en \(K\) clusters qui est la “meilleure” possible. Mais comment définir “meilleure” ?
En clustering, une bonne partition est une partition où les clusters sont très compacts. K-Means formalise cette idée en cherchant à minimiser une métrique appelée inertie intra-cluster, ou somme des carrés intra-cluster (WCSS - Within-Cluster Sum of Squares).
3.1 L’Objectif : Minimiser l’Inertie
Notons : - \(C_k\) l’ensemble des points de données appartenant au cluster \(k\). - \(c_k\) le centroïde (point moyen) du cluster \(k\).
L’inertie \(W(K)\) pour une partition en \(K\) clusters est définie comme : \[
W(K) = \sum_{k=1}^K \sum_{x_i \in C_k} \|x_i - c_k\|^2
\]
En français simple, on cherche à minimiser la somme des distances au carré entre chaque point et le centre de son propre cluster. C’est exactement la métrique que nous avons appelée inertie dans la méthode du coude.
Le problème d’optimisation du K-Means est donc : \[
\min_{C_1, \dots, C_K} W(K)
\]
Les deux étapes de l’algorithme (Assignation et Mise à jour) sont une stratégie intelligente pour résoudre ce problème de manière itérative : 1. Étape d’Assignation : Pour un ensemble de centroïdes \(c_k\) donné, assigner chaque point \(x_i\) au centroïde le plus proche est la meilleure façon de minimiser \(W(K)\). 2. Étape de Mise à Jour : Pour une partition en clusters \(C_k\) donnée, recalculer chaque centroïde \(c_k\) comme la moyenne des points de son cluster est la meilleure façon de minimiser \(W(K)\).
L’algorithme converge donc vers un minimum (local) de l’inertie.
3.2 La Perspective de l’Analyse de la Variance
Pour aller plus loin, on peut relier ce problème à l’analyse de la variance (ANOVA). La dispersion totale des données, mesurée par la Somme Totale des Carrés (TSS), peut être décomposée.
Somme Totale des Carrés (TSS) : Dispersion totale des données autour de la moyenne globale \(c\). \[ TSS = \sum_{i=1}^n \|x_i - c\|^2 \]
Somme des Carrés Intra-cluster (WCSS) : C’est notre inertie \(W(K)\), la dispersion à l’intérieur des clusters. \[ W(K) = \sum_{k=1}^K \sum_{x_i \in C_k} \|x_i - c_k\|^2 \]
Somme des Carrés Inter-clusters (BCSS) : C’est la dispersion des centroïdes des clusters autour de la moyenne globale \(c\). \[ B(K) = \sum_{k=1}^K n_k \|c_k - c\|^2 \]
Le théorème de décomposition de la variance (Théorème de Huygens) nous dit que : \[
TSS = W(K) + B(K)
\]
Implication Fondamentale
Puisque la dispersion totale (TSS) est une constante pour un jeu de données donné, minimiser la dispersion intra-cluster (\(W(K)\)) est mathématiquement équivalent à maximiser la dispersion inter-cluster (\(B(K)\)).
En cherchant à rendre les clusters les plus compacts possible, l’algorithme K-Means les rend simultanément les plus séparés possible.
4 Le Défi Majeur : Comment Choisir le Bon Nombre de Clusters (\(K\)) ?
La plus grande difficulté du K-Means est que nous devons lui spécifier le nombre de clusters \(K\) à l’avance. Mais comment le connaître si nous explorons justement les données ? Il n’y a pas de réponse unique, mais deux méthodes sont très populaires pour nous guider.
4.1 La Méthode du Coude (Elbow Method)
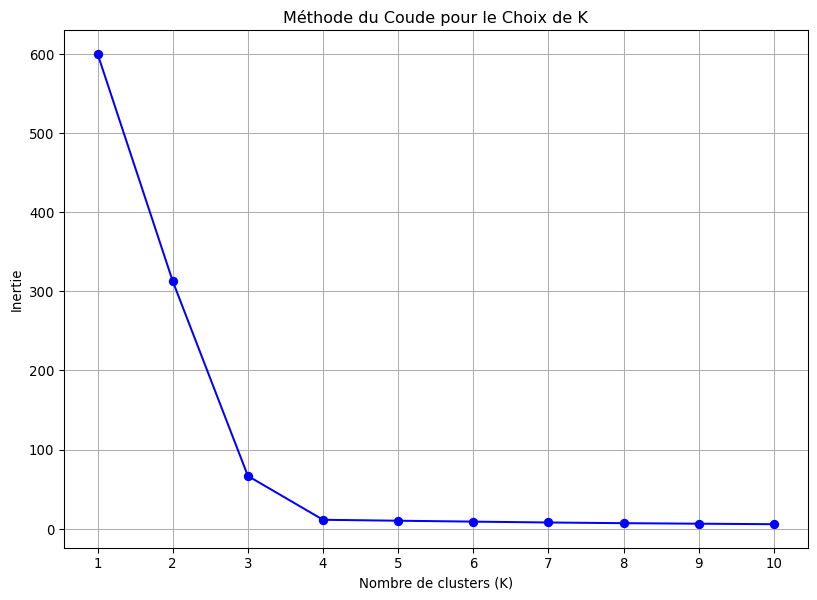
L’idée est de faire tourner l’algorithme K-Means pour un éventail de valeurs de \(K\) (ex: de 1 à 10) et de calculer pour chacune une métrique appelée inertie.
L’Inertie (ou WCSS - Within-Cluster Sum of Squares) : C’est la somme des distances au carré entre chaque point et le centre de son propre cluster. Une faible inertie signifie que les clusters sont denses et compacts.
On trace ensuite la courbe de l’inertie en fonction de \(K\). La courbe aura typiquement une forme de bras replié. Le “coude” de ce bras, c’est-à-dire le point où la courbe commence à s’aplatir, est généralement considéré comme une bonne indication du nombre optimal de clusters. C’est le point où ajouter un nouveau cluster n’apporte plus une grande amélioration.
4.2 Le Score de Silhouette
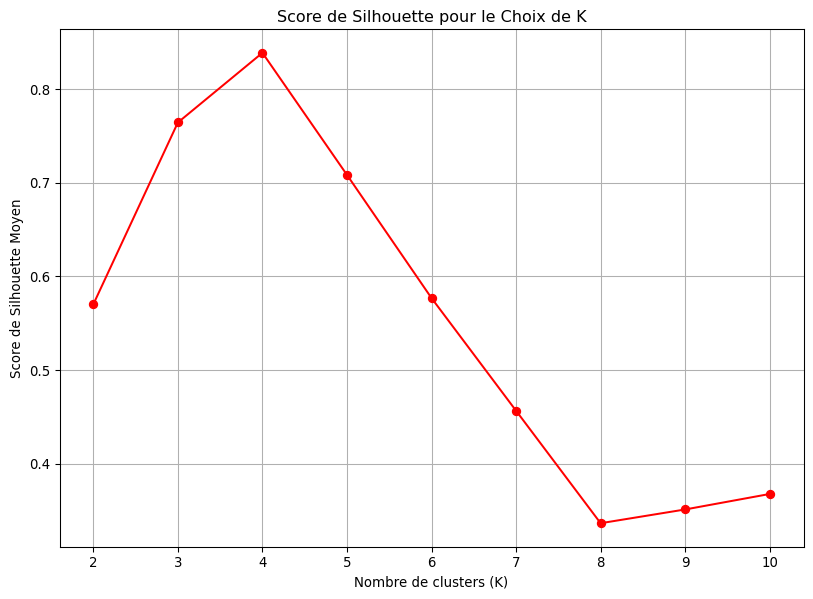
La méthode du coude n’est pas toujours claire. Une métrique plus robuste est le score de silhouette. Pour chaque point, ce score mesure à quel point il est “bien” dans son cluster par rapport aux autres clusters.
Il calcule la distance moyenne aux points de son propre cluster (a) et la distance moyenne aux points du cluster le plus proche (b).
Le score de silhouette pour ce point est : \(s = \frac{b - a}{\max(a, b)}\).
Le score varie de -1 à 1 :
Proche de +1 : Le point est bien assigné à son cluster.
Proche de 0 : Le point est à la frontière entre deux clusters.
Proche de -1 : Le point est probablement mal assigné.
On calcule le score de silhouette moyen pour toutes les observations. La valeur de \(K\) qui maximise ce score moyen est souvent un excellent choix.
4.3 Le Critère de Calinski-Harabasz (CH)
Aussi connu sous le nom de “Variance Ratio Criterion”, le critère de Calinski-Harabasz est une autre excellente métrique pour évaluer la qualité d’une partition. Son idée est très similaire à celle de l’ANOVA : il mesure le ratio de la dispersion entre les clusters sur la dispersion à l’intérieur des clusters.
Un score CH élevé est meilleur. Il indique que les clusters sont denses (faible dispersion intra-cluster, \(W(K)\)) et bien séparés les uns des autres (grande dispersion inter-cluster, \(B(K)\)).
Comme pour le score de silhouette, on calcule le score CH pour différentes valeurs de \(K\) et on choisit le \(K\) qui maximise ce score.
5 Limites du K-Means
Sensibilité à l’initialisation : Le résultat peut dépendre du choix initial des centroïdes. Heureusement, Scikit-learn utilise par défaut une initialisation intelligente appelée k-means++ qui résout en grande partie ce problème.
Hypothèse sur la forme des clusters : K-Means suppose implicitement que les clusters sont de forme sphérique, de taille similaire et de même densité. Il échouera sur des données avec des formes complexes (lunes, cercles concentriques…).
6 Atelier Pratique : Trouver des Groupes de Données Synthétiques
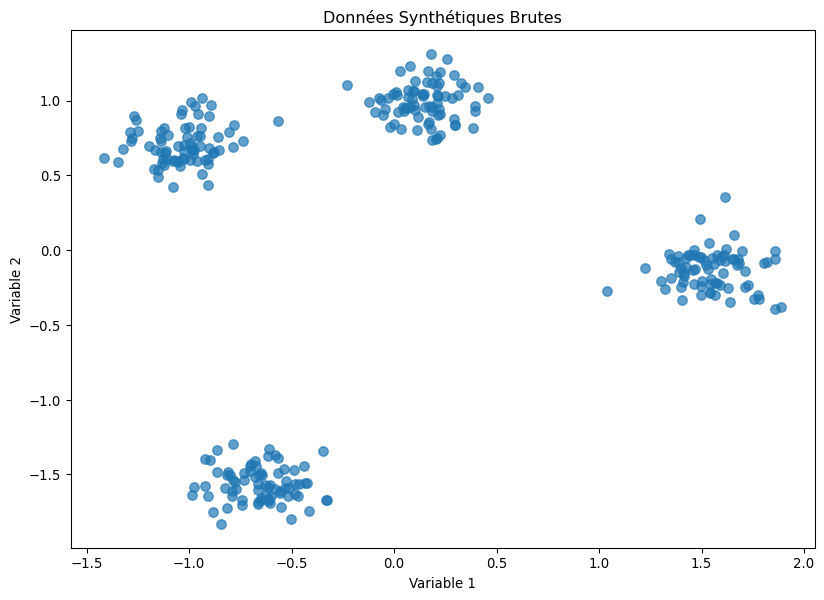
Utilisons le générateur make_blobs de Scikit-learn pour créer des données et mettons en pratique la recherche du \(K\) optimal.
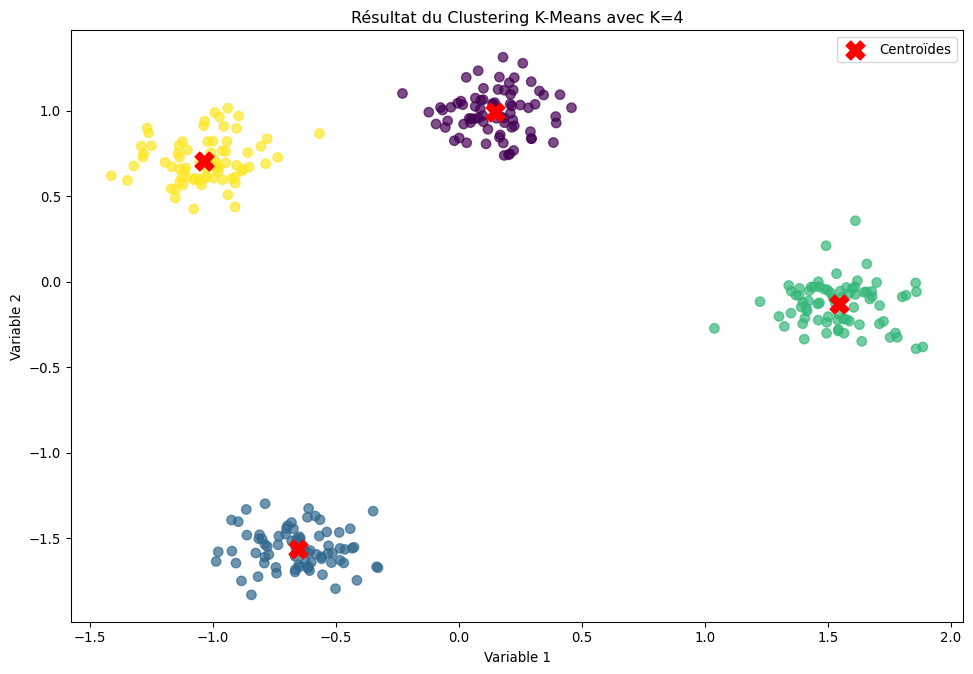
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import make_blobsfrom sklearn.preprocessing import StandardScalerfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_score# 1. Générer des données synthétiques# On crée 4 "blobs" (groupes) pour que nous connaissions la vraie réponseX, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.8, random_state=42)# Mise à l'échelle des données (toujours une bonne pratique)scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# Visualisation des données brutesplt.figure(figsize=(10, 7))plt.scatter(X_scaled[:, 0], X_scaled[:, 1], s=50, alpha=0.7)plt.title("Données Synthétiques Brutes")plt.xlabel("Variable 1")plt.ylabel("Variable 2")plt.show()# 2. Appliquer la Méthode du Coudeprint("--- Recherche du K optimal via la Méthode du Coude ---")inertia_values = []k_range =range(1, 11)for k in k_range: kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=42) kmeans.fit(X_scaled) inertia_values.append(kmeans.inertia_)# Tracer la courbe du coudeplt.figure(figsize=(10, 7))plt.plot(k_range, inertia_values, 'bo-')plt.xlabel('Nombre de clusters (K)')plt.ylabel('Inertie')plt.title('Méthode du Coude pour le Choix de K')plt.xticks(k_range)plt.grid(True)plt.show()print("Le 'coude' semble se situer à K=4, comme attendu.\n")# 3. Appliquer le Score de Silhouetteprint("--- Recherche du K optimal via le Score de Silhouette ---")silhouette_values = []for k inrange(2, 11): # Le score de silhouette n'est défini que pour K >= 2 kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=42) labels = kmeans.fit_predict(X_scaled) silhouette_values.append(silhouette_score(X_scaled, labels))# Tracer la courbe du score de silhouetteplt.figure(figsize=(10, 7))plt.plot(range(2, 11), silhouette_values, 'ro-')plt.xlabel('Nombre de clusters (K)')plt.ylabel('Score de Silhouette Moyen')plt.title('Score de Silhouette pour le Choix de K')plt.xticks(range(2, 11))plt.grid(True)plt.show()best_k_silhouette = np.argmax(silhouette_values) +2# +2 car on commence à k=2print(f"Le score de silhouette est maximal pour K={best_k_silhouette}.\n")# 4. Entraîner le modèle final avec le meilleur K et visualiserbest_k =4final_kmeans = KMeans(n_clusters=best_k, init='k-means++', n_init=10, random_state=42)y_kmeans = final_kmeans.fit_predict(X_scaled)centers = final_kmeans.cluster_centers_plt.figure(figsize=(12, 8))plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=y_kmeans, s=50, cmap='viridis', alpha=0.7)plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X', label='Centroïdes')plt.title(f"Résultat du Clustering K-Means avec K={best_k}")plt.xlabel("Variable 1")plt.ylabel("Variable 2")plt.legend()plt.show()
--- Recherche du K optimal via la Méthode du Coude ---
Le 'coude' semble se situer à K=4, comme attendu.
--- Recherche du K optimal via le Score de Silhouette ---
Le score de silhouette est maximal pour K=4.
7 Conclusion
K-Means est un algorithme incontournable pour le clustering par partition. Il est rapide, simple et efficace lorsque ses hypothèses sont respectées. Sa plus grande difficulté, le choix de \(K\), peut être abordée de manière méthodique grâce à des outils comme la méthode du coude et, de manière plus robuste, le score de silhouette.
Et maintenant ?
K-Means nous oblige à choisir \(K\) à l’avance et suppose des clusters sphériques. Que faire si nous ne connaissons pas le nombre de groupes ou si leur structure est plus complexe ? Dans notre prochain article, nous explorerons une approche différente : le clustering hiérarchique, qui construit un “arbre généalogique” de nos données.
8 Exercices
Exercise 1
Question 1
Quel est l’objectif principal de l’algorithme K-Means ?
Question 2
Lors de l’étape de mise à jour (M-Step) de l’algorithme K-Means, comment la position d’un centroïde est-elle recalculée ?
Question 3
Quel est le défi majeur lors de l’utilisation de K-Means ?
Question 4
La “Méthode du Coude” (Elbow Method) est utilisée pour choisir K. Quelle métrique est tracée pour identifier le “coude” ?
Question 5
Comment interprète-t-on un score de silhouette proche de +1 pour un point de données ?
Question 6
Lors de la recherche du K optimal, que cherche-t-on à faire avec le score de silhouette moyen ?
Question 7
Quelle est une des principales limites de K-Means concernant la structure des données ?
Question 8
Que se passe-t-il pendant l’étape d’assignation (E-Step) de l’algorithme K-Means ?
Question 9
L’initialisation k-means++ est utilisée par défaut dans Scikit-learn. Quel problème majeur de l’algorithme K-Means standard aide-t-elle à résoudre ?
Question 10
Dans l’atelier pratique, pourquoi est-il recommandé de mettre les données à l’échelle (StandardScaler) avant d’appliquer K-Means ?
Question 11
Sachant que la dispersion totale des données (TSS) est constante et que TSS = W(K) + B(K), que peut-on conclure sur l’objectif d’optimisation de K-Means ?
Question 12
Pourquoi K-Means est-il considéré comme un algorithme de “clustering par partitionnement” ?
Question 13
Quelle est la principale différence entre l’inertie et le score de silhouette pour l’évaluation du nombre de clusters K ?
Question 14
Si un point de données a un score de silhouette de 0, que cela signifie-t-il ?
Question 15
K-Means est un algorithme itératif. Quand le processus s’arrête-t-il ?
8.1 Exercices Pratiques
Exercice 1 : Segmentation des Vins
Objectif : Appliquer le workflow K-Means sur un jeu de données réel et évaluer la pertinence des clusters trouvés en les comparant aux vraies étiquettes.
Jeu de données : Utilisez le jeu de données wine de Scikit-learn (from sklearn.datasets import load_wine).
Étapes :
Chargez les données wine dans un DataFrame Pandas.
Mettez à l’échelle les variables numériques en utilisant StandardScaler.
Utilisez la méthode du coude et le score de silhouette pour déterminer le nombre optimal de clusters (sachant qu’il y a 3 classes de vin en réalité, est-ce que les métriques le confirment ?).
Appliquez l’algorithme K-Means avec le K que vous avez jugé optimal.
Pour évaluer la qualité de votre clustering, créez un tableau de contingence (pd.crosstab) qui croise les étiquettes de vos clusters avec les vraies étiquettes des vins (contenues dans wine.target).
Analysez ce tableau : le clustering a-t-il réussi à bien séparer les différentes classes de vin ? Quels sont les points de confusion ?
Exercice 2 : Analyse Critique d’un Scénario
Scénario : Une entreprise souhaite segmenter ses clients en fonction de deux variables : nombre_visites_mensuelles et montant_panier_moyen. Un nuage de points révèle deux groupes très distincts : - Un petit groupe très dense de “clients fidèles” avec un grand nombre de visites et un panier moyen élevé. - Un grand groupe très étalé et peu dense de “visiteurs occasionnels” avec peu de visites et un panier moyen faible.
Questions :
Quels sont les défis que l’algorithme K-Means pourrait rencontrer avec ce type de données ? Pensez aux hypothèses fondamentales de K-Means (forme, taille, densité des clusters).
Comment l’initialisation des centroïdes (même avec k-means++) pourrait-elle être problématique dans ce cas précis ?
Si vous appliquiez la méthode du coude sur ce jeu de données, quel nombre de clusters (K) serait probablement suggéré ? Pourquoi ce choix pourrait-il ne pas être le plus pertinent pour l’entreprise ?
Quel autre algorithme de clustering que vous connaissez pourrait être plus adapté à ce scénario et pourquoi ?