La Régression par Forêt Aléatoire : La Sagesse de la Foule
De l’arbre unique à l’ensemble puissant pour des prédictions robustes
Machine Learning
Apprentissage Supervisé
Méthodes Ensemblistes
Régression
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Au-delà de l’Arbre Unique
Dans notre dernier article, nous avons vu que les arbres de décision sont des modèles intuitifs et interprétables. Cependant, ils ont un défaut majeur : leur instabilité. Un petit changement dans les données d’entraînement peut produire un arbre complètement différent. Ils sont également très sujets au surapprentissage.
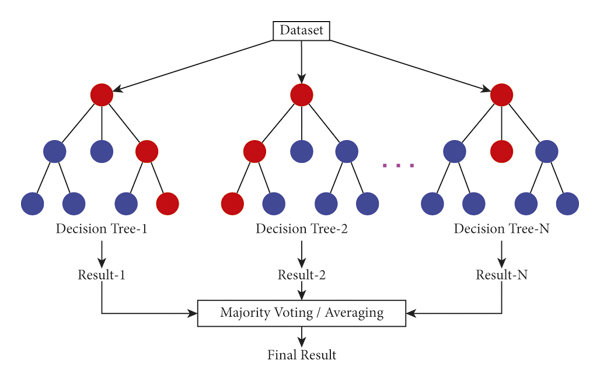
Comment surmonter ces faiblesses tout en gardant la puissance des arbres ? L’idée, comme souvent dans la vie, est de ne pas se fier à un seul expert, mais de consulter un comité d’experts. C’est le principe des méthodes ensemblistes, et son représentant le plus célèbre est la Forêt Aléatoire (Random Forest).
Ce post va vous montrer comment, en combinant des centaines d’arbres de décision simples, on peut obtenir l’un des modèles de régression les plus performants et les plus robustes qui existent.
2 L’Intuition : La Sagesse de la Foule
Une forêt aléatoire est littéralement ce que son nom indique : un ensemble (une “forêt”) de nombreux arbres de décision.
L’idée est la suivante :
On construit un grand nombre d’arbres de décision différents les uns des autres.
Pour faire une nouvelle prédiction, on demande à chaque arbre de la forêt de donner son avis.
La prédiction finale de la forêt est simplement la moyenne de toutes les prédictions individuelles.
En moyennant les prédictions de nombreux modèles différents, on lisse les erreurs et les biais de chaque arbre individuel. Un arbre qui a sur-appris dans une direction sera corrigé par un autre qui a sur-appris dans une autre direction. Le résultat est une prédiction beaucoup plus stable et fiable.
3 La Recette Magique : Comment Créer une Forêt “Aléatoire” ?
Pour que la “sagesse de la foule” fonctionne, il faut que les experts (nos arbres) soient diversifiés. Si tous les arbres sont identiques, leur moyenne n’apportera rien de plus. La forêt aléatoire utilise deux techniques pour garantir cette diversité :
3.1 Technique 1 : Le Bootstrap Aggregating (Bagging)
Au lieu d’entraîner chaque arbre sur l’intégralité du jeu de données d’entraînement, on va créer pour chaque arbre un échantillon bootstrap.
Un échantillon bootstrap est un sous-échantillon de même taille que l’original, mais créé par tirage avec remise. Cela signifie que certaines observations originales peuvent apparaître plusieurs fois dans un échantillon bootstrap, tandis que d’autres peuvent ne pas y figurer du tout.
En entraînant chaque arbre sur un échantillon bootstrap légèrement différent, on s’assure que chaque arbre a une “vision” un peu différente des données, ce qui les diversifie.
3.2 Technique 2 : La Sélection Aléatoire de Variables
C’est la deuxième source d’aléa, et c’est ce qui distingue vraiment la forêt aléatoire du simple bagging.
Lors de la construction de chaque arbre, au moment de choisir la meilleure division pour un nœud, l’algorithme ne considère pas toutes les variables explicatives disponibles. Il en sélectionne un sous-ensemble aléatoire (par exemple, 3 variables sur un total de 10). C’est seulement parmi ce sous-ensemble qu’il cherche la meilleure division possible.
Cette contrainte empêche un ou deux prédicteurs très forts de dominer systématiquement la construction de tous les arbres. Elle force les autres variables à être prises en compte, ce qui crée des arbres encore plus variés et décorrélés les uns des autres.
4 Avantages et Inconvénients
4.1 Avantages 👍
Performance : C’est l’un des modèles “prêts à l’emploi” les plus performants. Il donne souvent d’excellents résultats avec peu de réglages.
Robustesse : Très résistant au surapprentissage grâce au processus de moyennage.
Simplicité d’utilisation : Peu d’hyperparamètres à régler. Les plus importants sont le nombre d’arbres (n_estimators) et le nombre de variables à tester à chaque division (max_features).
Pas besoin de mise à l’échelle : Comme les arbres de décision, la forêt aléatoire n’est pas sensible à l’échelle des variables.
4.2 Inconvénients 👎
Perte d’Interprétabilité : C’est le principal compromis. On gagne en performance ce que l’on perd en simplicité. Une forêt de 500 arbres est une “boîte noire” ; il est très difficile de comprendre exactement comment elle prend sa décision, contrairement à un arbre unique.
Coût Calculatoire : Entraîner des centaines d’arbres peut être plus long et plus gourmand en mémoire qu’entraîner un seul modèle.
5 Atelier Pratique : Prédire à Nouveau la Valeur des Maisons
Reprenons notre problème de prédiction de la valeur des maisons en Californie et voyons si une forêt aléatoire peut battre notre arbre de décision élagué.
import pandas as pdimport numpy as npfrom sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error, r2_scoreimport matplotlib.pyplot as plt# 1. Charger les donnéeshousing = fetch_california_housing()X, y = housing.data, housing.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 2. Entraîner le modèle de Forêt Aléatoire# n_estimators: le nombre d'arbres dans la forêt.# random_state: pour la reproductibilité.# n_jobs=-1: pour utiliser tous les cœurs du processeur et accélérer l'entraînement.rf_model = RandomForestRegressor(n_estimators=100, random_state=42, n_jobs=-1)print("--- Entraînement de la Forêt Aléatoire (100 arbres) ---")rf_model.fit(X_train, y_train)print("Entraînement terminé.\n")# 3. Évaluer la performance sur le jeu de testprint("--- Évaluation du Modèle sur le Jeu de Test ---")y_pred = rf_model.predict(X_test)mse = mean_squared_error(y_test, y_pred)rmse = np.sqrt(mse)r2 = r2_score(y_test, y_pred)print(f"Erreur Quadratique Moyenne (MSE): {mse:.4f}")print(f"Racine de l'Erreur Quadratique Moyenne (RMSE): {rmse:.4f}")print(f"Coefficient de Détermination (R²): {r2:.4f}")print("\nObservation : Le R² est généralement bien meilleur que celui d'un arbre de décision unique, indiquant une performance prédictive supérieure.")# 4. Bonus : Importance des Variables (Feature Importance)# Même si le modèle est une boîte noire, il peut nous dire quelles variables ont été les plus utiles en moyenne pour réduire l'erreur.importances = rf_model.feature_importances_feature_importance_df = pd.DataFrame({'Feature': housing.feature_names,'Importance': importances}).sort_values(by='Importance', ascending=False)print("\n--- Importance des Variables selon la Forêt ---")print(feature_importance_df)# Visualisation de l'importanceplt.figure(figsize=(12, 8))plt.barh(feature_importance_df['Feature'], feature_importance_df['Importance'])plt.xlabel("Importance")plt.ylabel("Variable")plt.title("Importance des Variables dans la Prédiction")plt.gca().invert_yaxis() # Afficher la plus importante en hautplt.show()
--- Entraînement de la Forêt Aléatoire (100 arbres) ---
Entraînement terminé.
--- Évaluation du Modèle sur le Jeu de Test ---
Erreur Quadratique Moyenne (MSE): 0.2554
Racine de l'Erreur Quadratique Moyenne (RMSE): 0.5053
Coefficient de Détermination (R²): 0.8051
Observation : Le R² est généralement bien meilleur que celui d'un arbre de décision unique, indiquant une performance prédictive supérieure.
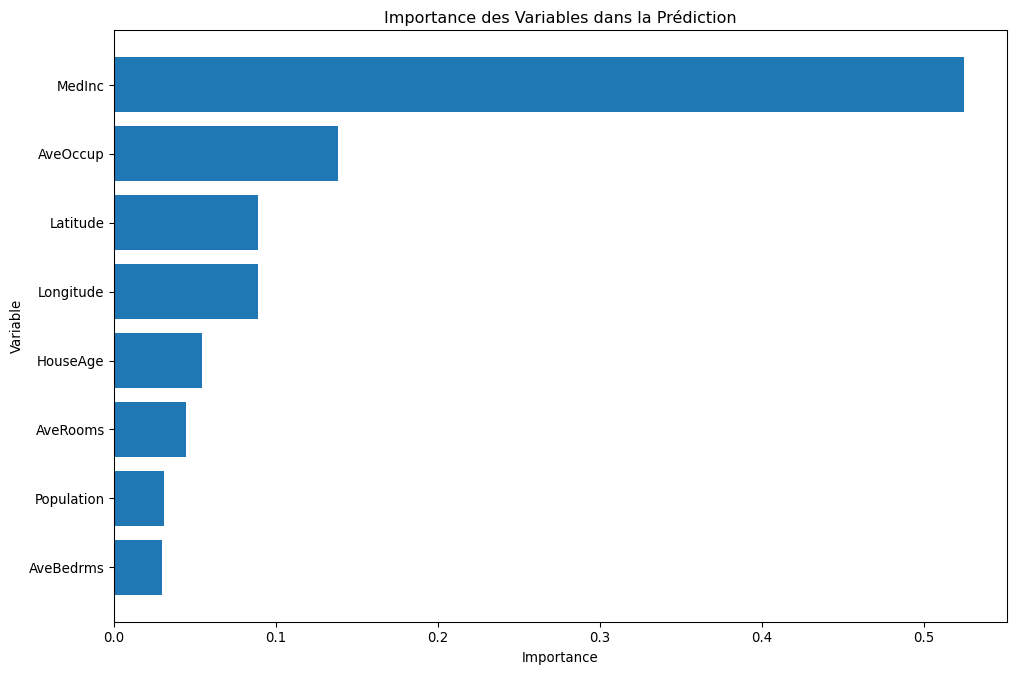
--- Importance des Variables selon la Forêt ---
Feature Importance
0 MedInc 0.524871
5 AveOccup 0.138443
6 Latitude 0.088936
7 Longitude 0.088629
1 HouseAge 0.054593
2 AveRooms 0.044272
4 Population 0.030650
3 AveBedrms 0.029606
6 Conclusion
La forêt aléatoire est un exemple parfait de la puissance des méthodes ensemblistes. En combinant de nombreux modèles “faibles” (des arbres de décision contraints), elle produit un modèle global extrêmement robuste et performant.
C’est souvent l’un des premiers modèles à essayer sur un nouveau problème de régression ou de classification, car il offre un excellent équilibre entre performance et facilité d’utilisation. Vous avez maintenant ajouté à votre arsenal l’un des algorithmes les plus respectés et les plus efficaces du Machine Learning.