import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeRegressor, plot_tree
import matplotlib.pyplot as plt
# 1. Charger et préparer les données
housing = fetch_california_housing()
X, y = housing.data, housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Entraîner un arbre complet et montrer le surapprentissage
full_tree = DecisionTreeRegressor(random_state=42)
full_tree.fit(X_train, y_train)
print(f"--- Arbre de Décision Complet ---")
print(f"Profondeur de l'arbre: {full_tree.get_depth()}")
print(f"Nombre de feuilles: {full_tree.get_n_leaves()}")
print(f"Score R² sur l'entraînement: {full_tree.score(X_train, y_train):.4f}")
print(f"Score R² sur le test: {full_tree.score(X_test, y_test):.4f}")
print("Observation: Le score sur l'entraînement est très élevé, mais il chute sur le test. C'est un signe clair de surapprentissage.\n")
# 3. Obtenir le chemin d'élagage
# Cette fonction nous donne les valeurs de alpha et les impuretés correspondantes
path = full_tree.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
# On retire le dernier alpha qui correspond à l'arbre trivial (un seul nœud)
ccp_alphas = ccp_alphas[:-1]
# 4. Trouver le meilleur alpha par validation croisée
print("--- Recherche du meilleur alpha par Validation Croisée ---")
alpha_scores = []
for alpha in ccp_alphas:
tree = DecisionTreeRegressor(random_state=42, ccp_alpha=alpha)
# On utilise le score MSE négatif car CV cherche à maximiser. Un MSE plus faible est meilleur.
score = cross_val_score(tree, X_train, y_train, cv=5, scoring='neg_mean_squared_error')
alpha_scores.append(np.mean(score))
# Trouver l'alpha qui a donné le meilleur score moyen
best_alpha = ccp_alphas[np.argmax(alpha_scores)]
print(f"Meilleur alpha trouvé : {best_alpha:.4f}")
# 5. Entraîner et évaluer l'arbre élagué final
pruned_tree = DecisionTreeRegressor(random_state=42, ccp_alpha=best_alpha)
pruned_tree.fit(X_train, y_train)
print("\n--- Arbre Élagué Optimal ---")
print(f"Profondeur de l'arbre: {pruned_tree.get_depth()}")
print(f"Nombre de feuilles: {pruned_tree.get_n_leaves()}")
print(f"Score R² sur l'entraînement: {pruned_tree.score(X_train, y_train):.4f}")
print(f"Score R² sur le test: {pruned_tree.score(X_test, y_test):.4f}")
print("Observation: Le score sur le test est maintenant bien meilleur ! Le modèle généralise mieux.")
# 6. Visualiser l'arbre élagué (les premières couches)
plt.figure(figsize=(20, 10))
plot_tree(pruned_tree,
feature_names=housing.feature_names,
filled=True,
rounded=True,
max_depth=3, # On affiche seulement les 3 premiers niveaux pour la lisibilité
fontsize=10)
plt.title("Visualisation de l'Arbre Élagué (premiers niveaux)")
plt.show()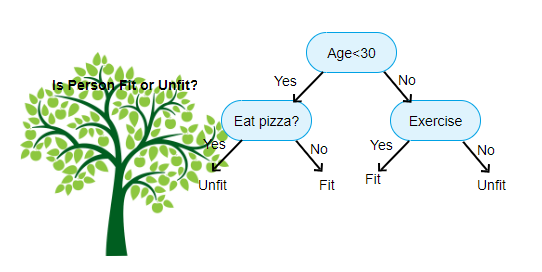
1 Introduction : Une Approche Visuelle et Intuitive
Après avoir exploré les modèles linéaires qui cherchent une équation globale et les k-NN qui se basent sur le voisinage, nous allons découvrir une troisième grande famille de modèles : les arbres de décision.
Un arbre de décision est peut-être le modèle de Machine Learning le plus facile à comprendre et à interpréter. Il imite la manière dont les humains prennent des décisions : en posant une série de questions simples, sous la forme d’un organigramme (ou “flowchart”).
Pour la régression, l’arbre va segmenter l’espace des données en régions rectangulaires et assigner une valeur de prédiction constante à chaque région. Ce post vous guidera à travers la construction de cet arbre, le danger inhérent du surapprentissage, et la technique cruciale de l’élagage (pruning) pour créer un modèle à la fois performant et généralisable.
2 L’Intuition : Comment un Arbre Prédit un Nombre
Imaginez que vous deviez prédire le salaire d’un employé. Un arbre de décision pourrait poser les questions suivantes : 1. L’employé a-t-il plus de 5 ans d’expérience ?
- **Oui :** On continue dans la branche de droite.
- **Non :** On continue dans la branche de gauche.(Dans la branche “Oui”) L’employé a-t-il un diplôme de Master ?
- Oui : La prédiction est de 75 000 €.
- Non : La prédiction est de 60 000 €.
(Dans la branche “Non”) … et ainsi de suite.
Chaque question divise les données en deux. On continue ce processus jusqu’à ce qu’on arrive à une “feuille” de l’arbre, qui contient la prédiction finale. Pour la régression, cette prédiction est simplement la moyenne des valeurs de la cible (y) de toutes les observations d’entraînement qui sont tombées dans cette feuille.

3 La Construction de l’Arbre : La Partition Binaire Récursive
Comment l’algorithme choisit-il les “meilleures” questions à poser ? Il utilise un processus appelé partition binaire récursive.
L’idée est de trouver, à chaque étape, la variable et le seuil de division qui réduisent le plus l’erreur de prédiction. Pour la régression, le critère standard est de minimiser la Somme des Carrés des Résidus (RSS - Residual Sum of Squares).
L’algorithme :
- Il commence avec toutes les données dans un seul nœud.
- Pour chaque variable explicative, il teste tous les seuils de division possibles.
- Il choisit la variable et le seuil qui, en divisant les données en deux nouvelles régions (R1 et R2), aboutissent à la plus faible RSS totale : \[\text{RSS} = \sum_{i \in R_1} (y_i - \bar{y}_{R1})^2 + \sum_{i \in R_2} (y_i - \bar{y}_{R2})^2\] Où \(\bar{y}_{R1}\) et \(\bar{y}_{R2}\) sont les moyennes de la cible dans chaque nouvelle région.
- L’algorithme répète ensuite ce processus de manière récursive sur les nouvelles régions R1 et R2, et ainsi de suite, jusqu’à ce qu’un critère d’arrêt soit atteint (ex: un nombre minimum d’observations par feuille).
4 Le Grand Danger : Le Surapprentissage
Si on laisse un arbre grandir sans aucune contrainte, il continuera à se diviser jusqu’à ce que chaque feuille contienne le moins d’observations possible (idéalement, une seule).
Le résultat ? Un arbre extrêmement complexe qui mémorise parfaitement le jeu de données d’entraînement. Son erreur sur ces données sera nulle, mais il sera incapable de généraliser à de nouvelles données. C’est le cas d’école du surapprentissage (overfitting).
5 La Solution : L’Élagage par Complexité de Coût
Comment empêcher l’arbre de devenir trop complexe ? On pourrait essayer de fixer des critères d’arrêt (ex: profondeur maximale), mais c’est une approche peu flexible.
La méthode la plus robuste est l’élagage (pruning). L’idée est de :
- Faire pousser un arbre très grand et complexe.
- “Tailler” les branches les moins importantes pour obtenir un sous-arbre plus simple et plus robuste.
La technique standard pour cela est l’élagage par complexité de coût (Cost-Complexity Pruning). On ne cherche plus seulement à minimiser la RSS, mais une nouvelle fonction de coût qui pénalise la complexité de l’arbre :
\[C(T) = \text{RSS}(T) + \alpha \times |T|\]
- \(T\) est un sous-arbre donné.
- \(|T|\) est le nombre de feuilles de l’arbre (sa complexité).
- \(\alpha \ge 0\) est le paramètre de complexité. C’est un hyperparamètre qui contrôle le compromis entre la qualité de l’ajustement (faible RSS) et la simplicité de l’arbre (faible \(|T|\)).
Pour chaque valeur de \(\alpha\), il existe un unique sous-arbre qui minimise cette fonction de coût. Scikit-learn peut nous fournir la séquence de ces arbres élagués, du plus complexe (\(\alpha=0\)) au plus simple (un seul nœud).
6 Atelier Pratique : Trouver l’Arbre Optimal
Notre mission est de trouver la meilleure valeur de alpha qui donne l’arbre avec la meilleure performance de généralisation. Pour cela, nous utiliserons la validation croisée.
Utilisons le jeu de données California Housing pour prédire la valeur des maisons.
7 Conclusion
Les arbres de décision sont des modèles puissants, et leur principal avantage est leur interprétabilité. On peut littéralement suivre le chemin de décision de l’algorithme.
Cependant, leur principal défaut est leur instabilité et leur forte tendance au surapprentissage. L’élagage par complexité de coût est la méthode de référence pour contrôler cette complexité et construire un modèle robuste.
Et maintenant ?
Les arbres de décision sont de bons modèles, mais ils peuvent être encore améliorés. Que se passerait-il si, au lieu de construire un seul arbre, nous en construisions des centaines et que nous faisions la moyenne de leurs prédictions ? C’est l’idée derrière les méthodes ensemblistes comme les Forêts Aléatoires (Random Forests), qui sont parmi les modèles les plus performants en Machine Learning. C’est ce que nous explorerons dans un prochain article!