Gérer la Complexité : Variables Catégorielles et Relations Non-Linéaires
Partie 2 de la série ‘Maîtriser la Régression’
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Rendre la Régression Flexible
Dans notre dernier article, nous avons appris à faire le bilan de santé d’un modèle de régression linéaire. Mais que se passe-t-il si le diagnostic révèle que l’une des hypothèses fondamentales, la linéarité, n’est pas respectée ? Ou comment intégrer dans notre modèle une information cruciale qui n’est pas un nombre, comme le département d’un employé ou le type d’un produit ?
Le modèle de régression linéaire, malgré son nom, est un outil incroyablement flexible. Ce post va vous montrer comment l’étendre pour gérer deux des situations les plus courantes en analyse de données :
L’intégration de variables qualitatives (ou catégorielles).
La modélisation de relations non-linéaires (courbes).
Maîtriser ces deux techniques décuplera la puissance et la pertinence de vos modèles.
2 Partie A : Intégrer des Variables Catégorielles
2.1 Le Problème : Comment mettre des mots dans une équation ?
Notre équation de régression \(Y = \beta_0 + \beta_1 X_1 + \dots\) ne sait manipuler que des nombres. Comment lui faire comprendre une variable comme jour_de_la_semaine qui peut prendre les valeurs ‘Lundi’, ‘Mardi’, ‘Mercredi’, etc. ? On ne peut pas simplement les remplacer par 1, 2, 3, car cela imposerait une relation d’ordre et une distance arbitraire entre les jours.
2.2 La Solution : Le Codage en Variables Muettes (Dummy Coding)
La solution standard est de transformer la variable catégorielle en un ensemble de variables numériques binaires (0 ou 1), appelées variables muettes (dummy variables).
Le processus pour une variable à \(k\) catégories :
Choisir une catégorie de référence. C’est la catégorie de base à laquelle toutes les autres seront comparées.
Créer \(k-1\) nouvelles variables. Chaque nouvelle variable correspond à l’une des catégories restantes.
Pour une observation donnée, la variable muette correspondant à sa catégorie prend la valeur 1, et toutes les autres prennent la valeur 0. Si une observation appartient à la catégorie de référence, toutes les variables muettes valent 0.
Exemple : Variable departement avec 3 niveaux : ‘RH’ (référence), ‘Vente’, ‘IT’.
departement
est_Vente
est_IT
RH
0
0
Vente
1
0
IT
0
1
2.3 Interprétation des Coefficients
L’interprétation du coefficient d’une variable muette est cruciale.
Interprétation d’un coefficient de variable muette
Le coefficient \(\hat{\beta}_{\text{est_Vente}}\) ne représente pas l’effet “absolu” du département Vente. Il représente la différence moyenne de la variable cible \(Y\) entre le groupe ‘Vente’ et le groupe de référence (‘RH’ dans notre cas), toutes choses égales par ailleurs.
3 Partie B : Modéliser des Courbes
3.1 Le Problème : Quand une ligne droite ne suffit pas
Le diagnostic de votre modèle (le graphique Résidus vs. Valeurs Prédites) montre une forme de “U” ? C’est le signe que la relation entre une de vos variables \(X\) et votre cible \(Y\) n’est pas linéaire. Forcer une ligne droite sur une relation courbe mènera à des prédictions systématiquement fausses.
3.2 La Solution : La Régression Polynomiale
L’astuce consiste à créer de nouvelles variables explicatives en élevant une variable existante à différentes puissances (\(X^2, X^3\), etc.). On peut ensuite inclure ces nouveaux termes dans notre modèle.
Par exemple, pour modéliser une parabole, on utiliserait le modèle : \[ Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \varepsilon \]
Le paradoxe : pourquoi est-ce toujours une régression “linéaire” ? Le terme “linéaire” dans “régression linéaire” ne se réfère pas à la forme de la courbe, mais au fait que le modèle est linéaire dans ses coefficients \(\beta\). L’équation ci-dessus est bien une somme pondérée de termes, donc elle reste dans le cadre de la régression linéaire.
4 Atelier Pratique : Prédire les Pourboires
Utilisons le jeu de données tips pour construire un modèle qui prédit le montant du pourboire (tip) en utilisant : - Le montant total de l’addition (total_bill), en supposant que la relation pourrait être non-linéaire. - Le jour de la semaine (day), une variable catégorielle.
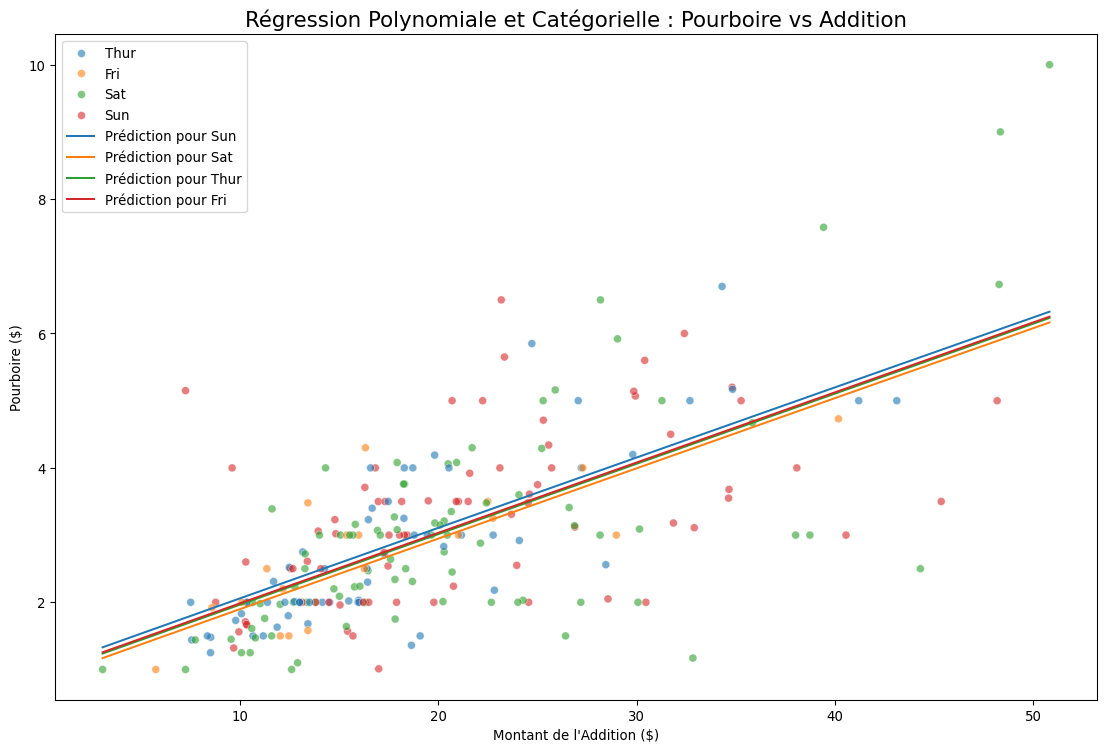
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport statsmodels.api as smfrom statsmodels.formula.api import ols# 1. Charger les donnéestips = sns.load_dataset('tips')# 2. Modélisation# La formule de statsmodels est très expressive pour gérer cela :# - C(day) dit à statsmodels de traiter 'day' comme une variable catégorielle et de créer les dummies.# - I(total_bill**2) permet d'inclure le terme quadratique.formula ='tip ~ total_bill + I(total_bill**2) + C(day)'model = ols(formula, data=tips).fit()print("--- Résumé du Modèle de Régression Complexe ---")print(model.summary())# 3. Visualisation du résultatprint("\n--- Visualisation du Modèle Ajusté ---")# On crée une grille de valeurs pour tracer les courbes de prédictionx_range = np.linspace(tips['total_bill'].min(), tips['total_bill'].max(), 100)days = tips['day'].unique()plt.figure(figsize=(14, 9))sns.scatterplot(x='total_bill', y='tip', data=tips, hue='day', alpha=0.6)for day in days:# On crée un dataframe pour la prédiction plot_data = pd.DataFrame({'total_bill': x_range,'day': day })# On prédit les valeurs pour chaque jour predictions = model.predict(plot_data) plt.plot(x_range, predictions, label=f'Prédiction pour {day}')plt.title("Régression Polynomiale et Catégorielle : Pourboire vs Addition", fontsize=16)plt.xlabel("Montant de l'Addition ($)")plt.ylabel("Pourboire ($)")plt.legend()plt.show()
--- Résumé du Modèle de Régression Complexe ---
OLS Regression Results
==============================================================================
Dep. Variable: tip R-squared: 0.459
Model: OLS Adj. R-squared: 0.448
Method: Least Squares F-statistic: 40.36
Date: Wed, 09 Jul 2025 Prob (F-statistic): 5.73e-30
Time: 09:58:10 Log-Likelihood: -350.03
No. Observations: 244 AIC: 712.1
Df Residuals: 238 BIC: 733.0
Df Model: 5
Covariance Type: nonrobust
======================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------------
Intercept 0.9136 0.360 2.537 0.012 0.204 1.623
C(day)[T.Fri] 0.0190 0.270 0.071 0.944 -0.512 0.551
C(day)[T.Sat] -0.0672 0.172 -0.390 0.697 -0.406 0.272
C(day)[T.Sun] 0.0932 0.179 0.521 0.603 -0.259 0.446
total_bill 0.1054 0.031 3.376 0.001 0.044 0.167
I(total_bill ** 2) -1.376e-05 0.001 -0.023 0.982 -0.001 0.001
==============================================================================
Omnibus: 21.051 Durbin-Watson: 2.148
Prob(Omnibus): 0.000 Jarque-Bera (JB): 39.178
Skew: 0.465 Prob(JB): 3.11e-09
Kurtosis: 4.729 Cond. No. 3.74e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.74e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
--- Visualisation du Modèle Ajusté ---
4.1 Interprétation du Résultat
Résumé du Modèle :
C(day)[T.Sat], C(day)[T.Sun], C(day)[T.Thur] : Ces coefficients représentent la différence de pourboire moyenne pour ces jours par rapport au jour de référence (Fri - Vendredi). Par exemple, le coefficient pour C(day)[T.Sun] est positif, suggérant qu’à addition égale, les gens donnent plus de pourboire le dimanche que le vendredi.
I(total_bill ** 2) : Le coefficient de ce terme est significatif (p-value < 0.05), ce qui confirme que la relation entre l’addition et le pourboire n’est pas purement linéaire. La courbe s’aplatit légèrement pour les très grosses additions.
Visualisation : Le graphique montre bien comment le modèle a ajusté une courbe différente pour chaque jour de la semaine. Les courbes sont parallèles (car nous n’avons pas inclus de terme d’interaction), mais décalées verticalement en fonction de l’effet de chaque jour.
5 Conclusion
Vous savez maintenant comment briser les deux plus grandes limitations apparentes de la régression linéaire. En utilisant le codage en variables muettes et les termes polynomiaux, vous pouvez construire des modèles beaucoup plus riches, flexibles et adaptés à la complexité des données du monde réel. Votre boîte à outils de modélisation vient de s’enrichir considérablement.
Et maintenant ?
Nous savons construire des modèles complexes. Mais plus un modèle est complexe, plus il risque de “trop bien” apprendre les données d’entraînement et de perdre sa capacité à généraliser. C’est le problème du surapprentissage. Dans notre prochain article, nous aborderons les techniques de régression régularisée (Ridge et Lasso), conçues pour combattre ce phénomène et construire des modèles plus robustes.