Le Bilan de Santé de Votre Modèle : Diagnostiquer la Régression Linéaire
Partie 1 de la série ‘Maîtriser la Régression’
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Au-delà du \(R^2\)
Vous avez construit votre premier modèle de régression linéaire. Le R² ajusté semble bon, les coefficients ont l’air pertinents. Mission accomplie ? Pas si vite !
Un modèle de régression est comme une voiture de course : sa performance affichée ne dit rien de sa fiabilité. Pour être sûr que votre modèle n’est pas sur le point de sortir de la route, vous devez passer au contrôle technique. C’est le rôle du diagnostic de la régression.
Ce post vous guidera à travers les étapes essentielles pour valider la santé de votre modèle. Nous apprendrons à vérifier les hypothèses fondamentales qui sous-tendent la régression linéaire et à identifier les points de données qui pourraient fausser nos résultats.
2 Les 4 Hypothèses Clés d’un Modèle Fiable (L.I.N.E.)
La validité des tests statistiques de votre modèle (les p-values de vos coefficients, les intervalles de confiance) repose sur quatre hypothèses principales concernant les résidus (\(\varepsilon = y - \hat{y}\)). L’acronyme L.I.N.E. est un bon moyen de s’en souvenir.
2.1 L - Linéarité
L’hypothèse : La relation entre les variables explicatives (\(X\)) et la variable cible (\(Y\)) est linéaire.
Pourquoi c’est important ? Si la relation est en réalité une courbe (ex: quadratique), votre modèle de ligne droite sera fondamentalement erroné et vos prédictions seront biaisées.
Comment vérifier ? Le graphique des Résidus vs. Valeurs Prédites. Il doit ressembler à un nuage de points aléatoire, sans structure, centré autour de 0. Une forme de “U” ou de “U inversé” est un signal d’alarme.
2.2 I - Indépendance des Erreurs
L’hypothèse : Les erreurs (résidus) sont indépendantes les unes des autres. L’erreur d’une observation ne doit pas être corrélée à l’erreur d’une autre.
Pourquoi c’est important ? C’est une hypothèse cruciale pour les données temporelles (séries chronologiques). Si les erreurs sont corrélées (autocorrélation), vos intervalles de confiance et p-values seront faussement optimistes.
Comment vérifier ? Principalement par la connaissance du design de l’étude. Pour les séries temporelles, on utilise le graphique des résidus en fonction du temps ou le test de Durbin-Watson.
2.3 N - Normalité des Erreurs
L’hypothèse : Les résidus du modèle suivent une distribution Normale.
Pourquoi c’est important ? Cette hypothèse est nécessaire pour que les tests d’hypothèses sur les coefficients (\(\beta_j\)) soient valides, surtout avec de petits échantillons.
Comment vérifier ? Le Q-Q Plot (Quantile-Quantile Plot) est l’outil roi. Les points doivent s’aligner sur la diagonale. Un histogramme des résidus peut aussi donner une première intuition.
2.4 E - Égalité de la Variance des Erreurs (Homoscédasticité)
L’hypothèse : La variance des résidus est constante pour tous les niveaux des variables explicatives. On parle d’homoscédasticité.
Pourquoi c’est important ? Si la variance change (hétéroscédasticité), les estimations des coefficients par les moindres carrés sont toujours sans biais, mais elles ne sont plus les plus efficaces. Les p-values et intervalles de confiance deviennent alors incorrects.
Comment vérifier ? De nouveau, le graphique des Résidus vs. Valeurs Prédites. Une forme de cône ou d’entonnoir (la dispersion des points augmente ou diminue avec les valeurs prédites) est le signe classique de l’hétéroscédasticité.
3 Identifier les Points Problématiques
Certaines observations individuelles peuvent avoir une influence disproportionnée sur votre modèle. Il faut savoir les repérer.
Outliers (Valeurs Aberrantes) : Des observations avec un résidu très élevé. Le modèle se trompe beaucoup pour ces points.
Points à Fort Levier (High Leverage Points) : Des observations avec des valeurs de variables explicatives (\(X\)) extrêmes ou inhabituelles. Ces points ont le potentiel de tirer la droite de régression vers eux.
Points Influents : Le pire des deux mondes. Ce sont des points (souvent des outliers avec un fort levier) qui, si on les retirait, changeraient de manière significative les coefficients du modèle. La distance de Cook est la mesure la plus courante pour quantifier cette influence.
4 Atelier Pratique : Le Diagnostic en Python
Mettons tout cela en pratique. Nous allons construire un modèle et générer les graphiques de diagnostic essentiels avec les bibliothèques statsmodels et seaborn.
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport statsmodels.api as smfrom statsmodels.formula.api import ols# --- 1. Création d'un jeu de données pour la démonstration ---# On va délibérément introduire de légers problèmes pour les diagnostiquernp.random.seed(42)n =100X1 = np.random.uniform(1, 10, n)X2 = np.random.uniform(1, 20, n)# Une relation légèrement non-linéaire et hétéroscédastiqueerror = np.random.normal(0, np.sqrt(X1) *1.5, n) y =10+2* X1 +0.5* X1**2+3* X2 + errordf = pd.DataFrame({'y': y, 'X1': X1, 'X2': X2})# --- 2. Construction du modèle linéaire (en supposant à tort une relation linéaire) ---model = ols('y ~ X1 + X2', data=df).fit()print(model.summary())# --- 3. Création des graphiques de diagnostic ---# On récupère les informations nécessaires du modèlefitted_values = model.fittedvaluesresiduals = model.residstudentized_residuals = model.get_influence().resid_studentized_internalleverage = model.get_influence().hat_matrix_diagprint("\n--- Génération des Graphiques de Diagnostic ---")fig, axes = plt.subplots(2, 2, figsize=(16, 14))fig.suptitle("Bilan de Santé du Modèle de Régression", fontsize=18)# Graphique 1 : Résidus vs. Valeurs Prédites (pour Linéarité & Homoscédasticité)sns.residplot(x=fitted_values, y=residuals, lowess=True, scatter_kws={'alpha': 0.5}, line_kws={'color': 'red', 'lw': 2}, ax=axes[0, 0])axes[0, 0].set_title('Résidus vs. Valeurs Prédites', fontsize=14)axes[0, 0].set_xlabel('Valeurs Prédites')axes[0, 0].set_ylabel('Résidus')# Graphique 2 : Q-Q Plot (pour Normalité des résidus)sm.qqplot(residuals, line='45', fit=True, ax=axes[0, 1])axes[0, 1].set_title('Q-Q Plot des Résidus', fontsize=14)# Graphique 3 : Scale-Location (pour Homoscédasticité)axes[1, 0].scatter(fitted_values, np.sqrt(np.abs(studentized_residuals)), alpha=0.5)sns.regplot(x=fitted_values, y=np.sqrt(np.abs(studentized_residuals)), scatter=False, ci=False, lowess=True, line_kws={'color': 'red', 'lw': 2}, ax=axes[1, 0])axes[1, 0].set_title('Scale-Location Plot', fontsize=14)axes[1, 0].set_xlabel('Valeurs Prédites')axes[1, 0].set_ylabel('√|Résidus Standardisés|')# Graphique 4 : Résidus vs. Levier (pour points influents)sm.graphics.influence_plot(model, ax=axes[1, 1], criterion="cooks")axes[1, 1].set_title('Résidus vs. Levier (Distance de Cook)', fontsize=14)plt.tight_layout(rect=[0, 0.03, 1, 0.95])plt.show()
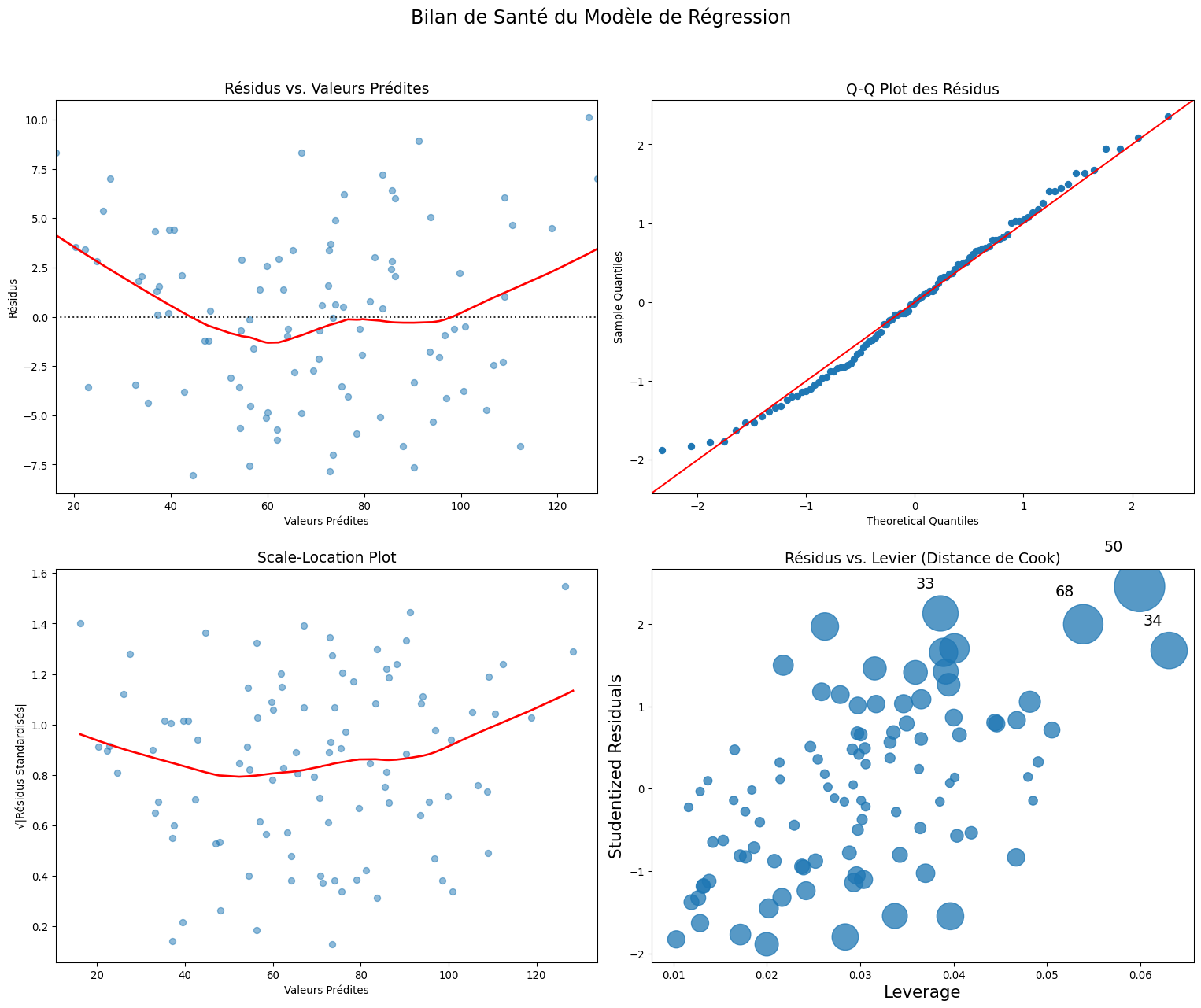
Résidus vs. Valeurs Prédites : La ligne rouge n’est pas parfaitement plate, elle a une légère forme de courbe. C’est un signe de non-linéarité. De plus, les points semblent se disperser un peu plus vers la droite, un indice d’hétéroscédasticité.
Q-Q Plot : Les points suivent assez bien la ligne diagonale, sauf aux extrémités. L’hypothèse de normalité des résidus semble raisonnablement respectée.
Scale-Location : La ligne rouge a une tendance à monter, ce qui confirme notre suspicion d’hétéroscédasticité (la variance des résidus augmente avec la valeur prédite).
Résidus vs. Levier : Ce graphique nous permet d’identifier les points qui ont un fort levier et/ou un fort résidu. Les points sont numérotés, et la taille des bulles est proportionnelle à la distance de Cook. Ici, aucun point ne semble avoir une influence dramatique.
Conclusion du diagnostic : Notre modèle a des problèmes de non-linéarité et d’hétéroscédasticité. Avant de faire confiance à ses coefficients, il faudrait l’améliorer, par exemple en ajoutant un terme quadratique pour \(X\_1\) (comme nous l’avions fait en créant les données !).
5 Conclusion
Le diagnostic de régression n’est pas une simple formalité, c’est une étape fondamentale qui garantit la validité et la fiabilité de vos conclusions. En utilisant systématiquement ces quelques graphiques, vous développez une compréhension beaucoup plus profonde de la relation entre vos données et votre modèle.
Et maintenant ?
Nous avons diagnostiqué un modèle et trouvé des problèmes. La prochaine étape logique est d’apprendre à les corriger ! Dans notre prochain article, nous verrons comment rendre notre modèle plus flexible pour gérer des variables catégorielles et des relations non-linéaires.