Forêts Aléatoires : Comment le Hasard Crée la Performance
Machine Learning
Apprentissage Supervisé
Bagging
Forêts Aléatoires
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction
Dans notre introduction, nous avons vu que le Bagging est une stratégie d’ensemble visant à réduire la variance de modèles instables. Aujourd’hui, nous allons disséquer ce mécanisme et son application la plus célèbre et la plus puissante : l’algorithme des Forêts Aléatoires (Random Forests).
2 Le Bagging (Bootstrap Aggregating) Décortiqué ⚙️
Le nom “Bagging” est la contraction de Bootstrap Aggregating. Le processus est exactement ce que son nom suggère.
2.1 Bootstrap
La première étape consiste à créer de la diversité dans les données d’entraînement. Partant d’un jeu de données original \(D\) contenant \(n\) observations, nous créons \(B\) nouveaux jeux de données \(D_1, D_2, \dots, D_B\), chacun de taille \(n\), en utilisant la technique du bootstrap (échantillonnage avec remise).
Cela signifie que pour chaque \(D_b\), nous tirons \(n\) fois une observation de \(D\), en la remettant à chaque fois. En conséquence, chaque échantillon bootstrap est différent : certains points de données originaux peuvent apparaître plusieurs fois, tandis que d’autres peuvent ne pas apparaître du tout.
Le saviez-vous ? En moyenne, un échantillon bootstrap contient environ 63.2% des observations uniques de l’ensemble original. La probabilité qu’une observation ne soit pas choisie en \(n\) tirages est \((1 - 1/n)^n\), ce qui tend vers \(e^{-1} \approx 0.368\) lorsque \(n\) est grand. La probabilité d’être inclus est donc de \(1 - 0.368 = 0.632\).
2.2 Aggregating
La deuxième étape consiste à entraîner un modèle de base (par exemple, un arbre de décision) de manière indépendante sur chacun des \(B\) échantillons bootstrap. On obtient ainsi un ensemble de \(B\) modèles \(\hat{f}_1, \hat{f}_2, \dots, \hat{f}_B\).
Pour faire une prédiction sur une nouvelle donnée \(x\), on agrège les résultats :
En régression, on fait la moyenne des prédictions de tous les modèles : \[ \hat{f}_{\text{bag}}(x) = \frac{1}{B} \sum_{b=1}^{B} \hat{f}_b(x) \]
En classification, on effectue un vote à la majorité. La classe prédite est celle qui est la plus souvent proposée par les modèles de l’ensemble : \[ \hat{C}_{\text{bag}}(x) = \underset{k}{\text{argmax}} \left( \sum_{b=1}^{B} I(\hat{f}_b(x) = k) \right) \] où \(I(\cdot)\) est la fonction indicatrice.
Ce processus de moyennage ou de vote lisse les prédictions, réduisant drastiquement la variance et donc la tendance au sur-apprentissage du modèle final.
3 L’Évolution : Les Forêts Aléatoires 🌲🌳
Le Bagging avec des arbres de décision est déjà très efficace. Cependant, il présente une faiblesse : si une ou quelques variables sont très prédictives, elles seront probablement sélectionnées pour les premières divisions dans tous les arbres de l’ensemble. Cela rend les arbres structurellement similaires et leurs prédictions corrélées, ce qui limite l’efficacité de la réduction de variance.
C’est ici que les Forêts Aléatoires introduisent leur ingrédient secret : une deuxième source de hasard.
Au lieu de considérer toutes les variables à chaque division d’un nœud, l’algorithme des Forêts Aléatoires ne considère qu’un sous-ensemble aléatoire de variables.
Typiquement, pour un problème de classification avec \(p\) variables, l’algorithme en sélectionne \(m \approx \sqrt{p}\) au hasard à chaque étape de division. En forçant les arbres à choisir parmi un sous-ensemble restreint de prédicteurs, on s’assure qu’ils ne peuvent pas tous s’appuyer sur la même variable dominante. Cela les décorrèle fortement, maximisant ainsi l’effet de la réduction de variance par l’agrégation.
4 Atelier Pratique : Bagging vs. Forêt Aléatoire
Comparons un simple Bagging d’arbres de décision à une Forêt Aléatoire pour voir l’effet de cette décorrélation.
4.1 En Classification sur données simulées
from sklearn.datasets import make_classificationfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scorefrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import BaggingClassifierfrom sklearn.ensemble import RandomForestClassifier# 1. Générer un jeu de données synthétiqueX, y = make_classification( n_samples=1000, n_features=20, n_informative=10, # Seules 10 variables sont réellement utiles n_redundant=5, # 5 sont des combinaisons linéaires des utiles n_repeated=0, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 2. Modèle 1: Bagging simple d'arbres de décision# On utilise un arbre de décision comme estimateur de basebagging_clf = BaggingClassifier( estimator=DecisionTreeClassifier(random_state=42), n_estimators=100, random_state=42, n_jobs=-1)bagging_clf.fit(X_train, y_train)y_pred_bag = bagging_clf.predict(X_test)acc_bag = accuracy_score(y_test, y_pred_bag)print(f"Accuracy (Bagging d'Arbres) : {acc_bag:.4f}")# 3. Modèle 2: Forêt Aléatoire# La Forêt Aléatoire fait la même chose, mais avec la décorrélation des variablesrf_clf = RandomForestClassifier( n_estimators=100, random_state=42, n_jobs=-1)rf_clf.fit(X_train, y_train)y_pred_rf = rf_clf.predict(X_test)acc_rf = accuracy_score(y_test, y_pred_rf)print(f"Accuracy (Forêt Aléatoire) : {acc_rf:.4f}")
Dans la plupart des cas, la Forêt Aléatoire affiche une performance égale ou légèrement supérieure. Sa robustesse vient de sa capacité à explorer un plus large éventail d’interactions entre les variables, là où le Bagging simple pourrait se concentrer de manière répétitive sur les quelques variables les plus dominantes.
4.2 En Régression sur données réelles
CodeLes données
Nous allons utiliser le jeu de données California Housing pour prédire la valeur médiane des maisons.
Code
from sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import r2_score, mean_squared_errorimport numpy as npfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.ensemble import BaggingRegressorfrom sklearn.ensemble import RandomForestRegressor# 1. Charger les données California Housinghousing = fetch_california_housing()X, y = housing.data, housing.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 2. Modèle 1: Bagging de Régresseurs par Arbre de Décisionbagging_reg = BaggingRegressor( estimator=DecisionTreeRegressor(random_state=42), n_estimators=100, random_state=42, n_jobs=-1)bagging_reg.fit(X_train, y_train)y_pred_bag_reg = bagging_reg.predict(X_test)r2_bag_reg = r2_score(y_test, y_pred_bag_reg)rmse_bag_reg = np.sqrt(mean_squared_error(y_test, y_pred_bag_reg))print(f"Performance (Bagging d'Arbres de Régression) :")print(f" R²: {r2_bag_reg:.4f}, RMSE: {rmse_bag_reg:.4f}")# 3. Modèle 2: Forêt Aléatoire de Régressionrf_reg = RandomForestRegressor( n_estimators=100, random_state=42, n_jobs=-1)rf_reg.fit(X_train, y_train)y_pred_rf_reg = rf_reg.predict(X_test)r2_rf_reg = r2_score(y_test, y_pred_rf_reg)rmse_rf_reg = np.sqrt(mean_squared_error(y_test, y_pred_rf_reg))print(f"\\nPerformance (Forêt Aléatoire de Régression) :")print(f" R²: {r2_rf_reg:.4f}, RMSE: {rmse_rf_reg:.4f}")
Performance (Bagging d'Arbres de Régression) :
R²: 0.8043, RMSE: 0.5068
\nPerformance (Forêt Aléatoire de Régression) :
R²: 0.8046, RMSE: 0.5065
Analyse des résultats
Ici aussi, la Forêt Aléatoire surpasse légèrement le Bagging simple. Le R² est plus élevé et le RMSE (l’erreur de prédiction moyenne) est plus faible. La décorrélation des arbres en forçant une sélection aléatoire de variables à chaque division s’avère bénéfique pour la performance globale du modèle.
5 Les “Super-Pouvoirs” des Forêts Aléatoires 🦸
Au-delà de leur performance, les Forêts Aléatoires offrent deux outils d’analyse fantastiques.
5.1 L’Erreur Out-of-Bag (OOB)
Grâce au bootstrap, chaque arbre est entraîné sur une partie seulement des données. Les données non utilisées (~36.8%) sont appelées “Out-of-Bag”. On peut utiliser ces données OOB comme un jeu de validation “gratuit” pour chaque arbre. L’erreur OOB est l’erreur moyenne de prédiction sur les échantillons OOB. C’est une estimation très fiable et non biaisée de la performance du modèle sur de nouvelles données, sans avoir besoin de recourir à une validation croisée coûteuse en calculs.
5.2 L’Importance des Variables (Feature Importance)
Comment savoir quelles variables sont les plus influentes dans notre “boîte noire” ? La méthode la plus courante est la Réduction Moyenne d’Impureté (Mean Decrease in Impurity).
Le principe : Chaque fois qu’une variable est utilisée pour diviser un nœud dans un arbre, elle réduit l’impureté (ex: l’indice de Gini) de ce nœud. Une bonne variable conduit à une forte réduction de l’impureté.
Le calcul : Pour chaque variable, on calcule la réduction totale d’impureté qu’elle a apportée sur tous les arbres de la forêt.
L’interprétation : Plus le score d’importance est élevé, plus la variable a été déterminante dans les décisions du modèle.
Une alternative plus robuste (mais plus coûteuse) est l’Importance par Permutation, qui consiste à mélanger aléatoirement les valeurs d’une variable et à mesurer à quel point la performance du modèle se dégrade. Si la performance chute drastiquement, la variable est importante.
5.3 Atelier Pratique : Importance des Variables sur les Données California Housing
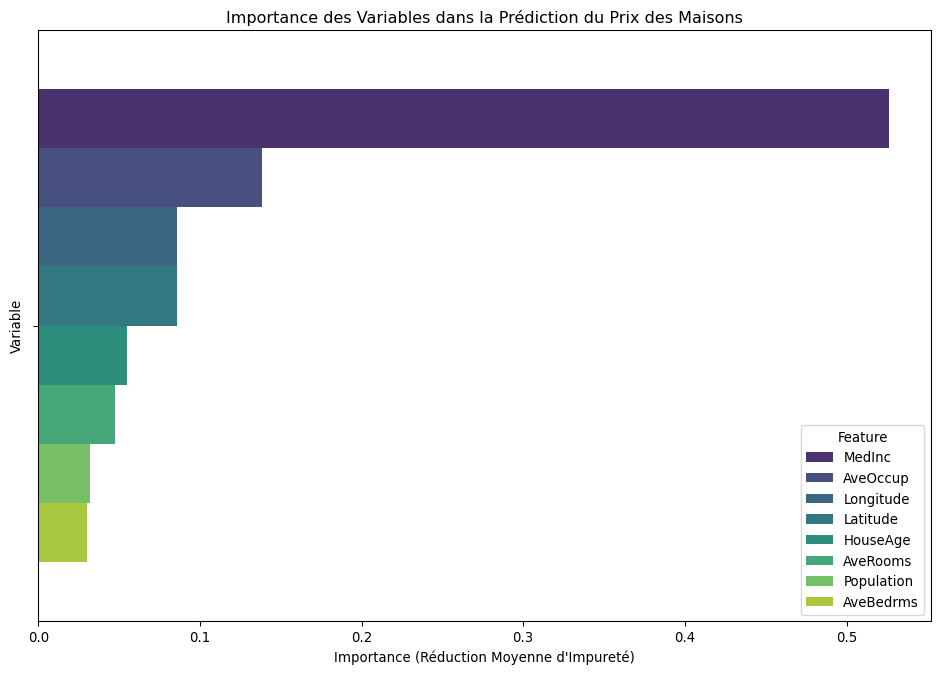
Reprenons notre modèle de Forêt Aléatoire entraîné sur les données California Housing et voyons quelles variables il a jugées les plus importantes pour prédire le prix des maisons.
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# On utilise le modèle rf_reg et les données housing déjà chargés et entraînés# 1. Extraire les importances et les noms des variablesimportances = rf_reg.feature_importances_feature_names = housing.feature_names# 2. Créer un DataFrame pour une meilleure lisibilitéfeature_importance_df = pd.DataFrame({'Feature': feature_names,'Importance': importances}).sort_values(by='Importance', ascending=False)print("--- Importance des Variables selon la Forêt Aléatoire ---")print(feature_importance_df)# 3. Visualiser les importancesplt.figure(figsize=(12, 8))sns.barplot(x='Importance', hue='Feature', data=feature_importance_df, palette='viridis')plt.title('Importance des Variables dans la Prédiction du Prix des Maisons')plt.xlabel('Importance (Réduction Moyenne d\'Impureté)')plt.ylabel('Variable')plt.show()
--- Importance des Variables selon la Forêt Aléatoire ---
Feature Importance
0 MedInc 0.526011
5 AveOccup 0.138220
7 Longitude 0.086124
6 Latitude 0.086086
1 HouseAge 0.054654
2 AveRooms 0.047188
4 Population 0.031722
3 AveBedrms 0.029995
Analyse des résultats
Le graphique confirme de manière très claire que le revenu médian (MedInc) est de loin la variable la plus importante pour prédire la valeur d’une maison. Cela a un sens intuitif fort.
Ensuite, des caractéristiques géographiques et de densité comme le nombre moyen d’occupants (AveOccup), la latitude et la longitude jouent un rôle significatif. L’âge de la maison (HouseAge) est également un facteur non négligeable.
Cet outil ne nous dit pas comment une variable influence le prix (par exemple, si un revenu plus élevé augmente le prix), mais il quantifie l’importance de chaque variable dans le processus de décision global du modèle. C’est une première étape cruciale pour interpréter un modèle “boîte noire”.
6 Conclusion
La Forêt Aléatoire n’est pas juste un Bagging d’arbres. C’est une évolution intelligente qui utilise une double source de hasard (sur les données et sur les variables) pour créer un ensemble de modèles experts diversifiés et décorrélés. Le résultat est l’un des algorithmes les plus polyvalents et performants du Machine Learning, offrant un excellent équilibre entre performance, robustesse et interprétabilité.
Dans notre prochain article, nous changerons de philosophie pour explorer le monde du Boosting, où les modèles ne travaillent plus en parallèle, mais en séquence pour apprendre de leurs erreurs.
7 Exercices
Exercise 1
Question 1
Quel est l’objectif principal de la technique de Bagging ?
Question 2
À quoi correspond l’étape “Bootstrap” dans le Bagging (Bootstrap Aggregating) ?
Question 3
Quelle est la principale différence entre une Forêt Aléatoire et un Bagging standard d’arbres de décision ?
Question 4
Quel est le principal avantage de la sélection aléatoire de variables à chaque division dans une Forêt Aléatoire ?
Question 5
Comment une Forêt Aléatoire fait-elle une prédiction pour un problème de régression ?
Question 6
Qu’est-ce que l’erreur Out-of-Bag (OOB) dans une Forêt Aléatoire ?
Question 7
Un score d’importance élevé pour une variable dans une Forêt Aléatoire signifie généralement que :
Question 8
Si un jeu de données contient quelques variables très prédictives, quelle méthode est la plus susceptible de souffrir de la corrélation entre ses arbres ?
Question 9
Quel est un inconvénient majeur des Forêts Aléatoires par rapport à un unique Arbre de Décision ?
Question 10
En moyenne, quel pourcentage d’observations uniques de l’ensemble d’entraînement original est contenu dans un seul échantillon bootstrap ?
Question 11
Pourquoi les Forêts Aléatoires sont-elles considérées comme robustes face au surapprentissage ?
Question 12
Quelle est la principale métrique utilisée pour calculer l’importance des variables dans Scikit-learn pour les Forêts Aléatoires ?
Question 13
Si vous avez un problème de classification avec 100 variables (p=100), combien de variables sont typiquement considérées à chaque division dans une Forêt Aléatoire ?
Question 14
Quel est l’avantage de l’erreur OOB par rapport à la validation croisée traditionnelle pour évaluer une Forêt Aléatoire ?
Question 15
Le Bagging est une méthode ensembliste qui vise principalement à réduire :
Question 16
Dans le contexte des Forêts Aléatoires, que signifie “décorréler les arbres” ?
Question 17
Quelle est la principale différence entre le Bagging et le Boosting en termes de construction des modèles ?
Question 18
Les Forêts Aléatoires sont-elles adaptées aux problèmes de régression ?
Question 19
Quel est l’impact de l’augmentation du nombre d’estimateurs (n_estimators) dans une Forêt Aléatoire ?
Question 20
Pourquoi les Forêts Aléatoires sont-elles souvent un bon point de départ pour de nombreux problèmes de Machine Learning ?