L’Analyse Discriminante Linéaire (LDA) : Réduire pour Mieux Classifier
Machine Learning
Réduction de Dimensionnalité
Classification
Statistiques
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Quand les Étiquettes Entrent en Jeu
Dans notre dernier article sur le PCA, nous avons découvert une technique puissante pour réduire la dimension en trouvant les axes de plus grande variance. Cependant, le PCA est non supervisé : il ignore les étiquettes de classe. Il se contente de trouver la structure de la variance, que cette structure soit utile ou non pour séparer les classes.
Mais si notre objectif est de préparer le terrain pour un modèle de classification ? Ne serait-il pas plus judicieux de trouver une projection qui maximise la séparation entre les classes ?
C’est précisément la mission de l’Analyse Discriminante Linéaire (LDA). C’est une technique de réduction de dimensionnalité supervisée qui utilise les informations des étiquettes pour trouver les axes les plus “discriminants”.
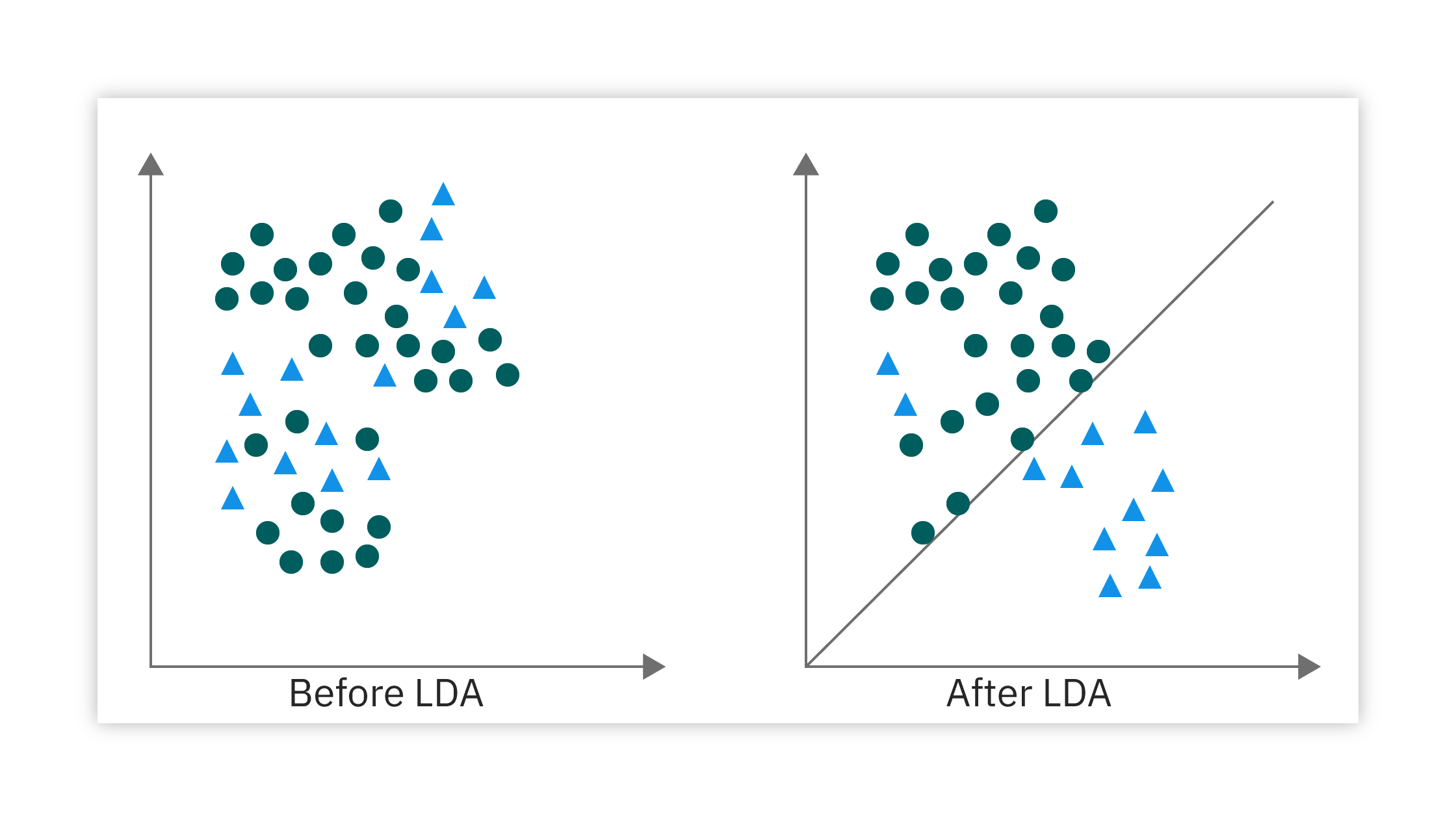
2 La Différence Fondamentale : PCA vs. LDA
PCA vs LDA
Pour résumer la différence fondamentale d’objectif :
PCA : Maximise la variance totale des données projetées.
LDA : Maximise la séparabilité des classes projetées.
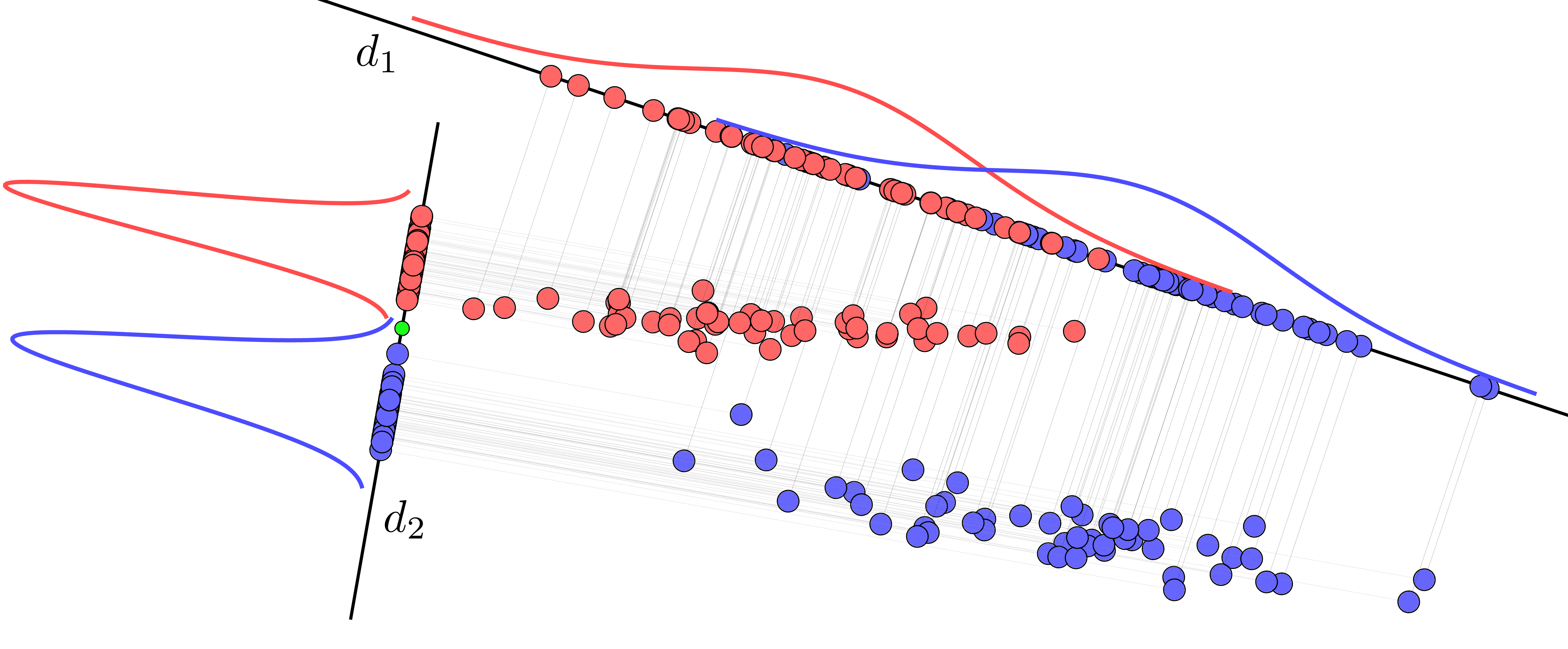
3 Formalisation Mathématique de l’LDA 📐
L’intuition du LDA est de maximiser le ratio de la variance inter-classes (la séparation entre les classes) sur la variance intra-classe (la compacité à l’intérieur de chaque classe). Formalisons cela.
Soit un jeu de données avec \(K\) classes. Pour chaque observation \(x_i\), on note sa classe \(c_i \in \{1, \dots, K\}\).
Définir la Dispersion : Les Matrices de “Scatter”
Nous avons besoin de deux mesures pour quantifier la dispersion :
La Matrice de Dispersion Intra-classe (\(S_W\)) : Elle mesure à quel point les points sont dispersés à l’intérieur de leur propre classe. C’est la somme des matrices de covariance de chaque classe. Un \(S_W\) “petit” signifie que les classes sont compactes. \[ S_W = \sum_{k=1}^{K} \sum_{i \in C_k} (x_i - \mu_k)(x_i - \mu_k)^T \] où \(\mu_k\) est le vecteur moyen de la classe \(k\).
La Matrice de Dispersion Inter-classes (\(S_B\)) : Elle mesure à quel point les centres des différentes classes sont éloignés les uns des autres. Un \(S_B\) “grand” signifie que les classes sont bien séparées. \[ S_B = \sum_{k=1}^{K} n_k (\mu_k - \mu)(\mu_k - \mu)^T \] où \(n_k\) est le nombre d’observations dans la classe \(k\) et \(\mu\) est le vecteur moyen global de toutes les données.
Le Critère de Fisher : Le Ratio à Maximiser
Le LDA cherche une direction de projection (un vecteur \(w\)) qui maximise le critère de Fisher. Ce critère est simplement le ratio des dispersions projetées : \[ J(w) = \frac{\text{Variance Inter-classe Projetée}}{\text{Variance Intra-classe Projetée}} = \frac{w^T S_B w}{w^T S_W w} \]
3. La Solution : Transformer le Problème LDA en Problème PCA
Maximiser ce ratio est un problème d’optimisation connu sous le nom de problème de valeurs propres généralisées. La solution \(w\) se trouve en résolvant : \[ S_B w = \lambda S_W w \] Si la matrice \(S_W\) est inversible, on peut réécrire l’équation comme : \[ S_W^{-1} S_B w = \lambda w \]
Les directions discriminantes optimales (les axes du LDA) sont les vecteurs propres de la matrice \(S_W^{-1} S_B\).
Voici le lien avec le PCA : Le problème peut être résolu en deux étapes :
“Blanchir” la variance intra-classe : On applique une transformation linéaire aux données de sorte que la matrice de dispersion intra-classe \(S_W\) devienne une matrice identité. Cela a pour effet de rendre les nuages de points de chaque classe sphériques et de même taille.
Appliquer un PCA sur les moyennes des classes : Une fois que les nuages de points sont sphériques, le seul moyen de maximiser la séparation entre eux est de trouver les axes de plus grande variance des centres de ces classes. Et trouver les axes de plus grande variance, c’est précisément le but du PCA !
En résumé, le problème LDA sur les données originales est équivalent à un problème PCA sur les moyennes des classes après avoir annulé la structure de covariance intra-classe. C’est une connexion mathématique profonde entre les deux méthodes.
4 Cas d’Usage et Limites
Cas d’Usage Principal : Le LDA est surtout utilisé comme une technique de pré-traitement avant un modèle de classification pour améliorer les performances et combattre la malédiction de la dimensionnalité.
Limite sur le Nombre de Composantes : Le nombre de composantes que le LDA peut extraire est au maximum de \(K-1\), où \(K\) est le nombre de classes. Cela vient du fait que la matrice \(S_B\) a au plus un rang de \(K-1\) (on ne peut pas définir plus de \(K-1\) dimensions avec \(K\) points, les centres des classes).
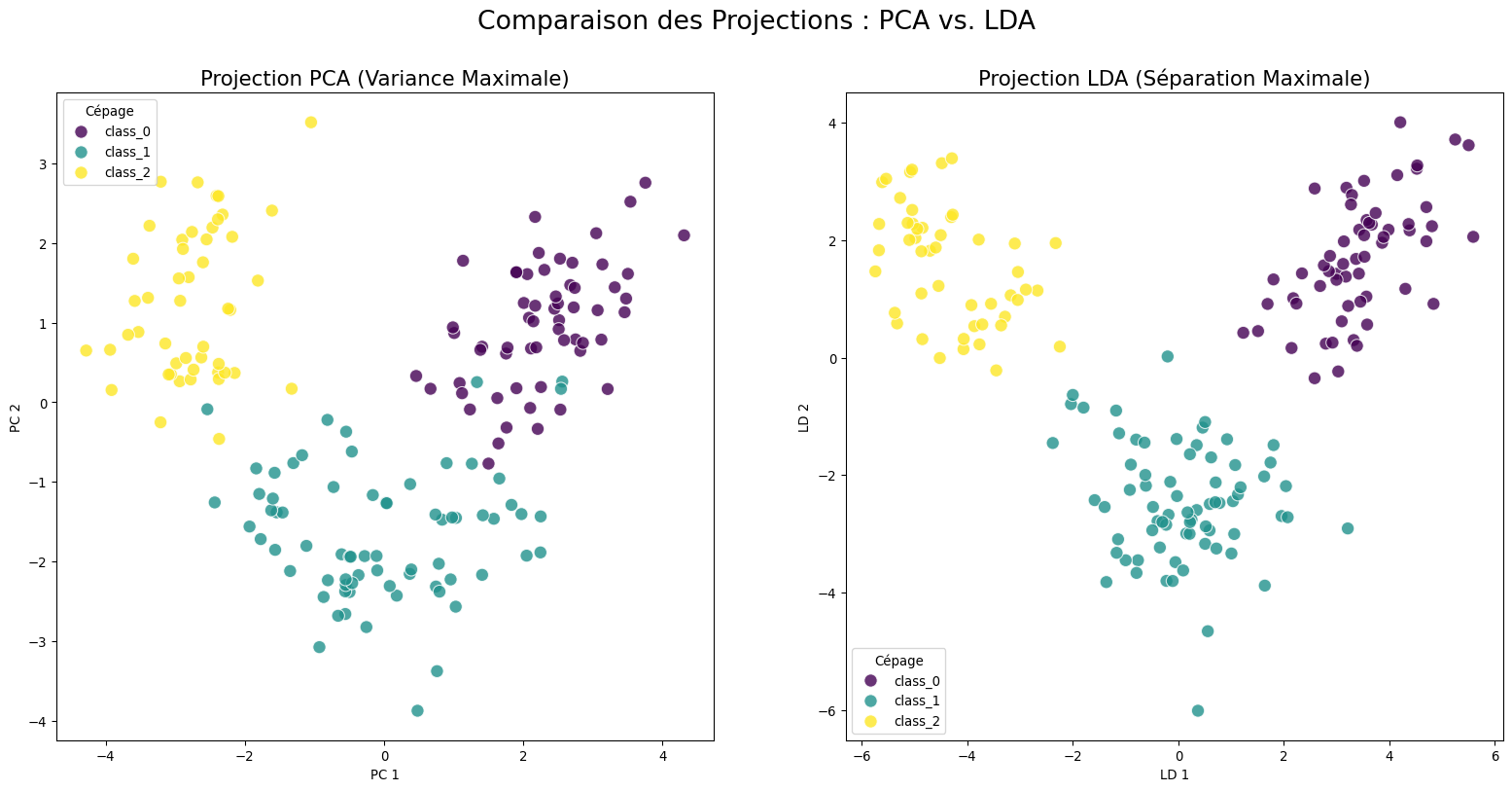
5 Atelier Pratique : PCA vs. LDA sur les Vins
Utilisons le jeu de données wine (3 classes) pour comparer la capacité de séparation du PCA et du LDA.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import load_winefrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis# 1. Charger les donnéeswine = load_wine()X, y = wine.data, wine.targettarget_names = wine.target_names# 2. Mettre les données à l'échellescaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 3. Appliquer le PCA (non supervisé)pca = PCA(n_components=2)X_pca = pca.fit_transform(X_scaled)# 4. Appliquer le LDA (supervisé)lda = LinearDiscriminantAnalysis(n_components=2)X_lda = lda.fit_transform(X_scaled, y) # On passe y ici !# 5. Visualisation Comparativefig, axes = plt.subplots(1, 2, figsize=(20, 9))fig.suptitle('Comparaison des Projections : PCA vs. LDA', fontsize=20)sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=y, palette='viridis', s=100, alpha=0.8, ax=axes[0])axes[0].set_title('Projection PCA (Variance Maximale)', fontsize=16)axes[0].set_xlabel('PC 1')axes[0].set_ylabel('PC 2')handles, _ = axes[0].get_legend_handles_labels()axes[0].legend(handles, target_names, title='Cépage')sns.scatterplot(x=X_lda[:, 0], y=X_lda[:, 1], hue=y, palette='viridis', s=100, alpha=0.8, ax=axes[1])axes[1].set_title('Projection LDA (Séparation Maximale)', fontsize=16)axes[1].set_xlabel('LD 1')axes[1].set_ylabel('LD 2')handles, _ = axes[1].get_legend_handles_labels()axes[1].legend(handles, target_names, title='Cépage')plt.show()
Interprétation des Résultats
Le résultat est sans appel. Tandis que la projection PCA laisse un chevauchement significatif entre les classes, la projection LDA produit une séparation quasi-parfaite. Le LDA, en maximisant le critère de Fisher, a trouvé l’angle de vue optimal non pas pour voir la “forme” générale des données, mais bien pour distinguer les groupes.
6 Conclusion
L’Analyse Discriminante Linéaire est un outil puissant, surtout si votre objectif final est la classification.
Choisissez le PCA pour l’exploration non supervisée ou la compression générale.
Choisissez le LDA pour maximiser la séparabilité des classes, souvent en pré-traitement pour améliorer un classifieur.
Et maintenant ?
Le PCA et le LDA sont des méthodes linéaires. Elles projettent les données sur des lignes ou des plans. Mais que faire si la structure de vos données est beaucoup plus complexe, comme des rubans enroulés ou des clusters imbriqués ? Pour visualiser ces structures, nous avons besoin d’outils plus sophistiqués. Dans notre prochain article, nous plongerons dans le monde fascinant de la réduction de dimensionnalité non-linéaire avec t-SNE et UMAP.
7 Exercices
Exercise 1
Question 1
Quel est l’objectif principal de l’Analyse Discriminante Linéaire (LDA) ?
Question 2
Comment le LDA se différencie-t-il fondamentalement du PCA ?
Question 3
Quel ratio le LDA cherche-t-il à maximiser pour trouver les meilleurs axes de projection ?
Question 4
Dans le contexte du LDA, que signifie “minimiser la variance intra-classe” ?
Question 5
Si vous appliquez le LDA à un problème de classification avec 5 classes (K=5), quel est le nombre maximum de composantes (discriminants linéaires) que vous pouvez extraire ?
Question 6
Dans l’atelier pratique, pourquoi le LDA a-t-il fourni une meilleure séparation des cépages que le PCA ?
Question 7
Le LDA est principalement utilisé comme…
Question 8
Quelle est la principale information que le LDA utilise et que le PCA ignore ?
Question 9
Le LDA et le PCA sont tous deux des méthodes de réduction de dimensionnalité…
Question 10
Que mesure la “variance inter-classes” (between-class variance) ?
Question 11
Quelle est la principale limitation du LDA concernant le nombre de composantes qu’il peut extraire ?
Question 12
Si vous avez un problème de classification binaire (2 classes), combien de composantes le LDA peut-il extraire au maximum ?
Question 13
Dans quel scénario le LDA serait-il généralement préféré au PCA ?
Question 14
La matrice de dispersion intra-classe (\(S_W\)) mesure :
Question 15
Le LDA est-il sensible aux données déséquilibrées (classes avec un nombre très différent d’observations) ?
Question 16
Quel est le rôle de la matrice \(S_W^{-1} S_B\) dans la résolution du problème LDA ?
Question 17
Le LDA suppose que les données suivent une distribution normale et que les matrices de covariance des classes sont :
Question 18
Si les classes sont intrinsèquement non-linéairement séparables, le LDA :
Question 19
Dans le contexte du LDA, qu’est-ce que le “blanchiment” de la variance intra-classe ?
Question 20
Le LDA est-il sensible aux valeurs aberrantes (outliers) ?