Découvrir l’Analyse Sémantique Latente (LSA) pour la réduction de dimensionnalité et l’exploration de thèmes dans les données textuelles.
SVD
Apprentissage Non-Supervisé
LSA
Authors
Affiliation
Wilson Toussile12
ENSPY
1ENSPY, 2ESSFAR
Published
May 24, 2025
1 Introduction à l’Analyse Sémantique Latente (LSA)
L’Analyse Sémantique Latente (LSA), également connue sous le nom d’Indexation Sémantique Latente (LSI) lorsqu’elle est appliquée à la recherche d’information, est une technique de traitement du langage naturel qui analyse les relations entre un ensemble de documents et les termes qu’ils contiennent. Elle permet de découvrir des structures sémantiques “latentes”, c’est-à-dire cachées ou non explicites, dans les données textuelles.
1.1 Qu’est-ce que LSA ?
Fondamentalement, LSA est une méthode qui utilise une approche statistique pour modéliser les relations entre les mots et les documents. Elle part du principe que les mots qui apparaissent dans des contextes similaires ont tendance à avoir des significations similaires. L’idée centrale est de représenter les termes et les documents dans un espace vectoriel de dimension réduite, appelé “espace sémantique latent”.
Les objectifs principaux de LSA sont :
Découvrir des relations sémantiques cachées : LSA peut identifier des relations entre des termes qui ne co-occurrent pas directement dans les mêmes documents, mais qui sont liés par leur co-occurrence avec d’autres termes. Par exemple, si “voiture” apparaît souvent avec “moteur” et “pneu”, et “automobile” apparaît aussi souvent avec “moteur” et “pneu”, LSA peut inférer que “voiture” et “automobile” sont sémantiquement proches, même s’ils n’apparaissent jamais ensemble.
Réduire la dimensionnalité : Les données textuelles sont souvent de très haute dimension (chaque mot unique peut être une dimension). LSA réduit cette dimensionnalité en projetant les données dans un espace de plus petite taille, tout en essayant de préserver au maximum l’information sémantique pertinente. Cela permet de simplifier les analyses ultérieures et de réduire le bruit.
1.2 Pourquoi utiliser LSA ?
LSA offre plusieurs avantages pour l’analyse de texte :
Gestion de la synonymie et de la polysémie (dans une certaine mesure) :
Synonymie : En regroupant les termes qui apparaissent dans des contextes similaires, LSA peut aider à traiter la synonymie (différents mots ayant la même signification). Par exemple, “ordinateur” et “PC” pourraient être mappés sur des dimensions sémantiques similaires.
Polysémie : LSA peut également aider (bien que de manière moins directe que des modèles plus avancés) à distinguer les différents sens d’un mot polysémique en fonction des contextes dans lesquels il apparaît. La représentation d’un mot sera une moyenne de ses différents sens pondérée par leur fréquence dans le corpus.
Amélioration de la recherche d’information (Latent Semantic Indexing - LSI) : LSI utilise LSA pour améliorer la pertinence des résultats de recherche. Au lieu de chercher des correspondances exactes de mots-clés, LSI recherche des documents qui sont sémantiquement proches de la requête, même s’ils n’utilisent pas les mêmes termes.
Découverte de “thèmes” ou “concepts” latents dans un corpus : Les dimensions de l’espace sémantique latent peuvent souvent être interprétées comme des “thèmes” ou des “concepts” abstraits qui parcourent le corpus. Par exemple, une dimension pourrait représenter le concept de “sport”, une autre celui de “politique”, etc.
1.3 Le rôle central de la Décomposition en Valeurs Singulières (SVD)
La pierre angulaire mathématique de LSA est la Décomposition en Valeurs Singulières (SVD). La SVD est une technique d’algèbre linéaire qui permet de décomposer une matrice (dans notre cas, une matrice termes-documents) en trois autres matrices. Cette décomposition est cruciale car elle permet d’identifier les dimensions les plus importantes de la variabilité des données et de réaliser la réduction de dimensionnalité en ne conservant que ces dimensions principales. Nous explorerons plus en détail la SVD dans la section suivante.
2 Les Étapes Clés de LSA
L’application de l’Analyse Sémantique Latente se déroule typiquement en trois grandes étapes :
2.1 Construction de la Matrice Termes-Documents (TDM)
La première étape consiste à transformer notre corpus de textes bruts en une représentation numérique structurée. Cette représentation est une matrice où les lignes correspondent aux termes (mots) uniques du corpus et les colonnes aux documents. Chaque cellule \((i, j)\) de cette matrice contient un poids qui indique l’importance du terme \(i\) dans le document \(j\).
Prétraitement du texte : Avant de construire la matrice, les textes subissent plusieurs étapes de nettoyage et de normalisation :
Tokenisation : Segmentation du texte en unités de base (généralement des mots).
Nettoyage : Suppression de la ponctuation, des caractères spéciaux, conversion en minuscules.
Suppression des mots vides (Stop Words) : Élimination des mots très fréquents et peu informatifs (ex: “le”, “la”, “de”, “est”).
Lemmatisation ou Racinisation (Stemming) : Réduction des mots à leur forme de base (lemme) ou à leur racine. Par exemple, “mange”, “mangeons”, “mangeront” pourraient être réduits à “manger” (lemme) ou “mang” (racine). Cela permet de regrouper des mots sémantiquement similaires.
Choix de la pondération : Une fois les termes extraits, il faut leur assigner un poids dans chaque document. Les schémas de pondération courants incluent :
Fréquence des termes (TF - Term Frequency) : Simplement le nombre d’occurrences d’un terme dans un document. L’idée est que plus un mot apparaît souvent dans un document, plus il est important pour ce document.
TF-IDF (Term Frequency-Inverse Document Frequency) : C’est la pondération la plus couramment utilisée. Elle combine la fréquence du terme (TF) avec la fréquence documentaire inverse (IDF). L’IDF mesure la rareté d’un terme dans l’ensemble du corpus. Les termes qui apparaissent dans de nombreux documents ont un IDF faible (et donc un poids TF-IDF plus faible), tandis que les termes rares ont un IDF élevé. TF-IDF donne ainsi plus de poids aux termes qui sont fréquents dans un document particulier mais rares dans l’ensemble du corpus, les considérant comme plus discriminants.
Le résultat est une grande matrice, souvent creuse (contenant beaucoup de zéros), qui sert d’entrée à l’étape suivante.
2.2 Application de la Décomposition en Valeurs Singulières (SVD)
Une fois la matrice termes-documents \(A\) (de dimensions \(m \times n\), où \(m\) est le nombre de termes et \(n\) le nombre de documents) construite, on lui applique la Décomposition en Valeurs Singulières (SVD). La SVD décompose la matrice \(A\) en produit de trois autres matrices :
\[A = U \Sigma V^T\]
Où : * \(U\) est une matrice orthogonale \(m \times r\) dont les colonnes sont les vecteurs singuliers gauches. Chaque ligne de \(U\) peut être vue comme la représentation d’un terme dans un espace de “concepts” latents. * \(\Sigma\) (Sigma) est une matrice diagonale \(r \times r\) contenant les valeurs singulières \(\sigma_1, \sigma_2, ..., \sigma_r\) sur sa diagonale, triées par ordre décroissant (\(\sigma_1 \ge \sigma_2 \ge ... \ge \sigma_r \ge 0\)). Ces valeurs singulières représentent “l’énergie” ou l’importance de chaque dimension (concept) latente. \(r\) est le rang de la matrice \(A\). * \(V^T\) (V transposée) est une matrice orthogonale \(r \times n\) dont les lignes sont les vecteurs singuliers droits (les colonnes de \(V\) sont les vecteurs singuliers droits). Chaque colonne de \(V^T\) (ou ligne de \(V\)) peut être vue comme la représentation d’un document dans ce même espace de “concepts” latents.
La SVD trouve les directions de plus grande variance dans les données (similaire à l’ACP, Analyse en Composantes Principales, dont elle est une généralisation).
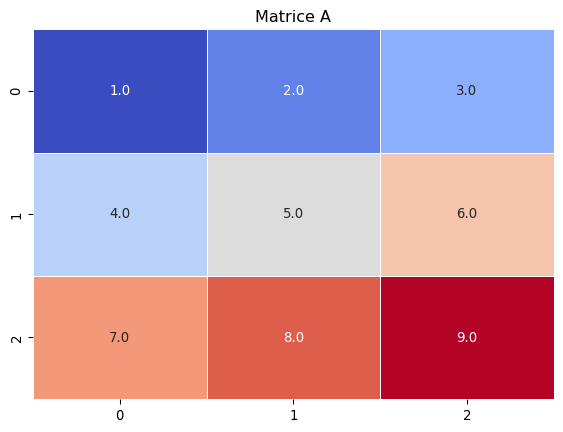
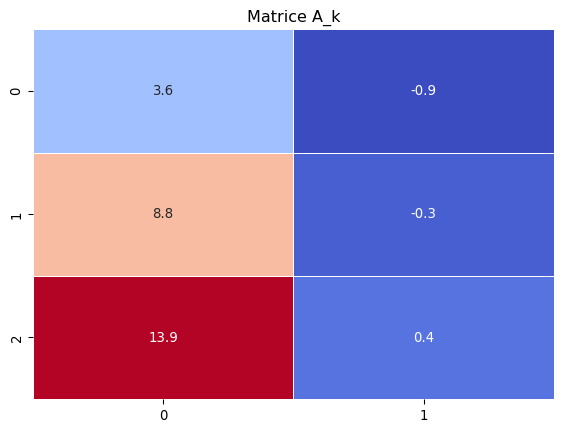
Exemple de SVD avec Code
Code
# Librairiesimport numpy as npfrom sklearn.decomposition import TruncatedSVD# MatriceA = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# SVDsvd = TruncatedSVD(n_components=2)A_k = svd.fit_transform(A)# Heatmap de A et A_kimport seaborn as snsimport matplotlib.pyplot as pltsns.heatmap(A, annot=True, cmap='coolwarm', fmt='.1f', linewidths=0.5, cbar=False)plt.title('Matrice A')plt.show()sns.heatmap(A_k, annot=True, cmap='coolwarm', fmt='.1f', linewidths=0.5, cbar=False)plt.title('Matrice A_k')plt.show()
2.3 Réduction de Dimensionnalité
L’étape cruciale de LSA est la réduction de dimensionnalité. Au lieu d’utiliser la SVD complète, on ne conserve que les \(k\) premières valeurs singulières les plus importantes (celles qui ont la plus grande magnitude) et les \(k\) premiers vecteurs correspondants dans \(U\) et \(V\). Ce nombre \(k\) est un hyperparamètre à choisir (typiquement entre 100 et 500, mais cela dépend fortement du corpus).
On obtient ainsi une approximation de la matrice originale, \(A_k\), de rang \(k\) :
\[A_k = U_k \Sigma_k V_k^T\]
Où \(U_k\) est \(m \times k\), \(\Sigma_k\) est \(k \times k\), et \(V_k^T\) est \(k \times n\).
L’espace sémantique latent : Les matrices \(U_k\) et \(V_k\) (ou \(V_k^T\)) définissent ce nouvel espace de dimension \(k\). Chaque terme est maintenant représenté par un vecteur de \(k\) dimensions (une ligne de \(U_k\)) et chaque document par un vecteur de \(k\) dimensions (une colonne de \(V_k^T\)). C’est dans cet “espace sémantique latent” que les relations sémantiques cachées sont supposées émerger. Les termes et documents ayant des profils similaires dans cet espace de \(k\) dimensions sont considérés comme sémantiquement proches.
3 Interprétation des Résultats de LSA
Une fois la SVD appliquée et la dimensionnalité réduite, nous obtenons de nouvelles représentations pour nos termes et documents. L’interprétation de ces résultats est une étape clé pour comprendre ce que LSA a appris du corpus.
3.1 Comment interpréter les “concepts” ou “thèmes” latents ?
Chacune des \(k\) dimensions conservées après la SVD peut être vue comme un “concept” ou un “thème” latent qui traverse le corpus. L’interprétation de ces concepts n’est pas toujours directe et peut nécessiter une analyse humaine. Voici quelques approches :
Examiner les termes les plus influents pour chaque concept : Pour un concept donné (une colonne de \(U_k\) ou une ligne de \(U_k^T\), selon la convention), on peut identifier les termes qui ont les poids (valeurs absolues) les plus élevés sur cette dimension. Ces termes donnent une indication du sujet ou de l’idée que ce concept représente. Par exemple, si un concept a des poids élevés pour les mots “ballon”, “but”, “équipe”, “match”, on pourrait l’interpréter comme le concept du “football”.
Examiner les documents les plus représentatifs de chaque concept : De même, pour un concept donné (une colonne de \(V_k\) ou une ligne de \(V_k^T\)), on peut identifier les documents qui ont les scores les plus élevés sur cette dimension. Lire ces documents peut aider à comprendre la nature du concept.
Visualisation : Si \(k\) est petit (par exemple 2 ou 3), on peut visualiser les termes et les documents dans cet espace. Cependant, \(k\) est souvent bien plus grand, rendant la visualisation directe difficile. Des techniques de réduction de dimensionnalité supplémentaires (comme t-SNE ou UMAP) peuvent être appliquées aux vecteurs de termes ou de documents de l’espace LSA pour une visualisation en 2D ou 3D.
Il est important de noter que les concepts latents sont des constructions mathématiques et ne correspondent pas toujours à des thèmes humains intuitifs et bien définis. Parfois, un concept peut être un mélange de plusieurs idées ou difficile à nommer.
3.2 Représentation des termes et des documents dans l’espace sémantique réduit
Après la réduction de dimensionnalité, chaque terme est représenté par un vecteur de \(k\) dimensions (une ligne de la matrice \(U_k \Sigma_k^{1/2}\) ou simplement \(U_k\), selon les implémentations) et chaque document est également représenté par un vecteur de \(k\) dimensions (une ligne de la matrice \(V_k \Sigma_k^{1/2}\) ou une colonne de \(V_k^T \Sigma_k^{1/2}\), ou simplement \(V_k\)).
Ces vecteurs capturent la “position” sémantique du terme ou du document dans l’espace latent de \(k\) dimensions. Les termes ayant des significations similaires ou apparaissant dans des contextes similaires auront tendance à avoir des vecteurs proches dans cet espace. De même, les documents traitant de sujets similaires auront des représentations vectorielles proches.
3.3 Calcul de similarité entre documents ou entre termes dans cet espace
L’un des grands avantages de LSA est la capacité de calculer la similarité sémantique entre des paires de termes, des paires de documents, ou même entre un terme et un document. La similarité la plus couramment utilisée dans cet espace vectoriel est la similarité cosinus. Elle mesure le cosinus de l’angle entre deux vecteurs non nuls. Une similarité cosinus de 1 signifie que les vecteurs pointent dans la même direction (très similaires), 0 signifie qu’ils sont orthogonaux (pas de similarité), et -1 qu’ils pointent dans des directions opposées.
Pour deux vecteurs \(A\) et \(B\) (par exemple, les représentations LSA de deux termes ou de deux documents), la similarité cosinus est calculée comme suit :
Où \(k\) est la dimensionnalité de l’espace sémantique latent, \(A_i\) et \(B_i\) sont les composantes des vecteurs \(A\) et \(B\).
Similarité entre termes : En calculant la similarité cosinus entre les vecteurs de deux termes (par exemple, les lignes correspondantes de \(U_k\)), on peut quantifier leur proximité sémantique. Des termes avec une similarité cosinus élevée sont considérés comme sémantiquement plus proches.
Similarité entre documents : De même, la similarité cosinus entre les vecteurs de deux documents (par exemple, les colonnes correspondantes de \(V_k^T\) ou les lignes de \(V_k\)) indique à quel point ils traitent de sujets similaires. C’est la base de LSI pour la recherche d’information : une requête peut être transformée en un pseudo-document, projetée dans l’espace LSA, et les documents les plus similaires (score de similarité cosinus le plus élevé) sont retournés.
Similarité terme-document : On peut également calculer la similarité entre un terme et un document pour voir à quel point un document est pertinent pour un terme donné dans l’espace sémantique.
Ces mesures de similarité sont plus robustes que celles basées sur le simple comptage de mots partagés, car elles tiennent compte des relations sémantiques indirectes (synonymie, etc.) capturées par LSA.
4 Applications Pratiques de LSA
Grâce à sa capacité à modéliser les relations sémantiques et à réduire la dimensionnalité, LSA trouve son utilité dans diverses applications du traitement du langage naturel :
Recherche d’information et Indexation Sémantique Latente (LSI) : C’est l’application historique et l’une des plus connues de LSA. En projetant les documents et les requêtes dans le même espace sémantique latent, LSI permet de retrouver des documents pertinents même s’ils ne partagent pas exactement les mêmes mots-clés que la requête. Cela aide à surmonter les problèmes de synonymie (trouver des documents utilisant des synonymes des termes de la requête) et, dans une certaine mesure, de polysémie. Une requête est traitée comme un “mini-document”, projetée dans l’espace LSA, et les documents les plus proches (selon la similarité cosinus) sont retournés.
Classification et Clustering de Documents : Les représentations vectorielles des documents obtenues par LSA (les colonnes de \(V_k^T\) ou les lignes de \(V_k\)) peuvent servir d’entrée à des algorithmes de classification supervisée (si des étiquettes de catégories sont disponibles) ou de clustering non supervisé. En travaillant dans un espace de dimension réduite et sémantiquement plus riche, on peut souvent obtenir de meilleures performances et des regroupements plus cohérents que sur la base de la matrice termes-documents originale (par exemple, avec des vecteurs TF-IDF bruts).
Comparaison de Documents et Détection de Similarité : LSA fournit un cadre naturel pour mesurer la similarité sémantique entre des documents. En calculant la similarité cosinus entre leurs vecteurs dans l’espace latent, on peut quantifier à quel point deux documents traitent de sujets similaires. Cela est utile pour des tâches comme la détection de plagiat, la recommandation de documents similaires, ou l’organisation de grandes collections de textes.
Extraction de Thèmes (Topic Modeling) : Bien que des méthodes plus modernes et spécialisées comme LDA (Latent Dirichlet Allocation) soient souvent préférées pour une modélisation thématique fine, LSA peut être considérée comme une forme plus simple d’extraction de thèmes. Chaque dimension latente (concept) peut être interprétée comme un “thème” en examinant les termes et les documents qui y sont fortement associés. Cependant, l’interprétabilité des thèmes LSA peut être moins directe que celle des thèmes LDA.
Filtrage Collaboratif et Systèmes de Recommandation : Des variantes de LSA ont été appliquées dans le domaine des systèmes de recommandation. Par exemple, en construisant une matrice utilisateurs-items (au lieu de termes-documents), la SVD peut aider à découvrir des “profils latents” d’utilisateurs et d’items, permettant de prédire les préférences et de faire des recommandations.
Annotation Automatique d’Images (Cross-modal retrieval) : LSA a été étendue pour trouver des correspondances entre différents types de données, par exemple, entre du texte et des images. En créant un espace sémantique commun, on peut associer des mots-clés à des images ou retrouver des images à partir de descriptions textuelles.
5 Avantages et Limites de LSA
Avantages (capture des relations sémantiques, réduction du bruit).
Inconvénients (coût de calcul de la SVD, choix de \(k\), interprétabilité des concepts parfois difficile, aspects “bag-of-words”).
L’Indexation Sémantique Latente (LSI) exploite la puissance de LSA pour améliorer la recherche d’information. Plutôt que de se baser sur une simple correspondance de mots-clés, LSI vise à retrouver des documents qui sont sémantiquement pertinents par rapport à une requête, même s’ils n’utilisent pas exactement les mêmes termes. Le principe repose sur la projection des documents et des requêtes dans un même espace sémantique de dimension réduite.
6.1 Principe de le LSI
Matrice Termes-Documents et SVD : On commence avec une matrice termes-documents \(A\) de dimensions \(m \times n\), où \(m\) est le nombre de termes uniques et \(n\) le nombre de documents. Comme vu précédemment, LSA applique une Décomposition en Valeurs Singulières (SVD) tronquée pour obtenir une approximation de \(A\) de rang \(k\) (où \(k \ll \min(m,n)\)) : \[ A \approx A_k = U_k \Sigma_k V_k^T \] Où :
\(U_k\) est une matrice \(m \times k\) dont les colonnes sont les vecteurs singuliers gauches (associés aux termes). Chaque ligne de \(U_k\) peut être vue comme la représentation d’un terme dans l’espace latent de \(k\) dimensions.
\(\Sigma_k\) est une matrice diagonale \(k \times k\) contenant les \(k\) plus grandes valeurs singulières \(\sigma_1, \sigma_2, \dots, \sigma_k\).
\(V_k^T\) est une matrice \(k \times n\) dont les lignes sont les vecteurs singuliers droits (associés aux documents). Chaque colonne de \(V_k^T\) représente un document dans l’espace latent de \(k\) dimensions.
Représentation des Documents dans l’Espace Latent : Chaque document \(j\) du corpus original (correspondant à la \(j\)-ième colonne de la matrice \(A\)) est représenté par un vecteur dans l’espace sémantique latent de \(k\) dimensions. Ce vecteur, noté \(\mathbf{d'}_j\), est la \(j\)-ième colonne de la matrice \(V_k^T\): \[ \mathbf{d'}_j = (V_k^T)_{:,j} \in \mathbb{R}^k \] Certaines implémentations utilisent les colonnes de \(\Sigma_k V_k^T\) comme vecteurs documents, ce qui pondère les dimensions par leur importance. Pour simplifier, nous considérons ici les colonnes de \(V_k^T\).
Représentation d’une Requête dans l’Espace Latent (“Folding-in”) : Lorsqu’une nouvelle requête \(\mathbf{q}\) est formulée, elle est d’abord représentée comme un vecteur de \(m\) dimensions dans l’espace des termes (par exemple, un vecteur TF-IDF basé sur le vocabulaire du corpus). Ce vecteur \(\mathbf{q} \in \mathbb{R}^m\) est ensuite projeté dans l’espace sémantique latent de \(k\) dimensions. La représentation de la requête dans cet espace, notée \(\mathbf{\hat{q}}\), est calculée comme suit (formulation de Deerwester et al.) : \[\mathbf{\hat{q}} = \Sigma_k^{-1} U_k^T \mathbf{q} \in \mathbb{R}^k\] L’inversion de \(\Sigma_k\) pondère les composantes de la requête en fonction de l’importance des concepts latents. \(U_k^T \mathbf{q}\) projette la requête sur les axes des concepts définis par les termes.
Calcul de Similarité : Une fois la requête \(\mathbf{\hat{q}}\) et tous les documents \(\mathbf{d'}_j\) représentés dans le même espace latent de \(k\) dimensions, leur similarité est calculée. La mesure la plus courante est la similarité cosinus : \[\text{sim}(\mathbf{\hat{q}}, \mathbf{d'}_j) = \frac{\mathbf{\hat{q}} \cdot \mathbf{d'}_j}{\|\mathbf{\hat{q}}\| \|\mathbf{d'}_j\|} = \frac{\sum_{i=1}^{k} \hat{q}_i d'_{ji}}{\sqrt{\sum_{i=1}^{k} \hat{q}_i^2} \sqrt{\sum_{i=1}^{k} (d'_{ji})^2}}\] Où \(\hat{q}_i\) est la \(i\)-ème composante de \(\mathbf{\hat{q}}\) et \(d'_{ji}\) est la \(i\)-ème composante de \(\mathbf{d'}_j\).
Classement des Documents : Les documents du corpus sont classés en fonction de leur score de similarité avec la requête \(\mathbf{\hat{q}}\). Les documents ayant les scores les plus élevés sont considérés comme les plus pertinents sémantiquement et sont retournés à l’utilisateur.
En opérant dans cet espace sémantique latent, LSI peut identifier des relations de synonymie (des termes différents mais conceptuellement similaires contribuent à la similarité) et, dans une certaine mesure, de polysémie, améliorant ainsi la pertinence des résultats de recherche par rapport aux méthodes basées sur la correspondance exacte de mots-clés.
6.2 Exemple de LSI avec Code
Code
# Importations nécessairesimport numpy as npfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.decomposition import TruncatedSVDfrom sklearn.metrics.pairwise import cosine_similarityimport pandas as pd# 1. Corpus de documentsdocuments = ["Le chat dort sur le tapis.","Le chien joue dans le jardin avec une balle.","Les chats aiment le lait et les caresses.","Mon chien est un fidèle compagnon.","L'informatique quantique est un domaine fascinant.","La programmation en Python est très populaire pour l'analyse de données.","Les algorithmes d'apprentissage automatique révolutionnent la technologie."]# 2. Création de la matrice TF-IDFvectorizer = TfidfVectorizer(stop_words=['le', 'la', 'les', 'un', 'une', 'des', 'sur', 'dans', 'est', 'sont', 'et', 'pour'])tfidf_matrix = vectorizer.fit_transform(documents)terms = vectorizer.get_feature_names_out()# Affichage de la matrice TF-IDF (optionnel)# print("Matrice TF-IDF (termes x documents):")# print(pd.DataFrame(tfidf_matrix.toarray(), columns=terms, index=[f"Doc{i+1}" for i in range(len(documents))]))# 3. Application de LSA (SVD tronquée)n_components =2# Nombre de concepts latents (dimensions à conserver)svd_model = TruncatedSVD(n_components=n_components, random_state=42)# U_k * Sigma_k : Représentation des termes dans l'espace latent (non directement utilisé ici pour LSI)# lsa_term_topic_matrix = svd_model.fit_transform(tfidf_matrix.T) # Transposée car SVD de sklearn attend (n_samples, n_features)# V_k^T : Représentation des documents dans l'espace latent# fit_transform sur la matrice (documents x termes) donne U_k * Sigma_k (documents x concepts)lsa_doc_topic_matrix = svd_model.fit_transform(tfidf_matrix)# print(f"\nMatrice Documents-Concepts (LSA - {n_components} dimensions):")# print(pd.DataFrame(lsa_doc_topic_matrix, index=[f"Doc{i+1}" for i in range(len(documents))], columns=[f"Concept{j+1}" for j in range(n_components)]))# 4. Définition d'une requêtequery ="animal de compagnie affectueux"# 5. Transformation de la requête dans l'espace LSA ("folding-in")# D'abord, transformer la requête en vecteur TF-IDF en utilisant le vocabulaire apprisquery_tfidf_vector = vectorizer.transform([query])# Ensuite, projeter ce vecteur dans l'espace LSAquery_lsa_vector = svd_model.transform(query_tfidf_vector)# print(f"\nVecteur de la requête '{query}' dans l'espace LSA:")# print(query_lsa_vector)# 6. Calcul de la similarité cosinus entre la requête et les documents dans l'espace LSAsimilarities = cosine_similarity(query_lsa_vector, lsa_doc_topic_matrix)# 7. Classement des documentsranked_doc_indices = np.argsort(similarities[0])[::-1] # [0] car similarities est une matrice (1 x n_docs)print(f"\nDocuments les plus similaires à la requête '{query}' (basé sur LSI avec {n_components} concepts):")for i, doc_index inenumerate(ranked_doc_indices):print(f"Rang {i+1}: Document {doc_index+1} (Similarité: {similarities[0][doc_index]:.4f})")print(f" Texte: {documents[doc_index]}\n")# Note: Avec n_components=2, la distinction peut être grossière.# Augmenter n_components peut améliorer la finesse, mais aussi le coût et le risque de sur-apprentissage.
Documents les plus similaires à la requête 'animal de compagnie affectueux' (basé sur LSI avec 2 concepts):
Rang 1: Document 7 (Similarité: 1.0000)
Texte: Les algorithmes d'apprentissage automatique révolutionnent la technologie.
Rang 2: Document 6 (Similarité: 1.0000)
Texte: La programmation en Python est très populaire pour l'analyse de données.
Rang 3: Document 5 (Similarité: 1.0000)
Texte: L'informatique quantique est un domaine fascinant.
Rang 4: Document 2 (Similarité: 0.0000)
Texte: Le chien joue dans le jardin avec une balle.
Rang 5: Document 1 (Similarité: 0.0000)
Texte: Le chat dort sur le tapis.
Rang 6: Document 4 (Similarité: -0.0000)
Texte: Mon chien est un fidèle compagnon.
Rang 7: Document 3 (Similarité: -1.0000)
Texte: Les chats aiment le lait et les caresses.
7 Conclusion
Récapitulatif des points clés.
Quand envisager d’utiliser LSA.
8 Exercices
Exercise 1 (Application de LSI sur un Corpus Anglais) L’objectif de cet exercice est d’appliquer l’Indexation Sémantique Latente (LSI) à un petit corpus de documents en anglais pour trouver les documents les plus pertinents pour une requête donnée.
Corpus de Documents (Anglais) :
Code
corpus = ["Machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to 'learn' from data, without being explicitly programmed.","Supervised learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs.","Unsupervised learning is a type of machine learning that looks for previously undetected patterns in a data set with no pre-existing labels and with a minimum of human supervision.","Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to learn from data.","Reinforcement learning is an area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.","Common applications of machine learning include image recognition, speech recognition, and natural language processing.","Evaluating machine learning models often involves metrics like accuracy, precision, recall, and F1-score.","Data preprocessing is a crucial step in machine learning workflows, involving cleaning, transformation, and feature scaling.","Overfitting is a common problem in machine learning where a model learns the training data too well, including noise, and performs poorly on new data.","Libraries like scikit-learn, TensorFlow, and PyTorch are widely used for implementing machine learning algorithms.","Football, also known as soccer, is a team sport played with a spherical ball between two teams of 11 players.","The game is played on a rectangular field called a pitch, with a goal at each end.","The object of the game is to score by getting the ball into the opposing goal.","Goalkeepers are the only players allowed to touch the ball with their hands or arms in the area called the penalty area.","Outfield players typically use their feet to strike or pass the ball, but may also use their head or torso.","A standard football match consists of two halves of 45 minutes each, with a half-time interval.","The FIFA World Cup is the most prestigious association football tournament in the world.","Major football leagues include the Premier League, La Liga, Serie A, Bundesliga, and Ligue 1.","Famous football players include Lionel Messi, Cristiano Ronaldo, Pelé, and Diego Maradona.","Tactics in football involve formations, pressing, counter-attacking, and set pieces."]
Tâches :
Prétraitement et Vectorisation TF-IDF :
Utilisez TfidfVectorizer de sklearn.feature_extraction.text pour convertir le english_corpus en une matrice TF-IDF.
Pensez à exclure les stop words courants en anglais (par exemple, en utilisant le paramètre stop_words='english').
Affichez les termes (features) extraits par le vectoriseur.
Application de LSA (TruncatedSVD) :
Utilisez TruncatedSVD de sklearn.decomposition pour réduire la dimensionnalité de la matrice TF-IDF.
Choisissez un nombre de composantes (concepts latents), par exemple n_components = 2 ou n_components = 3 pour commencer.
Transformez la matrice TF-IDF en un espace LSA, obtenant ainsi une représentation des documents dans cet espace réduit.
Définition et Transformation d’une Requête :
Définissez une requête en anglais, par exemple : query = "machine learning applications" ou query = "animal behavior".
Transformez cette requête en un vecteur TF-IDF en utilisant le TfidfVectorizerentraîné sur le corpus.
Projetez ensuite ce vecteur TF-IDF de la requête dans l’espace LSA en utilisant le modèle TruncatedSVDentraîné.
Calcul de Similarité et Classement :
Calculez la similarité cosinus entre le vecteur LSA de la requête et les vecteurs LSA de chaque document du corpus.
Classez les documents par ordre décroissant de similarité.
Affichez les documents les plus pertinents pour la requête, avec leur score de similarité.
Analyse (Optionnel) :
Variez le nombre de n_components dans TruncatedSVD (par exemple, 1, 2, 3, 4) et observez comment cela affecte les résultats de la recherche pour différentes requêtes.
Essayez d’interpréter sommairement les “concepts” latents en examinant les composantes du modèle SVD (par exemple, svd_model.components_ qui représente la matrice \(V_k^T\) où les lignes sont les concepts et les colonnes les poids des termes pour ces concepts).
Squelette de Code (Python) :
Code
# Importations nécessairesimport numpy as npfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.decomposition import TruncatedSVDfrom sklearn.metrics.pairwise import cosine_similarityimport pandas as pd# 0. Corpus de Documents (Anglais)english_corpus = ["Machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to 'learn' from data, without being explicitly programmed.","Supervised learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs.","Unsupervised learning is a type of machine learning that looks for previously undetected patterns in a data set with no pre-existing labels and with a minimum of human supervision.","Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to learn from data.","Reinforcement learning is an area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.","Common applications of machine learning include image recognition, speech recognition, and natural language processing.","Evaluating machine learning models often involves metrics like accuracy, precision, recall, and F1-score.","Data preprocessing is a crucial step in machine learning workflows, involving cleaning, transformation, and feature scaling.","Overfitting is a common problem in machine learning where a model learns the training data too well, including noise, and performs poorly on new data.","Libraries like scikit-learn, TensorFlow, and PyTorch are widely used for implementing machine learning algorithms.","Football, also known as soccer, is a team sport played with a spherical ball between two teams of 11 players.","The game is played on a rectangular field called a pitch, with a goal at each end.","The object of the game is to score by getting the ball into the opposing goal.","Goalkeepers are the only players allowed to touch the ball with their hands or arms in the area called the penalty area.","Outfield players typically use their feet to strike or pass the ball, but may also use their head or torso.","A standard football match consists of two halves of 45 minutes each, with a half-time interval.","The FIFA World Cup is the most prestigious association football tournament in the world.","Major football leagues include the Premier League, La Liga, Serie A, Bundesliga, and Ligue 1.","Famous football players include Lionel Messi, Cristiano Ronaldo, Pelé, and Diego Maradona.","Tactics in football involve formations, pressing, counter-attacking, and set pieces."]document_names = [f"Doc{i+1}"for i inrange(len(english_corpus))]# 1. Prétraitement et Vectorisation TF-IDFprint("--- 1. TF-IDF Vectorization ---")vectorizer = TfidfVectorizer(stop_words='english')tfidf_matrix = vectorizer.fit_transform(english_corpus)terms = vectorizer.get_feature_names_out()# 2. Application de LSA (TruncatedSVD)n_components_lsa =2# Nombre de concepts latentssvd_model = TruncatedSVD(n_components=n_components_lsa, random_state=42)lsa_doc_topic_matrix = svd_model.fit_transform(tfidf_matrix)# 3. Définition et Transformation d'une Requêtequery ="machine learning applications"query_tfidf_vector = vectorizer.transform([query])query_lsa_vector = svd_model.transform(query_tfidf_vector)# 4. Calcul de Similarité et Classementsimilarities = cosine_similarity(query_lsa_vector, lsa_doc_topic_matrix)ranked_doc_indices = np.argsort(similarities[0])[::-1]print(f"\nDocuments les plus similaires à la requête '{query}' (basé sur LSI avec {n_components_lsa} concepts):")for i, doc_index inenumerate(ranked_doc_indices):print(f"Rang {i+1}: {document_names[doc_index]} (Similarité: {similarities[0][doc_index]:.4f}) - {english_corpus[doc_index]}")
3.1 Comment interpréter les “concepts” ou “thèmes” latents ?
Chacune des \(k\) dimensions conservées après la SVD peut être vue comme un “concept” ou un “thème” latent qui traverse le corpus. L’interprétation de ces concepts n’est pas toujours directe et peut nécessiter une analyse humaine. Voici quelques approches :
Il est important de noter que les concepts latents sont des constructions mathématiques et ne correspondent pas toujours à des thèmes humains intuitifs et bien définis. Parfois, un concept peut être un mélange de plusieurs idées ou difficile à nommer.