Code
require(reticulate)require(reticulate)Après avoir collecté, nettoyé et structuré notre corpus \(\mathcal{D}_n=\left\{d_i\right\}_{i=1}^n\) , l’étape suivante est de l’explorer. L’Analyse Exploratoire de Données (EDA - Exploratory Data Analysis) est un processus itératif qui vise à :
Pour les données textuelles, l’EDA combine des statistiques descriptives et des techniques de visualisation adaptées. Elle nous aide à “sentir” nos données avant de nous lancer dans des analyses plus complexes. (Bengfort et al., 2018, Chapter 4: Visualizing Text Corpora).
Ces statistiques nous donnent un aperçu quantitatif de notre corpus et de ses composantes.
Longueur des documents : Nombre de tokens par document.
import matplotlib.pyplot as plt
import nltk
from nltk.tokenize import word_tokenize
# Exemple de corpus (liste de chaînes de caractères)
corpus_texts = [
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec Python et NLTK.",
"Visualisation des longueurs de documents."
]
# Tokenisation (exemple simple, vous utiliseriez votre prétraitement du Chapitre 2)
# Assurez-vous d'avoir téléchargé 'punkt' : nltk.download('punkt')
try:
corpus_tokens = [word_tokenize(doc.lower()) for doc in corpus_texts]
except LookupError:
nltk.download('punkt')
corpus_tokens = [word_tokenize(doc.lower()) for doc in corpus_texts]
document_lengths = [len(doc_tokens) for doc_tokens in corpus_tokens]
plt.figure(figsize=(8, 5))
plt.hist(document_lengths, bins=5, color='skyblue', edgecolor='black')
plt.title("Distribution des longueurs de documents (en tokens)")
plt.xlabel("Nombre de tokens")
plt.ylabel("Nombre de documents")
plt.grid(axis='y', alpha=0.75)
plt.show()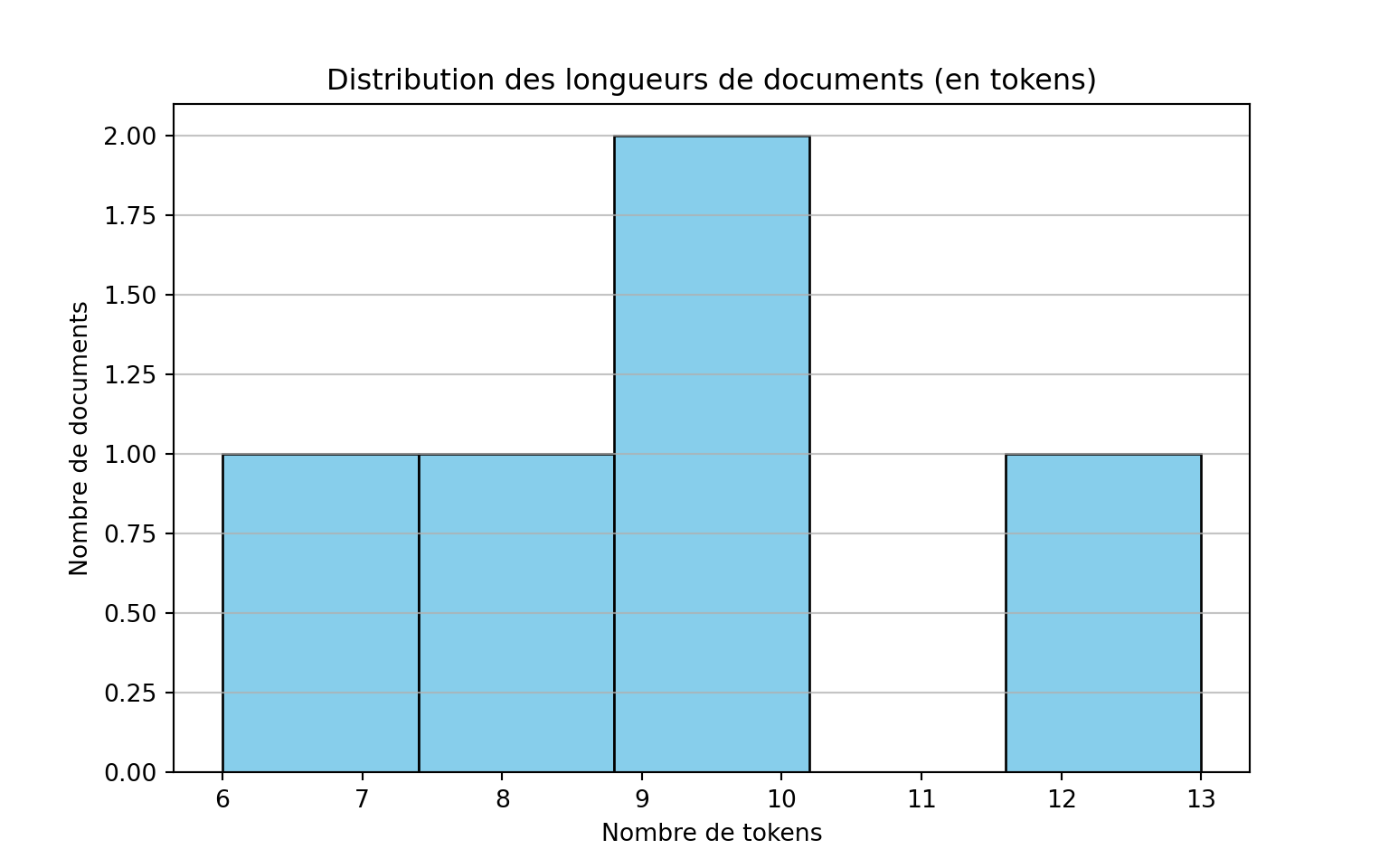
print(f"Longueur minimale: {min(document_lengths)}")Longueur minimale: 6print(f"Longueur maximale: {max(document_lengths)}")Longueur maximale: 13print(f"Longueur moyenne: {sum(document_lengths)/len(document_lengths):.2f}")Longueur moyenne: 9.00# install.packages(c("dplyr", "tidytext", "ggplot2"))
library(dplyr)
library(tidytext) # Pour unnest_tokens
library(ggplot2)
# Exemple de corpus (tibble ou data frame)
corpus_df <- tibble(
doc_id = 1:5,
text = c(
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec R et tidytext.",
"Visualisation des longueurs de documents."
)
)
# Tokenisation et calcul des longueurs
document_lengths_df <- corpus_df %>%
unnest_tokens(word, text) %>%
group_by(doc_id) %>%
summarise(length = n(), .groups = 'drop')
ggplot(document_lengths_df, aes(x = length)) +
geom_histogram(bins = 5, fill = "skyblue", color = "black") +
labs(title = "Distribution des longueurs de documents (en tokens)",
x = "Nombre de tokens",
y = "Nombre de documents") +
theme_minimal()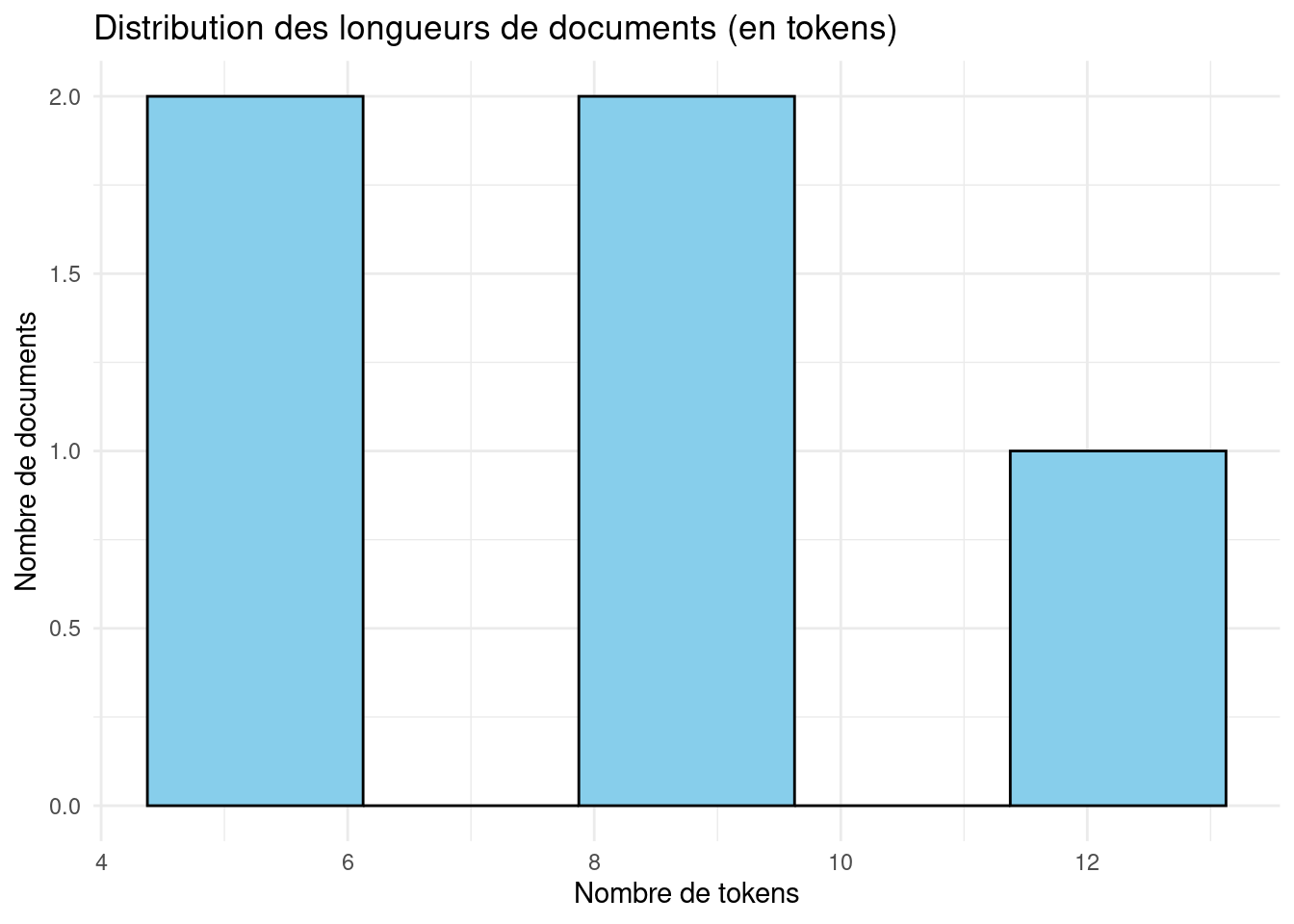
summary(document_lengths_df$length) Min. 1st Qu. Median Mean 3rd Qu. Max.
5.0 6.0 8.0 7.8 8.0 12.0 from collections import Counter
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Corpus de l'exemple précédent
corpus_texts = [
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec Python et NLTK.",
"Visualisation des longueurs de documents."
]
# Assurez-vous d'avoir téléchargé 'stopwords' et 'punkt'
try:
stop_words_fr = set(stopwords.words('french'))
# Ajoutez des mots-vides personnalisés si nécessaire
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
except LookupError:
nltk.download('stopwords')
nltk.download('punkt')
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
all_tokens_processed = []
for text in corpus_texts:
tokens = word_tokenize(text.lower())
tokens_filtered = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
all_tokens_processed.extend(tokens_filtered)
word_counts = Counter(all_tokens_processed)
print("10 mots les plus fréquents :")10 mots les plus fréquents :for word, count in word_counts.most_common(10):
print(f"- {word}: {count}")- document: 3
- ceci: 1
- premier: 1
- exemple: 1
- deuxième: 1
- peu: 1
- plus: 1
- long: 1
- parle: 1
- exploratoire: 1# install.packages(c("dplyr", "tidytext", "stopwords"))
library(dplyr)
library(tidytext)
library(stopwords) # Pour une liste de mots-vides plus complète
# Corpus de l'exemple précédent
corpus_df <- tibble(
doc_id = 1:5,
text = c(
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec R et tidytext.",
"Visualisation des longueurs de documents."
)
)
# Obtenir les mots vides en français
stop_words_fr <- tibble(word= stopwords::stopwords("fr")) # Package stopwords offre des listes plus fournies
# Vous pouvez ajouter des mots-vides personnalisés
custom_stop_words <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle"))
tidy_words_freq <- corpus_df %>%
unnest_tokens(word, text) %>%
filter(stringr::str_detect(word, "[a-z]")) %>% # Garder les mots avec au moins une lettre
anti_join(stop_words_fr, by = "word") %>%
anti_join(custom_stop_words, by = "word") %>%
count(word, sort = TRUE)
print("10 mots les plus fréquents :")[1] "10 mots les plus fréquents :"print(head(tidy_words_freq, 10))# A tibble: 10 × 2
word n
<chr> <int>
1 document 3
2 concis 1
3 court 1
4 d'analyse 1
5 deuxième 1
6 documents 1
7 données 1
8 exemple 1
9 exploration 1
10 exploratoire 1<br> :::{.panel-tabset}
from collections import Counter
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
import numpy as np
# Corpus et prétraitement de l'exemple précédent
corpus_texts = [
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec Python et NLTK.",
"Visualisation des longueurs de documents."
]
try:
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
except LookupError:
nltk.download('stopwords')
nltk.download('punkt')
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
all_tokens_processed = []
for text in corpus_texts:
tokens = word_tokenize(text.lower())
tokens_filtered = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
all_tokens_processed.extend(tokens_filtered)
word_counts = Counter(all_tokens_processed)
# Préparation des données pour le graphique de Zipf
frequencies = [count for word, count in word_counts.most_common()]
ranks = np.arange(1, len(frequencies) + 1)
plt.figure(figsize=(8, 6))
plt.loglog(ranks, frequencies, marker=".", linestyle='none', color='purple')
plt.title("Loi de Zipf : Distribution des fréquences de mots")
plt.xlabel("Rang (log)")
plt.ylabel("Fréquence (log)")
plt.grid(True)
plt.show()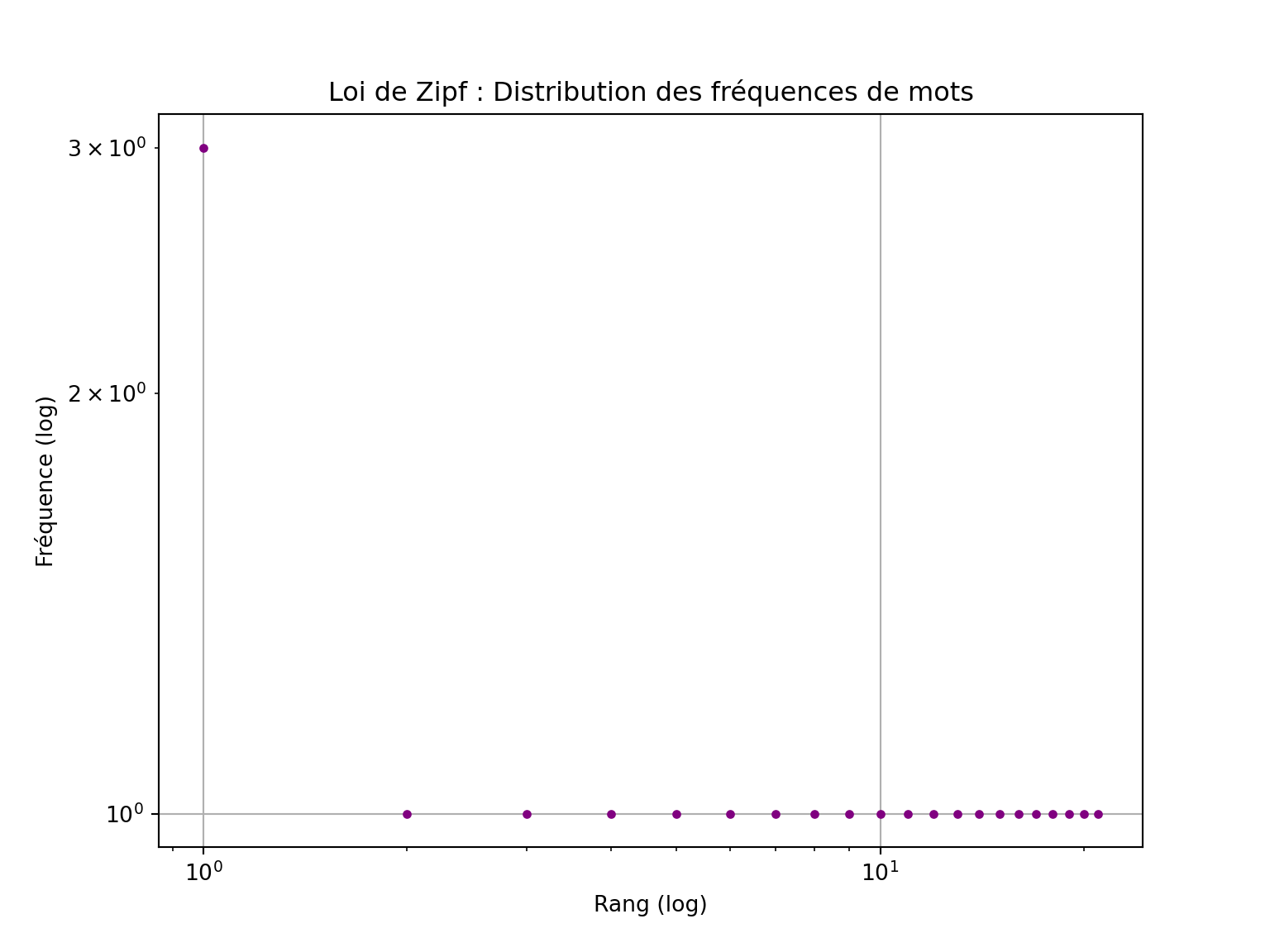
# install.packages(c("dplyr", "tidytext", "ggplot2", "stopwords"))
library(dplyr)
library(tidytext)
library(ggplot2)
library(stopwords)
# Corpus de l'exemple précédent
corpus_df <- tibble(
doc_id = 1:5,
text = c(
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec R et tidytext.",
"Visualisation des longueurs de documents."
)
)
stop_words_fr <- tibble(word= stopwords::stopwords("fr"))
custom_stop_words <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle"))
word_counts_df <- corpus_df %>%
unnest_tokens(word, text) %>%
filter(stringr::str_detect(word, "[a-z]")) %>%
anti_join(stop_words_fr, by = "word") %>%
anti_join(custom_stop_words, by = "word") %>%
count(word, sort = TRUE) %>%
mutate(rank = row_number())
ggplot(word_counts_df, aes(x = rank, y = n)) +
geom_point(pch=20) +
geom_line(color = "purple") +
scale_x_log10() +
scale_y_log10() +
labs(title = "Loi de Zipf : Distribution des fréquences de mots",
x = "Rang (log)",
y = "Fréquence (log)") +
theme_minimal()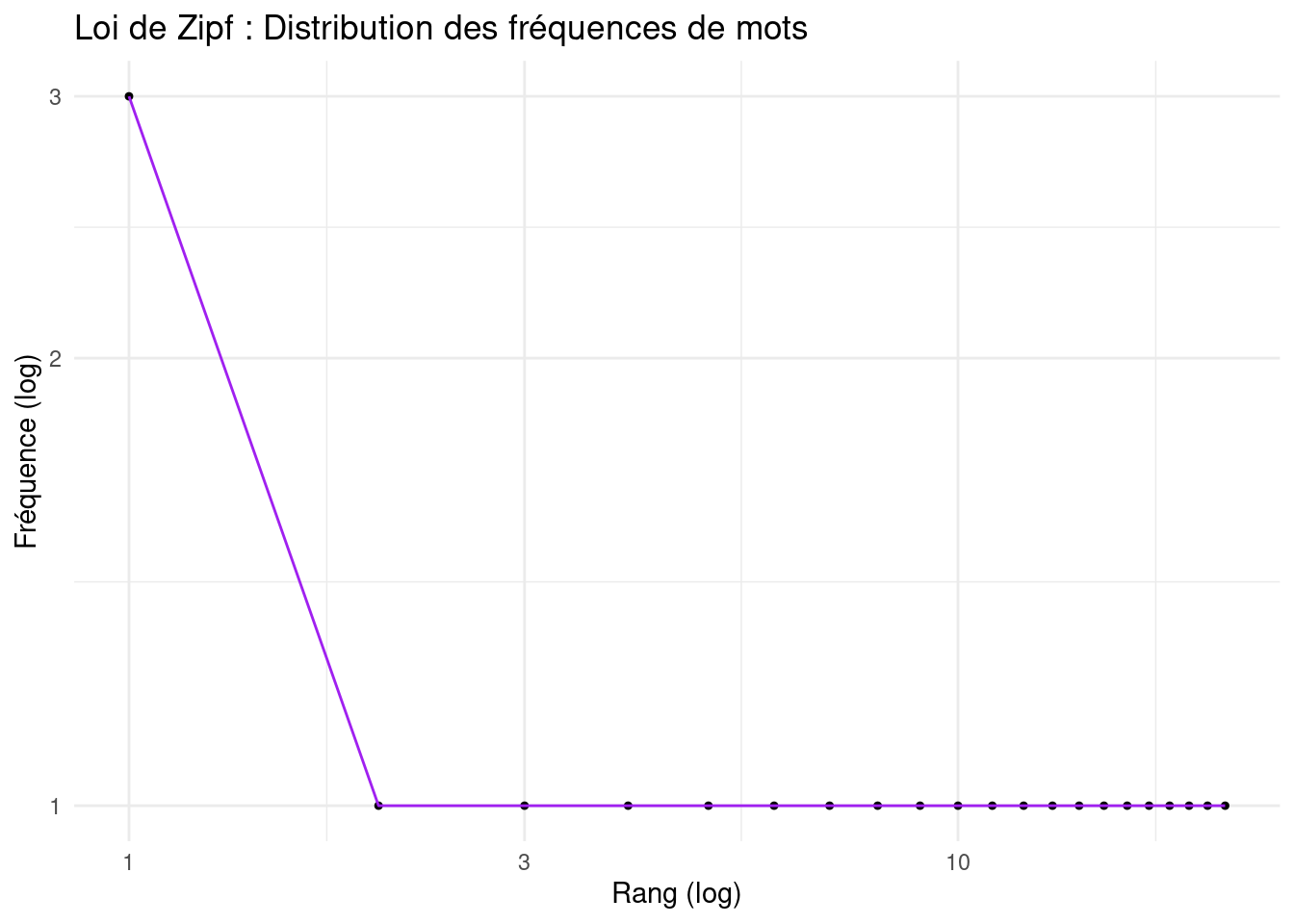
:::
La visualisation est un outil puissant pour explorer et communiquer les caractéristiques des données textuelles.
Ces graphiques permettent de visualiser la distribution des fréquences des mots les plus courants, rendant les tendances plus apparentes que de simples tableaux.
from collections import Counter
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
import pandas as pd # Pour faciliter le tracé avec les labels
# Corpus et prétraitement de l'exemple précédent
corpus_texts = [
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec Python et NLTK.",
"Visualisation des longueurs de documents."
]
try:
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
except LookupError:
nltk.download('stopwords')
nltk.download('punkt')
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
all_tokens_processed = []
for text in corpus_texts:
tokens = word_tokenize(text.lower())
tokens_filtered = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
all_tokens_processed.extend(tokens_filtered)
word_counts = Counter(all_tokens_processed)
# Préparer les données pour le diagramme en barres
top_n = 10
top_words_df = pd.DataFrame(word_counts.most_common(top_n), columns=['word', 'count'])
plt.figure(figsize=(10, 6))
plt.barh(top_words_df['word'], top_words_df['count'], color='teal')
plt.xlabel("Fréquence")
plt.ylabel("Mot")
plt.title(f"{top_n} mots les plus fréquents")
plt.gca().invert_yaxis() # Afficher le mot le plus fréquent en haut
plt.tight_layout()
plt.show()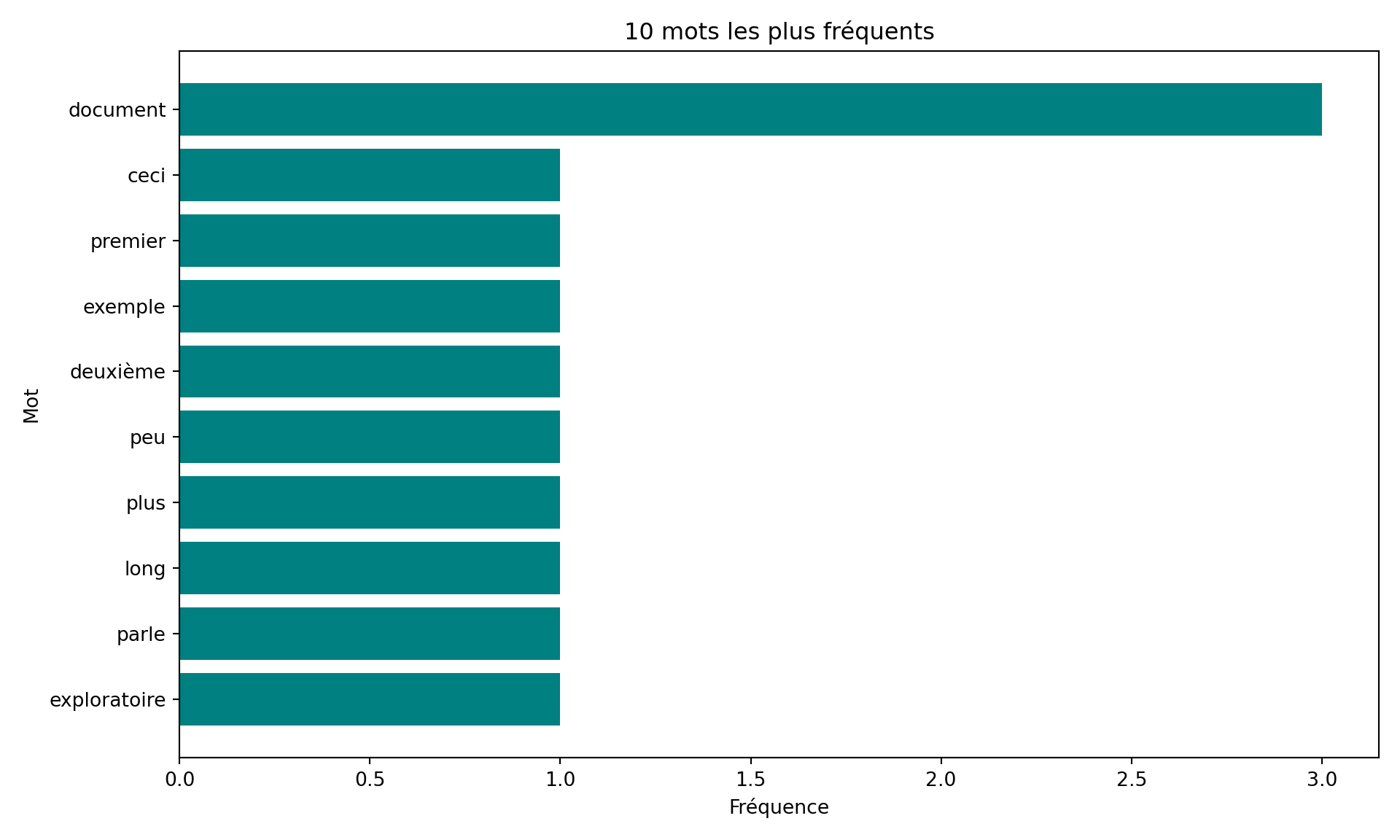
# install.packages(c("dplyr", "tidytext", "ggplot2", "stopwords"))
library(dplyr)
library(tidytext)
library(ggplot2)
library(stopwords)
# Corpus de l'exemple précédent
corpus_df <- tibble(
doc_id = 1:5,
text = c(
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec R et tidytext.",
"Visualisation des longueurs de documents."
)
)
stop_words_fr <- tibble(word= stopwords::stopwords("fr"))
custom_stop_words <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle"))
tidy_words_freq_plot <- corpus_df %>%
unnest_tokens(word, text) %>%
filter(stringr::str_detect(word, "[a-z]")) %>%
anti_join(stop_words_fr, by = "word") %>%
anti_join(custom_stop_words, by = "word") %>%
count(word, sort = TRUE) %>%
top_n(10, n) %>% # Sélectionner les 10 plus fréquents
mutate(word = reorder(word, n)) # Réordonner pour le graphique
ggplot(tidy_words_freq_plot, aes(x = word, y = n)) +
geom_col(fill = "steelblue") +
xlab(NULL) +
ylab("Fréquence") +
coord_flip() + # Barres horizontales
ggtitle("10 mots les plus fréquents") +
theme_minimal()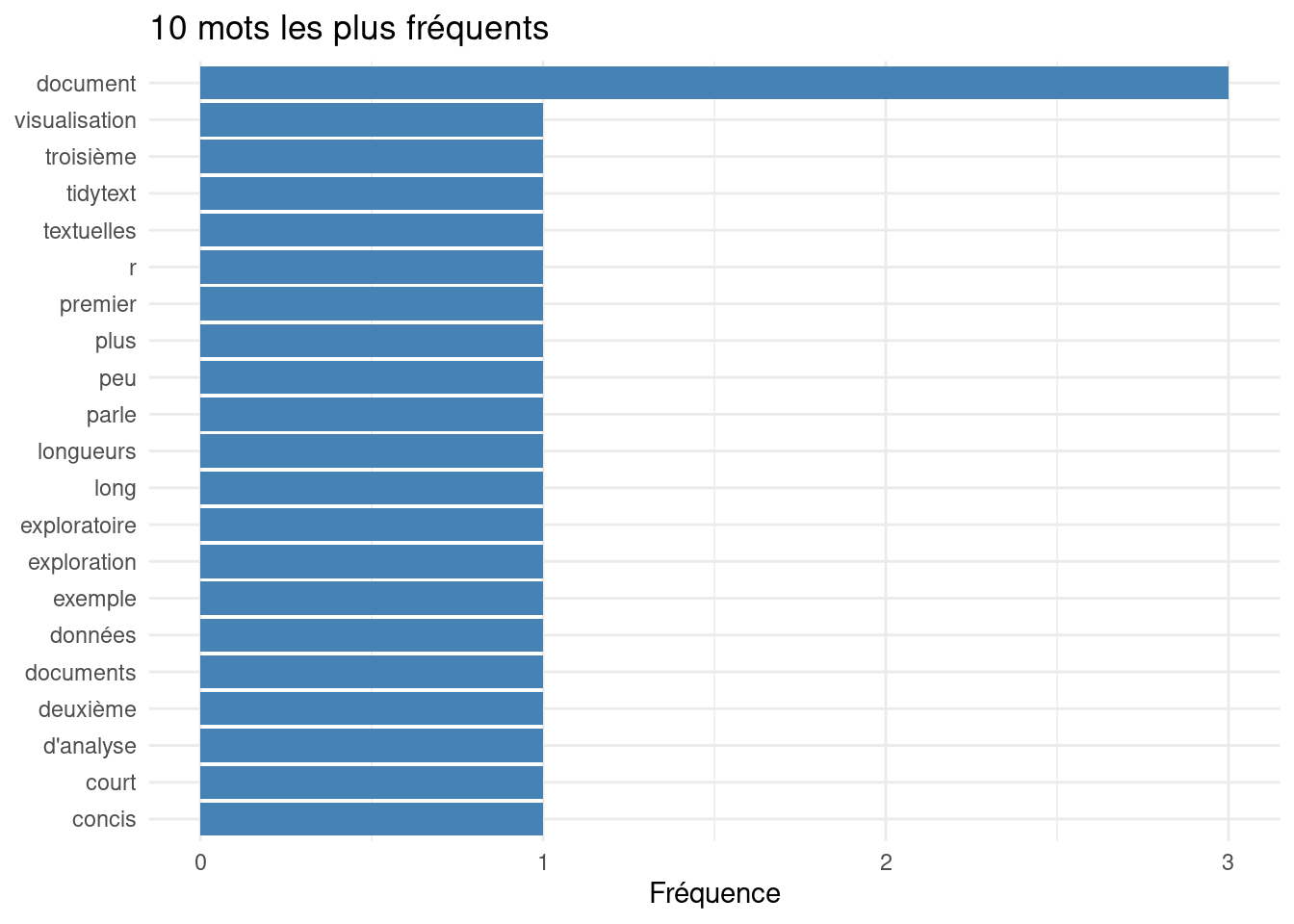
Un nuage de mots est une représentation visuelle des fréquences de mots où la taille de chaque mot est proportionnelle à sa fréquence dans le corpus.
wordcloud en Python ou wordcloud / wordcloud2 en R.# install.packages("wordcloud") # Si non installé
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Corpus et prétraitement de l'exemple précédent
corpus_texts = [
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec Python et NLTK.",
"Visualisation des longueurs de documents."
]
try:
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
except LookupError:
nltk.download('stopwords')
nltk.download('punkt')
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle"])
all_tokens_processed_str = ""
for text in corpus_texts:
tokens = word_tokenize(text.lower())
tokens_filtered = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
all_tokens_processed_str += " ".join(tokens_filtered) + " "
if all_tokens_processed_str.strip(): # Vérifier si la chaîne n'est pas vide
wordcloud_img = WordCloud(width=800, height=400, background_color='white',
colormap='viridis', stopwords=stop_words_fr).generate(all_tokens_processed_str)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud_img, interpolation='bilinear')
plt.axis("off")
plt.title("Nuage de mots du corpus")
plt.show()
else:
print("Aucun mot à afficher dans le nuage de mots après filtrage.")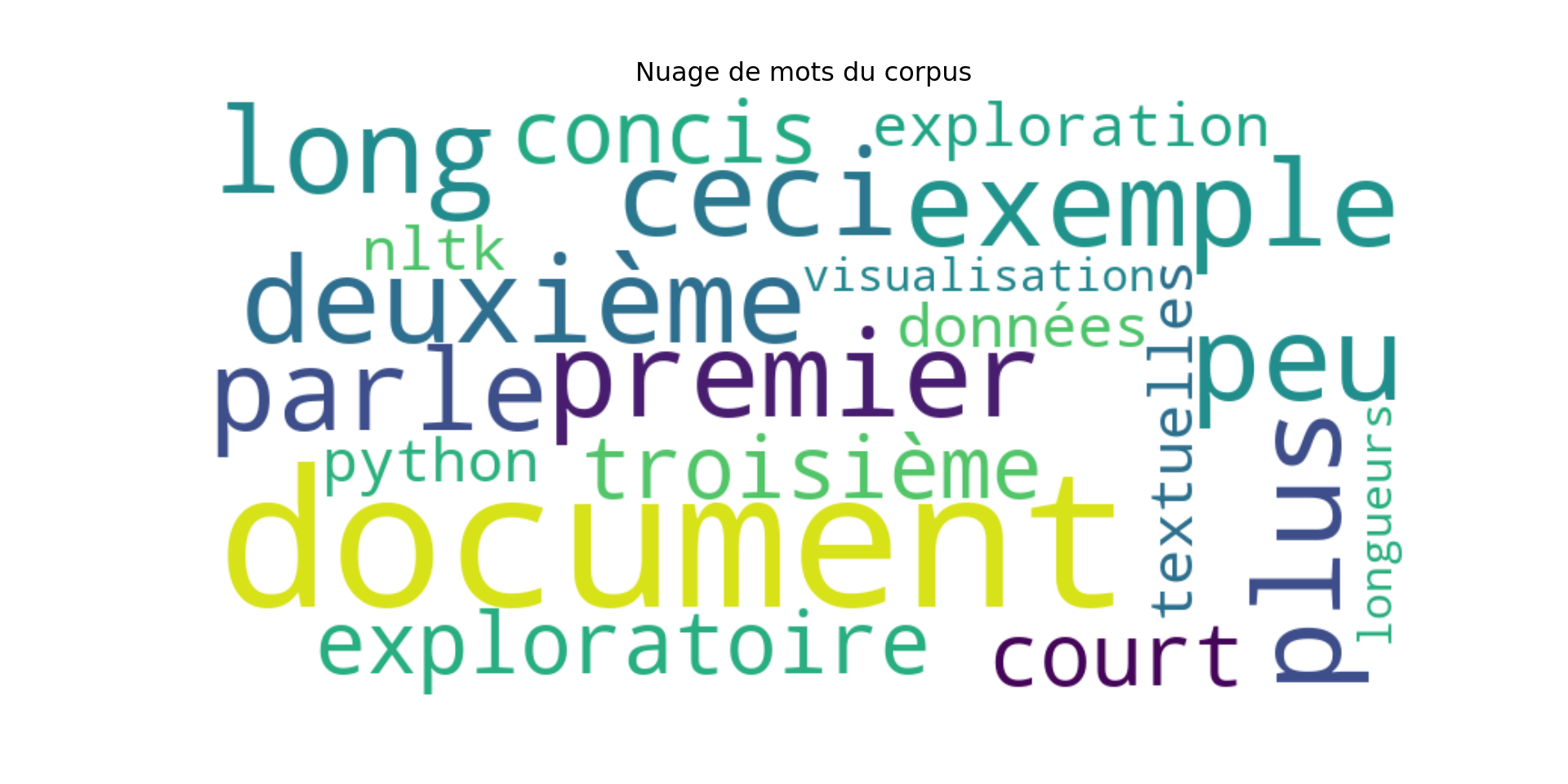
# install.packages(c("dplyr", "tidytext", "wordcloud", "stopwords", "RColorBrewer"))
library(dplyr)
library(tidytext)
library(wordcloud)
library(stopwords)
library(RColorBrewer) # Pour les palettes de couleurs
# Corpus de l'exemple précédent
corpus_df <- tibble(
doc_id = 1:5,
text = c(
"Ceci est le premier document pour notre exemple.",
"Le deuxième document est un peu plus long et parle d'analyse exploratoire.",
"Un troisième document, court et concis.",
"Exploration des données textuelles avec R et tidytext.",
"Visualisation des longueurs de documents."
)
)
stop_words_fr <- tibble(word= stopwords::stopwords("fr"))
custom_stop_words <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle"))
word_counts_for_cloud <- corpus_df %>%
unnest_tokens(word, text) %>%
filter(stringr::str_detect(word, "[a-z]")) %>%
anti_join(stop_words_fr, by = "word") %>%
anti_join(custom_stop_words, by = "word") %>%
count(word, sort = TRUE)
# Vérifier si des mots sont disponibles
if(nrow(word_counts_for_cloud) > 0) {
set.seed(123) # Pour la reproductibilité de la disposition
wordcloud(words = word_counts_for_cloud$word,
freq = word_counts_for_cloud$n,
min.freq = 1, # Afficher les mots avec au moins cette fréquence
max.words = 100, # Nombre maximum de mots à afficher
random.order = FALSE, # Mots les plus fréquents au centre
rot.per = 0.30, # Proportion de mots pivotés
colors = brewer.pal(8, "Dark2")) # Palette de couleurs
title(main = "Nuage de mots du corpus", cex.main = 1)
} else {
print("Aucun mot à afficher dans le nuage de mots après filtrage.")
}
C’est comme prendre les mots les plus “lourds” (fréquents) de votre texte et les laisser tomber sur une page ; les plus lourds prendront plus de place.
Si votre corpus peut être divisé en catégories (par exemple, avis positifs vs. négatifs, articles de différents auteurs, textes de différentes époques), il est très informatif de comparer les fréquences de mots entre ces sous-ensembles.
# install.packages(c("dplyr", "tidytext", "ggplot2", "stopwords", "stringr"))
library(dplyr)
library(tidytext)
library(ggplot2)
library(stopwords)
library(stringr) # Pour str_detect
corpus_comparison_df <- tibble(
category = factor(rep(c("Sports", "Technologie"), each = 3)),
text = c(
"Le match de football était incroyable, une victoire écrasante pour l'équipe locale.",
"Le joueur de tennis a gagné le grand tournoi après un match difficile et intense.",
"L'équipe de basket a montré une grande performance défensive et offensive durant le championnat.",
"Le nouveau smartphone offre des fonctionnalités innovantes et une meilleure autonomie.",
"L'intelligence artificielle transforme de nombreux secteurs, y compris la santé et la finance.",
"La cybersécurité est un enjeu majeur pour la protection des données dans le monde de la technologie."
)
)
# Obtenir les mots vides en français
stop_words_fr_tbl <- tibble(word = stopwords::stopwords("fr"))
custom_stop_words_tbl <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle", "plus", "très", "aussi"))
category_word_counts <- corpus_comparison_df %>%
unnest_tokens(word, text) %>%
filter(str_detect(word, "[a-z]")) %>% # Garder les mots avec au moins une lettre
anti_join(stop_words_fr_tbl, by = "word") %>%
anti_join(custom_stop_words_tbl, by = "word") %>%
count(category, word, sort = TRUE) %>%
group_by(category) %>%
top_n(7, n) %>% # Sélectionner les N plus fréquents par catégorie
ungroup() %>%
mutate(word = reorder_within(word, n, category)) # Pour un bon ordre dans les facettes
ggplot(category_word_counts, aes(x = word, y = n, fill = category)) +
geom_col(show.legend = FALSE) +
scale_x_reordered() + # Utiliser avec reorder_within
facet_wrap(~category, scales = "free_y") + # Facettes par catégorie, échelle y libre
coord_flip() +
labs(title = "Mots les plus fréquents par catégorie", x = "Mot", y = "Fréquence") +
theme_minimal()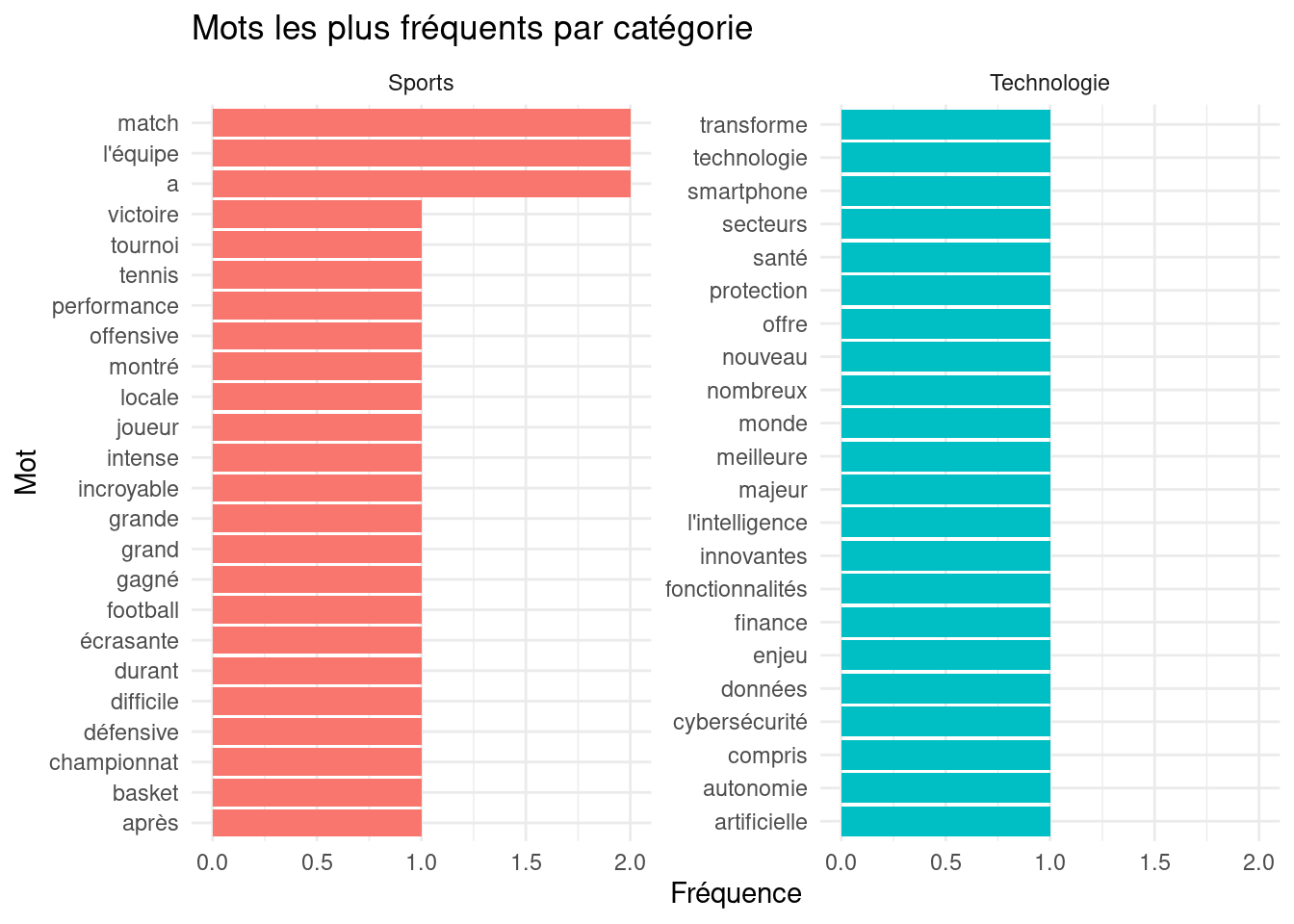
Comprendre quels mots apparaissent fréquemment ensemble peut révéler des associations thématiques ou des expressions courantes.
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.collocations import BigramAssocMeasures, BigramCollocationFinder
import networkx as nx
import matplotlib.pyplot as plt
import itertools
from collections import Counter
# S'assurer que les ressources NLTK nécessaires sont téléchargées
try:
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle", "plus", "très", "aussi", "cet", "cette", "si"])
word_tokenize("test")
except LookupError:
nltk.download('stopwords', quiet=True)
nltk.download('punkt', quiet=True)
stop_words_fr = set(stopwords.words('french'))
stop_words_fr.update(['.', ',', '!', '?', "c'est", "d'un", "l'on", "qu'il", "qu'elle", "plus", "très", "aussi", "cet", "cette", "si"])['test']corpus_cooccurrence = [
"L'intelligence artificielle est un domaine fascinant de l'informatique.",
"L'apprentissage automatique, une branche de l'intelligence artificielle, progresse rapidement.",
"Les réseaux de neurones sont utilisés en apprentissage automatique.",
"Le traitement du langage naturel bénéficie de l'intelligence artificielle.",
"L'éthique en intelligence artificielle est un sujet de discussion important.",
"Apprentissage profond et réseaux de neurones sont des sujets liés."
]
all_words_processed = []
for text in corpus_cooccurrence:
tokens = word_tokenize(text.lower())
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
all_words_processed.extend(filtered_tokens)
# Option 1: Utiliser BigramCollocationFinder (plus formel pour les collocations)
# finder = BigramCollocationFinder.from_words(all_words_processed)
# finder.apply_freq_filter(2) # Filtrer les bigrammes apparaissant moins de N fois
# bigram_measures = BigramAssocMeasures()
# top_bigrams = finder.nbest(bigram_measures.pmi, 10) # Top N bigrammes par PMI
# Option 2: Compter les paires de mots co-occurrents dans une fenêtre (plus simple pour la visualisation)
cooccurrences = Counter()
window_size = 3 # Fenêtre de co-occurrence (mots adjacents)
for text in corpus_cooccurrence:
tokens = word_tokenize(text.lower())
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words_fr]
for i in range(len(filtered_tokens) - window_size + 1):
window = filtered_tokens[i : i + window_size]
# Générer toutes les paires uniques dans la fenêtre
for w1, w2 in itertools.combinations(window, 2):
# Mettre en ordre alphabétique pour éviter (motA, motB) et (motB, motA) comme paires distinctes
pair = tuple(sorted((w1, w2)))
cooccurrences[pair] +=1
top_pairs = cooccurrences.most_common(15) # Les 15 paires les plus fréquentes
if top_pairs:
G = nx.Graph()
for (word1, word2), freq in top_pairs:
G.add_edge(word1, word2, weight=freq)
plt.figure(figsize=(12, 10))
pos = nx.spring_layout(G, k=0.6, iterations=50, seed=42) # k pour ajuster l'espacement
# Dessiner les nœuds
nx.draw_networkx_nodes(G, pos, node_size=1500, node_color='skyblue', alpha=0.9)
# Dessiner les arêtes avec une épaisseur proportionnelle au poids
edges = G.edges(data=True)
edge_weights = [d['weight'] for u,v,d in edges]
# Normaliser les poids pour une meilleure visualisation de l'épaisseur
max_weight = max(edge_weights) if edge_weights else 1
edge_widths = [5 * (weight / max_weight) for weight in edge_weights]
nx.draw_networkx_edges(G, pos, width=edge_widths, alpha=0.5, edge_color='gray')
# Dessiner les étiquettes des nœuds
nx.draw_networkx_labels(G, pos, font_size=10, font_family='sans-serif')
plt.title("Réseau de Cooccurrences de Mots (Top 15 paires)", size=15)
plt.axis('off') # Masquer les axes
plt.show()
else:
print("Pas assez de cooccurrences trouvées pour générer un graphe.")<Figure size 1200x1000 with 0 Axes>
<matplotlib.collections.PathCollection object at 0x7d6927954830>
<matplotlib.collections.LineCollection object at 0x7d6927d20fb0>
{'neurones': Text(0.18464296749636416, 0.806546049438682, 'neurones'), 'réseaux': Text(0.3406941351266433, 0.9172401300622078, 'réseaux'), 'artificielle': Text(0.11065451659305364, -0.42231742779377107, 'artificielle'), 'branche': Text(-0.09401213213165924, -0.11194539706096518, 'branche'), 'progresse': Text(0.3729077254916497, -0.40722442167346207, 'progresse'), 'utilisés': Text(0.4239085294870128, 0.638821633683458, 'utilisés'), 'apprentissage': Text(0.6750531789907405, 0.593575865542347, 'apprentissage'), 'langage': Text(-0.7467722558820136, -0.5980249759113309, 'langage'), 'naturel': Text(-0.513008701311172, -0.545272089399724, 'naturel'), 'bénéficie': Text(-0.4525366211164922, -0.7687194079419716, 'bénéficie'), 'sujet': Text(-0.18772924448189351, -0.3607668224254237, 'sujet'), 'discussion': Text(-0.44637761672727533, -0.2620340954297071, 'discussion'), 'profond': Text(0.23179416377689663, 1.0, 'profond'), 'sujets': Text(-0.11236819387420502, 0.8293470404225252, 'sujets'), 'domaine': Text(0.24280642259448332, -0.8048414505245326, 'domaine'), 'fascinant': Text(0.40346348094575185, -0.7033601002099067, 'fascinant'), 'automatique': Text(-0.4331203549778848, 0.1989754692215745, 'automatique')}
Text(0.5, 1.0, 'Réseau de Cooccurrences de Mots (Top 15 paires)')
(-0.8960639265436527, 0.8243448496523796, -0.9943498028296085, 1.189508352305076)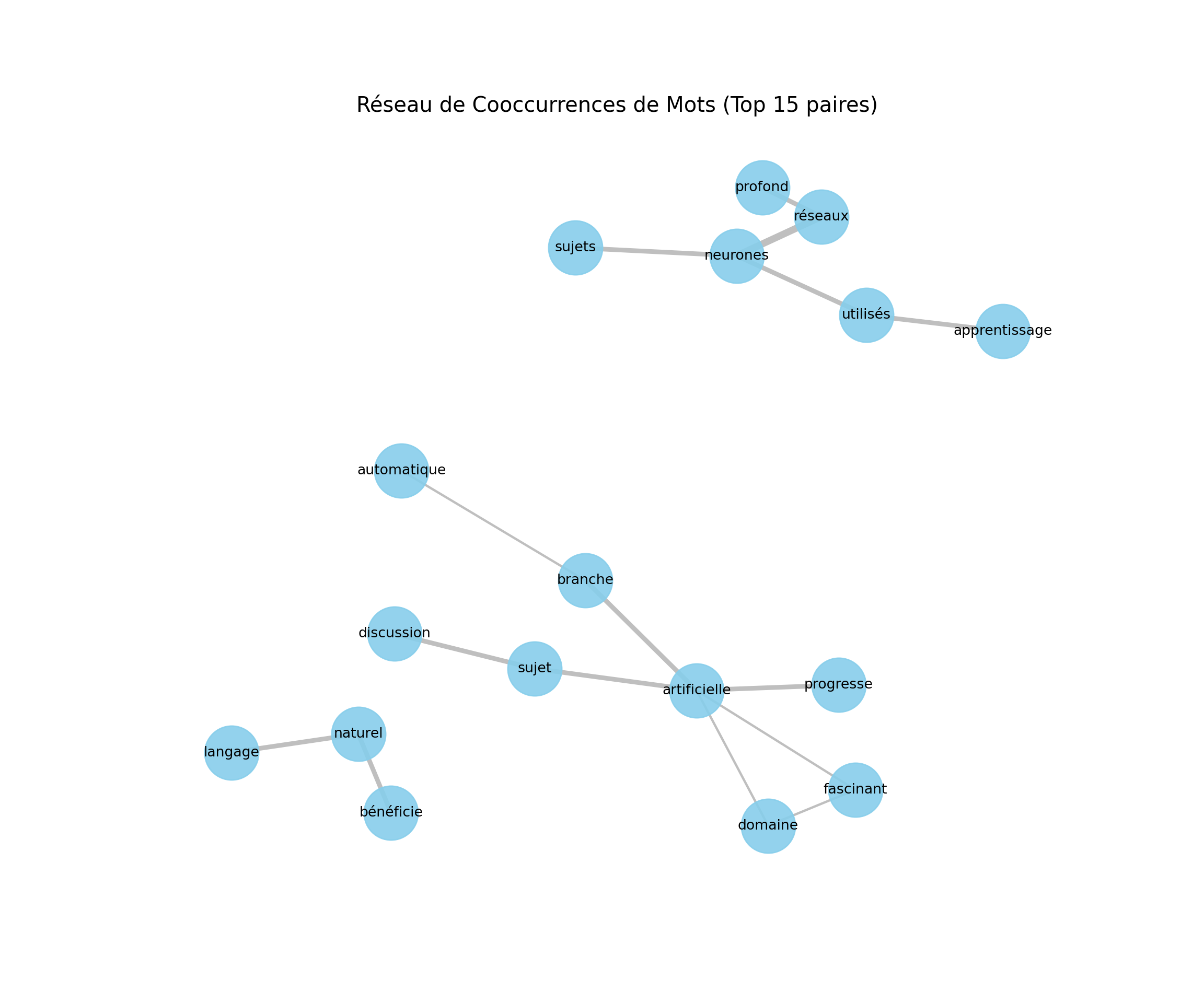
# install.packages(c("dplyr", "tidytext", "widyr", "ggraph", "igraph", "stopwords", "stringr"))
library(dplyr)
library(tidytext)
library(widyr) # Pour pairwise_count
library(ggraph)
library(igraph)
library(stopwords)
library(stringr)
corpus_cooccurrence_df <- tibble(
doc_id = 1:6,
text = c(
"L'intelligence artificielle est un domaine fascinant de l'informatique.",
"L'apprentissage automatique, une branche de l'intelligence artificielle, progresse rapidement.",
"Les réseaux de neurones sont utilisés en apprentissage automatique.",
"Le traitement du langage naturel bénéficie de l'intelligence artificielle.",
"L'éthique en intelligence artificielle est un sujet de discussion important.",
"Apprentissage profond et réseaux de neurones sont des sujets liés."
)
)
stop_words_fr_tbl <- tibble(word = stopwords::stopwords("fr"))
custom_stop_words_tbl <- tibble(word = c("c'est", "d'un", "l'on", "qu'il", "qu'elle", "plus", "très", "aussi", "cet", "cette", "si"))
# Tokeniser et filtrer les mots
tidy_words_cooc <- corpus_cooccurrence_df %>%
unnest_tokens(word, text) %>%
filter(str_detect(word, "[a-zÀ-ÿ]+")) %>% # Garder les mots (avec accents)
anti_join(stop_words_fr_tbl, by = "word") %>%
anti_join(custom_stop_words_tbl, by = "word")
# Compter les cooccurrences de mots au sein de chaque document
# 'item' est le mot, 'feature' est le doc_id pour grouper
word_pairs <- tidy_words_cooc %>%
pairwise_count(item = word, feature = doc_id, sort = TRUE, upper = FALSE) %>%
filter(n >= 1) # Garder les paires qui co-occurrent au moins N fois
if(nrow(word_pairs) > 0) {
# Sélectionner les N paires les plus fréquentes pour la visualisation
top_word_pairs <- word_pairs %>%
top_n(20, n) # Les 20 paires les plus fréquentes
# Créer un objet graphe
graph_cooc <- graph_from_data_frame(top_word_pairs, directed = FALSE)
# Visualiser avec ggraph
set.seed(123) # Pour la reproductibilité de la disposition
ggraph(graph_cooc, layout = "fr") + # Fruchterman-Reingold layout
geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "dodgerblue") +
geom_node_point(color = "skyblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE, size = 3.5, point.padding = unit(0.2, "lines")) +
theme_graph(base_family = "sans") +
labs(title = "Réseau de Cooccurrences de Mots",
subtitle = "Basé sur les paires de mots au sein des documents",
edge_width = "Fréquence de cooccurrence",
edge_alpha = "Fréquence de cooccurrence")
} else {
print("Pas assez de cooccurrences trouvées pour générer un graphe.")
}
L’analyse exploratoire et la visualisation sont des étapes indispensables du text mining. Elles permettent de se familiariser avec le corpus, de valider les étapes de prétraitement, de découvrir des informations initiales et d’orienter les choix méthodologiques pour les analyses plus poussées. Les “insights” obtenus ici peuvent grandement influencer la qualité et la pertinence des résultats finaux de votre projet de text mining.
Exercise 1 Objectif
Analyser et comparer les caractéristiques linguistiques de descriptions de produits provenant de deux catégories différentes (par exemple, “Smartphones” vs. “Livres de Fiction”). L’objectif est d’identifier les termes distinctifs et les tendances de langage propres à chaque catégorie.
Donnée
Nous allons utiliser un petit corpus de descriptions de produits que nous allons définir directement dans le code.
corpus_produits = {
"Smartphones": [
"Découvrez le nouveau smartphone Alpha avec son écran OLED révolutionnaire et une autonomie de batterie exceptionnelle. Capturez des photos incroyables grâce à son triple capteur photo avancé.",
"Le modèle Beta offre une performance ultra-rapide avec son processeur dernière génération et 12Go de RAM. Idéal pour le gaming et le multitâche intensif. Design élégant et léger en aluminium recyclé.",
"Smartphone Gamma : l'équilibre parfait entre puissance et prix. Doté d'un grand écran lumineux, d'une batterie longue durée et d'un appareil photo polyvalent pour tous vos besoins.",
"Le smartphone Delta Pro est conçu pour les professionnels exigeants. Sécurité renforcée, processeur optimisé pour les applications métier et une suite logicielle exclusive.",
"Compact et performant, le smartphone Epsilon se glisse partout. Son interface utilisateur intuitive et sa batterie optimisée en font un excellent choix pour une utilisation quotidienne."
],
"Livres de Fiction": [
"Plongez dans une aventure épique avec 'Les Chroniques de Valoria', un roman de fantasy captivant. Des personnages attachants et un univers riche en mystères et magie vous attendent.",
"'Le Dernier Secret de l'Horloger' est un thriller psychologique haletant qui vous tiendra en haleine jusqu'à la dernière page. Rebondissements garantis et suspense insoutenable.",
"Découvrez 'Murmures dans la Brume', une romance historique poignante se déroulant au XIXe siècle. Amour, trahison et secrets de famille s'entremêlent dans ce récit inoubliable.",
"Ce recueil de nouvelles de science-fiction explore des futurs alternatifs et des technologies étonnantes. Chaque histoire est une réflexion profonde sur l'humanité et son devenir.",
"'L'Énigme du Manoir Oublié' est un roman policier classique où un détective sagace doit résoudre un meurtre mystérieux. Indices subtils et fausses pistes mettront vos méninges à l'épreuve."
]
}
# Pour l'utiliser :
# for categorie, descriptions in corpus_produits.items():
# print(f"\nCatégorie : {categorie}")
# for desc in descriptions:
# print(f"- {desc}")library(tibble)
corpus_produits_df <- tibble(
category = factor(rep(c("Smartphones", "Livres de Fiction"), each = 5)),
text = c(
# Smartphones
"Découvrez le nouveau smartphone Alpha avec son écran OLED révolutionnaire et une autonomie de batterie exceptionnelle. Capturez des photos incroyables grâce à son triple capteur photo avancé.",
"Le modèle Beta offre une performance ultra-rapide avec son processeur dernière génération et 12Go de RAM. Idéal pour le gaming et le multitâche intensif. Design élégant et léger en aluminium recyclé.",
"Smartphone Gamma : l'équilibre parfait entre puissance et prix. Doté d'un grand écran lumineux, d'une batterie longue durée et d'un appareil photo polyvalent pour tous vos besoins.",
"Le smartphone Delta Pro est conçu pour les professionnels exigeants. Sécurité renforcée, processeur optimisé pour les applications métier et une suite logicielle exclusive.",
"Compact et performant, le smartphone Epsilon se glisse partout. Son interface utilisateur intuitive et sa batterie optimisée en font un excellent choix pour une utilisation quotidienne.",
# Livres de Fiction
"Plongez dans une aventure épique avec 'Les Chroniques de Valoria', un roman de fantasy captivant. Des personnages attachants et un univers riche en mystères et magie vous attendent.",
"'Le Dernier Secret de l'Horloger' est un thriller psychologique haletant qui vous tiendra en haleine jusqu'à la dernière page. Rebondissements garantis et suspense insoutenable.",
"Découvrez 'Murmures dans la Brume', une romance historique poignante se déroulant au XIXe siècle. Amour, trahison et secrets de famille s'entremêlent dans ce récit inoubliable.",
"Ce recueil de nouvelles de science-fiction explore des futurs alternatifs et des technologies étonnantes. Chaque histoire est une réflexion profonde sur l'humanité et son devenir.",
"'L'Énigme du Manoir Oublié' est un roman policier classique où un détective sagace doit résoudre un meurtre mystérieux. Indices subtils et fausses pistes mettront vos méninges à l'épreuve."
)
)
# Pour l'utiliser :
# print(corpus_produits_df)Tâches à Réaliser
Outils à Utiliser
Utilisez les bibliothèques Python (nltk, collections.Counter, matplotlib, wordcloud, pandas) ou R (dplyr, tidytext, ggplot2, wordcloud, stopwords, stringr) que nous avons vues.
Pour Aller Plus Loin