1 Qu’est-ce que le Text Mining ?

Le Text Mining, ou exploration de textes, est un processus intensif en connaissances au cours duquel un utilisateur interagit avec une collection de documents textuels à l’aide d’outils analytiques afin d’identifier et d’explorer des motifs intéressants. À une époque caractérisée par une explosion de la quantité de données, dont une grande partie est textuelle et non structurée, le text mining est devenu une discipline essentielle pour extraire des informations précieuses[cite: 8103, 4332]. Il vise à transformer le texte, un ensemble de données intrinsèquement non structurées, en informations exploitables et en connaissances.
Soit \(\mathcal{D}_n=\left\{d_i\right\}_{i=1}^n\) un corpus de \(n\) documents. L’objectif du text mining est d’analyser ce corpus pour en déduire des structures, des tendances ou des informations cachées.
1.1 Relation avec le Data Mining et le Traitement du Langage Naturel (NLP)
Le text mining est étroitement lié au data mining, qui est le processus de découverte de motifs implicites, inconnus et potentiellement utiles dans de grandes collections de données[cite: 4366]. La principale différence réside dans la nature des données : le data mining traite typiquement des données structurées (numériques ou catégorielles dans des tables), tandis que le text mining se concentre sur les données textuelles non structurées[cite: 4370, 4379]. Pour appliquer les méthodes de data mining aux textes, ces derniers doivent d’abord être convertis en une représentation structurée.
Le text mining s’appuie également fortement sur le Traitement du Langage Naturel (NLP), un domaine de l’intelligence artificielle et de la linguistique computationnelle qui se concentre sur l’interaction entre les ordinateurs et le langage humain. Le NLP fournit les outils pour comprendre la structure et la signification du langage (par exemple, l’analyse syntaxique, la reconnaissance d’entités nommées), qui sont ensuite utilisés par le text mining pour des analyses à plus grande échelle.
1.2 Le Processus Général du Text Mining
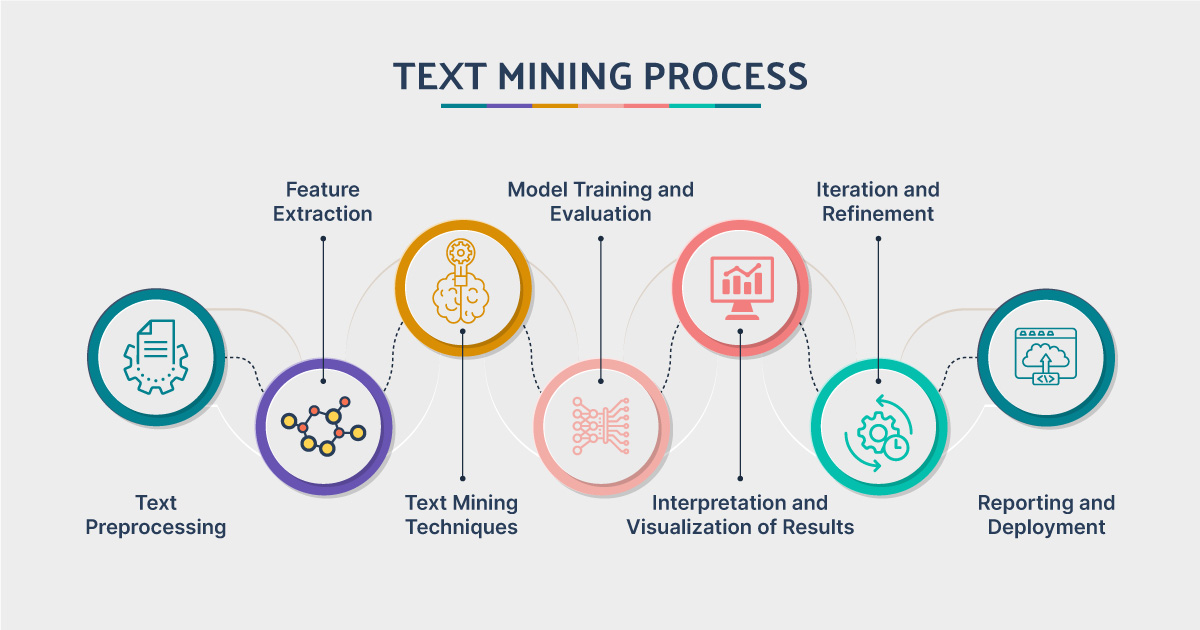
Bien que les détails puissent varier, un projet de text mining suit généralement plusieurs étapes clés:
- Définition du Problème : Comprendre le domaine et formuler clairement les questions auxquelles on cherche à répondre.
- Collecte des Données : Identifier et rassembler les documents textuels pertinents (le corpus \(\mathcal{D}_n\)).
- Prétraitement du Texte : Nettoyer et transformer le texte brut en une forme plus structurée et analysable. Cela inclut des tâches comme la tokenisation (découpage en mots ou phrases), la normalisation (conversion en minuscules, suppression de la ponctuation), le filtrage (suppression des mots-vides) et la racinisation/lemmatisation.
- Définition des Caractéristiques (Feature Engineering) : Convertir le texte prétraité en une représentation numérique (par exemple, le modèle sac-de-mots, TF-IDF, ou des plongements de mots) que les algorithmes d’apprentissage automatique peuvent comprendre[cite: 4417, 786, 5107].
- Analyse des Données (Modélisation) : Appliquer des algorithmes d’apprentissage automatique (supervisé ou non supervisé) pour trouver des motifs, classifier des documents, découvrir des thèmes, etc.
- Interprétation et Évaluation des Résultats : Analyser les sorties du modèle, valider leur pertinence par rapport au problème initial et communiquer les découvertes.
1.3 Le Langage comme Donnée
La pierre angulaire du text mining est la capacité de traiter le langage naturel comme une source de données. Contrairement aux données numériques traditionnelles, le texte est non structuré (ou semi-structuré dans des formats comme XML ou JSON) et contient une richesse sémantique complexe[cite: 4348]. Transformer cette complexité en caractéristiques quantifiables est un défi majeur mais essentiel[cite: 5107]. Le corpus \(\mathcal{D}_n\) est la matière première à partir de laquelle les caractéristiques (ou “features”) sont extraites pour alimenter les modèles d’analyse.
Dans les chapitres suivants, nous allons détailler chacune de ces étapes et explorer les techniques et outils qui vous permettront de mener à bien vos propres projets de text mining.