Un Guide Pratique de la Classification Binaire avec la Régression Logistique
Authors
Affiliation
Wilson Toussile12
ENSPY
1ENSPY, 2ESSFAR
1 Introduction à la Classification Binaire
La classification binaire est une tâche fondamentale en apprentissage automatique (Machine Learning). Elle appartient à la catégorie de l’apprentissage supervisé et son objectif principal est de prédire une variable cible qui ne peut prendre que deux valeurs distinctes, souvent représentées par 0 et 1. Pensez à des problèmes courants comme déterminer si un email est un “spam” (1) ou “non-spam” (0), si un client va effectuer un achat (1) ou non (0), ou encore si une transaction financière est “frauduleuse” (1) ou “légitime” (0).
Dans cet article, nous allons explorer en détail l’un des algorithmes les plus populaires et les plus intuitifs pour aborder ces problèmes : la régression logistique. Nous verrons pourquoi des méthodes plus simples comme la régression linéaire ne sont pas directement adaptées, comment la fonction logistique vient à la rescousse, et comment entraîner et évaluer un tel modèle avec des exemples concrets en Python.
2 Les Limites de la Régression Linéaire pour la Classification
La régression linéaire est un outil puissant pour prédire des valeurs continues, comme le prix d’une maison ou la température. Son équation est de la forme :
Si l’on tentait d’appliquer directement la régression linéaire à un problème de classification binaire où \(y\) ne peut être que 0 ou 1, nous rencontrerions plusieurs problèmes (source: 765):
Sorties non bornées : Les prédictions \(y\) pourraient être inférieures à 0 ou supérieures à 1. Or, si nous voulons interpréter la sortie comme une probabilité d’appartenance à une classe, celle-ci doit impérativement être comprise entre 0 et 1.
Relation non linéaire : La relation entre les caractéristiques (les \(x_j\)) et la probabilité qu’une observation appartienne à une classe donnée est rarement linéaire (source: 767, 768). Une petite variation d’une caractéristique peut avoir un impact très différent sur la probabilité selon que cette probabilité est déjà proche de 0, de 1, ou en plein milieu.
Note
Le besoin d’une transformation : Il nous faut donc une méthode pour “transformer” la sortie linéaire de manière à ce qu’elle puisse être interprétée comme une probabilité, c’est-à-dire une valeur comprise entre 0 et 1.
3 La Fonction Logistique (ou Sigmoïde) : Le Cœur du Modèle
C’est ici qu’intervient la fonction logistique, également appelée fonction sigmoïde. Elle a la propriété remarquable de transformer n’importe quelle valeur réelle (provenant de la combinaison linéaire de nos caractéristiques) en une valeur comprise strictement entre 0 et 1.
Sa formule mathématique est :
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]
Où \(z\) représente la sortie linéaire de nos caractéristiques pondérées par les coefficients du modèle : \(z = \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p\) (source: 771).
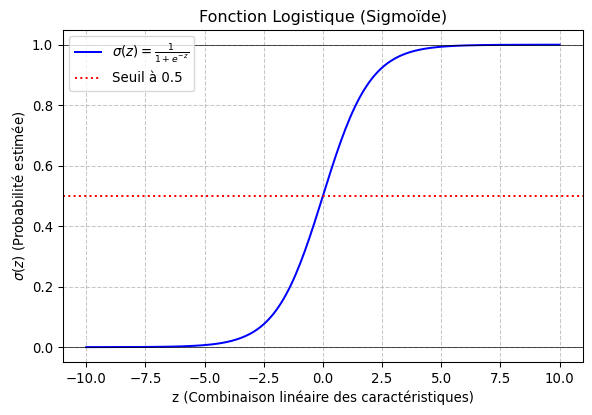
Visuellement, la fonction sigmoïde ressemble à ceci :
# Importations pour le graphiqueimport numpy as npimport matplotlib.pyplot as pltdef sigmoid(z):return1/ (1+ np.exp(-z))z_values = np.linspace(-10, 10, 200)sigma_values = sigmoid(z_values)plt.figure(figsize=(7, 4.5)) # Ajusté pour fig-width/heightplt.plot(z_values, sigma_values, label=r"$\sigma(z) = \frac{1}{1 + e^{-z}}$", color="blue")plt.title("Fonction Logistique (Sigmoïde)")plt.xlabel("z (Combinaison linéaire des caractéristiques)")plt.ylabel(r"$\sigma(z)$(Probabilité estimée)")plt.grid(True, linestyle='--', alpha=0.7)plt.axhline(y=0.5, color='red', linestyle=':', label="Seuil à 0.5")plt.axhline(y=0, color='black', linestyle='-', lw=0.5)plt.axhline(y=1, color='black', linestyle='-', lw=0.5)plt.legend()plt.show()
Visualisation de la fonction logistique (sigmoïde).
Comme on peut le voir, pour des valeurs de \(z\) très négatives, \(\sigma(z)\) tend vers 0. Pour des valeurs de \(z\) très positives, \(\sigma(z)\) tend vers 1. Et lorsque \(z=0\), \(\sigma(z)=0.5\).
3.1 Interprétation comme Probabilité
La sortie de cette fonction sigmoïde, \(\sigma(z)\), est interprétée en régression logistique comme la probabilité conditionnelle que l’observation \(X\) appartienne à la classe positive (généralement codée “1”), étant donné ses caractéristiques et les coefficients \(\beta\) du modèle :
Par exemple, si pour une observation donnée, le modèle calcule \(\sigma(\beta^T X) = 0.8\), cela signifie qu’il estime à 80% la probabilité que cette observation appartienne à la classe 1. Par conséquent, la probabilité d’appartenir à la classe 0 est de \(1 - 0.8 = 0.2\), soit 20%.
3.2 Le Lien avec les “Odds” : La Transformation Logit
La régression logistique ne modélise pas directement la probabilité \(P(Y=1|X)\) comme une fonction linéaire des \(x_j\). Au lieu de cela, elle modélise le logarithme de la cote (log-odds) de \(Y=1\) comme une fonction linéaire des \(x_j\).
La cote (odds) est définie comme le rapport de la probabilité qu’un événement se produise sur la probabilité qu’il ne se produise pas : \[
\text{Odds}(Y=1|X) = \frac{P(Y=1|X)}{P(Y=0|X)} = \frac{P(Y=1|X)}{1-P(Y=1|X)}
\]
Le logarithme de cette cote est appelé le logit : \[
\text{logit}(P(Y=1|X)) = \log\left(\frac{P(Y=1|X)}{1-P(Y=1|X)}\right)
\]
Et c’est cette quantité qui est modélisée linéairement : \[
\log\left(\frac{P(Y=1|X)}{1-P(Y=1|X)}\right) = \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p = \beta^T X.
\]
Si on résout cette équation pour \(P(Y=1|X)\), on retombe sur la formule avec la fonction sigmoïde.
4 Entraînement du Modèle : La Quête des Meilleurs Coefficients \(\beta\)
L’objectif de l’entraînement est de trouver les valeurs des coefficients \(\beta = (\beta_0, \beta_1, \dots, \beta_p)\) qui permettent au modèle de faire les meilleures prédictions possibles sur les données d’entraînement. Ce processus se déroule typiquement en deux étapes :
Définition d’une fonction de coût (ou de perte) : Cette fonction quantifie l’erreur entre les prédictions du modèle et les véritables étiquettes des données d’entraînement.
Optimisation : Un algorithme est utilisé pour ajuster les \(\beta\) de manière à minimiser cette fonction de coût.
4.1 La Fonction de Coût : Entropie Croisée (Log Loss)
Pour la régression logistique, la fonction de coût la plus couramment utilisée est l’Entropie Croisée Binaire, aussi appelée Log Loss. Pour une seule observation \((x_i, y_i)\), où \(y_i \in \{0, 1\}\) est la vraie étiquette et \(\hat{p}_i = P(Y=1|X=x_i)\) est la probabilité prédite par le modèle pour la classe 1, le coût est :
Sur l’ensemble des \(N\) observations d’entraînement, la fonction de coût globale \(L(\beta)\) que nous cherchons à minimiser est la moyenne de ces coûts individuels :
Le Log Loss a des propriétés intéressantes : - Si la vraie étiquette \(y_i=1\) et le modèle prédit une probabilité \(\hat{p}_i\) proche de 1 (bonne prédiction), alors \(y_i \log(\hat{p}_i) \approx \log(1) = 0\), et \((1-y_i) \log(1-\hat{p}_i) = 0\). Le coût est faible. - Si la vraie étiquette \(y_i=1\) mais le modèle prédit une probabilité \(\hat{p}_i\) proche de 0 (très mauvaise prédiction, et le modèle est confiant dans son erreur), alors \(y_i \log(\hat{p}_i) \approx \log(0) \to -\infty\). Le coût devient donc très élevé (\(-\log(0) \to \infty\)). Cette fonction pénalise donc lourdement les prédictions incorrectes faites avec une grande confiance.
4.2 Optimisation par Descente de Gradient
Contrairement à la régression linéaire ordinaire (OLS) qui a une solution analytique (une formule directe pour calculer les \(\beta\)), il n’existe pas de solution de forme fermée pour la régression logistique qui minimise le Log Loss.
À la place, on utilise des méthodes d’optimisation itératives. La plus connue est la descente de gradient. Son principe est le suivant : 1. Initialisation : On commence avec des valeurs initiales pour les coefficients \(\beta\) (par exemple, tous à zéro ou de petites valeurs aléatoires). 2. Calcul du Gradient : On calcule le gradient (la dérivée partielle) de la fonction de coût \(L(\beta)\) par rapport à chaque coefficient \(\beta_j\). Le gradient indique la direction de la plus forte augmentation du coût. 3. Mise à jour : On ajuste chaque \(\beta_j\) en se déplaçant dans la direction opposée au gradient, ce qui correspond à la direction de la plus forte diminution du coût. L’ampleur de ce déplacement est contrôlée par un “taux d’apprentissage” (learning rate). \[
\beta_j^{\text{nouveau}} = \beta_j^{\text{ancien}} - \text{taux\_apprentissage} \times \frac{\partial L(\beta)}{\partial \beta_j}
\]
Répétition : On répète les étapes 2 et 3 jusqu’à ce que les coefficients convergent (c’est-à-dire que le coût ne diminue plus de manière significative ou qu’un nombre maximal d’itérations est atteint).
La fonction de coût Log Loss est convexe, ce qui garantit que la descente de gradient convergera vers le minimum global (la meilleure solution possible). Le gradient de la log-vraisemblance (qui est l’opposé du Log Loss, à un facteur près) par rapport aux \(\beta\) pour l’ensemble des données est: \[
\nabla_{\beta} \text{LogVraisemblance} = \sum_{i=1}^{N} (y_i - \sigma(\beta^T x_i)) x_i
\]
Les solveurs des bibliothèques de Machine Learning implémentent des versions plus sophistiquées de la descente de gradient (ex: L-BFGS, liblinear, SAG, SAGA) pour une convergence plus rapide et plus stable.
5 Faire des Prédictions et Définir la Frontière de Décision
Une fois que le modèle est entraîné et que nous avons obtenu les coefficients \(\beta\) optimaux, faire une prédiction pour une nouvelle observation \(x_{\text{new}}\) est simple : 1. Calculer la combinaison linéaire : \(z_{\text{new}} = \beta^T x_{\text{new}}\). 2. Appliquer la fonction sigmoïde pour obtenir la probabilité : \(P(Y=1 | x_{\text{new}}) = \sigma(z_{\text{new}})\). 3. Prendre une décision de classification : Pour convertir cette probabilité en une prédiction de classe (0 ou 1), on utilise un seuil de décision. Par défaut, ce seuil est souvent fixé à 0.5 : - Si \(P(Y=1 | x_{\text{new}}) > 0.5\), alors on prédit la classe 1. - Sinon (si \(P(Y=1 | x_{\text{new}}) \le 0.5\)), on prédit la classe 0.
La frontière de décision est l’ensemble des points pour lesquels la probabilité prédite est exactement égale au seuil. Si le seuil est 0.5, cela correspond aux points où \(\sigma(\beta^T X) = 0.5\), ce qui implique \(\beta^T X = 0\). Puisque \(\beta^T X = \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p = 0\) est l’équation d’un hyperplan (une droite en 2D, un plan en 3D, etc.), la régression logistique produit toujours une frontière de décision linéaire dans l’espace des caractéristiques.
6 Tutoriel Pratique : Régression Logistique avec Python et Scikit-learn
Passons maintenant à un exemple concret d’implémentation de la régression logistique en utilisant Python et la populaire bibliothèque scikit-learn.
6.1 1. Préparation : Importations et Données
D’abord, importons les modules nécessaires et générons un jeu de données synthétiques adapté à la classification binaire.
# Importations essentiellesimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_curve, aucfrom sklearn.preprocessing import StandardScaler # Pour la mise à l'échellefrom sklearn.datasets import make_classification # Pour générer des données
Code
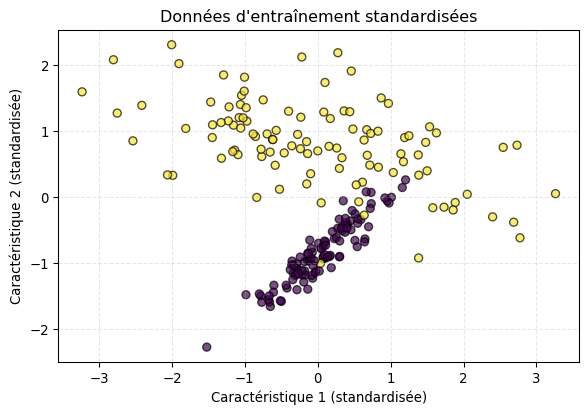
# Génération de donnéesX, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=42, n_clusters_per_class=1)# Division en ensembles d'entraînement et de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Mise à l'échelle des caractéristiques (Standardisation)# C'est une bonne pratique pour de nombreux algorithmes, y compris la régression logistique.scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# Visualisation des données d'entraînementplt.figure(figsize=(7, 4.5))plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=y_train, cmap='viridis', edgecolors='k', alpha=0.7)plt.title('Données d\'entraînement standardisées')plt.xlabel('Caractéristique 1 (standardisée)')plt.ylabel('Caractéristique 2 (standardisée)')plt.grid(True, linestyle='--', alpha=0.3)plt.show()
La standardisation (ou mise à l’échelle) des caractéristiques consiste à les transformer pour qu’elles aient une moyenne de 0 et un écart-type de 1. Cela aide souvent les algorithmes basés sur la descente de gradient à converger plus rapidement et plus sûrement.
6.2 2. Entraînement du Modèle
Nous allons maintenant créer une instance du modèle LogisticRegression et l’entraîner sur nos données d’entraînement mises à l’échelle.
Code
# Création et entraînement du modèle# Le paramètre 'C' est l'inverse de la force de régularisation (lambda).# Une plus petite valeur de C spécifie une régularisation plus forte.# 'solver' spécifie l'algorithme d'optimisation à utiliser.model = LogisticRegression(solver='liblinear', random_state=42, C=1.0) model.fit(X_train_scaled, y_train)print("Le modèle de régression logistique est entraîné.")print(f"Coefficients (betas) appris : {model.coef_}")print(f"Ordonnée à l'origine (beta_0) apprise : {model.intercept_}")
Le modèle de régression logistique est entraîné.
Coefficients (betas) appris : [[0.38142426 3.62346426]]
Ordonnée à l'origine (beta_0) apprise : [0.09854056]
scikit-learn applique une régularisation L2 par défaut à la régression logistique (contrôlée par le paramètre C). La régularisation aide à prévenir le sur-apprentissage, un concept détaillé au chapitre 6 de l’ouvrage “Introduction au Machine Learning” (source: 802).
6.3 3. Faire des Prédictions
Une fois le modèle entraîné, nous pouvons l’utiliser pour faire des prédictions sur de nouvelles données (notre ensemble de test X_test_scaled dans ce cas).
Code
# Prédictions sur l'ensemble de testy_pred_classes = model.predict(X_test_scaled) # Prédit les classes (0 ou 1)y_pred_probabilities = model.predict_proba(X_test_scaled)[:, 1] # Prédit les probabilités pour la classe 1print("Premières 5 prédictions de classe :", y_pred_classes[:5])print("Premières 5 probabilités prédites (pour la classe 1) :", np.round(y_pred_probabilities[:5], 3))
Premières 5 prédictions de classe : [0 1 1 0 1]
Premières 5 probabilités prédites (pour la classe 1) : [0.114 0.993 0.993 0.255 0.989]
La méthode predict() retourne directement la classe prédite (0 ou 1) en utilisant un seuil de 0.5 par défaut. La méthode predict_proba() retourne les probabilités pour chaque classe. Nous avons extrait ici la probabilité pour la classe 1.
6.4 4. Évaluation du Modèle
Il est crucial d’évaluer la performance de notre modèle pour savoir s’il généralise bien à des données qu’il n’a pas vues pendant l’entraînement (source: 367). Nous utiliserons plusieurs métriques courantes (détaillées au Chapitre 3 de l’ouvrage source: 363).
Code
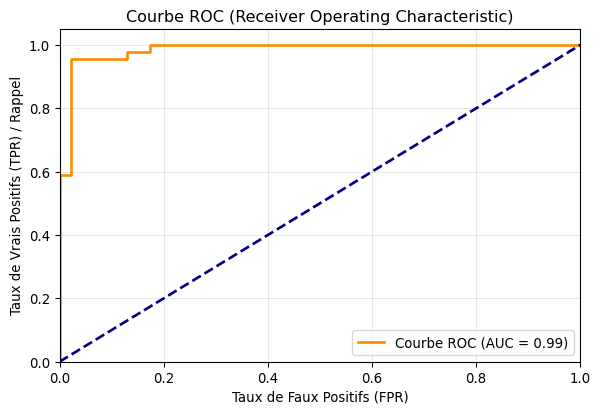
# Exactitude (Accuracy)accuracy = accuracy_score(y_test, y_pred_classes)print(f"Exactitude (Accuracy) du modèle : {accuracy:.4f}")# Matrice de Confusion (`source: 425`)print("\nMatrice de Confusion :")# TN | FP# FN | TPprint(confusion_matrix(y_test, y_pred_classes))# Rapport de Classification (Précision, Rappel, F1-score) (`source: 433`)print("\nRapport de Classification :")print(classification_report(y_test, y_pred_classes))# Courbe ROC et Aire sous la Courbe (AUC) (`source: 449, 451`)fpr, tpr, thresholds = roc_curve(y_test, y_pred_probabilities)roc_auc = auc(fpr, tpr)plt.figure(figsize=(7, 4.5))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'Courbe ROC (AUC = {roc_auc:.2f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # Ligne de référence (classifieur aléatoire)plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('Taux de Faux Positifs (FPR)')plt.ylabel('Taux de Vrais Positifs (TPR) / Rappel')plt.title('Courbe ROC (Receiver Operating Characteristic)')plt.legend(loc="lower right")plt.grid(alpha=0.3)plt.show()
Exactitude (Accuracy) du modèle : 0.9556
Matrice de Confusion :
[[44 2]
[ 2 42]]
Rapport de Classification :
precision recall f1-score support
0 0.96 0.96 0.96 46
1 0.95 0.95 0.95 44
accuracy 0.96 90
macro avg 0.96 0.96 0.96 90
weighted avg 0.96 0.96 0.96 90
Courbe ROC pour le modèle de régression logistique sur les données de test.
Ces métriques nous donnent une vue d’ensemble de la performance. L’exactitude est le pourcentage de prédictions correctes. La matrice de confusion détaille les vrais positifs, vrais négatifs, faux positifs et faux négatifs. Le rapport de classification fournit la précision (proportion de prédictions positives qui étaient correctes), le rappel (proportion d’instances positives réelles qui ont été correctement identifiées) et le F1-score (moyenne harmonique de la précision et du rappel) pour chaque classe. L’AUC (Area Under the ROC Curve) mesure la capacité du modèle à distinguer les classes ; un AUC de 1.0 est parfait, tandis qu’un AUC de 0.5 correspond à un classifieur aléatoire.
6.5 5. Visualisation de la Frontière de Décision (pour données 2D)
Si nos données ont seulement deux caractéristiques, nous pouvons visualiser la frontière de décision apprise par le modèle.
Code
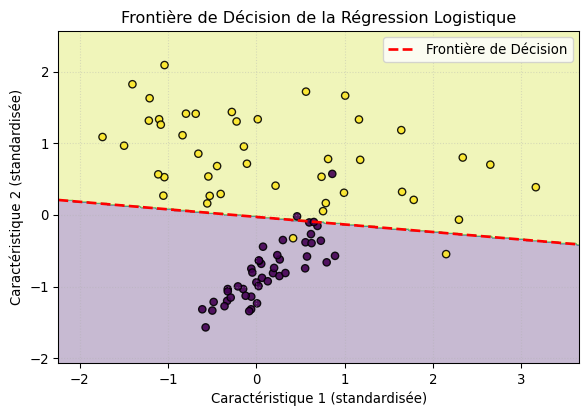
# S'assurer que X_train_scaled et y_train sont disponibles et que le modèle est entraînéif X_train_scaled.shape[1] ==2: # Uniquement si 2 caractéristiques x_min_vis, x_max_vis = X_test_scaled[:, 0].min() -0.5, X_test_scaled[:, 0].max() +0.5 y_min_vis, y_max_vis = X_test_scaled[:, 1].min() -0.5, X_test_scaled[:, 1].max() +0.5# Création d'une grille de points xx_vis, yy_vis = np.meshgrid(np.arange(x_min_vis, x_max_vis, 0.02), np.arange(y_min_vis, y_max_vis, 0.02))# Prédiction des classes pour chaque point de la grille Z_vis = model.predict(np.c_[xx_vis.ravel(), yy_vis.ravel()]) Z_vis = Z_vis.reshape(xx_vis.shape) plt.figure(figsize=(7, 4.5))# Affichage des régions de décision plt.contourf(xx_vis, yy_vis, Z_vis, alpha=0.3, cmap='viridis')# Affichage des points de l'ensemble de test plt.scatter(X_test_scaled[:, 0], X_test_scaled[:, 1], c=y_test, s=30, edgecolor='k', cmap='viridis', alpha=0.9)# Extraction des coefficients pour tracer la droite de décision# La droite est où beta0*x0 + beta1*x1 + intercept = 0# Donc x1 = (-intercept - beta0*x0) / beta1 coef = model.coef_[0] intercept = model.intercept_[0]# Création des points pour la ligne de décision# Attention si coef[1] est nul (droite verticale) ou coef[0] est nul (droite horizontale)ifabs(coef[1]) >1e-6: # Cas général line_x_vis = np.array([xx_vis.min(), xx_vis.max()]) line_y_vis = (-intercept - coef[0] * line_x_vis) / coef[1] plt.plot(line_x_vis, line_y_vis, 'r--', lw=2, label="Frontière de Décision")elifabs(coef[0]) >1e-6: # Droite verticale line_y_vis = np.array([yy_vis.min(), yy_vis.max()]) line_x_vis = (-intercept - coef[1] * line_y_vis) / coef[0] # devrait être -intercept / coef[0] plt.plot(line_x_vis, line_y_vis, 'r--', lw=2, label="Frontière de Décision") plt.title('Frontière de Décision de la Régression Logistique') plt.xlabel('Caractéristique 1 (standardisée)') plt.ylabel('Caractéristique 2 (standardisée)')if'line_x_vis'inlocals() or'line_y_vis'inlocals(): # Ajouter la légende seulement si la ligne a été tracée plt.legend() plt.grid(True, linestyle=':', alpha=0.4) plt.show()else:print("La visualisation de la frontière de décision n'est affichée que pour 2 caractéristiques.")
Frontière de décision linéaire apprise par la régression logistique sur les données de test.
La ligne rouge pointillée représente la frontière où le modèle est incertain (probabilité de 0.5). Les points d’un côté sont classés comme une classe, et ceux de l’autre côté comme l’autre classe. On voit bien ici le caractère linéaire de cette frontière.
7 Forces et Faiblesses de la Régression Logistique
7.1 Avantages
Interprétabilité : Les coefficients \(\beta_j\) peuvent être interprétés en termes d’impact sur le log-odds de la classe positive. Un \(\beta_j\) positif signifie que l’augmentation de \(x_j\) augmente le log-odds (et donc la probabilité) d’être dans la classe 1, et inversement pour un \(\beta_j\) négatif. L’ampleur du coefficient indique la force de cet impact.
Sortie Probabiliste : Le modèle ne se contente pas de prédire une classe, il fournit également une probabilité d’appartenance à cette classe. C’est très utile dans de nombreux contextes (ex: trier les clients par probabilité d’achat).
Efficacité Computationnelle : La régression logistique est relativement rapide à entraîner, même sur des jeux de données volumineux, surtout avec les solveurs optimisés.
Bonnes Performances de Base : Elle constitue souvent un excellent point de départ et peut être difficile à battre si la relation sous-jacente est effectivement (approximativement) linéaire.
Moins Sujette au Sur-apprentissage que des Modèles Plus Complexes (si régularisée) : Avec la régularisation (comme L1 ou L2, implicite dans scikit-learn via le paramètre C), on peut contrôler la complexité du modèle.
7.2 Inconvénients
Hypothèse de Linéarité : La principale limitation est que la régression logistique suppose que la frontière de décision entre les classes est linéaire dans l’espace des caractéristiques (ou, de manière équivalente, que le log-odds est une fonction linéaire des caractéristiques). Si la relation réelle est fortement non linéaire, la régression logistique ne pourra pas la capturer efficacement.
Performance Limitée sur des Problèmes Complexes : Pour des problèmes avec des frontières de décision complexes, d’autres algorithmes (comme les SVM avec noyaux, les arbres de décision, ou les réseaux de neurones) peuvent offrir de meilleures performances.
Sensibilité à la Multicolinéarité : Si les caractéristiques sont fortement corrélées entre elles, l’interprétation des coefficients individuels peut devenir difficile et les estimations des coefficients peuvent être instables.
Peut Nécessiter une Préparation des Données : Bien que robuste, la mise à l’échelle des caractéristiques est souvent recommandée, et la création de termes d’interaction ou polynomiaux peut être nécessaire pour capturer certaines non-linéarités (mais cela complexifie le modèle).
8 Conclusion
La régression logistique est un algorithme de classification binaire puissant, efficace et largement utilisé. Sa capacité à fournir des probabilités et l’interprétabilité de ses coefficients en font un outil précieux dans la boîte à outils du data scientist. Bien qu’elle repose sur une hypothèse de linéarité de la frontière de décision, elle constitue souvent une excellente ligne de base pour les problèmes de classification et est un concept fondamental à maîtriser avant de s’aventurer vers des modèles plus complexes.
En comprenant ses mécanismes, de la fonction sigmoïde à l’optimisation par descente de gradient et à l’évaluation de ses performances, vous êtes désormais mieux équipé pour l’appliquer judicieusement à vos propres problèmes de classification.