Ce tutoriel explore la régression linéaire multiple, une technique statistique fondamentale utilisée pour modéliser la relation entre une variable dépendante (ou réponse) et plusieurs variables indépendantes (ou prédicteurs).
1 Le Modèle de Régression Linéaire Multiple
1.1 Définition
Soit un jeu de données \(\mathcal{D}_n=\left\{(x_i, y_i)\right\}_{i=1}^n\), où \(y_i \in \mathbb{R}\) est la variable réponse pour l’observation \(i\), et \(x_i = (x_{i,1}, x_{i,2}, ..., x_{i,p})^T \in \mathbb{R}^p\) est le vecteur des \(p\) variables prédictives pour cette même observation.
Le modèle de régression linéaire multiple postule une relation linéaire entre la réponse \(Y\) et les prédicteurs \(X_1, ..., X_p\) :
\(Y_i\) est la valeur de la variable dépendante pour la \(i\)-ème observation.
\(x_{i,j}\) est la valeur de la \(j\)-ème variable indépendante pour la \(i\)-ème observation.
\(\beta_0\) est l’ordonnée à l’origine (intercept).
\(\beta_j\) (pour \(j=1, ..., p\)) sont les coefficients de régression associés aux variables \(X_j\). Ils représentent le changement moyen de \(Y\) pour une augmentation d’une unité de \(X_j\), en maintenant les autres variables constantes.
\(\epsilon_i\) est le terme d’erreur aléatoire pour la \(i\)-ème observation, représentant la variabilité non expliquée par le modèle.
1.2 Forme Matricielle
Il est souvent plus pratique d’écrire le modèle sous forme matricielle. En considérant les \(n\) observations :
\[Y = X\beta + \epsilon \tag{2}\]
où :
\(Y = (y_1, ..., y_n)^T\) est le vecteur des réponses (\(n \times 1\)).
\(X\) est la matrice de design (\(n \times (p+1)\)). La première colonne est constituée de 1 (pour l’intercept \(\beta_0\)), et les colonnes suivantes contiennent les valeurs des prédicteurs : \[
X = \begin{pmatrix}
1 & x_{1,1} & \cdots & x_{1,p} \\
1 & x_{2,1} & \cdots & x_{2,p} \\
\vdots & \vdots & \ddots & \vdots \\
1 & x_{n,1} & \cdots & x_{n,p}
\end{pmatrix}
\]
\(\beta = (\beta_0, \beta_1, ..., \beta_p)^T\) est le vecteur des paramètres inconnus à estimer (\((p+1) \times 1\)).
\(\epsilon = (\epsilon_1, ..., \epsilon_n)^T\) est le vecteur des erreurs aléatoires (\(n \times 1\)).
1.3 Hypothèses du Modèle (Hypothèses de Gauss-Markov)
Pour que l’estimateur des moindres carrés (présenté ci-dessous) ait de bonnes propriétés (notamment être le Meilleur Estimateur Linéaire Sans Biais - BLUE), les hypothèses suivantes sont généralement requises :
Linéarité : La relation entre \(Y\) et les \(X_j\) est linéaire, comme spécifié par l’équation du modèle Equation 1.
Moyenne des erreurs nulle :\(E[\epsilon_i] = 0\) pour tout \(i\). Les erreurs sont centrées autour de zéro.
Homoscédasticité : La variance des erreurs est constante pour toutes les observations : \(Var(\epsilon_i) = \sigma^2\) pour tout \(i\).
Non-corrélation des erreurs : Les erreurs associées à différentes observations ne sont pas corrélées : \(Cov(\epsilon_i, \epsilon_k) = 0\) pour \(i \neq k\).
Pas de multicolinéarité parfaite : Aucune variable prédictive ne peut être écrite comme une combinaison linéaire exacte des autres. Mathématiquement, cela signifie que la matrice \(X^T X\) est inversible (ou que les colonnes de \(X\) sont linéairement indépendantes).
(Optionnel, pour l’inférence)Normalité des erreurs : Les erreurs \(\epsilon_i\) suivent une distribution normale : \(\epsilon_i \sim \mathcal{N}(0, \sigma^2)\). Cette hypothèse est nécessaire pour construire des intervalles de confiance et effectuer des tests d’hypothèses sur les coefficients \(\beta_j\).
1.4 Paramètres à Estimer
Les principaux paramètres à estimer sont :
Le vecteur des coefficients de régression : \(\beta = (\beta_0, \beta_1, ..., \beta_p)^T\).
La variance des erreurs : \(\sigma^2\).
2 Estimateur des Moindres Carrés Ordinaires (MCO)
L’idée de la méthode des moindres carrés est de trouver les valeurs des coefficients \(\beta\) qui minimisent la somme des carrés des résidus (les différences entre les valeurs observées \(y_i\) et les valeurs prédites par le modèle \(\hat{y}_i = x_i^T \beta\)).
La somme des carrés des résidus (Sum of Squared Residuals - SSR) est donnée par :
Pour minimiser \(SSR(\beta)\), on calcule le gradient par rapport à \(\beta\) et on l’égale au vecteur nul :
\[\nabla_\beta SSR(\beta) = \nabla_\beta (Y^T Y - 2 Y^T X \beta + \beta^T X^T X \beta) = -2 X^T Y + 2 X^T X \beta\]
En posant \(\nabla_\beta SSR(\beta) = 0\) :
\[-2 X^T Y + 2 X^T X \beta = 0 \implies X^T X \beta = X^T Y\]
Si la matrice \(X^T X\) est inversible (hypothèse 5), on peut isoler \(\beta\) pour obtenir l’estimateur MCO, noté \(\hat{\beta}\):
\[\hat{\beta} = (X^T X)^{-1} X^T Y \tag{5}\]
2.1 Avantages du MCO
Solution Analytique : Il existe une formule explicite (fermée) pour \(\hat{\beta}\)Equation 5, ce qui évite le recours à des méthodes itératives (si \(X^T X\) est inversible et pas trop grande).
Propriétés Théoriques : Sous les hypothèses de Gauss-Markov (1-5), \(\hat{\beta}\) est le Meilleur Estimateur Linéaire Sans Biais (BLUE - Best Linear Unbiased Estimator). Il est sans biais (\(E[\hat{\beta}] = \beta\)) et a la variance la plus faible parmi tous les estimateurs linéaires sans biais.
Interprétabilité : Les coefficients \(\hat{\beta}_j\) ont une interprétation directe en termes de changement de la variable réponse.
2.2 Inconvénients du MCO
Sensibilité aux valeurs aberrantes (Outliers) : La minimisation des carrés des résidus donne beaucoup de poids aux observations éloignées de la tendance générale.
Problème de Multicolinéarité : Si les variables prédictives sont fortement corrélées entre elles (multicolinéarité forte, mais pas parfaite), la matrice \(X^T X\) est proche d’être singulière (non inversible). L’inversion numérique devient instable, conduisant à des estimations de \(\beta\) avec une grande variance (erreurs standards élevées) et difficiles à interpréter. En cas de multicolinéarité parfaite, \(X^T X\) n’est pas inversible et la solution MCO n’existe pas.
Coût Computationnel : Le calcul de \((X^T X)^{-1}\) a une complexité cubique par rapport au nombre de prédicteurs \(p\) (environ \(O(p^3)\)). Si \(p\) est très grand (milliers ou millions), cette inversion devient prohibitive. Le calcul nécessite également de stocker la matrice \(X\) en mémoire (\(n \times p\)).
3 Algorithme de la Descente de Gradient
Lorsque le calcul direct de \(\hat{\beta}\)Equation 5 est impossible ou trop coûteux (par exemple, si \(p\) est très grand), on peut utiliser des méthodes itératives comme la descente de gradient pour trouver les coefficients \(\beta\) qui minimisent la fonction de coût \(SSR(\beta)\)Equation 4.
3.1 Fonction de Coût
On utilise souvent une version normalisée de la SSR comme fonction de coût (Cost Function) \(J(\beta)\), par exemple l’erreur quadratique moyenne (Mean Squared Error - MSE) divisée par 2 pour simplifier le gradient :
Ce gradient indique la direction de la plus forte pente ascendante de la fonction de coût. Pour minimiser \(J(\beta)\), on doit se déplacer dans la direction opposée au gradient.
3.3 Algorithme
L’algorithme de la descente de gradient est itératif :
Initialisation : Choisir une valeur initiale pour le vecteur \(\beta\), souvent \(\beta^{(0)} = \vec{0}\). Choisir un taux d’apprentissage (learning rate) \(\alpha > 0\) et un critère d’arrêt (nombre d’itérations max, ou seuil de changement de \(J(\beta)\)).
Mettre à jour les coefficients : \(\beta^{(k+1)} = \beta^{(k)} - \alpha \nabla J(\beta^{(k)})\)
Arrêt : L’algorithme s’arrête lorsque le critère d’arrêt est satisfait. La dernière valeur \(\beta^{(k+1)}\) est l’approximation des coefficients optimaux.
3.4 Taux d’Apprentissage (\(\alpha\))
Le choix de \(\alpha\) est crucial :
Si \(\alpha\) est trop petit, la convergence sera très lente.
Si \(\alpha\) est trop grand, l’algorithme peut osciller autour du minimum, voire diverger.
3.5 Quand utiliser la Descente de Gradient ?
Grand nombre de prédicteurs (\(p\)) : Lorsque l’inversion de \(X^T X\) (\(O(p^3)\)) est trop coûteuse. Le calcul du gradient à chaque étape (\(O(np)\)) peut être plus efficace.
Très grand nombre d’observations (\(n\)) : Des variantes comme la Descente de Gradient Stochastique (SGD) ou Mini-Batch peuvent être utilisées.
SGD : Met à jour \(\beta\) en utilisant le gradient calculé sur une seule observation à la fois. Plus rapide par itération, mais convergence plus bruitée.
Mini-Batch GD : Met à jour \(\beta\) en utilisant le gradient calculé sur un petit sous-ensemble (batch) d’observations. Compromis entre la descente de gradient classique (Batch GD) et SGD.
4 Lien avec le Perceptron
Le perceptron est un algorithme d’apprentissage supervisé pour la classification binaire. Il est l’un des plus anciens algorithmes de neurones artificiels.
Similarité : Comme la régression linéaire, le perceptron calcule d’abord une combinaison linéaire des entrées \(x_i\) avec des poids \(w\) (analogues aux \(\beta_j\)) et un biais \(b\) (analogue à \(\beta_0\)) : \(z = w^T x + b\).
Différence : La sortie du perceptron n’est pas la valeur \(z\) directement. Elle passe par une fonction d’activation, typiquement une fonction de Heaviside (ou fonction signe), qui transforme \(z\) en une sortie binaire (+1 ou -1, ou 1 ou 0) représentant la classe prédite. \[\hat{y} = \text{sign}(z)\]
Objectif : La régression linéaire minimise l’erreur quadratique Equation 6 (continue). Le perceptron (dans sa version originale) vise à trouver un hyperplan qui sépare linéairement les données, et son algorithme d’apprentissage ajuste les poids uniquement lorsqu’une erreur de classification est commise.
En résumé, bien que les deux modèles utilisent une combinaison linéaire des entrées, la régression linéaire prédit une valeur continue en minimisant les erreurs quadratiques, tandis que le perceptron prédit une classe discrète via une fonction d’activation et utilise une règle de mise à jour différente axée sur la correction des erreurs de classification. La descente de gradient sur l’erreur quadratique (régression) est différente de l’algorithme d’apprentissage du perceptron.
5 Application sur un Jeu de Données (avec Python)
Illustrons la régression linéaire multiple avec scikit-learn sur des données synthétiques. Nous allons générer des données où la relation est connue, puis voir si le modèle retrouve les bons coefficients.
Code
# Import necessary librariesimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_error, r2_scoreimport warnings# Suppress specific warnings for cleaner output (optional)warnings.filterwarnings('ignore', category=FutureWarning)# --- 1. Generate Synthetic Data ---np.random.seed(42) # for reproducibilityn_samples =100n_features =3# Generate features (predictors)X = np.random.rand(n_samples, n_features) *10# Features between 0 and 10# Define true coefficients (including intercept)true_beta = np.array([5.0, 2.0, -3.0, 1.5])# Create the design matrix X_b with intercept columnX_b = np.c_[np.ones((n_samples, 1)), X]# Generate the response variable Y with noisenoise_std_dev =2.0noise = np.random.randn(n_samples) * noise_std_devy = X_b.dot(true_beta) + noise# --- 2. Split Data ---X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# --- 3. Train Model ---model = LinearRegression(fit_intercept=True)model.fit(X_train, y_train)# --- 4. Get Coefficients ---estimated_intercept = model.intercept_estimated_coeffs = model.coef_print(f"True Intercept (beta_0): {true_beta[0]}")print(f"Estimated Intercept: {estimated_intercept:.4f}")print("-"*30)print(f"True Coefficients (beta_1 to beta_p): {true_beta[1:]}")print(f"Estimated Coefficients: {np.round(estimated_coeffs, 4)}")print("-"*30)# --- 5. Make Predictions ---y_pred = model.predict(X_test)# --- 6. Evaluate Model ---mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(f"Mean Squared Error (MSE) on test set: {mse:.4f}")print(f"R-squared (R2) score on test set: {r2:.4f}")print("-"*30)# --- 7. Visualization ---plt.figure(figsize=(8, 6))plt.scatter(y_test, y_pred, alpha=0.7, edgecolors='k', label='Prédictions')min_val =min(min(y_test), min(y_pred))max_val =max(max(y_test), max(y_pred))plt.plot([min_val, max_val], [min_val, max_val], '--r', lw=2, label='Idéal (y=x)')plt.xlabel("Valeurs Réelles (y_test)")plt.ylabel("Valeurs Prédites (y_pred)")plt.title("Valeurs Réelles vs. Prédites pour la Régression Linéaire")plt.legend()plt.grid(True)plt.axis('equal')plt.tight_layout()plt.show()
True Intercept (beta_0): 5.0
Estimated Intercept: 4.8300
------------------------------
True Coefficients (beta_1 to beta_p): [ 2. -3. 1.5]
Estimated Coefficients: [ 2.0212 -3.0151 1.6372]
------------------------------
Mean Squared Error (MSE) on test set: 8.0696
R-squared (R2) score on test set: 0.9321
------------------------------
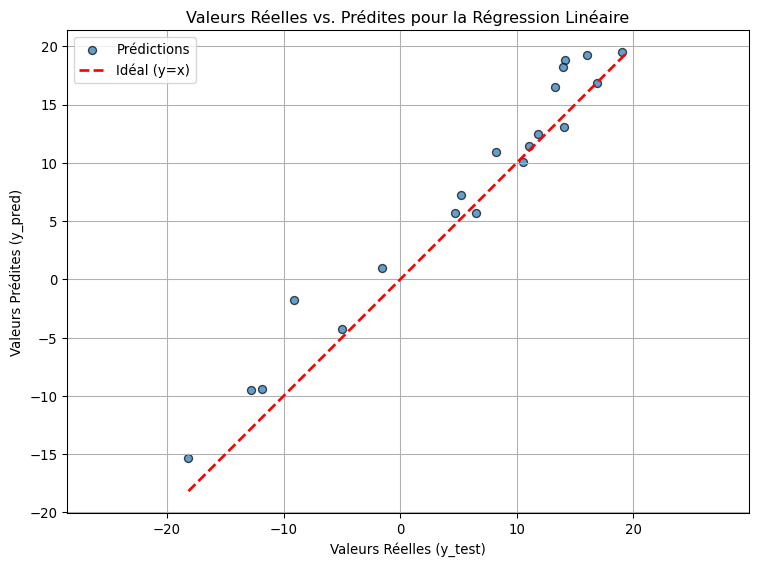
Figure 1: Comparaison des valeurs réelles et prédites par le modèle de régression linéaire.
5.1 Interprétation des résultats de l’exemple
Les coefficients estimés par le modèle (estimated_intercept et estimated_coeffs) devraient être proches des vrais coefficients (true_beta) que nous avons utilisés pour générer les données. Les petites différences sont dues au bruit aléatoire ajouté.
Le MSE mesure l’erreur quadratique moyenne des prédictions sur l’ensemble de test. Une valeur plus faible indique un meilleur ajustement.
Le R-squared (\(R^2\)) mesure la proportion de la variance de la variable dépendante qui est expliquée par le modèle. Une valeur proche de 1 indique que le modèle explique une grande partie de la variabilité des données.
Le graphique Figure 1 montre la qualité des prédictions. Si les points sont proches de la ligne rouge (y=x), cela signifie que les prédictions sont proches des valeurs réelles.
6 6. Conclusion
La régression linéaire multiple est un outil puissant et largement utilisé pour modéliser des relations linéaires entre une variable réponse et plusieurs prédicteurs.
Le modèle est défini par une équation linéaire Equation 1 et repose sur des hypothèses clés (Gauss-Markov) pour garantir les bonnes propriétés de l’estimateur.
L’estimateur des moindres carrés ordinaires (MCO) fournit une solution analytique Equation 5 pour les coefficients \(\beta\), mais peut être sensible aux outliers, à la multicolinéarité et coûteux pour un très grand nombre de prédicteurs.
L’algorithme de la descente de gradient offre une alternative itérative pour estimer les coefficients, particulièrement utile lorsque \(p\) est grand ou pour des applications en ligne (avec SGD/Mini-Batch).
Bien qu’utilisant une combinaison linéaire des entrées comme le perceptron, la régression linéaire se distingue par sa sortie continue et son objectif de minimisation de l’erreur quadratique Equation 6, tandis que le perceptron est un classifieur binaire avec une fonction d’activation et une règle d’apprentissage différente.
Le choix de la méthode d’estimation (MCO ou Descente de Gradient) dépendra de la taille du jeu de données, du nombre de prédicteurs et des contraintes computationnelles. L’évaluation du modèle (via MSE, R², analyse des résidus) est essentielle pour valider son adéquation et sa performance.
7 Quiz
7.1 Question 1
Quelle est la forme générale du modèle de régression linéaire multiple ?
7.2 Question 2
Dans le contexte de la régression linéaire multiple, que représente \(\beta_0\) ?
7.3 Question 3
Quelle est l’interprétation d’un coefficient de régression \(\beta_j\) dans un modèle de régression linéaire multiple ?
7.4 Question 4
Quelle est la forme matricielle du modèle de régression linéaire multiple ?
7.5 Question 5
Laquelle de ces hypothèses N’EST PAS une hypothèse classique du modèle de régression linéaire pour que l’estimateur MCO soit BLUE ?
7.6 Question 6
Quelle est la formule de l’estimateur des Moindres Carrés Ordinaires (MCO) pour \(\hat{\beta}\) ?
7.7 Question 7
Quel est l’un des principaux inconvénients de l’estimateur MCO ?
7.8 Question 8
Dans l’algorithme de la descente de gradient pour la régression linéaire, que se passe-t-il si le taux d’apprentissage (\(\alpha\)) est trop grand ?
7.9 Question 9
Quand est-il particulièrement pertinent d’utiliser la descente de gradient plutôt que la solution MCO directe pour la régression linéaire ?
7.10 Question 10
Quelle est une différence clé entre la régression linéaire et le perceptron ?
7.11 Question 11
Quelle est la conséquence principale de la violation de l’hypothèse d’homoscédasticité (variance constante des erreurs) dans la régression linéaire ?
7.12 Question 12
Que signifie l’acronyme “BLUE” pour l’estimateur MCO sous les hypothèses de Gauss-Markov ?
7.13 Question 13
Comment la variance des erreurs \(\sigma^2\) est-elle typiquement estimée dans un modèle de régression linéaire ?
7.14 Question 14
Si une multicolinéarité parfaite existe entre deux prédicteurs dans un modèle de régression linéaire, quelle en est la conséquence pour l’estimateur MCO ?
7.15 Question 15
Quelle est la principale différence entre la Descente de Gradient Stochastique (SGD) et la Descente de Gradient par Batch (classique) ?
7.16 Question 16
Dans la descente de gradient pour la régression linéaire, quel est le rôle principal de la fonction de coût \(J(\beta)\) (par exemple, MSE) ?
7.17 Question 17
Qu’est-ce que le coefficient de détermination \(R^2\) mesure dans le contexte de la régression linéaire ?
7.18 Question 18
Que sont les résidus dans un modèle de régression linéaire ?
7.19 Question 19
Une analyse graphique des résidus (par exemple, résidus vs. valeurs prédites) peut être utilisée pour vérifier principalement lesquelles des hypothèses suivantes du modèle de régression linéaire ?
7.20 Question 20
Quelle est l’interprétation géométrique de la solution des Moindres Carrés Ordinaires (MCO) pour \(\hat{Y} = X\hat{\beta}\) ?