# Importations
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler1 Introduction : Une Approche Générative de la Classification
Après avoir exploré la régression logistique, une méthode discriminative pour la classification binaire, nous allons nous pencher sur une autre famille d’algorithmes : les modèles génératifs. L’Analyse Discriminante Gaussienne (GDA) est un exemple classique de cette approche.
Contrairement aux modèles discriminatifs qui apprennent directement une frontière de décision ou la probabilité \(P(Y|X)\) (probabilité de la classe \(Y\) étant donné les caractéristiques \(X\)), les modèles génératifs s’attachent à modéliser la distribution de chaque classe. Plus précisément, ils apprennent :
- La distribution des caractéristiques \(X\) pour chaque classe \(Y=k\), soit \(p(x|Y=k)\) (la vraisemblance).
- La probabilité a priori de chaque classe \(P(Y=k)\) (le prior).
Une fois ces distributions apprises, ils utilisent le théorème de Bayes pour calculer la probabilité a posteriori \(P(Y=k|X)\) et ainsi effectuer la classification.
Dans ce tutoriel, nous allons : - Comprendre le cadre probabiliste de GDA basé sur le théorème de Bayes. - Explorer l’hypothèse gaussienne pour les distributions conditionnelles de classe. - Détailler comment les paramètres du modèle (moyennes, covariances, priors) sont estimés. - Distinguer l’Analyse Discriminante Linéaire (LDA) et l’Analyse Discriminante Quadratique (QDA). - Mettre en œuvre LDA et QDA en Python avec scikit-learn. - Discuter des avantages, inconvénients et cas d’usage de ces méthodes.
2 Le Cadre Probabiliste : Le Théorème de Bayes au Service de la Classification
Le théorème de Bayes est la pierre angulaire de l’Analyse Discriminante Gaussienne. Pour un problème de classification où nous voulons prédire la classe \(Y=k\) pour une observation \(X\), le théorème s’énonce ainsi (source: 545):
\[ P(Y=k | X = x) = \dfrac{p(x | Y=k) P(Y=k)}{p(x)} \]
Décortiquons les termes :
- \(P(Y=k | X=x)\) : Probabilité a posteriori. C’est la probabilité que l’observation appartienne à la classe \(k\), après avoir observé ses caractéristiques \(X=x\). C’est ce que nous voulons calculer pour prendre une décision.
- \(p(x | Y=k)\) : Vraisemblance (Likelihood). C’est la probabilité ou la densité de probabilité des caractéristiques \(x\), sachant que l’observation appartient à la classe \(k\). C’est ce que GDA va modéliser avec une distribution gaussienne.
- \(P(Y=k)\) : Probabilité a priori (Prior). C’est la probabilité qu’une observation appartienne à la classe \(k\) avant même d’avoir regardé ses caractéristiques. Par exemple, si nous savons que 70% des emails sont des spams, \(P(Y=\text{spam})=0.7\). (
source: 546) - \(p(x)\) : Évidence (Evidence) ou Probabilité Marginale de X. C’est la probabilité globale d’observer les caractéristiques \(X\). Elle se calcule par : \(p(x) = \sum_k p(x | Y=k) P(Y=k)\) (sommation sur toutes les classes possibles \(j\)).
Pour la classification, une fois que nous avons \(P(Y=k|X=x)\) pour chaque classe \(k\), nous choisissons la classe qui maximise cette probabilité a posteriori. C’est la règle de décision du Maximum A Posteriori (MAP). Notez que puisque \(p(x)\) est le même pour toutes les classes lors de la comparaison, on peut se contenter de maximiser le numérateur \(p(x | Y=k) P(Y=k)\).
3 L’Hypothèse Gaussienne pour \(p(x|Y=k)\)
L’Analyse Discriminante Gaussienne tire son nom de l’hypothèse fondamentale qu’elle fait sur la distribution de vraisemblance \(p(x|Y=k)\) : elle suppose que pour chaque classe \(k\), les caractéristiques \(X\) suivent une distribution Gaussienne (ou Normale) multidimensionnelle.
Une distribution Gaussienne multidimensionnelle pour un vecteur \(X\) de dimension \(D\) est caractérisée par : - Un vecteur moyen \(\mu_k \in \mathbb{R}^D\) (le centre de la distribution pour la classe \(k\)). - Une matrice de covariance \(\Sigma_k \in \mathbb{R}^{D \times D}\) (qui décrit la forme et l’orientation de la “cloche” et les corrélations entre les caractéristiques pour la classe \(k\)).
La fonction de densité de probabilité (PDF) d’une Gaussienne multidimensionnelle est : \[ p(x | Y=k; \mu_k, \Sigma_k) = \dfrac{1}{(2\pi)^{D/2} |\Sigma_k|^{1/2}} \exp\left(-\dfrac{1}{2}(X-\mu_k)^T \Sigma_k^{-1} (X-\mu_k)\right) \]
Où \(|\Sigma_k|\) est le déterminant de la matrice de covariance \(\Sigma_k\), et \(\Sigma_k^{-1}\) est son inverse.
Important
L’hypothèse clé de GDA : Pour chaque classe \(k\), les données \(X\) sont générées par une distribution \(\mathcal{N}(\mu_k, \Sigma_k)\).
4 Estimation des Paramètres du Modèle
Pour utiliser GDA, nous devons estimer les paramètres suivants à partir de nos données d’entraînement \(\{(x_i, y_i)\}_{i=1}^N\):
Les probabilités a priori \(\phi_k = P(Y=k)\) : L’estimateur du maximum de vraisemblance (MLE) pour \(\phi_k\) est simplement la proportion d’échantillons appartenant à la classe \(k\) dans l’ensemble d’entraînement. Si \(N_k\) est le nombre d’échantillons de la classe \(k\) et \(N\) le nombre total d’échantillons : \[ \hat{\phi}_k = \frac{N_k}{N} \]
Les vecteurs moyens \(\mu_k\) pour chaque classe \(k\) : Le MLE pour \(\mu_k\) est la moyenne empirique des échantillons appartenant à la classe \(k\): \[ \hat{\mu}_k = \frac{1}{N_k} \sum_{i \text{ t.q. } y_i=k} x_i \]
Les matrices de covariance \(\Sigma_k\) (ou la matrice \(\Sigma\) partagée) : C’est ici que les variantes de GDA (LDA et QDA) se distinguent.
Pour QDA (Analyse Discriminante Quadratique) : Chaque classe \(k\) a sa propre matrice de covariance \(\Sigma_k\). Le MLE est la covariance empirique des échantillons de la classe \(k\): \[ \hat{\Sigma}_k = \frac{1}{N_k} \sum_{i \text{ t.q. } y_i=k} (x_i - \hat{\mu}_k)(x_i - \hat{\mu}_k)^T \]
(Note: Pour un estimateur non biaisé, on divise par \(N_k-1\), mais pour de grands \(N_k\), la différence est minime.
scikit-learnutilise \(N_k\).)Pour LDA (Analyse Discriminante Linéaire) : Toutes les classes partagent la même matrice de covariance \(\Sigma\). Le MLE pour \(\Sigma\) est une moyenne pondérée des covariances individuelles, ou plus simplement, la covariance calculée sur l’ensemble des données après centrage par rapport à la moyenne de leur classe respective : \[ \hat{\Sigma} = \frac{1}{N} \sum_{k=1}^{K} \sum_{i \text{ t.q. } y_i=k} (x_i - \hat{\mu}_k)(x_i - \hat{\mu}_k)^T \]
ou une version non biaisée (souvent utilisée) : \[ \hat{\Sigma} = \frac{1}{N-K} \sum_{k=1}^{K} (N_k-1)\hat{\Sigma}_k^{\text{indiv}} \]
où \(\hat{\Sigma}_k^{\text{indiv}}\) est la covariance de la classe \(k\) calculée avec \(1/(N_k-1)\).
scikit-learnutilise la première formulation (pondérée par \(N_k/N\)).
Ces estimations sont basées sur le principe du maximum de vraisemblance (MLE), qui cherche les valeurs des paramètres qui maximisent la probabilité d’observer les données d’entraînement.
5 Analyse Discriminante Linéaire (LDA)
LDA fait l’hypothèse (parfois forte) que toutes les classes partagent la même matrice de covariance : \(\Sigma_k = \Sigma\) pour toutes les classes \(k\).
Conséquence sur la frontière de décision : Quand on compare les log-probabilités a posteriori pour deux classes \(k\) et \(l\) (ce qui revient à comparer \(p(x|Y=k)P(Y=k)\) et \(p(x|Y=l)P(Y=l)\)), les termes quadratiques en \(X\) (ceux impliquant \(X^T \Sigma^{-1} X\)) s’annulent car \(\Sigma\) est la même. Il ne reste que des termes linéaires en \(X\). Ainsi, la frontière de décision entre deux classes quelconques est linéaire.
Intuitivement, LDA cherche à trouver une projection des données sur un sous-espace de dimension inférieure (si \(K > 2\)) telle que la séparabilité entre les classes soit maximisée, tout en minimisant la variance à l’intérieur de chaque classe.
6 Analyse Discriminante Quadratique (QDA)
QDA est plus flexible que LDA car elle permet à chaque classe \(k\) d’avoir sa propre matrice de covariance \(\Sigma_k\).
Conséquence sur la frontière de décision : Avec des \(\Sigma_k\) différentes, les termes quadratiques en \(X\) ne s’annulent plus lors de la comparaison des log-probabilités a posteriori. La frontière de décision entre les classes devient quadratique (paraboles, hyperboles, ellipses). Cela permet à QDA de capturer des formes de classes plus complexes et des orientations différentes pour chaque classe.
Note
Plus de flexibilité, mais un coût : QDA a plus de paramètres à estimer que LDA (une matrice de covariance complète pour chaque classe au lieu d’une seule partagée). Elle est donc plus sujette au sur-apprentissage si le nombre d’échantillons par classe n’est pas suffisamment grand par rapport au nombre de caractéristiques.
7 Faire des Prédictions avec GDA
Une fois les paramètres \(\hat{\phi}_k\), \(\hat{\mu}_k\), et \(\hat{\Sigma}_k\) (ou \(\hat{\Sigma}\)) estimés : 1. Pour une nouvelle observation \(x_{\text{new}}\): 2. Pour chaque classe \(k=1, \dots, K\): a. Calculer la vraisemblance \(P(x_{\text{new}} | Y=k; \hat{\mu}_k, \hat{\Sigma}_k)\) en utilisant la formule de la PDF Gaussienne. b. Calculer le produit \(P(x_{\text{new}} | Y=k) \times \hat{\phi}_k\). 3. Prédire la classe \(k^*\) qui maximise ce produit : \[ \hat{y}_{\text{new}} = \arg\max_k P(x_{\text{new}} | Y=k; \hat{\mu}_k, \hat{\Sigma}_k) \hat{\phi}_k \] Les probabilités \(P(Y=k | x_{\text{new}})\) peuvent aussi être calculées en normalisant ces produits (en divisant par leur somme sur toutes les classes, qui est \(P(x_{\text{new}})\)).
8 Tutoriel Pratique : LDA et QDA avec Python et Scikit-learn
Illustrons LDA et QDA avec un exemple.
8.1 Préparation : Importations et Données
Code
# Génération de données avec 3 classes
X, y = make_classification(n_samples=500, n_features=2, n_redundant=0,
n_informative=2, random_state=42, n_clusters_per_class=1,
n_classes=3)
# Division en ensembles d'entraînement et de test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Standardisation (bien que GDA soit moins sensible à l'échelle que d'autres algo,
# c'est une bonne habitude et peut aider à stabiliser l'estimation de la covariance)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Visualisation
plt.figure(figsize=(7, 4.5))
scatter = plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=y_train, cmap='viridis', edgecolors='k', alpha=0.7)
plt.title('Données d\'entraînement standardisées (3 classes)')
plt.xlabel('Caractéristique 1 (standardisée)')
plt.ylabel('Caractéristique 2 (standardisée)')
plt.legend(handles=scatter.legend_elements()[0], labels=['Classe 0', 'Classe 1', 'Classe 2'])
plt.grid(True, linestyle='--', alpha=0.3)
plt.show()
8.2 Entraînement et Prédiction avec LDA
Code
# Création et entraînement du modèle LDA
lda = LinearDiscriminantAnalysis(solver='svd') # 'svd' n'a pas besoin de calculer l'inverse de la covariance
# 'lsqr' ou 'eigen' peuvent aussi être utilisés
lda.fit(X_train_scaled, y_train)
# Prédictions avec LDA
y_pred_lda = lda.predict(X_test_scaled)
y_pred_proba_lda = lda.predict_proba(X_test_scaled)
print("LDA - Exactitude :", accuracy_score(y_test, y_pred_lda))
print("\nLDA - Rapport de Classification:\n", classification_report(y_test, y_pred_lda))
print("\nLDA - Matrice de Confusion:\n", confusion_matrix(y_test, y_pred_lda))LDA - Exactitude : 0.8933333333333333
LDA - Rapport de Classification:
precision recall f1-score support
0 0.90 0.88 0.89 50
1 0.90 0.85 0.88 55
2 0.88 0.96 0.91 45
accuracy 0.89 150
macro avg 0.89 0.90 0.89 150
weighted avg 0.89 0.89 0.89 150
LDA - Matrice de Confusion:
[[44 5 1]
[ 3 47 5]
[ 2 0 43]]8.3 Entraînement et Prédiction avec QDA
Code
# Création et entraînement du modèle QDA
qda = QuadraticDiscriminantAnalysis()
qda.fit(X_train_scaled, y_train)
# Prédictions avec QDA
y_pred_qda = qda.predict(X_test_scaled)
y_pred_proba_qda = qda.predict_proba(X_test_scaled)
print("QDA - Exactitude :", accuracy_score(y_test, y_pred_qda))
print("\nQDA - Rapport de Classification:\n", classification_report(y_test, y_pred_qda))
print("\nQDA - Matrice de Confusion:\n", confusion_matrix(y_test, y_pred_qda))QDA - Exactitude : 0.96
QDA - Rapport de Classification:
precision recall f1-score support
0 1.00 0.88 0.94 50
1 0.95 1.00 0.97 55
2 0.94 1.00 0.97 45
accuracy 0.96 150
macro avg 0.96 0.96 0.96 150
weighted avg 0.96 0.96 0.96 150
QDA - Matrice de Confusion:
[[44 3 3]
[ 0 55 0]
[ 0 0 45]]8.4 Visualisation des Frontières de Décision (pour données 2D)
Code
def plot_decision_boundary(ax, clf, X, y, title):
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.3, cmap='viridis')
scatter_plot = ax.scatter(X[:, 0], X[:, 1], c=y, s=30, edgecolor='k', cmap='viridis', alpha=0.9)
ax.set_title(title)
ax.set_xlabel('Caractéristique 1 (standardisée)')
ax.set_ylabel('Caractéristique 2 (standardisée)')
# Create a common legend for all subplots if classes are consistent
# Handles for legend
if hasattr(clf, 'classes_'): # Check if classes_ attribute exists
legend_handles = [plt.Line2D([0], [0], marker='o', color='w', label=f'Classe {i}',
markerfacecolor=plt.cm.viridis(i/ (len(clf.classes_)-1 if len(clf.classes_)>1 else 1) ),
markersize=8) for i in clf.classes_]
ax.legend(handles=legend_handles, loc='best')
ax.grid(True, linestyle=':', alpha=0.4)
if X_train_scaled.shape[1] == 2:
fig, axes = plt.subplots(1, 2, figsize=(14, 6)) # Ajusté pour deux graphiques
plot_decision_boundary(axes[0], lda, X_test_scaled, y_test, 'Frontière de Décision LDA')
plot_decision_boundary(axes[1], qda, X_test_scaled, y_test, 'Frontière de Décision QDA')
plt.tight_layout()
plt.show()
else:
print("La visualisation des frontières n'est affichée que pour 2 caractéristiques.")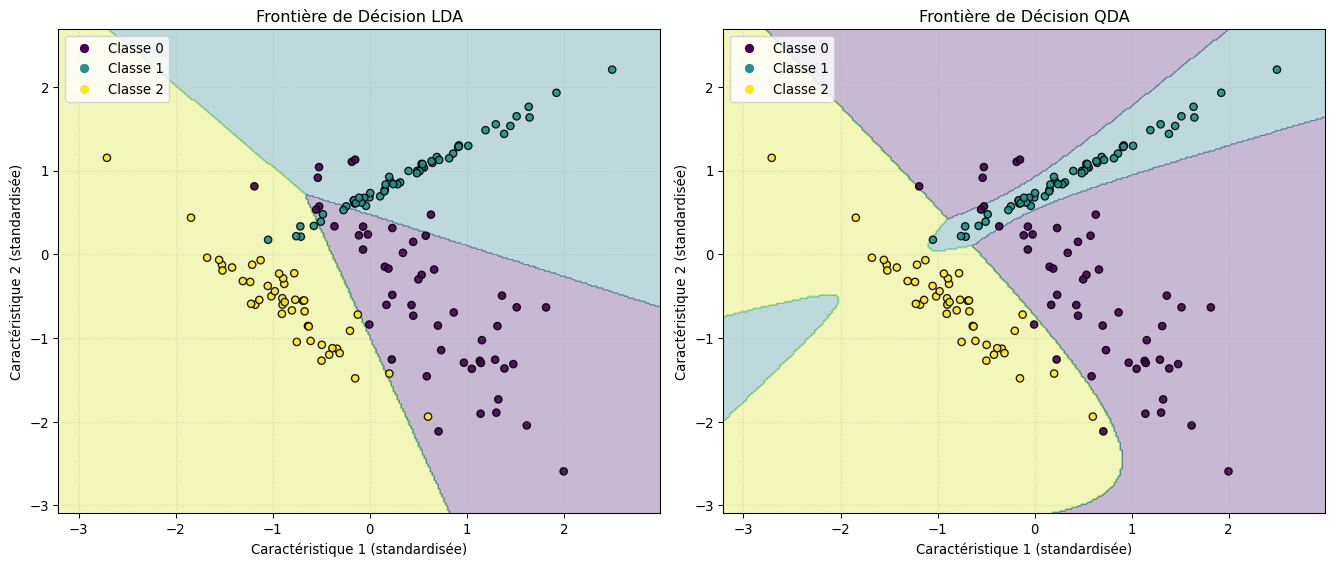
Sur les graphiques (si générés), vous devriez observer que la frontière de LDA est composée de segments de droites (linéaire par morceaux pour plus de 2 classes), tandis que celle de QDA peut avoir des formes courbes (quadratiques).
9 LDA vs. QDA : Le Compromis Biais-Variance
Le choix entre LDA et QDA dépend du compromis biais-variance et de la nature des données :
- LDA (Biais élevé, Variance faible) :
- Fait une hypothèse plus forte (covariance partagée).
- Moins de paramètres à estimer.
- Tendance à être plus robuste et moins sujet au sur-apprentissage, surtout avec peu de données d’entraînement ou lorsque la séparation est réellement proche de linéaire.
- Peut sous-apprendre si les covariances des classes sont très différentes.
- QDA (Biais faible, Variance élevée) :
- Hypothèse plus flexible (covariances distinctes).
- Beaucoup plus de paramètres à estimer (une matrice \(\Sigma_k\) complète par classe).
- Peut capturer des relations plus complexes.
- Nécessite plus de données d’entraînement pour bien estimer chaque \(\Sigma_k\) et éviter le sur-apprentissage. Peut mal performer si le nombre de caractéristiques est grand par rapport au nombre d’échantillons par classe.
Quand choisir quoi ? - Si vous avez peu de données ou si vous pensez que les classes ont des “formes” (distributions) similaires, LDA est souvent un meilleur choix. - Si vous avez beaucoup de données et que vous suspectez que les classes ont des covariances très différentes, QDA pourrait offrir de meilleures performances. - Il est toujours bon d’essayer les deux et d’évaluer leur performance via une validation croisée si le choix n’est pas évident.
10 Relation avec la Régression Logistique
Il existe un lien intéressant entre LDA et la régression logistique. Si les hypothèses de LDA sont vérifiées (c’est-à-dire que \(P(X|Y=k)\) est Gaussienne pour chaque classe \(k\), et que toutes les classes partagent la même matrice de covariance \(\Sigma\)), alors on peut montrer mathématiquement que la probabilité a posteriori \(P(Y=1|X)\) prend la forme d’une fonction logistique (sigmoïde) d’une combinaison linéaire des \(X\).
\[ \log \frac{P(Y=1|X)}{P(Y=0|X)} = \beta_0 + \beta^T X \]
Quelle est la différence alors ? - Estimation des paramètres : - GDA (LDA/QDA) estime les paramètres (\(\phi_k, \mu_k, \Sigma_k/\Sigma\)) en maximisant la vraisemblance jointe \(P(X,Y) = P(X|Y)P(Y)\). - La régression logistique estime ses paramètres \(\beta\) en maximisant la vraisemblance conditionnelle \(P(Y|X)\). - Hypothèses : - GDA fait des hypothèses plus fortes sur la distribution des données (\(X|Y\) est Gaussien). Si ces hypothèses sont correctes, GDA peut être plus efficace (converger vers la meilleure solution avec moins de données). - La régression logistique fait moins d’hypothèses sur \(P(X|Y)\) et peut être plus robuste si l’hypothèse gaussienne est violée. - En pratique, la régression logistique a souvent des performances similaires ou meilleures quand les hypothèses gaussiennes de LDA ne tiennent pas bien.
11 Avantages et Inconvénients de GDA
11.1 Avantages
- Efficacité avec peu de données (surtout LDA) : Si les hypothèses gaussiennes sont raisonnablement satisfaites, LDA peut atteindre de bonnes performances même avec un nombre limité d’échantillons d’entraînement car elle a moins de paramètres à estimer que QDA ou la régression logistique dans certains cas.
- Naturellement multi-classe : L’approche s’étend directement à plus de deux classes.
- Modèle génératif : Peut être utilisé pour générer de nouvelles données synthétiques ressemblant aux données d’entraînement si nécessaire (en échantillonnant à partir des \(P(X|Y=k)\) apprises).
- Pas d’hyperparamètres à régler (pour les versions de base) : Contrairement à des méthodes comme les SVM ou les réseaux de neurones, LDA et QDA de base n’ont pas d’hyperparamètres majeurs à optimiser (hors choix LDA/QDA lui-même et solveurs/régularisation dans certaines implémentations de
scikit-learn). - QDA offre une flexibilité de frontière de décision (quadratique).
11.2 Inconvénients
- Hypothèse Gaussienne : La performance de GDA dépend fortement de la validité de l’hypothèse que les données de chaque classe suivent une distribution gaussienne. Si ce n’est pas le cas (par exemple, distributions multimodales, très asymétriques), GDA peut mal performer.
- Sensibilité aux outliers : Les estimations de la moyenne et de la covariance peuvent être fortement influencées par les valeurs aberrantes.
- Performance de LDA limitée par la frontière linéaire : Si la séparation optimale entre les classes est fortement non linéaire, LDA ne sera pas performante.
- QDA nécessite plus de données : Pour estimer de manière fiable \(K\) matrices de covariance, QDA requiert un nombre d’échantillons par classe significativement plus grand que le nombre de caractéristiques, pour éviter le sur-apprentissage ou des problèmes numériques (matrices de covariance singulières).
- Nombre de caractéristiques : Si le nombre de caractéristiques \(D\) est très grand par rapport au nombre d’échantillons \(N\), l’estimation des matrices de covariance devient instable. Des techniques de régularisation ou de réduction de dimension sont alors nécessaires avant d’appliquer GDA. (
scikit-learna une option de régularisation pour LDA).
12 Conclusion
L’Analyse Discriminante Gaussienne, avec ses variantes LDA et QDA, offre une approche probabiliste générative pour les problèmes de classification. En modélisant la distribution de chaque classe comme une gaussienne, elle permet de dériver des frontières de décision linéaires (LDA) ou quadratiques (QDA) via le théorème de Bayes.
LDA est un modèle plus simple et robuste, particulièrement utile lorsque les données sont limitées ou que la séparation est approximativement linéaire. QDA offre plus de flexibilité mais nécessite plus de données pour éviter le sur-apprentissage. Le choix entre les deux est une illustration classique du compromis biais-variance.
Bien que reposant sur des hypothèses spécifiques (normalité des données), GDA reste un outil important, notamment pour sa simplicité, son efficacité dans certains contextes, et pour comprendre les fondements des modèles génératifs.
13 Exercices
Exercise 1 (Analyse Discriminante Gaussienne et Nature des Frontières de Décision 📊) Objectif :
Cet exercice vise à implémenter et à visualiser l’Analyse Discriminante Gaussienne (ADG) pour un problème de classification binaire. Vous explorerez comment la nature de la frontière de décision change (linéaire ou quadratique) en fonction des hypothèses sur les matrices de covariance des classes.
Contexte Théorique :
L’Analyse Discriminante Gaussienne est un classifieur génératif qui modélise la distribution de probabilité de chaque classe \(P(\vec{x}|Y=c)\) comme une gaussienne multidimensionnelle. La règle de décision consiste ensuite à assigner une nouvelle observation \(\vec{x}\) à la classe qui maximise la probabilité a posteriori \(P(Y=c|\vec{x})\).
La fonction de décision (ou score discriminant) pour une classe \(k\) peut s’écrire (en ignorant les termes constants identiques pour toutes les classes) :
\[ \delta_k(\vec{x}) = -\frac{1}{2} (\vec{x} - \vec{\mu}_k)^T \Sigma_k^{-1} (\vec{x} - \vec{\mu}_k) - \frac{1}{2} \log|\Sigma_k| + \log P(Y=k) \]
La frontière entre deux classes \(k\) et \(l\) est l’ensemble des points \(\vec{x}\) où \(\delta_k(\vec{x}) = \delta_l(\vec{x})\).
- Si les matrices de covariance sont égales pour toutes les classes (\(\Sigma_k = \Sigma_l = \Sigma\)), les termes quadratiques en \(\vec{x}\) s’annulent, et la frontière de décision devient linéaire. On parle alors d’Analyse Discriminante Linéaire (ADL).
- Si les matrices de covariance sont différentes (\(\Sigma_k \neq \Sigma_l\)), les termes quadratiques ne s’annulent pas, et la frontière de décision est quadratique. On parle alors d’Analyse Discriminante Quadratique (ADQ).
Données :
Vous allez générer deux ensembles de données synthétiques en 2D pour deux classes (Classe 0 et Classe 1).
Matrices de Covariance Égales (Frontière Linéaire)
- Génération des Données :
- Classe 0 : Générez \(N_0 = 100\) points à partir d’une distribution gaussienne avec :
- Moyenne \(\vec{\mu}_0 = \begin{pmatrix} 1 \\ 1 \end{pmatrix}\)
- Matrice de covariance \(\Sigma_0 = \begin{pmatrix} 2 & 0.5 \\ 0.5 & 1 \end{pmatrix}\)
- Classe 1 : Générez \(N_1 = 100\) points à partir d’une distribution gaussienne avec :
- Moyenne \(\vec{\mu}_1 = \begin{pmatrix} 4 \\ 4 \end{pmatrix}\)
- Matrice de covariance \(\Sigma_1 = \begin{pmatrix} 2 & 0.5 \\ 0.5 & 1 \end{pmatrix}\) (identique à \(\Sigma_0\))
- Supposez des probabilités a priori égales pour les classes : \(P(Y=0) = P(Y=1) = 0.5\).
- Classe 0 : Générez \(N_0 = 100\) points à partir d’une distribution gaussienne avec :
- Estimation des Paramètres :
- Estimez les moyennes \(\hat{\vec{\mu}}_0, \hat{\vec{\mu}}_1\) à partir de vos données générées.
- Estimez la matrice de covariance commune \(\hat{\Sigma}\) (par exemple, en moyennant les estimations individuelles des covariances pondérées par la taille des classes).
- Estimez les probabilités a priori \(\hat{P}(Y=0), \hat{P}(Y=1)\).
- Calcul de la Frontière de Décision :
- Dérivez l’équation de la frontière de décision linéaire en égalisant les fonctions discriminantes \(\delta_0(\vec{x})\) et \(\delta_1(\vec{x})\) sous l’hypothèse \(\Sigma_0 = \Sigma_1 = \Sigma\).
- Simplifiez l’expression pour obtenir une équation de la forme \(\vec{w}^T \vec{x} + w_0 = 0\).
- Visualisation :
- Affichez les points des deux classes sur un graphique 2D.
- Superposez la frontière de décision linéaire que vous avez calculée.
- (Optionnel) Créez une grille de points sur le graphique et prédisez la classe pour chaque point de la grille pour visualiser les régions de décision.
Matrices de Covariance Différentes (Frontière Quadratique)
- Génération des Données :
- Classe 0 : Générez \(N_0 = 100\) points à partir d’une distribution gaussienne avec :
- Moyenne \(\vec{\mu}_0 = \begin{pmatrix} 1 \\ 1 \end{pmatrix}\)
- Matrice de covariance \(\Sigma_0 = \begin{pmatrix} 2 & 0 \\ 0 & 0.5 \end{pmatrix}\) (covariance diagonale, ellipse orientée selon les axes)
- Classe 1 : Générez \(N_1 = 100\) points à partir d’une distribution gaussienne avec :
- Moyenne \(\vec{\mu}_1 = \begin{pmatrix} 3 \\ 3 \end{pmatrix}\)
- Matrice de covariance \(\Sigma_1 = \begin{pmatrix} 1 & -0.7 \\ -0.7 & 1.5 \end{pmatrix}\) (covariance non diagonale, ellipse orientée différemment)
- Supposez des probabilités a priori égales pour les classes : \(P(Y=0) = P(Y=1) = 0.5\).
- Classe 0 : Générez \(N_0 = 100\) points à partir d’une distribution gaussienne avec :
- Estimation des Paramètres :
- Estimez les moyennes \(\hat{\vec{\mu}}_0, \hat{\vec{\mu}}_1\) à partir de vos données générées.
- Estimez les matrices de covariance individuelles \(\hat{\Sigma}_0\) et \(\hat{\Sigma}_1\).
- Estimez les probabilités a priori \(\hat{P}(Y=0), \hat{P}(Y=1)\).
- Calcul de la Frontière de Décision :
- Écrivez l’équation de la frontière de décision quadratique en égalisant les fonctions discriminantes \(\delta_0(\vec{x})\) et \(\delta_1(\vec{x})\) avec \(\Sigma_0 \neq \Sigma_1\).
- L’équation sera de la forme \(\vec{x}^T A \vec{x} + \vec{b}^T \vec{x} + c = 0\). Identifiez les matrices/vecteurs A, \(\vec{b}\) et la constante c.
- Visualisation :
- Affichez les points des deux classes sur un graphique 2D.
- Créez une grille de points sur le graphique. Pour chaque point \((\text{x_grid, y_grid})\) de la grille, calculez \(\delta_0(\text{point_grid})\) et \(\delta_1(\text{point_grid})\).
- Prédisez la classe pour chaque point de la grille.
- Utilisez les prédictions pour colorer les régions de décision.
- Tracez la contour-line où \(\delta_0(\vec{x}) - \delta_1(\vec{x}) = 0\) pour visualiser la frontière quadratique.
Questions pour l’Analyse : 🤔
- Comparez les formes des frontières de décision obtenues dans la Partie 1 et la Partie 2. Sont-elles conformes aux attentes théoriques ?
- Dans la Partie 1, comment la frontière changerait-elle si les probabilités a priori \(P(Y=k)\) étaient différentes ?
- Dans la Partie 2, expliquez pourquoi la frontière devient quadratique. Quels termes de la fonction discriminante y contribuent ?
- Quel est l’impact pratique d’utiliser une ADL lorsque les covariances sont en réalité différentes, ou une ADQ lorsque les covariances sont en réalité similaires (en termes de complexité du modèle et de risque de sur-apprentissage) ?
Conseils pour l’Implémentation (Python) : 🐍
- Utilisez
numpypour la génération des données gaussiennes (numpy.random.multivariate_normal) et les calculs matriciels. - Utilisez
matplotlib.pyplotpour la visualisation.plt.contourouplt.contourfpeuvent être utiles pour visualiser les régions de décision et la frontière quadratique. - Pour l’estimation des paramètres, les formules empiriques de la moyenne et de la covariance sont suffisantes.
Exercise 2 (Implémentation du Classifieur Bayésien Gaussien Naïf BAYESIEN NAÏF) Objectif :
L’objectif de cet exercice est d’implémenter un classifieur Bayésien Gaussien Naïf à partir de zéro en créant une classe Python nommée MyNBGaussienClassifier. Vous testerez ensuite votre classifieur sur un jeu de données simple.
Contexte Théorique :
Le classifieur Bayésien Naïf est un algorithme d’apprentissage supervisé probabiliste basé sur le théorème de Bayes. Il est qualifié de “naïf” car il repose sur une hypothèse simplificatrice forte : les caractéristiques (ou features) sont supposées être conditionnellement indépendantes étant donné la classe.
Pour un classifieur Bayésien Gaussien Naïf, on suppose de plus que la vraisemblance de chaque caractéristique \(P(x_j | Y=c)\) suit une distribution gaussienne (normale). Les paramètres de cette distribution (moyenne \(\mu_{jc}\) et variance \(\sigma^2_{jc}\)) sont estimés à partir des données d’entraînement pour chaque caractéristique \(j\) et chaque classe \(c\).
La règle de décision pour classer une nouvelle observation \(\vec{x} = (x_1, x_2, ..., x_p)\) est d’assigner la classe \(\hat{y}\) qui maximise la probabilité a posteriori \(P(Y=c | \vec{x})\). En utilisant le théorème de Bayes et l’hypothèse d’indépendance conditionnelle, cela revient à maximiser :
\[ \hat{y} = \arg\max_c P(Y=c) \prod_{j=1}^{p} P(x_j | Y=c) \]
Où :
- \(P(Y=c)\) est la probabilité a priori de la classe \(c\).
- \(P(x_j | Y=c)\) est la vraisemblance de la caractéristique \(x_j\) étant donné la classe \(c\), modélisée par une PDF gaussienne : \[ P(x_j | Y=c; \mu_{jc}, \sigma^2_{jc}) = \frac{1}{\sqrt{2\pi\sigma^2_{jc}}} \exp\left(-\frac{(x_j-\mu_{jc})^2}{2\sigma^2_{jc}}\right) \]
Pour éviter les problèmes de sous-flux numérique (underflow) dus à la multiplication de nombreuses petites probabilités, il est courant de travailler avec la somme des log-probabilités :
\[ \hat{y} = \arg\max_c \left( \log P(Y=c) + \sum_{j=1}^{p} \log P(x_j | Y=c) \right) \]
Tâches à Réaliser :
Définir la Classe
MyNBGaussienClassifier: Créez une classe Python avec ce nom.Constructeur
__init__(self):- Initialisez les attributs nécessaires pour stocker les paramètres du modèle appris lors de l’entraînement :
classes_: pour les étiquettes de classe uniques.class_priors_: pour les probabilités a priori \(P(Y=c)\).means_: pour stocker les moyennes \(\mu_{jc}\) de chaque feature pour chaque classe.variances_: pour stocker les variances \(\sigma^2_{jc}\) de chaque feature pour chaque classe.epsilon_: une petite valeur (par exemple,1e-9) à ajouter aux variances pour éviter les divisions par zéro si une variance est nulle.
- Initialisez les attributs nécessaires pour stocker les paramètres du modèle appris lors de l’entraînement :
Méthode
_gaussian_pdf(self, x, mean, var):- Implémentez une fonction privée qui calcule la valeur de la densité de probabilité (PDF) gaussienne pour une valeur
x, une moyennemean, et une variancevar. - Assurez-vous que
var + self.epsilon_est utilisé dans le calcul pour la stabilité.
- Implémentez une fonction privée qui calcule la valeur de la densité de probabilité (PDF) gaussienne pour une valeur
Méthode
fit(self, X, y):X: Matrice des caractéristiques (array NumPy de forme(n_samples, n_features)).y: Vecteur des étiquettes de classe (array NumPy de forme(n_samples,)).- Dans cette méthode :
- Identifiez les classes uniques à partir de
yet stockez-les dansself.classes_. - Calculez et stockez les probabilités a priori des classes \(P(Y=c)\) dans
self.class_priors_. - Pour chaque classe \(c\) et pour chaque caractéristique \(j\) :
- Calculez la moyenne \(\mu_{jc}\) des valeurs de la caractéristique \(j\) pour les échantillons appartenant à la classe \(c\). Stockez dans
self.means_. - Calculez la variance \(\sigma^2_{jc}\) des valeurs de la caractéristique \(j\) pour les échantillons appartenant à la classe \(c\). Stockez dans
self.variances_.
- Calculez la moyenne \(\mu_{jc}\) des valeurs de la caractéristique \(j\) pour les échantillons appartenant à la classe \(c\). Stockez dans
- La structure de
self.means_etself.variances_pourrait être un dictionnaire où les clés sont les classes et les valeurs des arrays NumPy, ou des arrays NumPy où la première dimension correspond à la classe.
- Identifiez les classes uniques à partir de
Méthode
_predict_log_proba_one_sample(self, x_sample):x_sample: Un seul échantillon de données (array NumPy 1D de forme(n_features,)).- Pour chaque classe \(c\) dans
self.classes_:- Calculez le log de la probabilité a priori : \(\log P(Y=c)\).
- Calculez la somme des logs des vraisemblances : \(\sum_{j=1}^{p} \log P(x_j | Y=c)\). Utilisez
self._gaussian_pdfet les moyennes/variances stockées. Attention aux logs de zéro si une PDF est très petite (bien que l’utilisation deepsilon_dans la variance aide). - La somme de ces deux termes est proportionnelle au log de la probabilité a posteriori pour la classe \(c\).
- Retournez un array ou une liste des log-probabilités (ou scores) pour chaque classe.
Méthode
predict(self, X):X: Matrice des caractéristiques des échantillons à classifier.- Pour chaque échantillon
x_sampledansX:- Utilisez
self._predict_log_proba_one_sample(x_sample)pour obtenir les log-probabilités pour chaque classe. - La classe prédite pour
x_sampleest celle qui a la plus grande log-probabilité.
- Utilisez
- Retournez un array NumPy des étiquettes de classe prédites pour
X.
Données de Test Suggérées :
- Jeu de données Iris : Un classique simple avec 3 classes et 4 caractéristiques numériques. Vous pouvez le charger avec
sklearn.datasets.load_iris(). - Données Synthétiques : Générez vos propres données à partir de distributions gaussiennes distinctes pour chaque classe afin de bien contrôler le scénario de test.
Validation :
- Séparez vos données en un ensemble d’entraînement et un ensemble de test (par exemple, avec
sklearn.model_selection.train_test_split). - Entraînez votre
MyNBGaussienClassifiersur l’ensemble d’entraînement. - Faites des prédictions sur l’ensemble de test.
- Évaluez la performance, par exemple en calculant l’exactitude (accuracy) :
python from sklearn.metrics import accuracy_score accuracy = accuracy_score(y_test, y_pred) print(f"Exactitude de MyNBGaussienClassifier: {accuracy:.4f}") - (Optionnel) Comparez les résultats de votre classifieur avec l’implémentation de
sklearn.naive_bayes.GaussianNB.
Questions pour la Réflexion : 🤔
- Discutez de l’hypothèse “naïve” d’indépendance conditionnelle des caractéristiques. Dans quels scénarios du monde réel cette hypothèse pourrait-elle être fortement violée et quel impact cela pourrait-il avoir sur les performances ?
- Que se passe-t-il si une caractéristique a une variance nulle au sein d’une classe pendant l’entraînement (c’est-à-dire que toutes les valeurs de cette caractéristique sont identiques pour cette classe) ? Comment votre implémentation (notamment l’utilisation de
self.epsilon_) gère-t-elle cela ? - Pourquoi est-il préférable d’utiliser les log-probabilités dans les calculs plutôt que les probabilités directes ?
- Le classifieur Bayésien Naïf est un modèle génératif. Qu’est-ce que cela signifie, par opposition à un modèle discriminatif ?
Copyright
2025 W. Toussile