import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Configuration pour un meilleur affichage des graphiques
sns.set_theme(style="whitegrid")
plt.rcParams['figure.figsize'] = [7, 4.5] # Taille par défaut des figures1 Introduction : L’Importance Cruciale des Données
En Machine Learning, la qualité et la pertinence des données sont primordiales. Un algorithme, aussi sophistiqué soit-il, ne pourra produire des résultats fiables si les données en entrée sont de mauvaise qualité. C’est le fameux principe du “Garbage In, Garbage Out” (source: 90). La collecte et la préparation des données représentent souvent la majeure partie du temps et de l’effort dans un projet de Machine Learning (parfois jusqu’à 80% !).
Cet atelier a pour objectif de vous guider à travers les étapes essentielles pour transformer des données brutes en un jeu de données propre et structuré, prêt à être utilisé pour entraîner des modèles de Machine Learning.
Objectifs de l’atelier :
- Comprendre les différentes sources et méthodes de collecte de données (théorique).
- Apprendre à charger et inspecter un jeu de données avec Pandas.
- Identifier et traiter les valeurs manquantes.
- Gérer les types de données incorrects.
- Détecter et aborder (brièvement) les données aberrantes (outliers).
- Effectuer une ingénierie de caractéristiques de base (feature engineering).
- Encoder les variables catégorielles.
- Mettre à l’échelle les caractéristiques numériques.
Jeu de données utilisé : Pour cet atelier, nous utiliserons le célèbre jeu de données du Titanic. Il est accessible publiquement et présente de nombreux défis typiques de la préparation de données. Notre objectif (hypothétique pour cet atelier de préparation) pourrait être de prédire la survie d’un passager.
Outils principaux : Python, Pandas, NumPy, Matplotlib, Seaborn, Scikit-learn.
2 1. Phase de Collecte des Données (Aperçu Théorique)
Bien que cet atelier se concentre sur la préparation, il est important de mentionner brièvement la collecte. Les données peuvent provenir de multiples sources :
- Bases de données existantes : SQL, NoSQL, data warehouses.
- Fichiers plats : CSV, Excel, JSON, TXT.
- APIs (Interfaces de Programmation d’Applications) : Permettent d’accéder à des données de services web (ex: Twitter API, OpenWeatherMap API).
- Web Scraping : Extraction de données depuis des sites web (avec des bibliothèques comme
BeautifulSoupouScrapy). Il faut être attentif aux aspects légaux et éthiques. - Jeux de données publics : Kaggle, UCI Machine Learning Repository (
source: 179), Data.gov, Eurostat, etc. - Collecte manuelle ou via des enquêtes.
Pour cet atelier, nous allons simuler la collecte en chargeant le jeu de données du Titanic, souvent disponible via des bibliothèques comme Seaborn ou téléchargeable sur Kaggle.
Note
Considérations Éthiques et Légales : Lors de la collecte de données, il est impératif de respecter la vie privée, les réglementations (comme le RGPD en Europe), les conditions d’utilisation des APIs et des sites web. Obtenez toujours les permissions nécessaires.
3 Chargement et Première Exploration des Données
Commençons par charger notre jeu de données et par y jeter un premier coup d’œil.
3.1 Importation des bibliothèques et chargement
Pour obtenir le jeu de données du Titanic, nous pouvons le charger depuis la bibliothèque seaborn qui l’inclut à des fins d’exemple. Si vous ne l’avez pas, vous pouvez l’installer (pip install seaborn) ou télécharger un fichier CSV depuis Kaggle.
Code
# Chargement du jeu de données du Titanic depuis Seaborn
try:
titanic_df = sns.load_dataset('titanic')
print("Jeu de données Titanic chargé depuis Seaborn.")
except Exception as e:
print(f"Erreur lors du chargement depuis Seaborn : {e}")
print("Tentative de chargement d'un fichier CSV local 'titanic.csv'. Assurez-vous qu'il est présent.")
# En alternative, si vous avez un CSV local :
try:
titanic_df = pd.read_csv('titanic.csv') # Assurez-vous que le fichier est dans le bon répertoire
print("Jeu de données Titanic chargé depuis 'titanic.csv'.")
except FileNotFoundError:
print("titanic.csv non trouvé. Veuillez télécharger le jeu de données et le placer dans le répertoire.")
# Création d'un DataFrame vide pour que le reste du document puisse s'exécuter sans erreur
titanic_df = pd.DataFrame()
if not titanic_df.empty:
print("Dimensions du jeu de données (lignes, colonnes):", titanic_df.shape)
else:
print("Le jeu de données est vide. Les étapes suivantes ne pourront pas être exécutées correctement.")Jeu de données Titanic chargé depuis Seaborn.
Dimensions du jeu de données (lignes, colonnes): (891, 15)3.2 2.2. Inspection initiale
Une fois les données chargées, explorons-les pour comprendre leur structure et leur contenu.
Code
# Afficher les 5 premières lignes
if not titanic_df.empty:
print("Premières lignes du DataFrame :")
print(titanic_df.head())Premières lignes du DataFrame :
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True Code
# Informations générales sur le DataFrame
if not titanic_df.empty:
print("\nInformations générales (types de données, valeurs non nulles) :")
titanic_df.info()
Informations générales (types de données, valeurs non nulles) :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KBinfo() nous donne des informations précieuses : le nombre d’entrées, le nombre de colonnes, le type de chaque colonne (dtype), et le nombre de valeurs non nulles. Cela nous aide déjà à repérer les colonnes avec des valeurs manquantes.
Code
# Statistiques descriptives pour les colonnes numériques
if not titanic_df.empty:
print("\nStatistiques descriptives (colonnes numériques) :")
print(titanic_df.describe(include=[np.number])) # Forcer l'inclusion des types numériques
Statistiques descriptives (colonnes numériques) :
survived pclass age sibsp parch fare
count 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200Code
# Statistiques descriptives pour les colonnes catégorielles (objets)
if not titanic_df.empty:
print("\nStatistiques descriptives (colonnes catégorielles) :")
print(titanic_df.describe(include=['object', 'category']))
Statistiques descriptives (colonnes catégorielles) :
sex embarked class who deck embark_town alive
count 891 889 891 891 203 889 891
unique 2 3 3 3 7 3 2
top male S Third man C Southampton no
freq 577 644 491 537 59 644 549describe() fournit des statistiques comme la moyenne, l’écart-type, les quantiles pour les colonnes numériques, et le nombre de valeurs uniques, la valeur la plus fréquente (top) et sa fréquence (freq) pour les colonnes catégorielles.
3.3 2.3. Visualisation initiale des valeurs manquantes
Une heatmap peut être très utile pour visualiser la distribution des valeurs manquantes.
Code
if not titanic_df.empty:
plt.figure(figsize=(10,6)) # Un peu plus grand pour la heatmap
sns.heatmap(titanic_df.isnull(), cbar=False, cmap='viridis', yticklabels=False)
plt.title('Valeurs Manquantes par Colonne')
plt.show()
print("\nNombre de valeurs manquantes par colonne :")
print(titanic_df.isnull().sum().sort_values(ascending=False))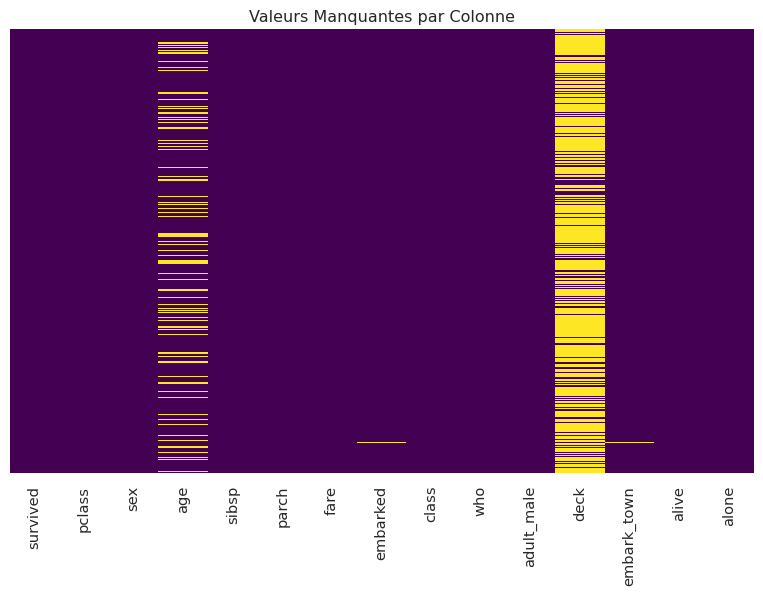
Nombre de valeurs manquantes par colonne :
deck 688
age 177
embarked 2
embark_town 2
survived 0
pclass 0
sex 0
sibsp 0
parch 0
fare 0
class 0
who 0
adult_male 0
alive 0
alone 0
dtype: int64Nous observons que age, deck (souvent dérivé de cabin), et embarked / embark_town ont des valeurs manquantes. deck (et cabin si présente) en a énormément.
4 3. Nettoyage et Prétraitement des Données
Cette section est le cœur de notre atelier. Nous allons aborder les problèmes identifiés.
4.1 3.1. Gestion des Valeurs Manquantes
Plusieurs stratégies existent pour traiter les valeurs manquantes. Le choix dépend du contexte, du type de variable, et du pourcentage de valeurs manquantes.
Colonne deck (ou cabin)
La colonne deck (qui est une simplification de cabin dans la version Seaborn) a une très grande proportion de valeurs manquantes.
Code
if not titanic_df.empty:
# Pourcentage de valeurs manquantes pour 'deck'
missing_deck_percentage = titanic_df['deck'].isnull().sum() / len(titanic_df) * 100
print(f"Pourcentage de valeurs manquantes pour 'deck': {missing_deck_percentage:.2f}%")
# Stratégie : Supprimer la colonne car trop de valeurs manquantes
# et 'cabin' (d'où 'deck' est dérivée) est difficile à imputer de manière significative.
# Si 'cabin' est présente et 'deck' absente, on fait pareil pour 'cabin'.
cols_to_drop = []
if 'deck' in titanic_df.columns:
cols_to_drop.append('deck')
if 'cabin' in titanic_df.columns and 'deck' not in titanic_df.columns: # Si on a chargé un CSV avec 'cabin'
cols_to_drop.append('cabin')
if cols_to_drop:
titanic_df.drop(columns=cols_to_drop, inplace=True)
print(f"Colonnes {cols_to_drop} supprimées.")Pourcentage de valeurs manquantes pour 'deck': 77.22%
Colonnes ['deck'] supprimées.
Warning
Suppression de colonnes : À utiliser avec prudence. Supprimer une colonne signifie perdre toute l’information qu’elle contient. C’est justifiable si la majorité des données sont manquantes et que l’imputation est peu fiable ou introduirait trop de biais.
Colonne age
La colonne age a un nombre modéré de valeurs manquantes. C’est une caractéristique importante, donc la supprimer n’est pas idéal. Nous pouvons imputer les valeurs manquantes.
Code
if not titanic_df.empty and 'age' in titanic_df.columns:
# Visualisation de la distribution de 'age' avant imputation
plt.figure(figsize=(7, 4.5))
sns.histplot(titanic_df['age'].dropna(), kde=True)
plt.title('Distribution de l\'âge (avant imputation)')
plt.show()
# Stratégie : Imputer avec la médiane (robuste aux outliers) ou la moyenne.
median_age = titanic_df['age'].median()
# mean_age = titanic_df['age'].mean() # Autre option
titanic_df['age'].fillna(median_age, inplace=True)
print(f"Valeurs manquantes pour 'age' imputées avec la médiane : {median_age:.2f}")
print("Nombre de valeurs manquantes restantes pour 'age':", titanic_df['age'].isnull().sum())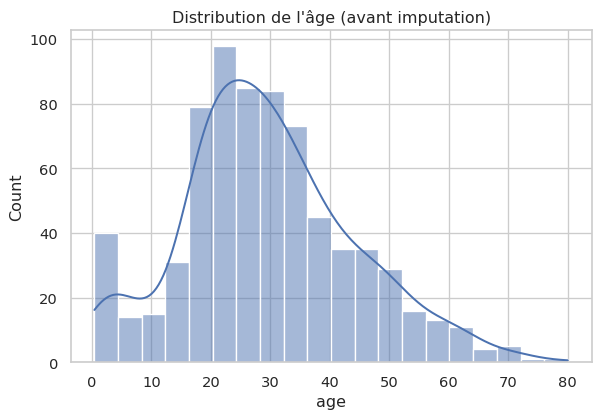
Valeurs manquantes pour 'age' imputées avec la médiane : 28.00
Nombre de valeurs manquantes restantes pour 'age': 0Colonnes embarked et embark_town
Ces colonnes ont très peu de valeurs manquantes. embark_town est redondante avec embarked (code du port).
Code
if not titanic_df.empty:
if 'embark_town' in titanic_df.columns:
print("Valeurs manquantes dans 'embark_town':", titanic_df['embark_town'].isnull().sum())
# Stratégie : Imputer avec le mode (la valeur la plus fréquente)
mode_embark_town = titanic_df['embark_town'].mode()[0] # mode() retourne une Series
titanic_df['embark_town'].fillna(mode_embark_town, inplace=True)
print(f"'embark_town' imputé avec le mode : {mode_embark_town}")
if 'embarked' in titanic_df.columns:
print("\nValeurs manquantes dans 'embarked':", titanic_df['embarked'].isnull().sum())
mode_embarked = titanic_df['embarked'].mode()[0]
titanic_df['embarked'].fillna(mode_embarked, inplace=True)
print(f"'embarked' imputé avec le mode : {mode_embarked}")
# Vérification finale des valeurs manquantes
print("\nValeurs manquantes après imputation :")
print(titanic_df.isnull().sum())Valeurs manquantes dans 'embark_town': 2
'embark_town' imputé avec le mode : Southampton
Valeurs manquantes dans 'embarked': 2
'embarked' imputé avec le mode : S
Valeurs manquantes après imputation :
survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
who 0
adult_male 0
embark_town 0
alive 0
alone 0
dtype: int644.2 3.2. Conversion des Types de Données (si nécessaire)
Vérifions les types de données avec .info() à nouveau si des changements sont attendus. Parfois, des colonnes numériques peuvent être lues comme object ou inversement. Dans le cas du Titanic (version Seaborn), les types sont généralement corrects. pclass est numérique mais représente une catégorie ordinale. On pourrait la convertir en category si on le souhaitait, mais beaucoup d’algorithmes la traiteront bien comme numérique.
Code
if not titanic_df.empty:
# Exemple : 'pclass' est numérique mais conceptuellement catégorielle ordinale.
# Pour cet atelier, nous la laissons numérique, mais on pourrait la convertir:
# titanic_df['pclass'] = titanic_df['pclass'].astype('category')
# 'survived', 'sibsp', 'parch' sont aussi des entiers qui pourraient être vus
# comme catégoriels dans certains contextes, mais sont souvent laissés numériques.
print("Types de données actuels:")
titanic_df.info()Types de données actuels:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 891 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 891 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 embark_town 891 non-null object
12 alive 891 non-null object
13 alone 891 non-null bool
dtypes: bool(2), category(1), float64(2), int64(4), object(5)
memory usage: 79.4+ KB4.3 3.3. Traitement des Données Aberrantes (Outliers) - Aperçu
Les outliers sont des valeurs extrêmes qui peuvent fausser les analyses statistiques et les modèles. Leur détection et traitement est un sujet complexe.
Identification : - Visuelle : Box plots, histogrammes. - Statistique : Écart par rapport à la moyenne (Z-score), intervalle interquartile (IQR).
Code
if not titanic_df.empty and 'fare' in titanic_df.columns:
plt.figure(figsize=(7, 4.5))
sns.boxplot(x=titanic_df['fare'])
plt.title('Box Plot de la variable Fare')
plt.show()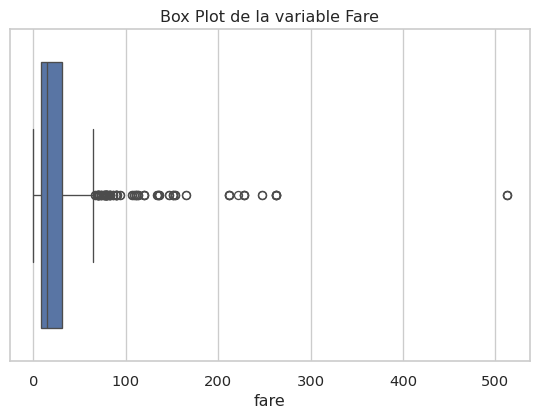
Le box plot de fare (prix du billet) montre clairement des valeurs très élevées.
Stratégies de traitement (non implémentées ici pour garder l’atelier concis) : - Suppression : Si l’outlier est clairement une erreur de saisie et qu’il y a peu d’outliers. - Capping (Plafonnement) : Remplacer les outliers par la valeur au 99ème percentile (ou 1er). - Transformation : Appliquer une transformation (log, racine carrée) peut réduire l’impact des outliers. - Imputation : Traiter comme une valeur manquante et imputer. - Utiliser des modèles robustes aux outliers.
Warning
Le traitement des outliers doit être fait avec une grande prudence et une bonne compréhension du domaine, car une valeur extrême n’est pas nécessairement une erreur.
4.4 3.4. Ingénierie de Caractéristiques (Feature Engineering)
C’est l’art de créer de nouvelles caractéristiques (variables) à partir de celles existantes pour améliorer la performance du modèle.
Exemple 1 : Créer family_size
Code
if not titanic_df.empty and 'sibsp' in titanic_df.columns and 'parch' in titanic_df.columns:
titanic_df['family_size'] = titanic_df['sibsp'] + titanic_df['parch'] + 1 # +1 pour le passager lui-même
print("Nouvelle colonne 'family_size' créée.")
print(titanic_df[['sibsp', 'parch', 'family_size']].head())Nouvelle colonne 'family_size' créée.
sibsp parch family_size
0 1 0 2
1 1 0 2
2 0 0 1
3 1 0 2
4 0 0 1Exemple 2 : Créer is_alone
Code
if not titanic_df.empty and 'family_size' in titanic_df.columns:
titanic_df['is_alone'] = 0
titanic_df.loc[titanic_df['family_size'] == 1, 'is_alone'] = 1
print("\nNouvelle colonne 'is_alone' créée.")
print(titanic_df[['family_size', 'is_alone']].head())
Nouvelle colonne 'is_alone' créée.
family_size is_alone
0 2 0
1 2 0
2 1 1
3 2 0
4 1 1Exemple 3 : Extraire le titre de name (plus avancé)
Code
if not titanic_df.empty and 'name' in titanic_df.columns:
# Expression régulière pour extraire les titres (Mr., Mrs., Miss., etc.)
titanic_df['title'] = titanic_df['name'].str.extract(' ([A-Za-z]+)\.', expand=False)
print("\nTitres extraits des noms :")
print(titanic_df['title'].value_counts().head())
# On pourrait regrouper les titres rares
common_titles = ['Mr', 'Miss', 'Mrs', 'Master']
titanic_df['title'] = titanic_df['title'].apply(lambda x: x if x in common_titles else 'Other')
print("\nTitres après regroupement :")
print(titanic_df['title'].value_counts())4.5 3.5. Encodage des Variables Catégorielles
Les algorithmes de Machine Learning requièrent généralement des entrées numériques. Nous devons donc convertir nos variables catégorielles.
Variables à encoder : sex, embarked, who, adult_male, embark_town, alive, alone, title.
(Certaines sont redondantes ou ont été créées, nous choisirons les plus pertinentes). Pour cet exemple, nous allons encoder sex, embarked (ou embark_town si embarked n’est pas là), et title.
One-Hot Encoding : Crée de nouvelles colonnes binaires (0 ou 1) pour chaque catégorie. C’est la méthode la plus courante car elle n’introduit pas de relation d’ordre artificielle.
Code
if not titanic_df.empty:
cols_to_encode = ['sex', 'title']
if 'embarked' in titanic_df.columns:
cols_to_encode.append('embarked')
elif 'embark_town' in titanic_df.columns: # Fallback si 'embarked' n'existe pas
cols_to_encode.append('embark_town')
# S'assurer que les colonnes existent avant d'essayer de les encoder
existing_cols_to_encode = [col for col in cols_to_encode if col in titanic_df.columns]
if existing_cols_to_encode:
titanic_df_encoded = pd.get_dummies(titanic_df, columns=existing_cols_to_encode, drop_first=True)
# drop_first=True pour éviter la multicolinéarité (une colonne est redondante)
print(f"\nColonnes après One-Hot Encoding (les {len(existing_cols_to_encode)+2} premières) :")
print(titanic_df_encoded.head(2))
print("Nouvelles dimensions:", titanic_df_encoded.shape)
else:
print("Aucune colonne à encoder n'a été trouvée.")
titanic_df_encoded = titanic_df.copy() # Garder une copie pour la suite
# Supprimer les colonnes originales non nécessaires ou redondantes pour la modélisation
# Par exemple, 'name' n'est plus utile si on a 'title'.
# 'who', 'adult_male', 'alive', 'alone' pourraient être redondantes avec d'autres.
cols_to_potentially_drop = ['name', 'who', 'adult_male', 'alive', 'alone',
'sibsp', 'parch'] # 'family_size' et 'is_alone' les remplacent
# Si 'embarked' et 'embark_town' sont toutes les deux présentes et ont été encodées, l'une peut être enlevée.
# Ici, on a déjà priorisé. Si on n'a pas encodé 'embark_town' car 'embarked' était là, on peut la dropper.
if 'embarked' in existing_cols_to_encode and 'embark_town' in titanic_df_encoded.columns:
cols_to_potentially_drop.append('embark_town')
elif 'embark_town' in existing_cols_to_encode and 'embarked' in titanic_df_encoded.columns:
cols_to_potentially_drop.append('embarked')
final_cols_to_drop = [col for col in cols_to_potentially_drop if col in titanic_df_encoded.columns]
if final_cols_to_drop:
titanic_df_final = titanic_df_encoded.drop(columns=final_cols_to_drop)
print(f"\nColonnes {final_cols_to_drop} supprimées pour la modélisation.")
else:
titanic_df_final = titanic_df_encoded.copy()
print("Dimensions finales:", titanic_df_final.shape)
print("Colonnes restantes:", titanic_df_final.columns.tolist())
Colonnes après One-Hot Encoding (les 4 premières) :
survived pclass age sibsp parch fare class who adult_male \
0 0 3 22.0 1 0 7.2500 Third man True
1 1 1 38.0 1 0 71.2833 First woman False
embark_town alive alone family_size is_alone sex_male embarked_Q \
0 Southampton no False 2 0 True False
1 Cherbourg yes False 2 0 False False
embarked_S
0 True
1 False
Nouvelles dimensions: (891, 17)
Colonnes ['who', 'adult_male', 'alive', 'alone', 'sibsp', 'parch', 'embark_town'] supprimées pour la modélisation.
Dimensions finales: (891, 10)
Colonnes restantes: ['survived', 'pclass', 'age', 'fare', 'class', 'family_size', 'is_alone', 'sex_male', 'embarked_Q', 'embarked_S']
Tip
Label Encoding vs. One-Hot Encoding : - Label Encoding : Assigne un entier unique à chaque catégorie (ex: S=0, C=1, Q=2). À utiliser avec prudence car cela peut introduire une relation d’ordre que l’algorithme pourrait mal interpréter (ex: Q > C > S). Adapté pour les variables ordinales si l’ordre est respecté. - One-Hot Encoding : Préférable pour les variables nominales (pas d’ordre intrinsèque).
4.6 3.6. Mise à l’Échelle des Caractéristiques Numériques (Feature Scaling)
Certains algorithmes (ceux basés sur les distances comme KNN ou SVM, ou ceux utilisant la descente de gradient comme la régression logistique avec régularisation) sont sensibles à l’échelle des caractéristiques. Si une caractéristique a des valeurs beaucoup plus grandes qu’une autre, elle pourrait dominer indûment le modèle.
Variables numériques à mettre à l’échelle (exemple) : age, fare, family_size. (pclass est ordinale, on pourrait la laisser ou la traiter aussi).
StandardScaler : Standardisation (Z-score Normalization)
Transforme les données pour qu’elles aient une moyenne de 0 et un écart-type de 1. \[ X_{scaled} = \frac{X - \mu}{\sigma} \]
MinMaxScaler : Normalisation Min-Max
Met à l’échelle les données dans un intervalle fixe, généralement [0, 1]. \[ X_{scaled} = \frac{X - X_{min}}{X_{max} - X_{min}} \]
Code
from sklearn.preprocessing import StandardScaler, MinMaxScaler
if not titanic_df_final.empty:
numerical_cols = titanic_df_final.select_dtypes(include=np.number).columns.tolist()
# Exclure la variable cible 'survived' et les variables binaires déjà en 0/1 (comme 'is_alone' ou celles du OHE)
target_col = 'survived'
if target_col in numerical_cols:
numerical_cols.remove(target_col)
# Identifier les colonnes déjà binaires ou issues du OHE pour ne pas les rescale
# (celles dont les valeurs uniques sont {0,1} ou un sous-ensemble)
binary_like_cols = [col for col in numerical_cols if set(titanic_df_final[col].unique()).issubset({0, 1})]
cols_to_scale = [col for col in numerical_cols if col not in binary_like_cols]
if cols_to_scale:
print(f"\nColonnes numériques à mettre à l'échelle : {cols_to_scale}")
scaler = StandardScaler()
titanic_df_final[cols_to_scale] = scaler.fit_transform(titanic_df_final[cols_to_scale])
print("Caractéristiques numériques mises à l'échelle avec StandardScaler.")
print(titanic_df_final[cols_to_scale].head())
print(titanic_df_final[cols_to_scale].describe())
else:
print("\nAucune colonne numérique identifiée pour la mise à l'échelle (hors cible/binaire).")
Colonnes numériques à mettre à l'échelle : ['pclass', 'age', 'fare', 'family_size']
Caractéristiques numériques mises à l'échelle avec StandardScaler.
pclass age fare family_size
0 0.827377 -0.565736 -0.502445 0.059160
1 -1.566107 0.663861 0.786845 0.059160
2 0.827377 -0.258337 -0.488854 -0.560975
3 -1.566107 0.433312 0.420730 0.059160
4 0.827377 0.433312 -0.486337 -0.560975
pclass age fare family_size
count 8.910000e+02 8.910000e+02 8.910000e+02 8.910000e+02
mean -8.772133e-17 2.272780e-16 3.987333e-18 -2.392400e-17
std 1.000562e+00 1.000562e+00 1.000562e+00 1.000562e+00
min -1.566107e+00 -2.224156e+00 -6.484217e-01 -5.609748e-01
25% -3.693648e-01 -5.657365e-01 -4.891482e-01 -5.609748e-01
50% 8.273772e-01 -1.046374e-01 -3.573909e-01 -5.609748e-01
75% 8.273772e-01 4.333115e-01 -2.424635e-02 5.915988e-02
max 8.273772e-01 3.891554e+00 9.667167e+00 5.640372e+00
Important
fit_transform vs. transform : Lors de la préparation des données pour un modèle, vous devez : 1. Adapter (fit) le scaler uniquement sur les données d’entraînement. 2. Appliquer (transform) ce scaler adapté à la fois aux données d’entraînement ET aux données de test/validation. Cela évite la fuite de données (data leakage) de l’ensemble de test vers le processus d’entraînement. Pour cet atelier, nous appliquons sur tout le jeu par simplicité, mais c’est une distinction cruciale en pratique.
5 4. Sauvegarde des Données Préparées
Après tout ce travail, il est bon de sauvegarder le jeu de données nettoyé.
Code
if not titanic_df_final.empty:
try:
titanic_df_final.to_csv('titanic_prepared.csv', index=False)
print("\nJeu de données préparé sauvegardé dans 'titanic_prepared.csv'")
except Exception as e:
print(f"Erreur lors de la sauvegarde : {e}")
Jeu de données préparé sauvegardé dans 'titanic_prepared.csv'6 5. Conclusion et Prochaines Étapes
Félicitations ! Vous avez parcouru les étapes essentielles de la collecte (théorique) et de la préparation des données. Nous avons : - Chargé et inspecté un jeu de données. - Géré les valeurs manquantes par suppression et imputation. - Discuté de la conversion de types et du traitement des outliers. - Créé de nouvelles caractéristiques (feature engineering). - Encodé les variables catégorielles pour les rendre utilisables par les algorithmes. - Mis à l’échelle les variables numériques.
Ce processus est itératif. Vous pourriez revenir à certaines étapes après une première modélisation si les résultats ne sont pas satisfaisants. Par exemple, essayer différentes stratégies d’imputation, créer d’autres caractéristiques, ou choisir un autre type d’encodage.
Votre jeu de données titanic_prepared.csv est maintenant dans un bien meilleur état pour être fourni à des algorithmes de Machine Learning afin de, par exemple, prédire la survie des passagers.
Prochaines étapes possibles : - Séparation des données en ensembles d’entraînement et de test (si pas encore fait pour la mise à l’échelle). - Entraînement de modèles de classification (Régression Logistique, Arbres de Décision, SVM, etc.). - Évaluation fine des modèles et optimisation des hyperparamètres.
7 Annexe : Ressources Utiles
- Documentation Pandas : https://pandas.pydata.org/pandas-docs/stable/
- Documentation Scikit-learn (Prétraitement) : https://scikit-learn.org/stable/modules/preprocessing.html
- “Python for Data Analysis” par Wes McKinney.
- De nombreux tutoriels et articles sur Medium, Towards Data Science, Kaggle Learn.
Copyright
2025 W. Toussile