Code
require(tidyverse)
require(reticulate)require(tidyverse)
require(reticulate)import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsLe prétraitement des données représente un ensemble de procédures initiales appliquées aux données brutes avant de procéder à l’analyse ou à la modélisation en Machine Learning. Cette étape est cruciale, car la qualité et l’utilité des données influencent directement la performance des algorithmes d’apprentissage automatique. Les données dans le monde réel sont souvent incomplètes, bruitées et inconsistentes, ce qui peut induire en erreur les modèles de Machine Learning et mener à des interprétations erronées des résultats.
Dans cette section, nous aborderons les techniques essentielles de prétraitement des données, en commençant par la gestion des valeurs manquantes, le filtrage du bruit et des outliers, la normalisation et la standardisation des données pour une uniformité de l’échelle, et l’encodage des variables catégorielles. À travers des exemples pratiques en R, nous illustrerons comment appliquer ces techniques pour préparer efficacement un ensemble de données pour l’analyse et la modélisation.
Dans les sections suivantes, nous explorerons chaque aspect du prétraitement en détail, en fournissant des exemples de code R pour guider le lecteur à travers les étapes pratiques du traitement des données.
Tout au long de ce tutoriel, nous considérons les données titanic. On trouve ce jeu de données dans le package titanic de R et dans seaborn de Python
Les données
# Charger titanic
titanic = titanic::titanic_train
# Affichier les permières lignes
titanic |>
head() |>
knitr::kable()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.2500 | S | |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.9250 | S | |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | S | |
| 6 | 0 | 3 | Moran, Mr. James | male | NA | 0 | 0 | 330877 | 8.4583 | Q |
Résumé des données
titanic |>
summary() |>
knitr::kable()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min. : 1.0 | Min. :0.0000 | Min. :1.000 | Length:891 | Length:891 | Min. : 0.42 | Min. :0.000 | Min. :0.0000 | Length:891 | Min. : 0.00 | Length:891 | Length:891 | |
| 1st Qu.:223.5 | 1st Qu.:0.0000 | 1st Qu.:2.000 | Class :character | Class :character | 1st Qu.:20.12 | 1st Qu.:0.000 | 1st Qu.:0.0000 | Class :character | 1st Qu.: 7.91 | Class :character | Class :character | |
| Median :446.0 | Median :0.0000 | Median :3.000 | Mode :character | Mode :character | Median :28.00 | Median :0.000 | Median :0.0000 | Mode :character | Median : 14.45 | Mode :character | Mode :character | |
| Mean :446.0 | Mean :0.3838 | Mean :2.309 | NA | NA | Mean :29.70 | Mean :0.523 | Mean :0.3816 | NA | Mean : 32.20 | NA | NA | |
| 3rd Qu.:668.5 | 3rd Qu.:1.0000 | 3rd Qu.:3.000 | NA | NA | 3rd Qu.:38.00 | 3rd Qu.:1.000 | 3rd Qu.:0.0000 | NA | 3rd Qu.: 31.00 | NA | NA | |
| Max. :891.0 | Max. :1.0000 | Max. :3.000 | NA | NA | Max. :80.00 | Max. :8.000 | Max. :6.0000 | NA | Max. :512.33 | NA | NA | |
| NA | NA | NA | NA | NA | NA’s :177 | NA | NA | NA | NA | NA | NA |
Les données
import seaborn as sns
import pandas as pd
# Charger titanic
titanic = sns.load_dataset("titanic")
titanic.head() survived pclass sex age ... deck embark_town alive alone
0 0 3 male 22.0 ... NaN Southampton no False
1 1 1 female 38.0 ... C Cherbourg yes False
2 1 3 female 26.0 ... NaN Southampton yes True
3 1 1 female 35.0 ... C Southampton yes False
4 0 3 male 35.0 ... NaN Southampton no True
[5 rows x 15 columns]Résumé des données
titanic.describe() survived pclass age sibsp parch fare
count 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200Le nettoyage des données est une étape préliminaire essentielle qui consiste à corriger ou à supprimer les données incorrectes, incomplètes, inexactes, irrélevantes ou mal formatées dans un dataset. Dans cette section, nous nous concentrerons sur deux aspects majeurs du nettoyage des données : le traitement des valeurs manquantes et le filtrage du bruit et des outliers.
Les valeurs manquantes peuvent fausser les analyses et affecter négativement la performance des modèles de Machine Learning. Plusieurs stratégies peuvent être adoptées pour gérer les valeurs manquantes :
Avant de traiter les valeurs manquantes, nous devons d’abord les identifier.
Example 1 (Exemple d’identification des données manquantes)
# Identifier les valeurs manquantes
apply(titanic, 2, function(x) sum(is.na(x))) |>
knitr::kable()| x | |
|---|---|
| PassengerId | 0 |
| Survived | 0 |
| Pclass | 0 |
| Name | 0 |
| Sex | 0 |
| Age | 177 |
| SibSp | 0 |
| Parch | 0 |
| Ticket | 0 |
| Fare | 0 |
| Cabin | 0 |
| Embarked | 0 |
titanic.apply(lambda x: x.isna().sum())survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64Example 2 (Exemple d’Imputation)
# Imputation par la moyenne pour la colonne Age
titanic$Age <- ifelse(is.na(titanic$Age), mean(titanic$Age, na.rm = TRUE), titanic$Age)
# Vérification
apply(titanic, 2, function(x) sum(is.na(x))) |>
knitr::kable()| x | |
|---|---|
| PassengerId | 0 |
| Survived | 0 |
| Pclass | 0 |
| Name | 0 |
| Sex | 0 |
| Age | 0 |
| SibSp | 0 |
| Parch | 0 |
| Ticket | 0 |
| Fare | 0 |
| Cabin | 0 |
| Embarked | 0 |
Imputation de age
# Imputation par la moyenne
titanic["age"] = titanic["age"].fillna(titanic["age"].mean())
# Vérification
titanic.apply(lambda x: x.isna().sum())survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64Imputation de deck en exo
Les outliers peuvent biaiser ou invalider les résultats des analyses statistiques et des modèles de prédiction. Il est donc crucial de les identifier et de décider d’une stratégie appropriée pour les gérer.
La méthode de l’écart interquartile (IQR) pour détecter les outliers consiste à identifier les valeurs qui sont plus éloignées de la médiane. En pratique, ces valeurs sont celles qui sont plus petites que \(Q_1 - 1.5 \times IQR\) ou plus grandes que \(Q_3 + 1.5 \times IQR\)., où \(Q_1\) et \(Q_3\) sont les permier et troisième quartiles, et \(IQR=Q_3-Q_1\) est l’intervalle interquartile.
Example 3 (Exemple de Détection d’Outliers)
Boxe plot
require(ggplot2)
ggplot(data = titanic, mapping = aes(y=Age)) +
geom_boxplot() +
theme_minimal()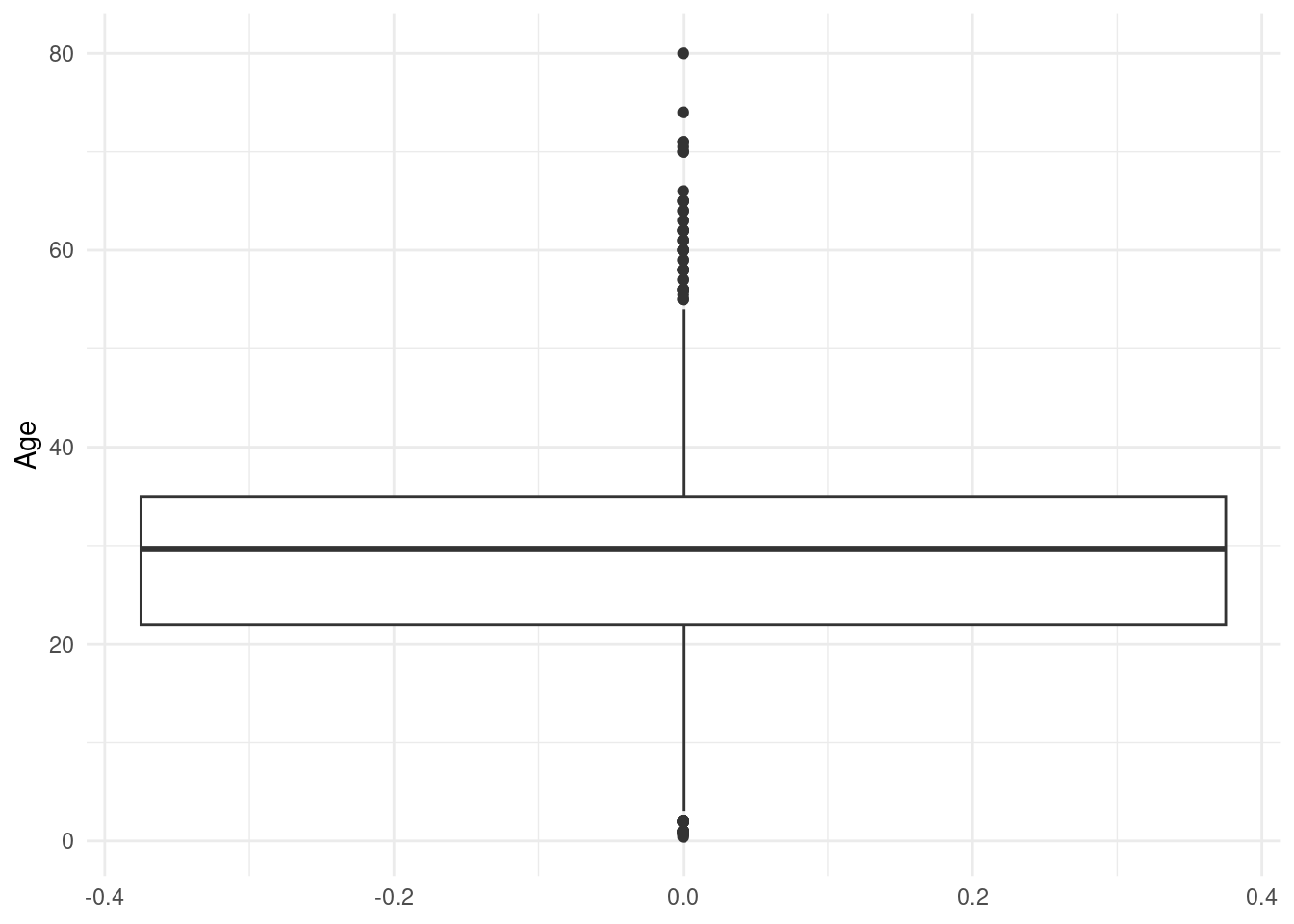
# Calculer l'IQR pour la colonne age
q1 <- quantile(titanic$Age, probs = 0.25)
q3 <- quantile(titanic$Age, probs = 0.75)
iqr <- q3 - q1
# Détection des outliers
outliers_A <- which(titanic$Age < q1 - 1.5 * iqr | titanic$Age > q3 + 1.5 * iqr)
cat("Nombre de outliers: ", length(outliers_A), "\n")Nombre de outliers: 66 import matplotlib.pyplot as plt
import seaborn as sns
titanic.boxplot(column = "age", vert = False)
plt.show()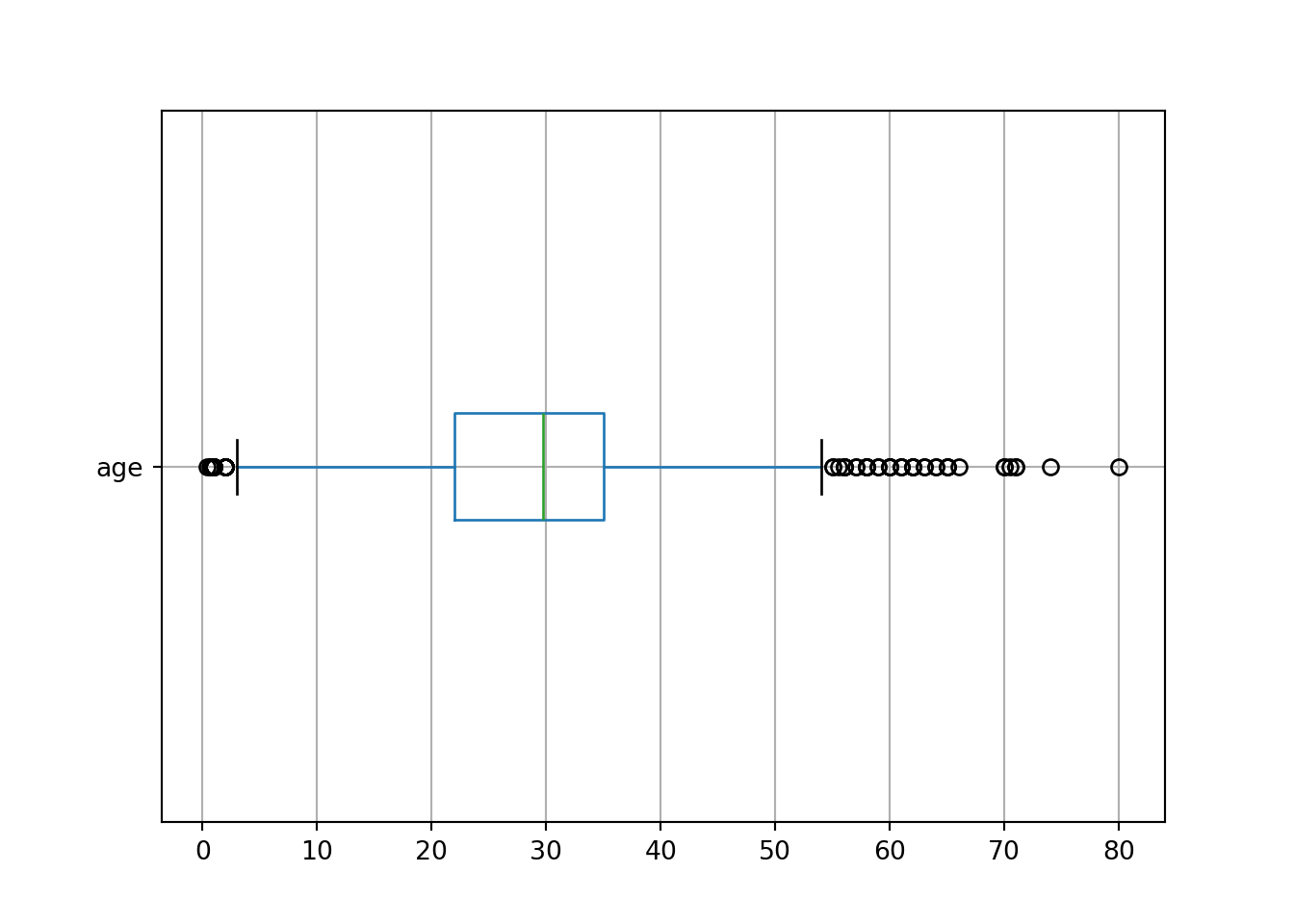
q1 = titanic["age"].quantile(0.25)
q3 = titanic["age"].quantile(0.75)
iqr = q3 - q1
# Détection des outliers
outliers_A = titanic[(titanic["age"] < q1 - 1.5 * iqr) | (titanic["age"] > q3 + 1.5 * iqr)].index
print(f"Nombre de outliers: {len(outliers_A)}")Nombre de outliers: 66Il existe d’autres approches pour détecter les outliers, notamment :
Une fois les outliers identifiés, plusieurs stratégies peuvent être envisagées :
Example 4 (Exemple de Filtrage (Suppression)) Supposons que nous ayons identifié les outliers dans la colonne Age du jeu de données titanic (variable outliers_A de l’exemple précédent).
# Créer une copie pour ne pas modifier l'original directement dans cet exemple
titanic_filtered_r <- titanic
# Nombre d'observations avant suppression
cat("Nombre d'observations avant suppression:", nrow(titanic_filtered_r), "\n")Nombre d'observations avant suppression: 891 # Supprimer les lignes contenant des outliers dans 'Age'
# Note: outliers_A contient les indices des lignes
if(length(outliers_A) > 0) {
titanic_filtered_r <- titanic_filtered_r[-outliers_A, ]
}
cat("Nombre d'observations après suppression:", nrow(titanic_filtered_r), "\n")Nombre d'observations après suppression: 825 # Afficher les premières lignes du dataframe filtré
titanic_filtered_r |> head() |> knitr::kable()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.00000 | 1 | 0 | A/5 21171 | 7.2500 | S | |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.00000 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.00000 | 0 | 0 | STON/O2. 3101282 | 7.9250 | S | |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.00000 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.00000 | 0 | 0 | 373450 | 8.0500 | S | |
| 6 | 0 | 3 | Moran, Mr. James | male | 29.69912 | 0 | 0 | 330877 | 8.4583 | Q |
# Créer une copie
titanic_filtered_py = titanic.copy()
# Nombre d'observations avant suppression
print(f"Nombre d'observations avant suppression: {len(titanic_filtered_py)}")Nombre d'observations avant suppression: 891# outliers_A contient les index des lignes outliers
if len(outliers_A) > 0:
titanic_filtered_py = titanic_filtered_py.drop(outliers_A)
print(f"Nombre d'observations après suppression: {len(titanic_filtered_py)}")Nombre d'observations après suppression: 825# Afficher les premières lignes
titanic_filtered_py.head() survived pclass sex age ... deck embark_town alive alone
0 0 3 male 22.0 ... NaN Southampton no False
1 1 1 female 38.0 ... C Cherbourg yes False
2 1 3 female 26.0 ... NaN Southampton yes True
3 1 1 female 35.0 ... C Southampton yes False
4 0 3 male 35.0 ... NaN Southampton no True
[5 rows x 15 columns]Un nombre élevé d’outliers peut significativement impacter la qualité de vos analyses et la performance de vos modèles. Il n’existe pas de solution universelle, et l’approche adéquate dépendra de la nature de vos données et de vos objectifs. Voici une démarche et des stratégies à considérer :
Investigation Approfondie de la Source des Outliers (Crucial !)
Avant toute intervention, il est impératif de comprendre l’origine de ces outliers :
Stratégies de Traitement (Adaptées à l’Investigation)
Correction (si possible) : Si des erreurs claires sont identifiées et corrigeables (ex: unité de mesure erronée), c’est la meilleure option.
Transformation des Données : Des transformations comme le logarithme, la racine carrée, ou la transformation de Box-Cox peuvent réduire l’asymétrie et “rapprocher” les outliers du corps principal des données, diminuant leur influence. C’est souvent une bonne approche pour les outliers naturels dans des distributions asymétriques.
# Exemple de transformation log sur 'Fare' (Titanic)
# Ajouter une petite constante si des zéros sont présents
titanic_transformed_r <- titanic
titanic_transformed_r$Fare_log <- log(titanic_transformed_r$Fare + 1)
# Visualisation avant et après
par(mfrow=c(1,2))
hist(titanic$Fare, main="Fare Original", xlab="Fare", col="lightblue")
hist(titanic_transformed_r$Fare_log, main="Fare Log-Transformé", xlab="Log(Fare)", col="lightgreen")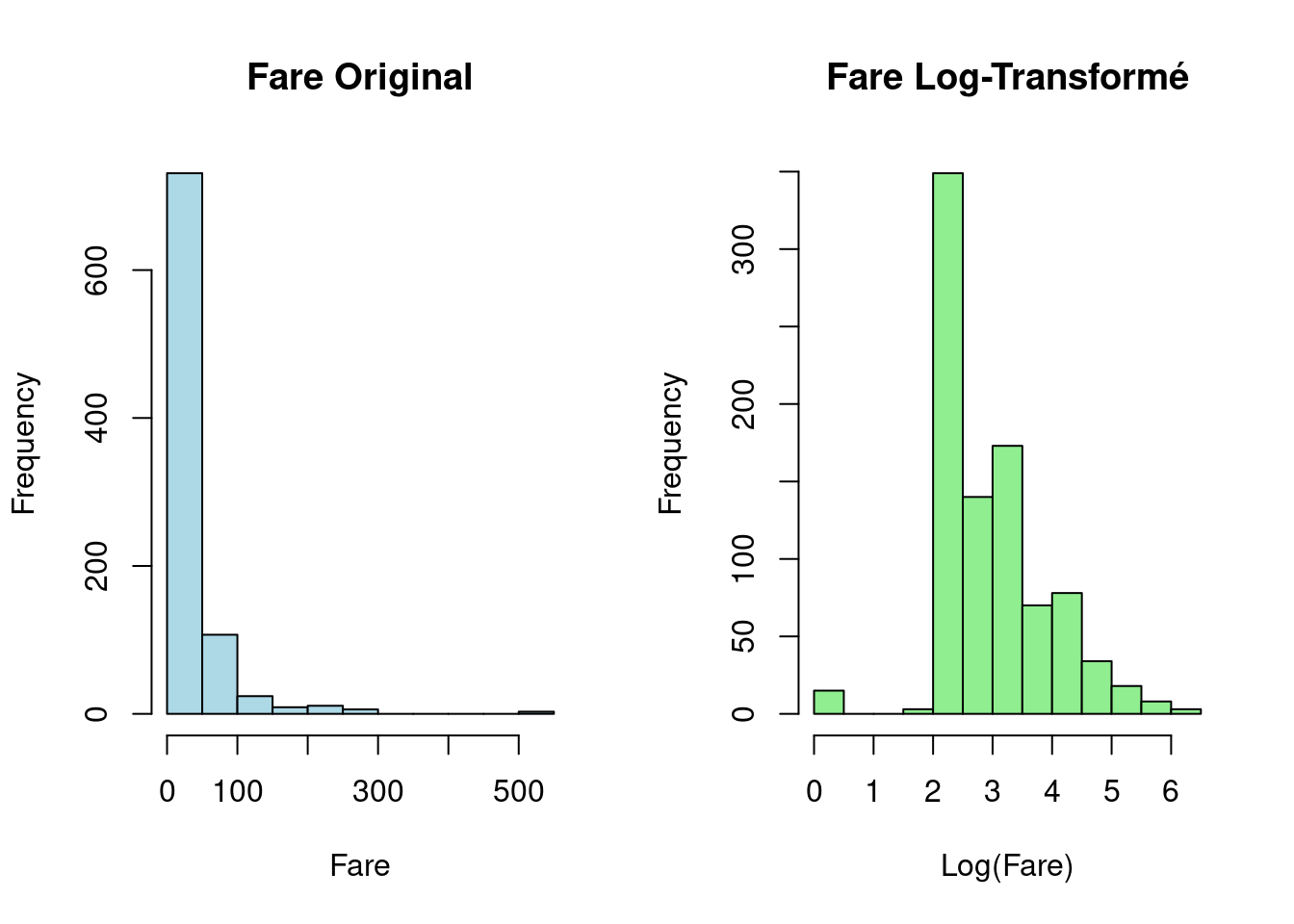
par(mfrow=c(1,1))# Exemple de transformation log sur 'fare' (Titanic)
titanic_transformed_py = titanic.copy()
# np.log1p(x) calcule log(1+x), gérant les zéros de manière appropriée
titanic_transformed_py['fare_log'] = np.log1p(titanic_transformed_py['fare'])
# Visualisation avant et après
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
sns.histplot(titanic['fare'], ax=ax[0], kde=True, color="skyblue").set_title('Fare Original')
sns.histplot(titanic_transformed_py['fare_log'], ax=ax[1], kde=True, color="lightcoral").set_title('Fare Log-Transformé')
plt.tight_layout()
plt.show()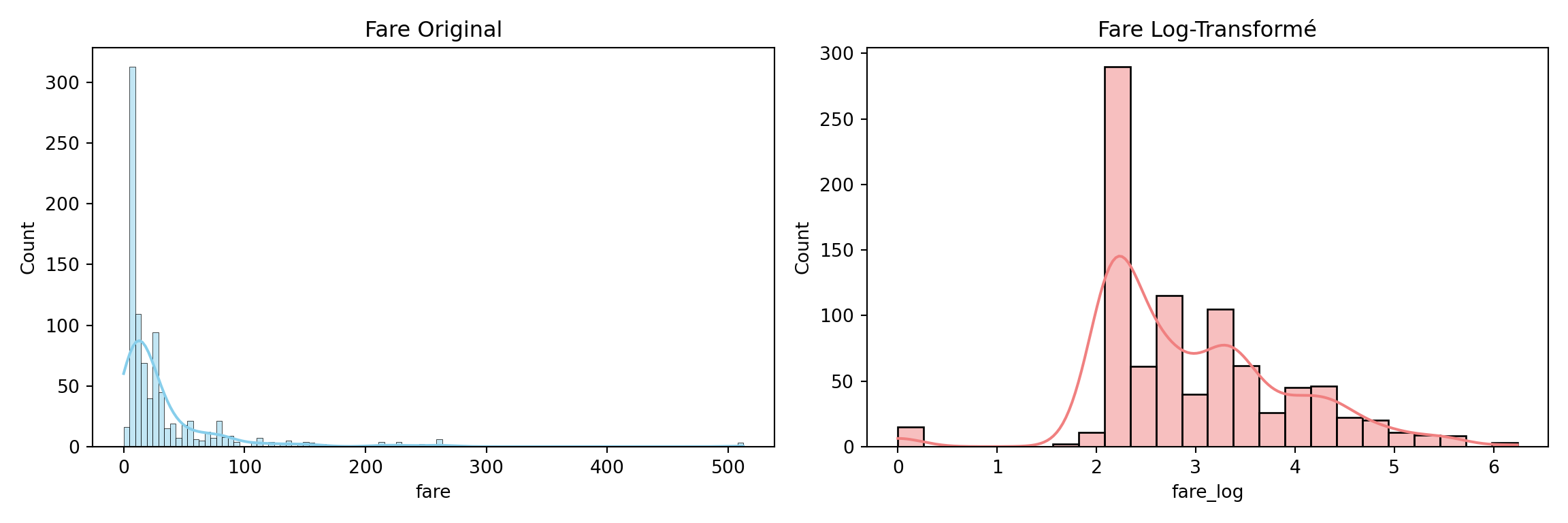
Winsorisation (ou Capping) : Au lieu de supprimer les outliers, on les remplace par la valeur non-outlier la plus proche (ex: le 1er et le 99ème percentile, ou \(Q_1 - 1.5 \times IQR\) et \(Q_3 + 1.5 \times IQR\)). Cela réduit leur impact sans perdre les observations.
# Winsorisation pour la colonne Age (exemple avec les bornes IQR)
# Assumons que 'titanic' est chargé et 'Age' a été imputé
q1_age_r <- quantile(titanic$Age, 0.25, na.rm = TRUE)
q3_age_r <- quantile(titanic$Age, 0.75, na.rm = TRUE)
iqr_age_r <- q3_age_r - q1_age_r
lower_bound_age_r <- q1_age_r - 1.5 * iqr_age_r
upper_bound_age_r <- q3_age_r + 1.5 * iqr_age_r
titanic_winsorized_r <- titanic
titanic_winsorized_r$Age_winsorized <- ifelse(
titanic_winsorized_r$Age < lower_bound_age_r, lower_bound_age_r,
ifelse(titanic_winsorized_r$Age > upper_bound_age_r, upper_bound_age_r, titanic_winsorized_r$Age)
)
summary(titanic$Age) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.42 22.00 29.70 29.70 35.00 80.00 summary(titanic_winsorized_r$Age_winsorized) Min. 1st Qu. Median Mean 3rd Qu. Max.
2.50 22.00 29.70 29.38 35.00 54.50 # Winsorisation pour la colonne age (exemple avec les bornes IQR)
# Assumons que 'titanic' est chargé et 'age' a été imputé
q1_age_py = titanic["age"].quantile(0.25)
q3_age_py = titanic["age"].quantile(0.75)
iqr_age_py = q3_age_py - q1_age_py
lower_bound_age_py = q1_age_py - 1.5 * iqr_age_py
upper_bound_age_py = q3_age_py + 1.5 * iqr_age_py
titanic_winsorized_py = titanic.copy()
titanic_winsorized_py['age_winsorized'] = np.clip(
titanic_winsorized_py['age'],
lower_bound_age_py,
upper_bound_age_py
)
print("Original Age stats:")Original Age stats:print(titanic['age'].describe())count 891.000000
mean 29.699118
std 13.002015
min 0.420000
25% 22.000000
50% 29.699118
75% 35.000000
max 80.000000
Name: age, dtype: float64print("\nWinsorized Age stats:")
Winsorized Age stats:print(titanic_winsorized_py['age_winsorized'].describe())count 891.000000
mean 29.376817
std 12.062035
min 2.500000
25% 22.000000
50% 29.699118
75% 35.000000
max 54.500000
Name: age_winsorized, dtype: float64Utiliser des Algorithmes Robustes aux Outliers : Certains modèles (ex: arbres de décision, Random Forest, Gradient Boosting, régression quantile) sont intrinsèquement moins sensibles aux outliers. Choisir un tel algorithme peut être une solution viable.
Suppression (avec Extrême Prudence) : Si, après investigation, les outliers sont confirmés comme des erreurs non corrigeables et nuisibles, la suppression peut être envisagée. Cependant, une suppression massive peut biaiser les données et réduire la puissance statistique. Justifiez et documentez toujours cette démarche.
Traiter les Outliers comme un Groupe Séparé : S’ils représentent une sous-population distincte, analysez-les séparément ou créez une variable binaire “est_outlier” comme nouvelle caractéristique.
Réviser la Méthode de Détection ou les Seuils : Explorez d’autres méthodes de détection (Z-score, DBSCAN, Isolation Forest) ou ajustez les seuils (ex: 3 * IQR au lieu de 1.5 * IQR) si la méthode actuelle semble inadaptée.
Considérations Finales
En résumé, face à un grand nombre d’outliers, privilégiez la compréhension et l’investigation avant d’appliquer une solution. Les transformations et la winsorisation sont souvent de bons compromis pour atténuer l’influence des outliers sans perdre une quantité excessive d’informations.
Le nettoyage des données est un processus itératif et dépendant du contexte. Les stratégies doivent être choisies en fonction des objectifs spécifiques de l’analyse ou de la modélisation prévue. En suivant les étapes décrites ci-dessus et en utilisant les exemples de code R, les chercheurs et les analystes peuvent améliorer significativement la qualité de leurs données, conduisant à des analyses plus fiables et des modèles de prédiction plus précis.
La normalisation et la standardisation sont deux approches de mise à l’échelle des données qui aident à uniformiser la portée des variables caractéristiques, permettant ainsi aux algorithmes de machine learning de les traiter de manière équitable.
La normalisation ajuste les données de telle sorte que leurs valeurs se situent dans une échelle commune, généralement entre 0 et 1. Cette technique est particulièrement utile pour les algorithmes qui calculent des distances entre les données, comme le K-means clustering ou le KNN.
On parle de normalisation Min-Max lorsque l’intervalle visé est \([0, 1]\).
Example 5 (Exemple de Normalisation) Utilisons la méthode Min-Max pour normaliser un dataset.
# Chargement de la bibliothèque
require(scales)
# Création d'un exemple de dataset
data_norm <- data.frame(
A = rnorm(100, mean = 5, sd = 2),
B = runif(100, min = 2, max = 5)
)
# Normalisation Min-Max
data_norm <- as.data.frame(lapply(data_norm, function(x) scales::rescale(x, to = c(0, 1))))
data_norm |>
head(n = 5) A B
1 1.0000000 0.5932604
2 0.6186863 0.8315955
3 0.4888564 0.2325049
4 0.4170607 0.0674324
5 0.4337969 0.1958853La standardisation redimensionne les données de sorte que leur distribution ait une moyenne de \(0\) et un écart type de \(1\). Elle est utile pour les algorithmes qui supposent que toutes les variables caractéristiques ont une distribution normale, comme la régression logistique, les machines à vecteurs de support et les perceptrons multicouches.
Example 6 (Exemple de Standardisation)
data_stand <- data.frame(
A = rnorm(100, mean = 5, sd = 2),
B = runif(100, min = 2, max = 5)
)
data_stand <- as.data.frame(scale(data_stand))
data_stand |>
head(n = 5) A B
1 -0.6367093 0.104486467
2 -1.0235900 0.001727342
3 0.6261473 0.785434769
4 -0.2384861 1.582460515
5 0.4047274 0.900353446Normalisation est préférée lorsque vous ne savez pas la distribution des données ou lorsque vous savez que la distribution n’est pas Gaussienne. Elle est également utile lorsque vous avez besoin de valeurs dans une plage liée.
Standardisation est recommandée lorsque les données suivent une distribution normale. Cependant, elle est également utile car elle conserve les informations sur les outliers et rend l’algorithme moins sensible aux valeurs aberrantes par rapport à la normalisation.
Il est essentiel de comprendre la nature de vos données et les exigences de l’algorithme que vous utilisez pour choisir la méthode la plus appropriée. Dans de nombreux cas, expérimenter avec les deux méthodes et comparer les performances du modèle peut être la meilleure approche pour déterminer quelle méthode de mise à l’échelle est la plus efficace pour votre problème spécifique.
Après avoir étudié les différentes techniques de prétraitement des données, mettez vos connaissances en pratique avec les exercices suivants. Assurez-vous d’avoir le package tidyverse installé et chargé dans votre session R pour certains de ces exercices.
Exercise 1 Le dataset airquality intégré à R contient des mesures de la qualité de l’air avec quelques valeurs manquantes.
airquality.Ozone par une valeur appropriée de votre choix.Solar.R_filled dans laquelle vous remplacerez les valeurs manquantes de Solar.R par une stratégie d’imputation de votre choix, mais appliquez cette stratégie uniquement sous certaines conditions que vous définirez basées sur les autres variables du dataset.Exercise 2 (Normalisation et Standardisation) Travaillez toujours avec le dataset airquality. Cette fois, vous vous concentrerez sur la mise à l’échelle des variables numériques.
Wind en utilisant la méthode Min-Max pour que ses valeurs soient comprises entre 0 et 1.Temp de sorte que sa distribution ait une moyenne de 0 et un écart-type de 1.Exercise 3 (Encodage des Variables Catégorielles) Les variables catégorielles doivent souvent être encodées numériquement avant de pouvoir être utilisées dans la plupart des modèles de machine learning.
Color avec les valeurs “Red”, “Blue”, et “Green”.Exercise 4 (Exercice Pratique Complet : Prétraitement du jeu de données “Pima Indians Diabetes”) Cet exercice vise à appliquer plusieurs techniques de prétraitement sur le jeu de données “Pima Indians Diabetes”. Ce jeu de données est utilisé pour prédire l’apparition du diabète en se basant sur certaines mesures diagnostiques. Il est connu pour contenir des zéros qui représentent en réalité des valeurs manquantes pour certaines colonnes.
Objectifs :
Jeu de données :
Le jeu de données peut être téléchargé depuis diverses sources. Pour cet exercice, nous utiliserons une version accessible via une URL. Il comprend les variables suivantes : Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Age, Outcome (variable cible : 0 ou 1).
Étapes et Questions :
https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'].Glucose, BloodPressure, SkinThickness, Insulin, BMI ne peuvent logiquement pas avoir une valeur de 0. Identifiez le nombre de zéros dans ces colonnes.NA (ou np.nan en Python).Glucose et BloodPressure par la médiane de leurs colonnes respectives.SkinThickness et Insulin, qui peuvent avoir un grand nombre de valeurs manquantes, discutez d’une stratégie d’imputation (par exemple, médiane, ou suppression si le pourcentage est trop élevé, ou une imputation plus avancée). Mettez en œuvre l’imputation par la médiane pour cet exercice.Insulin (après imputation). Visualisez sa distribution (histogramme, boxplot).Insulin. Combien y en a-t-il ?Conseils pour la réalisation :
```{r}
#| eval: false
# Noms des colonnes
col_names <- c('Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome')
# 1. Chargement
# pima_df <- read.csv("https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv", header = FALSE, col.names = col_names)
# 2. Zéros implicites
# cols_to_check_zeros <- c('Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI')
# pima_df[cols_to_check_zeros] <- lapply(pima_df[cols_to_check_zeros], function(x) ifelse(x == 0, NA, x))
# Imputation : pima_df$Glucose[is.na(pima_df$Glucose)] <- median(pima_df$Glucose, na.rm = TRUE)
# 3. Outliers (exemple pour Insulin)
# q1_insulin <- quantile(pima_df$Insulin, 0.25, na.rm = TRUE)
# ... (calcul IQR et bornes)
# pima_df$Insulin_winsorized <- ifelse(pima_df$Insulin > upper_bound_insulin, upper_bound_insulin, pima_df$Insulin)
# 4. Standardisation
# features_to_scale <- pima_df[, setdiff(col_names, "Outcome")] # Exclure la variable cible si elle existe et est traitée
# scaled_features <- scale(features_to_scale)
``````{python}
#| eval: false
# Noms des colonnes
col_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
# 1. Chargement
# pima_df = pd.read_csv("https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv", header=None, names=col_names)
# 2. Zéros implicites
# cols_to_check_zeros = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
# pima_df[cols_to_check_zeros] = pima_df[cols_to_check_zeros].replace(0, np.nan)
# Imputation: pima_df['Glucose'].fillna(pima_df['Glucose'].median(), inplace=True)
# 3. Outliers (exemple pour Insulin)
# Q1_insulin = pima_df['Insulin'].quantile(0.25)
# ... (calcul IQR et bornes)
# pima_df['Insulin_winsorized'] = np.clip(pima_df['Insulin'], lower_bound_insulin, upper_bound_insulin)
# 4. Standardisation
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# features_to_scale = pima_df.drop('Outcome', axis=1) # Assurez-vous que Outcome n'est pas inclus si non désiré
# scaled_features = scaler.fit_transform(features_to_scale)
# scaled_pima_df = pd.DataFrame(scaled_features, columns=features_to_scale.columns)
```Cet exercice vous permettra de consolider votre compréhension des étapes clés du prétraitement des données. Bonne chance !