Les objets suivants sont masqués depuis 'package:stats':
filter, lag
Les objets suivants sont masqués depuis 'package:base':
intersect, setdiff, setequal, union
Code
require(ggplot2)
Le chargement a nécessité le package : ggplot2
Introduction
Dans de nombreuses analyses de données, nous rencontrons des situations où nous devons examiner la relation entre une variable quantitative (mesurée numériquement) et une variable qualitative (catégorielle). Ce chapitre explore les méthodes et les outils pour analyser et interpréter ce type de relation.
L’objectif de cette analyse descriptive est d’explorer visuellement et numériquement les éventuelles associations entre ces deux types de variables, sans recourir à des tests statistiques formels. En d’autres termes, nous allons examiner comment les valeurs de la variable quantitative varient en fonction des différentes modalités de la variable qualitative.
Cette approche descriptive nous permettra de :
Identifier les tendances et les motifs potentiels dans les données.
Formuler des hypothèses pour des analyses ultérieures plus approfondies.
Fournir une base solide pour la compréhension des relations entre les variables.
Il est important de noter que, en l’absence de tests statistiques, les conclusions tirées de cette analyse seront de nature descriptive et ne pourront pas établir de relations causales ou généralisables à l’ensemble de la population.
Dans les sections suivantes, nous explorerons les méthodes graphiques et les indicateurs statistiques descriptifs qui nous permettront d’analyser en détail la relation entre nos variables d’intérêt.
Visualisation des données
Boxplots (Boîtes à moustaches)
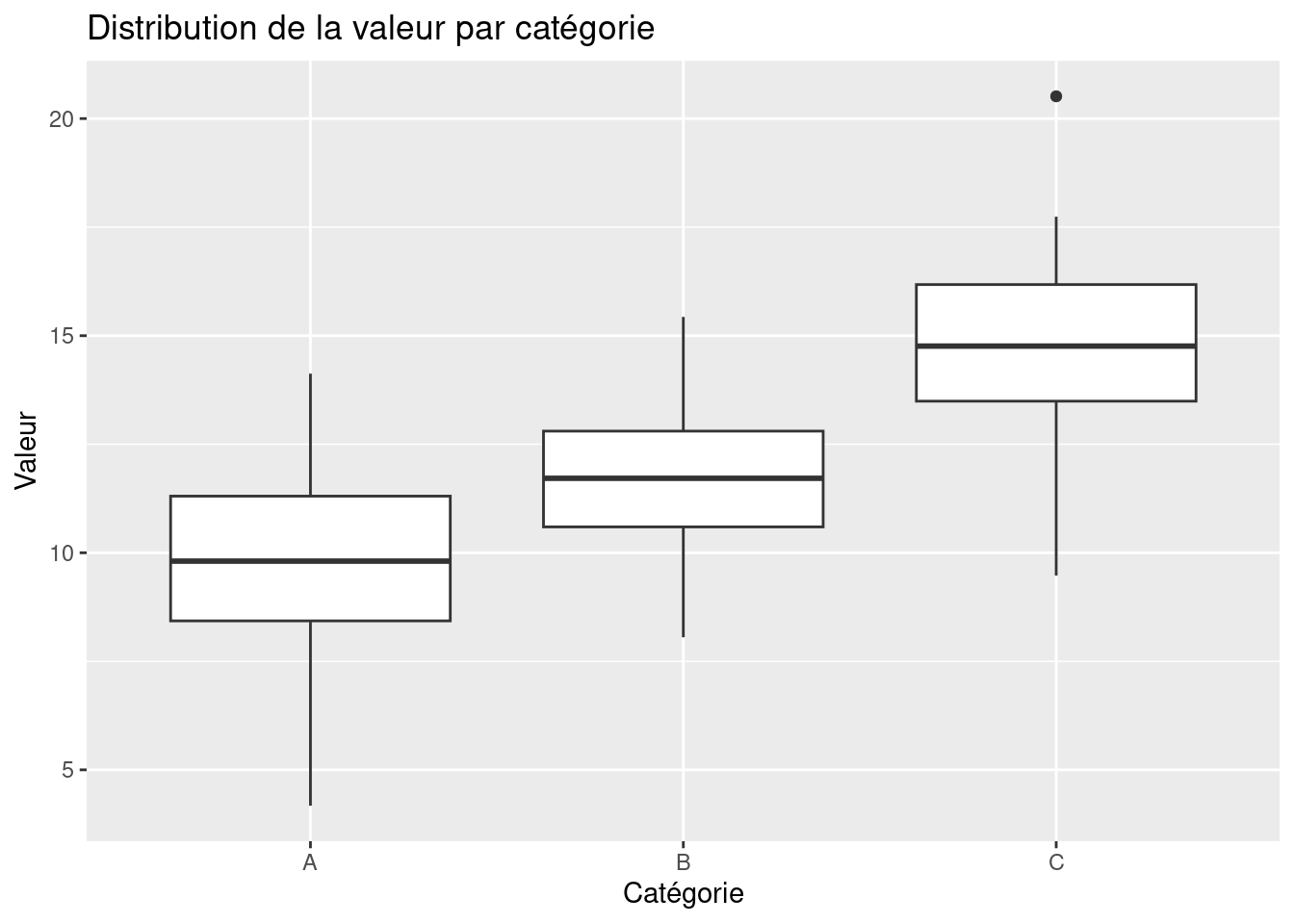
Les boxplots sont un excellent moyen de visualiser la distribution d’une variable quantitative pour chaque catégorie d’une variable qualitative.
Code
require(ggplot2)# Exemple de donnéesdata <-data.frame(categorie =factor(rep(c("A", "B", "C"), each =50)),valeur =c(rnorm(50, 10, 2), rnorm(50, 12, 2), rnorm(50, 15, 2)))ggplot(data, aes(x = categorie, y = valeur)) +geom_boxplot() +labs(title ="Distribution de la valeur par catégorie", x ="Catégorie", y ="Valeur")
Dans le graphique ci-dessus, nous pouvons observer :
La médiane : Représentée par la ligne au centre de chaque boîte, elle indique la valeur médiane pour chaque groupe.
Les quartiles : Les bords de la boîte représentent le premier (Q1) et le troisième quartile (Q3), délimitant la plage où se trouvent 50 % des données.
Les moustaches : Elles s’étendent généralement jusqu’à 1,5 fois l’écart interquartile (IQR) à partir des quartiles, et les points au-delà sont considérés comme des valeurs aberrantes.
Les valeurs aberrantes : Représentées par des points individuels, elles peuvent indiquer des observations inhabituelles ou des erreurs de données.
En comparant les boîtes à moustaches, nous pouvons identifier les différences de médianes, de dispersions et de présence de valeurs aberrantes entre les groupes.
Histogrammes groupés
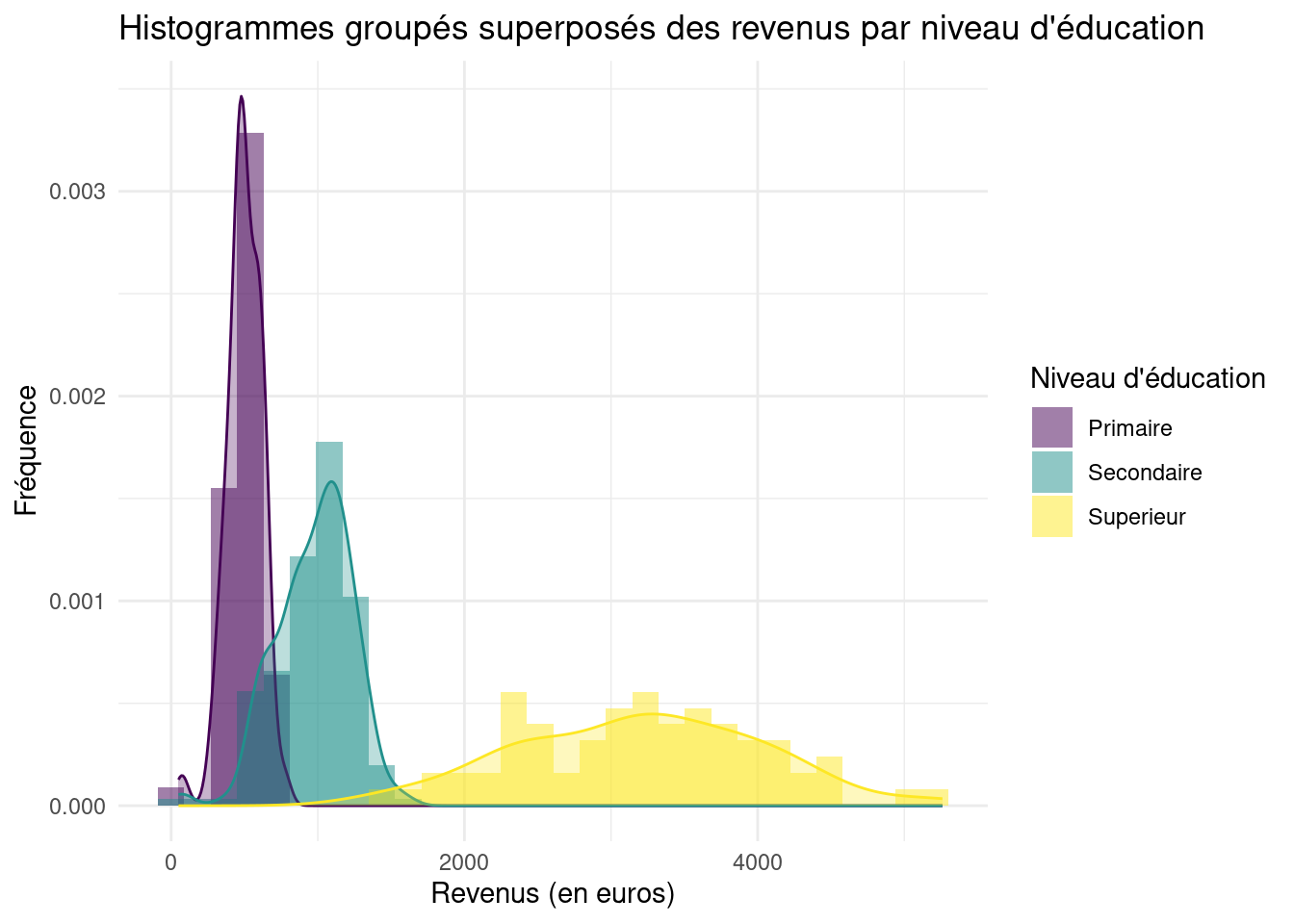
Les histogrammes groupés offrent une autre perspective en affichant la distribution de la variable quantitative pour chaque modalité de la variable qualitative. Ils permettent de comparer les formes, les centres et les étendues des distributions.
Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Histogrammes groupés superposés des revenus par niveau d’éducation avec ggplot2.
Dans les histogrammes ci-dessus, nous pouvons observer :
La forme de la distribution : Symétrique, asymétrique, bimodale, etc.
Le centre de la distribution : La position de la moyenne ou de la médiane.
L’étendue de la distribution : La plage de revenus observés.
La comparaison des histogrammes permet d’identifier les différences de formes et de tendances entre les niveaux d’éducation.
Introduction
Dans ce chapitre, nous allons détailler le calcul du rapport de corrélation \(\eta^2\) en utilisant les sommes des carrés. Cette approche, étroitement liée à l’analyse de la variance (ANOVA), permet de comprendre comment la variance d’une variable quantitative est expliquée par les modalités d’une variable qualitative.
Définitions
Variable quantitative (Y): Les données numériques que nous analysons.
Variable qualitative (X): Les catégories ou groupes qui divisent les données.
\(y_{k,i}\): La i-ème observation de la variable Y dans la modalité k de la variable X.
\(\bar{y}_k\): La moyenne des observations de Y dans la modalité k de X.
\(\bar{y}\): La moyenne globale de toutes les observations de Y.
\(n_k\): Le nombre d’observations dans la modalité k de X.
n: Le nombre total d’observations.
Sommes des carrés
Somme des carrés totale (SCT):
Mesure la variation totale des données Y autour de la moyenne globale \(\bar{y}\).