Mise en œuvre d’un workflow de classification de A à Z
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Contexte du Projet
Vous êtes data scientist pour une grande entreprise de télécommunications, “ConnectTel”. La direction est préoccupée par le taux de résiliation des clients (le “churn”). Perdre un client coûte cher, car il faut en acquérir de nouveaux pour compenser.
Votre mission est de construire un modèle de Machine Learning capable d’identifier les clients les plus susceptibles de résilier leur abonnement. L’objectif final est de permettre à l’équipe marketing de cibler ces clients à risque avec des offres de fidélisation proactives, avant qu’il ne soit trop tard.
2 Objectifs de l’Atelier
Ce projet vous guidera à travers toutes les étapes d’un projet de classification du monde réel :
Analyse Exploratoire des Données (EDA) : Comprendre les caractéristiques des clients qui partent et ceux qui restent.
Pré-traitement des Données : Préparer les données pour la modélisation (gestion des valeurs manquantes, encodage, mise à l’échelle).
Entraînement et Comparaison de Modèles : Entraîner au moins 3 classifieurs différents pour comparer leurs performances.
Évaluation et Interprétation : Évaluer les modèles avec des métriques pertinentes pour le problème (au-delà de la simple exactitude) et justifier le choix du meilleur modèle pour l’entreprise.
3 Le Jeu de Données : Telco Customer Churn
Nous utiliserons le jeu de données classique “Telco Customer Churn”, disponible sur Kaggle. Il contient des informations sur les clients d’une entreprise de télécom, leurs services souscrits, et s’ils ont résilié leur contrat ou non.
La première étape est de charger les données et de se faire une première idée de leur structure.
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# Configurationsns.set_theme(style="whitegrid")plt.rcParams['figure.figsize'] = (12, 7)# Chargement des donnéestry: df = pd.read_csv('https://raw.githubusercontent.com/IBM/telco-customer-churn-on-icp4d/master/data/Telco-Customer-Churn.csv')except:print("Erreur de chargement, veuillez vérifier l'URL ou votre connexion.")# Créer un dataframe vide pour que le reste du code ne plante pas df = pd.DataFrame()ifnot df.empty:print("Données chargées. Dimensions:", df.shape)print("\nAperçu des données :")print(df.head())print("\nInformations sur les colonnes et les types de données :") df.info()
Données chargées. Dimensions: (7043, 21)
Aperçu des données :
customerID gender SeniorCitizen Partner Dependents tenure PhoneService \
0 7590-VHVEG Female 0 Yes No 1 No
1 5575-GNVDE Male 0 No No 34 Yes
2 3668-QPYBK Male 0 No No 2 Yes
3 7795-CFOCW Male 0 No No 45 No
4 9237-HQITU Female 0 No No 2 Yes
MultipleLines InternetService OnlineSecurity ... DeviceProtection \
0 No phone service DSL No ... No
1 No DSL Yes ... Yes
2 No DSL Yes ... No
3 No phone service DSL Yes ... Yes
4 No Fiber optic No ... No
TechSupport StreamingTV StreamingMovies Contract PaperlessBilling \
0 No No No Month-to-month Yes
1 No No No One year No
2 No No No Month-to-month Yes
3 Yes No No One year No
4 No No No Month-to-month Yes
PaymentMethod MonthlyCharges TotalCharges Churn
0 Electronic check 29.85 29.85 No
1 Mailed check 56.95 1889.5 No
2 Mailed check 53.85 108.15 Yes
3 Bank transfer (automatic) 42.30 1840.75 No
4 Electronic check 70.70 151.65 Yes
[5 rows x 21 columns]
Informations sur les colonnes et les types de données :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
4.2 Étape 2 : Analyse Exploratoire (EDA)
Votre tâche : Explorez les données pour répondre aux questions suivantes.
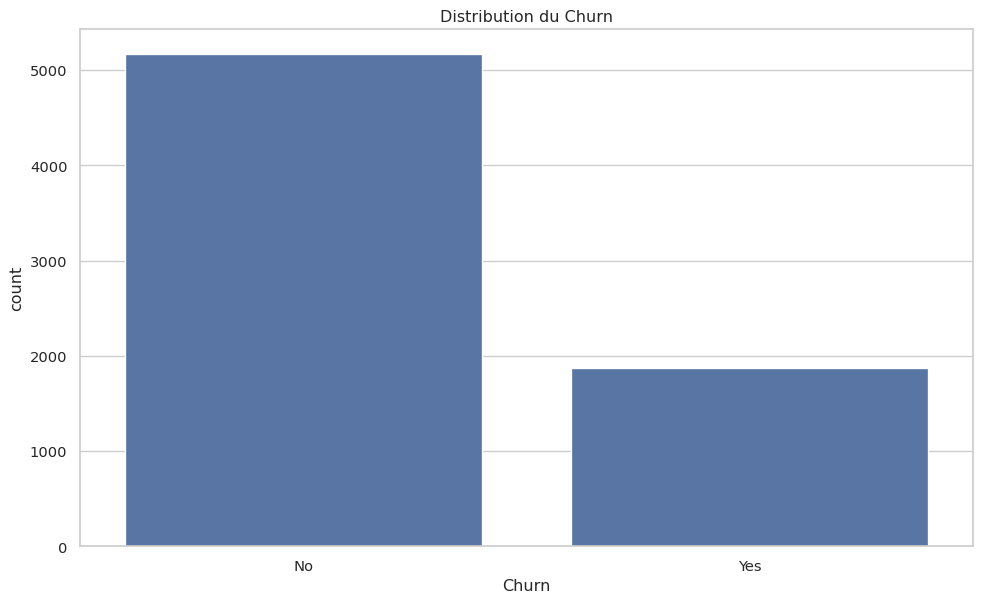
Quelle est la proportion de clients qui ont résilié (Churn) ?
Le jeu de données est-il déséquilibré ?
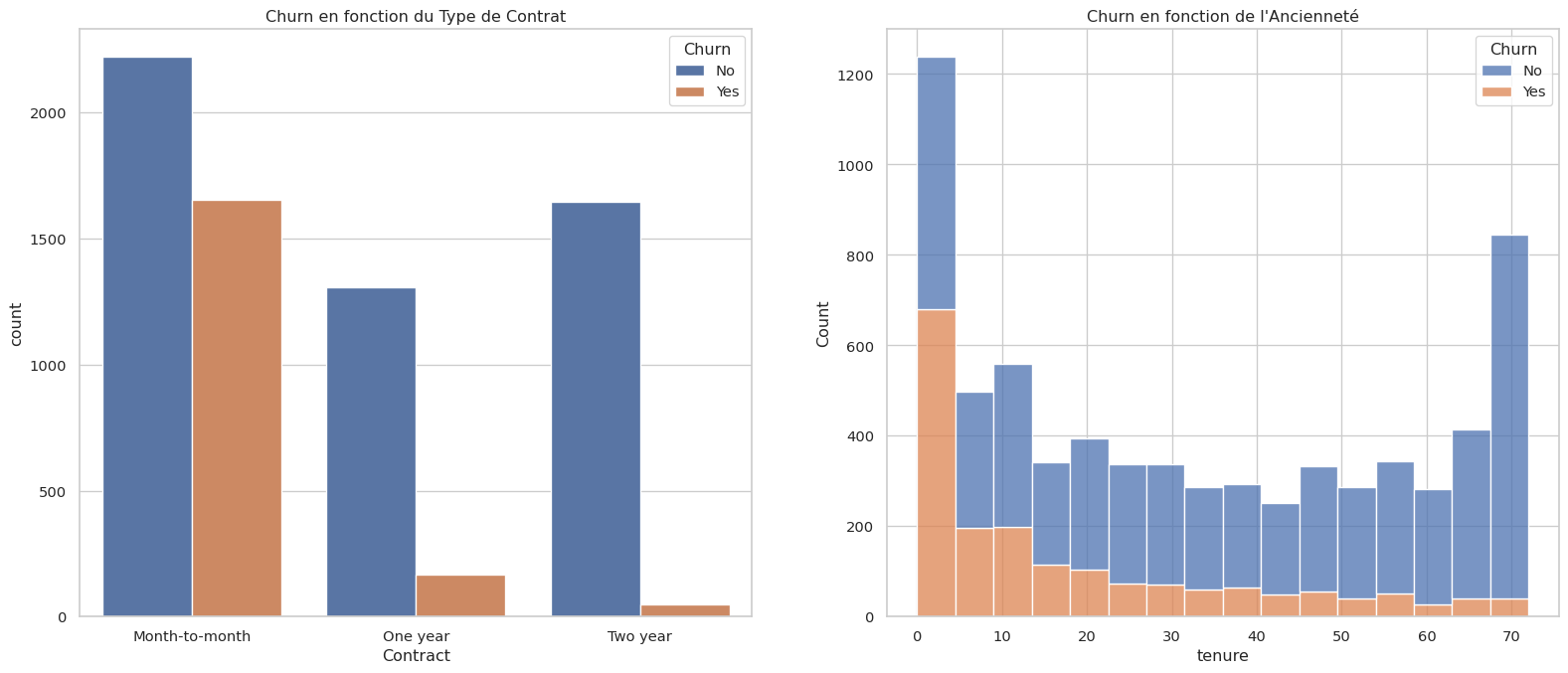
Visualisez la relation entre le Churn et quelques variables clés :
Le type de contrat (Contract).
L’ancienneté (tenure).
Les frais mensuels (MonthlyCharges).
ifnot df.empty:# 1. Proportion de Churn plt.figure() sns.countplot(x='Churn', data=df) plt.title('Distribution du Churn') plt.show()print(df['Churn'].value_counts(normalize=True))# 2. Visualisations bivariées fig, axes = plt.subplots(1, 2, figsize=(20, 8))# Churn vs Contract sns.countplot(x='Contract', hue='Churn', data=df, ax=axes[0]) axes[0].set_title('Churn en fonction du Type de Contrat')# Churn vs Tenure sns.histplot(data=df, x='tenure', hue='Churn', multiple='stack', ax=axes[1]) axes[1].set_title('Churn en fonction de l\'Ancienneté') plt.show()
Churn
No 0.73463
Yes 0.26537
Name: proportion, dtype: float64
Analyse rapide : On voit que les clients avec un contrat mensuel (Month-to-month) et une faible ancienneté (tenure) sont beaucoup plus susceptibles de partir.
4.3 Étape 3 : Pré-traitement des Données
Votre tâche : Préparez les données pour la modélisation.
Gérez la colonne TotalCharges qui a un type object à cause de quelques valeurs vides. Convertissez-la en numérique.
Encodez les variables catégorielles.
Mettez à l’échelle les variables numériques.
Divisez les données en ensembles d’entraînement et de test.
(Indice : Un Pipeline et un ColumnTransformer sont vos meilleurs amis pour cette étape !)
4.4 Étape 4 : Entraînement et Comparaison des Modèles
Votre tâche : Entraînez au moins 3 des modèles que nous avons étudiés (ex: LogisticRegression, RandomForestClassifier, GradientBoostingClassifier).
Créez des pipelines pour chaque modèle.
Entraînez-les sur le jeu de données d’entraînement.
Faites des prédictions sur le jeu de test.
4.5 Étape 5 : Évaluation et Choix du Meilleur Modèle
Votre tâche : Évaluez et comparez vos modèles.
Pour chaque modèle, générez la matrice de confusion et le rapport de classification (classification_report).
Comparez leurs performances, en vous concentrant sur les métriques les plus importantes pour ce problème.
Justifiez votre choix : Quel modèle recommanderiez-vous à l’entreprise ? Pourquoi ? Quelle est la métrique la plus importante à optimiser ici (Précision ? Rappel ? F1-Score ?) et pourquoi ?
(Indice : Est-il plus grave pour l’entreprise de prédire à tort qu’un client va rester (Faux Négatif) ou de prédire à tort qu’il va partir (Faux Positif) ? La réponse à cette question dictera votre choix de métrique.)
5 Livrable Attendu
Un document Quarto ou un notebook jupyter complet contenant :
Votre code Python pour chaque étape.
Les visualisations générées.
Des cellules de texte (en Markdown) où vous expliquez votre démarche, analysez vos résultats et, surtout, répondez de manière argument