# Imports et configuration de base
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Appliquer le style par défaut de Seaborn
sns.set_theme(style="whitegrid", palette="viridis")
plt.rcParams['figure.figsize'] = (10, 6)
1 Introduction
Si Matplotlib est le moteur de la visualisation en Python, Seaborn est la carrosserie de luxe avec un GPS intégré. Construite sur Matplotlib, cette bibliothèque vous permet de créer des graphiques statistiques complexes, informatifs et esthétiques avec une facilité déconcertante.
Pourquoi choisir Seaborn ?
- Syntaxe Intuitive : Vous passez moins de temps à écrire du code et plus de temps à interpréter vos graphiques.
- Esthétique Supérieure : Les styles et palettes de couleurs par défaut sont conçus pour la clarté et la publication.
- Focalisation Statistique : Seaborn excelle à révéler les distributions et les relations au sein de vos données.
- Intégration Parfaite : Fonctionne de manière transparente avec les DataFrames Pandas.
Ce guide vous montrera comment utiliser Seaborn pour répondre aux questions fondamentales que vous vous posez sur vos données.
1.1 La Philosophie de Seaborn : Fonctions “Axes-level” vs “Figure-level”
C’est LE concept à comprendre pour maîtriser Seaborn.
Fonctions “Axes-level” :
scatterplot(),histplot(),boxplot(), etc.- Elles dessinent sur un axe Matplotlib spécifique (
ax). - Utilisation : Parfaites lorsque vous voulez composer votre propre grille de graphiques personnalisée avec
plt.subplots(). Vous gardez un contrôle total sur la position de chaque graphique.
- Elles dessinent sur un axe Matplotlib spécifique (
Fonctions “Figure-level” :
relplot(),displot(),catplot(),pairplot().- Elles créent leur propre Figure Matplotlib, qui peut contenir un ou plusieurs sous-graphiques.
- Utilisation : Extrêmement puissantes pour créer rapidement des visualisations complexes en utilisant des arguments comme
col(colonnes),row(lignes) ethue(couleur) pour segmenter vos données.
Nous allons découvrir ces deux types de fonctions en répondant à des questions concrètes.
2 Partie 1 : Comment mes données sont-elles distribuées ?
La première étape de toute analyse est de comprendre la distribution de vos variables.
# Chargement des données
tips = sns.load_dataset("tips")histplot et kdeplot (Axes-level)
L’histogramme (histplot) montre la fréquence des valeurs dans des intervalles (bins), tandis que l’estimation par noyau de densité (kdeplot) montre une version lissée de la distribution.
# On peut même les combiner en une seule ligne !
sns.histplot(data=tips, x="total_bill", kde=True, bins=20)
plt.title("Distribution de la Facture Totale")
plt.show()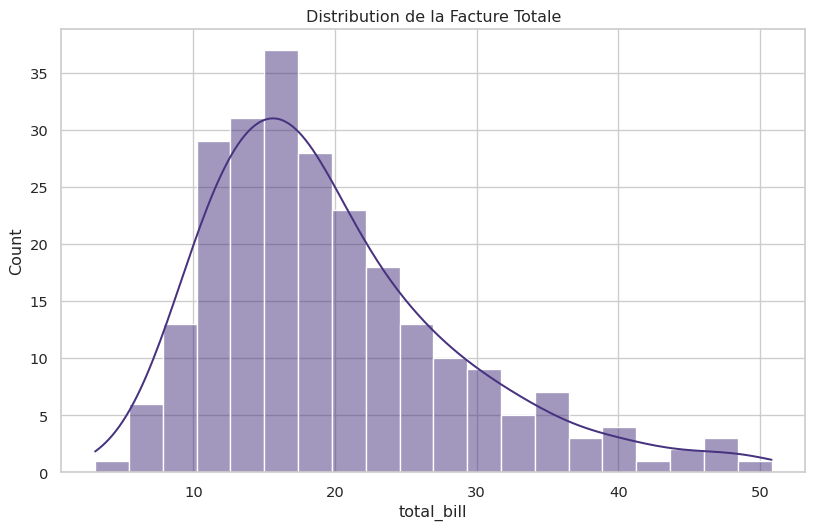
displot (Figure-level)
displot() (distribution plot) est la fonction “figure-level” qui vous permet de créer facilement des histogrammes ou des KDE pour différents sous-ensembles de vos données.
# Créer une colonne de graphiques, un pour chaque jour
sns.displot(data=tips, x="total_bill", col="day", kind="kde", col_wrap=2)
plt.suptitle("Densité de la Facture Totale par Jour", y=1.02)
plt.show()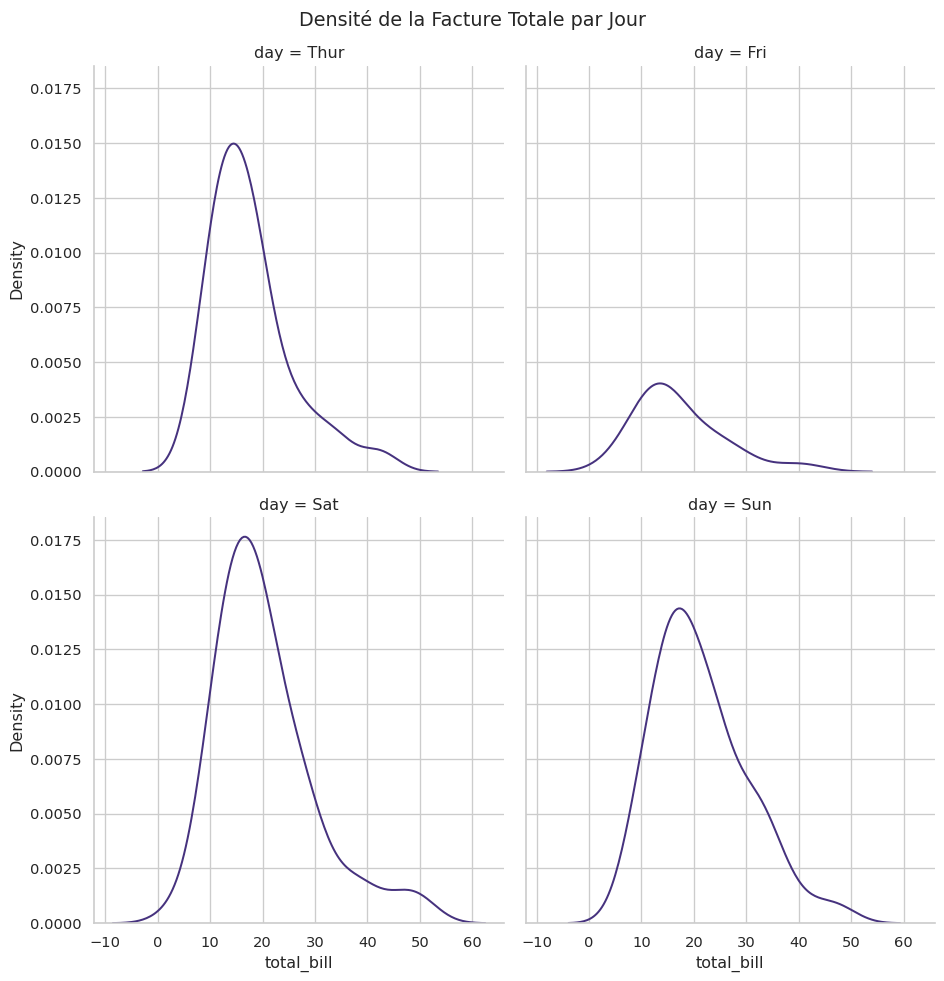
3 Partie 2 : Comment les catégories se comparent-elles ?
Seaborn facilite la comparaison de variables numériques ou de décomptes à travers différentes catégories.
Décomptes et Agrégats (Axes-level)
countplot: Compte les occurrences dans chaque catégorie.barplot: Affiche une estimation d’une tendance centrale (par défaut, la moyenne) pour une variable numérique par catégorie.
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle("Analyse par Catégorie")
# Compte le nombre de fumeurs vs non-fumeurs
sns.countplot(data=tips, x="smoker", ax=axes[0])
axes[0].set_title("Nombre de Fumeurs vs Non-Fumeurs")
# Affiche le pourboire moyen par jour
sns.barplot(data=tips, x="day", y="tip", ax=axes[1])
axes[1].set_title("Pourboire Moyen par Jour")
plt.show()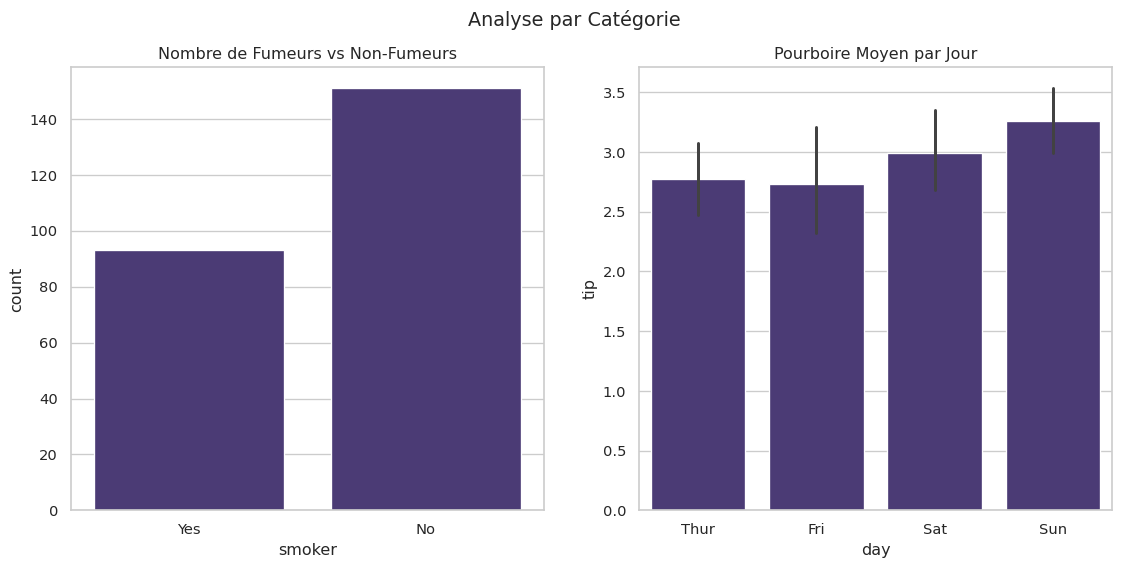
Distributions par Catégorie (Axes-level)
Pour une comparaison plus riche, boxplot et violinplot sont parfaits.
fig, axes = plt.subplots(1, 2, figsize=(14, 6), sharey=True)
fig.suptitle("Distribution du Pourboire par Jour")
sns.boxplot(data=tips, x="day", y="tip", ax=axes[0])
axes[0].set_title("Avec un Boxplot")
# Le violinplot combine un boxplot avec une estimation de la densité
sns.violinplot(data=tips, x="day", y="tip", ax=axes[1])
axes[1].set_title("Avec un Violinplot")
plt.show()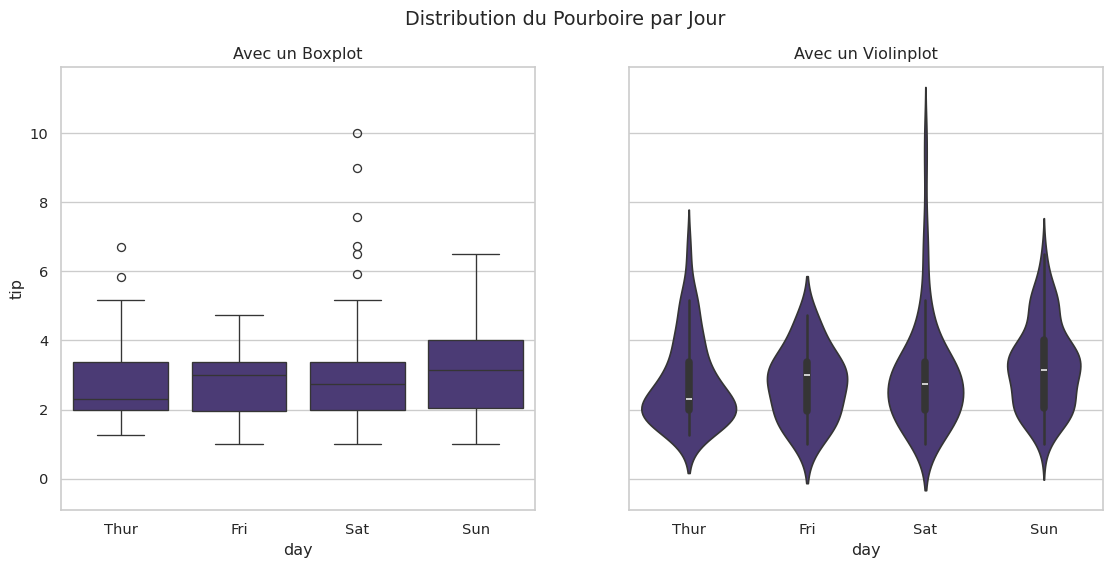
catplot (Figure-level)
catplot() (categorical plot) est le couteau suisse des graphiques catégoriels. En changeant le paramètre kind, il peut se transformer en countplot, barplot, boxplot, etc., tout en offrant la puissance de la segmentation par col et row.
# Comparer le pourboire moyen par jour, en séparant Fumeurs et Non-Fumeurs
sns.catplot(data=tips, x="day", y="tip", col="smoker", kind="bar")
plt.suptitle("Pourboire Moyen par Jour et Statut Fumeur", y=1.02)
plt.show()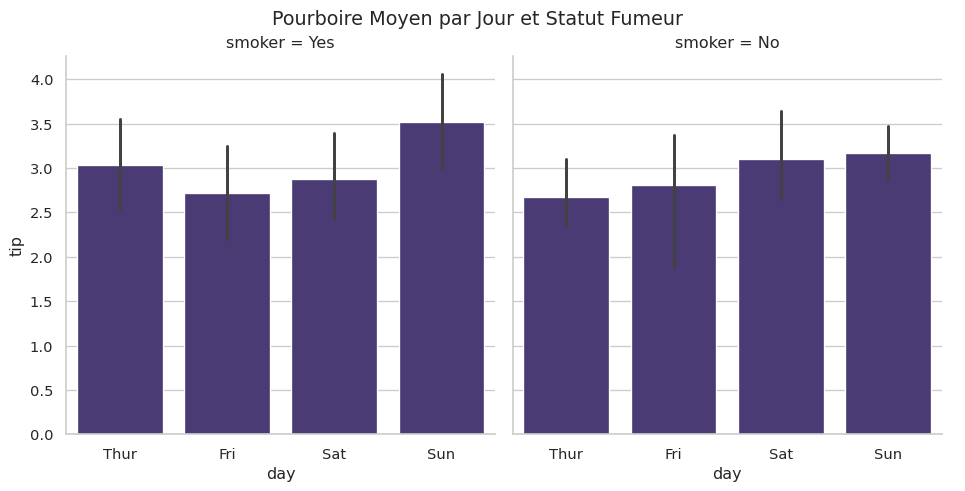
4 Partie 3 : Quelles relations existent dans mes données ?
Seaborn rend l’exploration des relations entre variables simple et visuellement riche.
scatterplot et relplot (Axes-level & Figure-level)
Le nuage de points est la base. scatterplot permet d’ajouter des dimensions via les paramètres hue, size, et style. relplot (relational plot) est son équivalent “figure-level”.
# Utilisons le jeu de données "iris"
iris = sns.load_dataset("iris")
sns.relplot(
data=iris,
x="sepal_length",
y="petal_length",
hue="species", # Couleur par espèce
size="sepal_width", # Taille par largeur du sépale
style="species", # Style de marqueur par espèce
height=6,
aspect=1.5
)
plt.title("Relations dans le jeu de données Iris")
plt.show()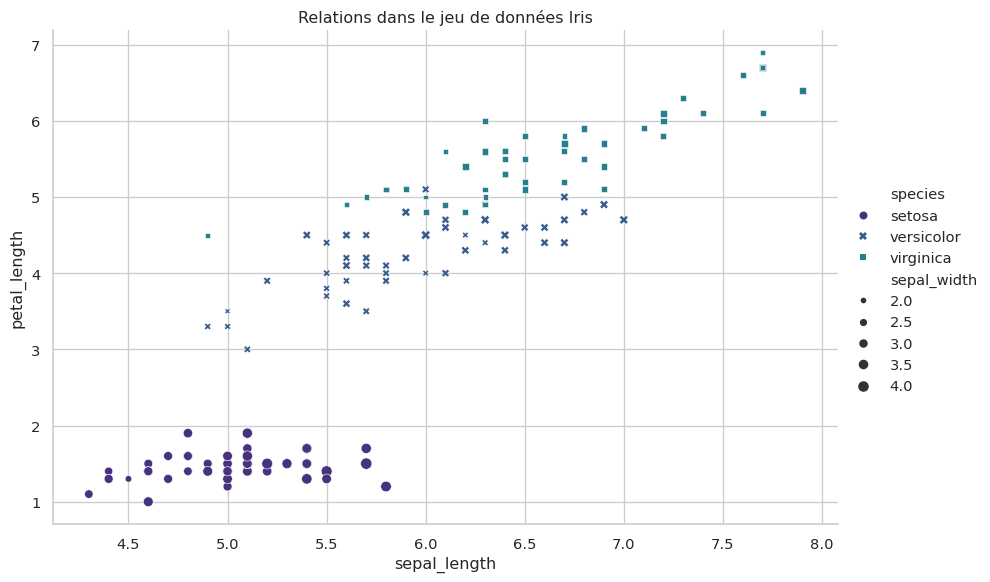
pairplot (Figure-level)
Le pairplot est un incontournable de l’analyse exploratoire. Il crée une grille de nuages de points pour chaque paire de variables et des histogrammes (ou KDE) sur la diagonale.
sns.pairplot(data=iris, hue="species")
plt.suptitle("Vue d'Ensemble des Relations dans Iris", y=1.02)
plt.show()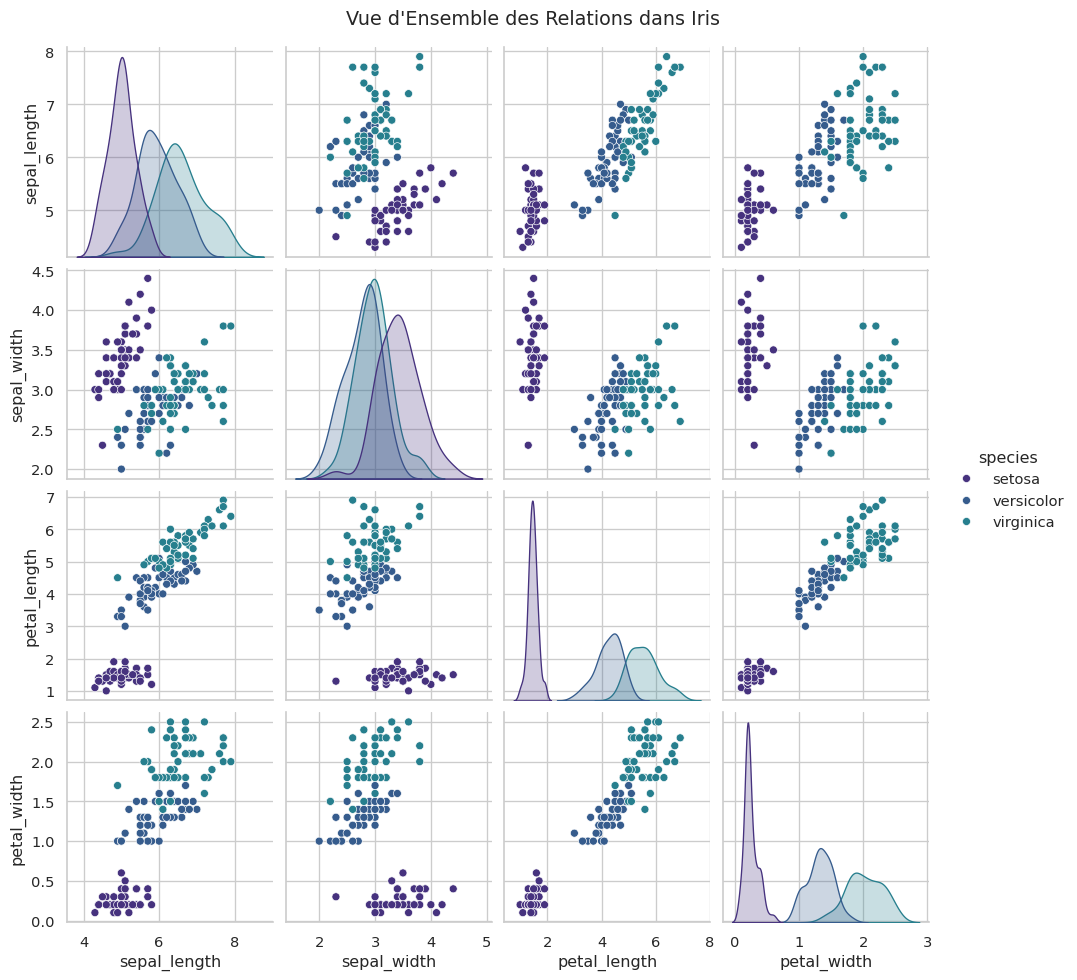
heatmap (Axes-level)
Idéal pour visualiser des matrices, comme les matrices de corrélation.
# Utilisons les données du Titanic
titanic = sns.load_dataset("titanic")
titanic_corr = titanic.select_dtypes(include='number').corr()
plt.figure(figsize=(8, 6))
sns.heatmap(titanic_corr, annot=True, cmap="vlag", fmt=".2f")
plt.title("Matrice de Corrélation (Titanic)")
plt.show()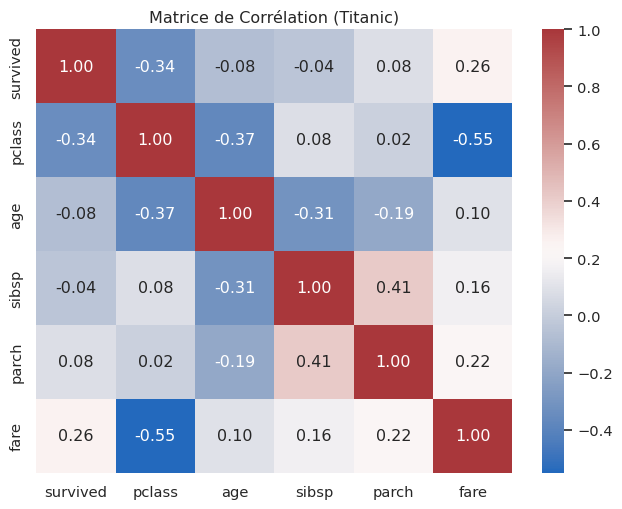
5 Atelier Pratique : Analyse des Survivants du Titanic 🚢
Objectif : Utiliser la puissance de Seaborn pour répondre à des questions sur les survivants du Titanic.
Question 1 : Le sexe a-t-il influencé la survie ?
- Utilisez
countplotpour visualiser le nombre de passagers parsex, en utilisanthue="survived".
- Utilisez
Question 2 : La classe du billet et le port d’embarquement ont-ils joué un rôle dans la survie ?
- Utilisez
catplotaveckind="bar"pour montrer le taux de survie (y="survived") par classe (x="class"), en créant des colonnes par port d’embarquement (col="embark_town").
- Utilisez
Question 3 : Comment l’âge et le tarif différaient-ils entre les survivants ?
- Utilisez des
violinplotpour comparer la distribution deageetfareen fonction de la survie (survived).
- Utilisez des
Question 4 (Synthèse) : Peut-on visualiser la relation entre l’âge, le tarif et la survie ?
- Utilisez
relplot(scatterplot) pour visualiser la relation entreageetfare. Utilisezhue="survived"etcol="pclass"pour une analyse complète.
- Utilisez
Ce guide vous a donné les clés pour transformer vos questions en visualisations claires et percutantes avec Seaborn. La prochaine étape est de l’appliquer à vos propres jeux de données !