import pandas as pd
import matplotlib.pyplot as plt # Charger la bibliothèque de visualisation
import seaborn as sns # Pour les styles et les datasets d'exemple
# Configuration pour un affichage esthétique et intégré
plt.style.use('seaborn-v0_8-whitegrid')
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
1 Introduction
Manipuler des données avec Pandas est une compétence fondamentale. Mais pour réellement comprendre ces données et communiquer vos découvertes, la visualisation est indispensable. Un graphique bien conçu peut révéler des tendances, des anomalies ou des relations qu’un tableau de chiffres ne montrera jamais.
Ce guide est conçu pour vous emmener de votre DataFrame Pandas à un graphique Matplotlib de qualité, en passant de l’exploration rapide à la personnalisation complète.
Objectifs :
- Créer des graphiques essentiels (lignes, barres, histogrammes, boîtes à moustaches, nuages de points) directement depuis Pandas.
- Comprendre l’anatomie d’un graphique Matplotlib (
Figure,Axes). - Maîtriser l’API orientée objet pour un contrôle total sur vos visualisations.
- Composer des tableaux de bord complexes avec plusieurs graphiques (subplots).
- Savoir quand et pourquoi utiliser Seaborn en complément.
1.1 Prérequis : Installation et Imports
1.2 L’Anatomie d’un Graphique Matplotlib anatomy
Avant de coder, il est essentiel de comprendre les deux objets principaux que vous manipulerez :
- La
Figure(fig) : C’est le conteneur global, la toile blanche sur laquelle tout repose. Une figure peut contenir un ou plusieurs graphiques. - Les
Axes(ax) : C’est le graphique en lui-même. Il contient la zone de traçage, les axes (X et Y), le titre, les graduations (ticks), la grille, la légende, etc. C’est sur l’objetaxque l’on effectue 90% des opérations.
La méthode plt.subplots() est la manière la plus courante de créer ces deux objets simultanément.
2 Partie 1 : Exploration Rapide avec pandas.plot() ⚡
Pour une première analyse, la méthode .plot() intégrée à Pandas est imbattable. Elle utilise Matplotlib en coulisses et permet de générer des graphiques instantanément. L’argument kind est votre meilleur ami ici.
# Chargement d'un jeu de données riche
df_gap = sns.load_dataset('tips')
# Supprimer les lignes avec des valeurs manquantes
df_gap.dropna(inplace=True)
df_gap.head()| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
Histogramme : Voir la distribution d’une variable
Quand l’utiliser ? Pour comprendre la répartition, la tendance centrale et la dispersion d’une variable numérique.
plt.figure()
df_gap['total_bill'].plot(kind='hist', bins=20, title='Distribution de la Facture Totale')
plt.xlabel('Facture Totale ($)')
plt.show()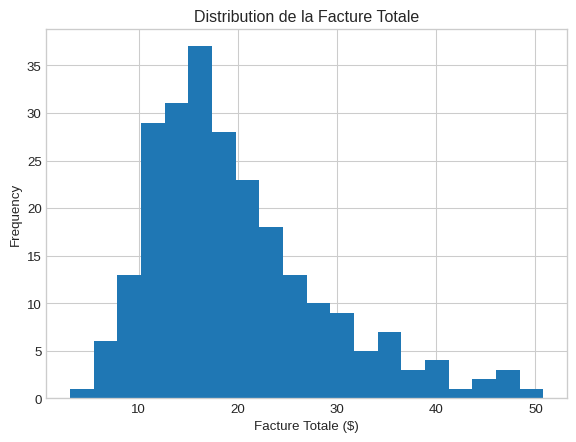
Diagramme en barres : Comparer des catégories
Quand l’utiliser ? Pour comparer une valeur numérique entre différents groupes ou catégories.
# Montant moyen de la facture par jour
plt.figure()
df_gap.groupby('day')['total_bill'].mean().plot(kind='bar', title='Facture Moyenne par Jour')
plt.ylabel('Facture Moyenne ($)')
plt.xlabel('Jour de la semaine')
plt.xticks(rotation=0) # Rendre les labels de l'axe X horizontaux
plt.show()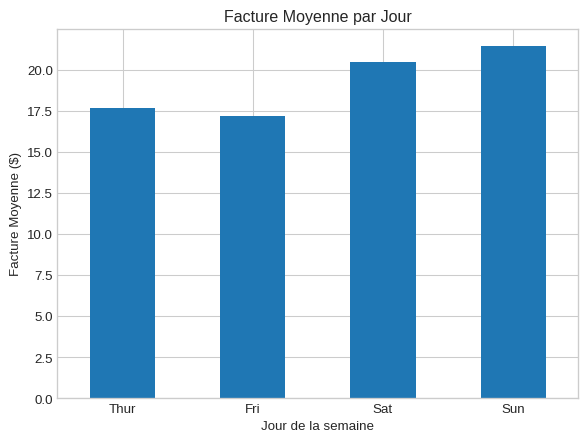
Nuage de points : Révéler les relations
Quand l’utiliser ? Pour visualiser la relation (ou son absence) entre deux variables numériques.
plt.figure()
df_gap.plot(kind='scatter', x='total_bill', y='tip', alpha=0.6,
title='Relation entre la Facture Totale et le Pourboire')
plt.xlabel('Facture Totale ($)')
plt.ylabel('Pourboire ($)')
plt.show()<Figure size 672x480 with 0 Axes>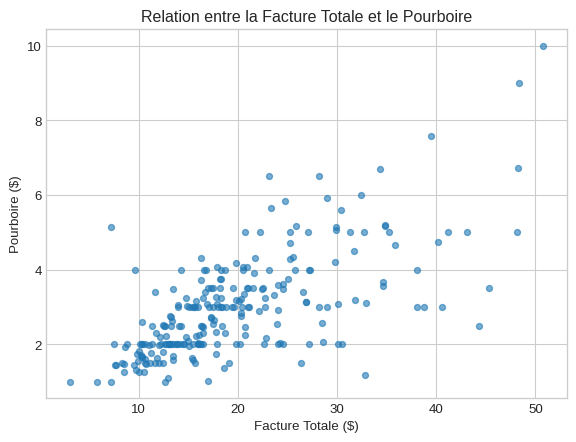
Boîte à moustaches (Boxplot) : Comparer des distributions
Quand l’utiliser ? C’est une version plus puissante du diagramme en barres. Elle montre la médiane, les quartiles et les valeurs aberrantes pour chaque catégorie.
plt.figure()
df_gap.plot(kind='box', x='day', y='total_bill', title='Distribution des Factures par Jour')
# Le titre et les labels sont gérés automatiquement ici, mais nous les supprimerons pour les personnaliser plus tard
plt.suptitle('') # Supprimer le titre par défaut
plt.title('Distribution des Factures par Jour')
plt.xlabel('Jour de la semaine')
plt.ylabel('Facture Totale ($)')
plt.show()<Figure size 672x480 with 0 Axes>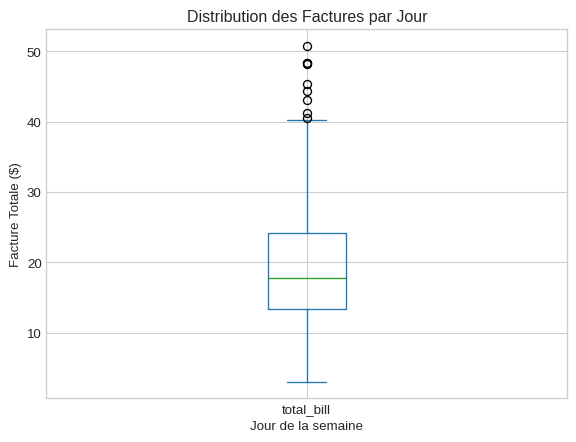
3 Partie 2 : La Puissance de l’API Orientée Objet 🎨
Pour tout ce qui va au-delà de l’exploration de base, l’API orientée objet (fig, ax) est la voie à suivre. Elle offre un contrôle total et une clarté inégalée.
Le Modèle de Base
La structure est toujours la même : créer les objets, tracer les données, personnaliser.
# 1. Créer la Figure et les Axes
plt.figure()
fig, ax = plt.subplots()
# 2. Tracer les données sur les axes `ax`
ax.scatter(df_gap['total_bill'], df_gap['tip'], alpha=0.6)
# 3. Personnaliser les axes `ax`
ax.set_title('Relation Facture Totale vs Pourboire', fontsize=16)
ax.set_xlabel('Facture Totale ($)')
ax.set_ylabel('Pourboire ($)')
ax.grid(True)
plt.show()<Figure size 672x480 with 0 Axes>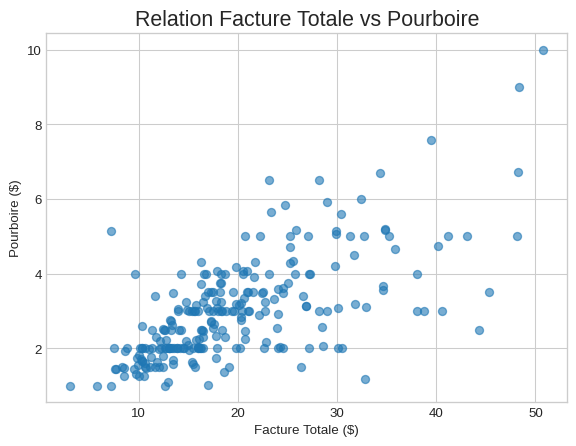
L’Astuce d’Or : Combiner Pandas et l’API Objet ✨
Vous pouvez bénéficier de la simplicité de .plot() tout en gardant le contrôle de l’API objet en passant l’axe ax comme argument. C’est le meilleur des deux mondes !
plt.figure()
fig, ax = plt.subplots()
# On dit à Pandas sur quel axe dessiner
df_gap.plot(kind='scatter', x='total_bill', y='tip', ax=ax, alpha=0.6)
# On garde le contrôle total pour la personnalisation
ax.set_title('Le Meilleur des Deux Mondes', fontsize=16)
ax.set_xlabel('Facture Totale ($)')
ax.set_ylabel('Pourboire ($)')
plt.show()<Figure size 672x480 with 0 Axes>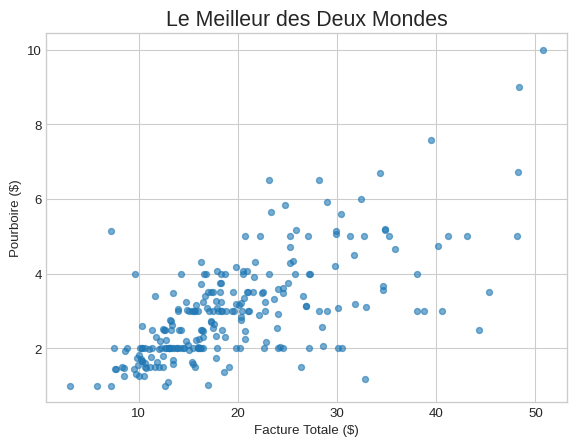
4 Partie 3 : Composer des Vues avec les Subplots 🖼️
La vraie force de l’API objet se révèle lorsque vous devez comparer plusieurs visualisations. plt.subplots() peut créer une grille entière d’axes.
# Créer une grille 1x2. `axes` est maintenant un tableau d'objets ax
plt.figure()
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 6))
# Graphique de gauche
axes[0].hist(df_gap['total_bill'], bins=20)
axes[0].set_title('Distribution de la Facture Totale')
axes[0].set_xlabel('Facture ($)')
# Graphique de droite (en utilisant l'astuce `ax=...`)
smokers_mean = df_gap.groupby('smoker')['tip'].mean()
smokers_mean.plot(kind='bar', ax=axes[1], title='Pourboire Moyen (Fumeur vs Non-Fumeur)')
axes[1].set_ylabel('Pourboire Moyen ($)')
axes[1].tick_params(axis='x', rotation=0)
# Titre global et agencement propre
fig.suptitle('Analyse des Pourboires', fontsize=20)
plt.tight_layout(rect=[0, 0.03, 1, 0.95]) # Ajuste pour le suptitle
plt.show()<Figure size 672x480 with 0 Axes>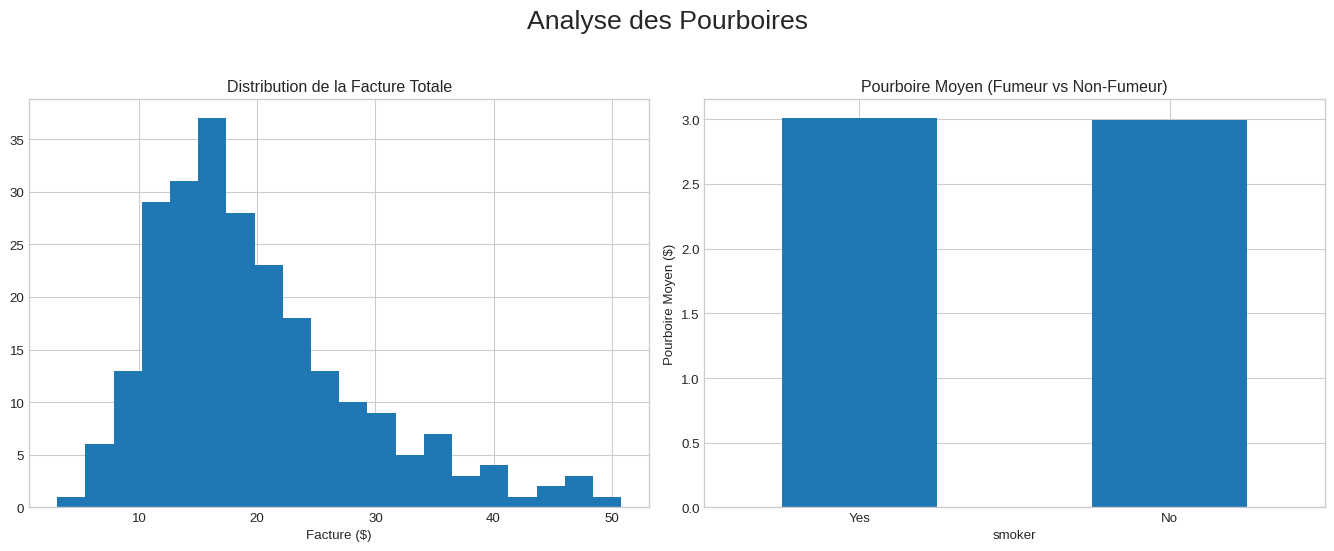
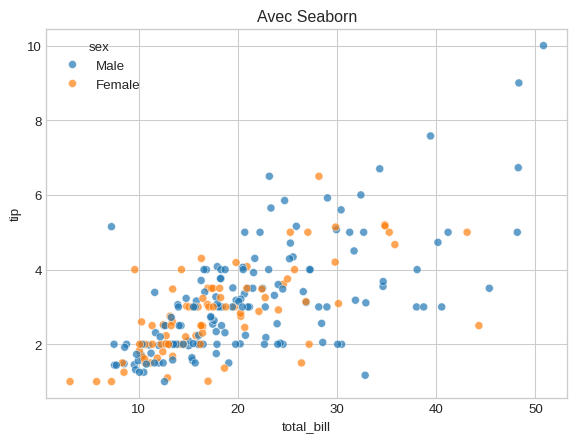
5 Et Seaborn dans tout ça ? 🤔
Seaborn est une bibliothèque construite sur Matplotlib. Elle excelle dans deux domaines :
- Elle produit des graphiques esthétiquement plus plaisants par défaut.
- Elle possède une API de haut niveau qui simplifie énormément la création de graphiques statistiques complexes.
Exemple : Créons un nuage de points où la couleur dépend d’une catégorie.
# La méthode Matplotlib (verbeuse, nécessite une boucle)
plt.figure()
fig, ax = plt.subplots()
colors = {'Male': 'blue', 'Female': 'red'}
for sex, group in df_gap.groupby('sex'):
ax.scatter(group['total_bill'], group['tip'], c=colors[sex], label=sex, alpha=0.7)
ax.legend(title='Sexe')
ax.set_title('Avec Matplotlib Pur')
plt.show()
# La méthode Seaborn (concise et élégante)
fig, ax = plt.subplots()
sns.scatterplot(data=df_gap, x='total_bill', y='tip', hue='sex', alpha=0.7, ax=ax)
ax.set_title('Avec Seaborn')
plt.show()<Figure size 672x480 with 0 Axes>
6 Conclusion
Utilisez Matplotlib pour le contrôle fin et les graphiques de base. Tournez-vous vers Seaborn dès que vous voulez créer des visualisations statistiques complexes (regplot, violinplot, heatmap…) avec une syntaxe simple.
7 Atelier Pratique Final : Tableau de Bord d’Analyse 🚀
Objectif : Mettre en pratique tous les concepts pour créer un tableau de bord 2x2 analysant le jeu de données gapminder.
Préparation :
- Chargez les données :
df_gapminder = px.data.gapminder().
- Chargez les données :
Création de la Grille :
- Créez une figure avec une grille 2x2 d’axes (
fig, axes = plt.subplots(2, 2, ...)).
- Créez une figure avec une grille 2x2 d’axes (
Remplissage des Graphiques :
En haut à gauche (axes[0, 0]) : Évolution de l’espérance de vie.
- Préparez les données :
life_exp_time = df_gapminder.groupby('year')['lifeExp'].mean(). - Tracez un graphique en lignes.
- Préparez les données :
En haut à droite (axes[0, 1]) : Distribution du PIB par habitant en 2007.
- Filtrez les données pour l’année 2007.
- Tracez un histogramme de
gdpPercapet mettez l’axe X en échelle logarithmique (ax.set_xscale('log')).
En bas à gauche (axes[1, 0]) : Espérance de vie par continent en 2007.
- Utilisez un
boxplotou unviolinplot(avec Seaborn) pour comparer la distribution delifeExpparcontinent.
- Utilisez un
En bas à droite (axes[1, 1]) : Relation PIB vs Espérance de vie en 2007.
- Tracez un nuage de points de
gdpPercapvslifeExp. - Faites varier la taille des points en fonction de la population (
s=df_2007['pop']/1e6). - Faites varier la couleur des points en fonction du continent (
hue='continent'avec Seaborn est idéal ici). - Mettez l’axe X en échelle logarithmique.
- Tracez un nuage de points de
Finalisation :
- Donnez un titre clair et des labels à chaque subplot.
- Ajoutez un titre global avec
fig.suptitle(). - Utilisez
plt.tight_layout()etplt.show().
Ce projet final vous fera passer de la théorie à une compétence pratique et solide en visualisation de données.