import pandas as pd
import numpy as np
1 Introduction
Pandas est la bibliothèque incontournable en Python pour la manipulation et l’analyse de données. Elle fournit des structures de données rapides, flexibles et expressives, conçues pour rendre le travail avec des données “relationnelles” ou “étiquetées” à la fois simple et intuitif.
Public Cible : Toute personne débutant en Data Science avec des bases en Python. Une connaissance de NumPy est un plus, mais pas obligatoire.
Objectifs :
- Comprendre les deux structures de données principales :
SeriesetDataFrame. - Charger, inspecter et nettoyer des jeux de données.
- Sélectionner, filtrer et manipuler des données efficacement.
- Effectuer des opérations de groupement et d’agrégation pour l’analyse.
- Combiner plusieurs jeux de données.
2 Partie 1 : Les Structures de Données Pandas
2.1 Installation et Importation
Comme pour les autres bibliothèques, on utilise une convention d’importation.
2.2 La Series : Une Colonne de Données
Une Series est un tableau unidimensionnel de type ndarray avec des étiquettes (un index). C’est l’équivalent d’une colonne dans une feuille de calcul.
# Créer une Series à partir d'une liste
s = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
# Afficher la Series
print(s)
# Le type
print(f"\nType de s: {type(s)}")
# Le type d'un élément
print(f"Type d'un élément de s: {s.dtype}")
# Accéder à un élément par son index
print(f"\nValeur à l'index 'c': {s['c']}")
# Mettre à jour un élément par son index
s['c'] = 50
print(s)
# Calculer la moyenne
print(f"\nMoyenne: {s.mean()}")
# Calculer la variance
print(f"Variance: {s.var()}")
# Calculer l'écart-type
print(f"Écart-type: {s.std()}")
# Déterminer le plus grand
print(f"Plus grand: {s.max()}")
# Déterminer le plus petit
print(f"Plus petit: {s.min()}")
# Calculer les statistiques descriptives univariées
s.describe()
# Filtrer des éléments
print(f"Les éléments > 20: {s[s > 20]}")a 10
b 20
c 30
d 40
dtype: int64
Type de s: <class 'pandas.core.series.Series'>
Type d'un élément de s: int64
Valeur à l'index 'c': 30
a 10
b 20
c 50
d 40
dtype: int64
Moyenne: 30.0
Variance: 333.3333333333333
Écart-type: 18.257418583505537
Plus grand: 50
Plus petit: 10
Les éléments > 20: c 50
d 40
dtype: int64# Une série qualitative
s_qual = pd.Series(['Paris', 'Lyon', 'Paris', 'Marseille', 'Lyon', 'Paris'])
print(f"Série qualitative:\n{s_qual}")
# Compter les occurrences de chaque valeur
print(f"\nFréquence des valeurs:\n{s_qual.value_counts()}")
# Obtenir les valeurs uniques
print(f"\nValeurs uniques: {s_qual.unique()}")
# Le mode (la ou les valeurs les plus fréquentes)
print(f"Mode: {s_qual.mode()[0]}") # [0] pour n'afficher que la première si plusieurs modesSérie qualitative:
0 Paris
1 Lyon
2 Paris
3 Marseille
4 Lyon
5 Paris
dtype: object
Fréquence des valeurs:
Paris 3
Lyon 2
Marseille 1
Name: count, dtype: int64
Valeurs uniques: ['Paris' 'Lyon' 'Marseille']
Mode: Paris2.3 Le DataFrame : Le Tableau Complet
Un DataFrame est une structure de données bidimensionnelle, semblable à une feuille de calcul SQL ou Excel. C’est l’objet que vous utiliserez 95% du temps.
# Création à partir d'un dictionnaire
data = {
'Pays': ['France', 'Espagne', 'Allemagne'],
'Population': [65, 47, 83],
'Capitale': ['Paris', 'Madrid', 'Berlin']
}
df = pd.DataFrame(data)
# Afficher le DataFrame
print(df)
# Les dimensions
print(f"\nDimensions: {df.shape}")
# Les noms des colonnes
print(f"Colonnes: {df.columns}")
# Les types des colonnes
print(f"\nTypes des colonnes:\n{df.dtypes}") Pays Population Capitale
0 France 65 Paris
1 Espagne 47 Madrid
2 Allemagne 83 Berlin
Dimensions: (3, 3)
Colonnes: Index(['Pays', 'Population', 'Capitale'], dtype='object')
Types des colonnes:
Pays object
Population int64
Capitale object
dtype: object3 Partie 2 : Charger et Inspecter les Données
La plupart du temps, vous ne créerez pas de DataFrame à la main, mais vous les chargerez depuis un fichier.
3.1 Lire un fichier CSV
La fonction pd.read_csv() est votre meilleure amie.
# Pour cet exemple, nous créons un faux fichier CSV
from io import StringIO
csv_data = """nom,age,ville
Alice,25,Paris
Bob,30,Lyon
Charlie,22,Marseille
David,35,Paris
Paul,31,Yaoundé
Jean,45,Mbouda
Henriette,50,Bafoussam
Amandla,23,Nancy
Jeanne,77,Mbouda"""
df = pd.read_csv(StringIO(csv_data))
print(df) nom age ville
0 Alice 25 Paris
1 Bob 30 Lyon
2 Charlie 22 Marseille
3 David 35 Paris
4 Paul 31 Yaoundé
5 Jean 45 Mbouda
6 Henriette 50 Bafoussam
7 Amandla 23 Nancy
8 Jeanne 77 Mbouda3.2 Premiers Regards sur les Données
Une fois les données chargées, la première étape est toujours de les inspecter.
# Afficher les 5 premières lignes
print("--- head() ---")
print(df.head())
# Obtenir un résumé technique (types, valeurs non nulles)
print("\n--- info() ---")
df.info()
# Obtenir un résumé statistique des colonnes numériques
print("\n--- describe() ---")
print(df.describe())
# Obtenir les dimensions du DataFrame (lignes, colonnes)
print(f"\nForme du DataFrame (shape): {df.shape}")--- head() ---
nom age ville
0 Alice 25 Paris
1 Bob 30 Lyon
2 Charlie 22 Marseille
3 David 35 Paris
4 Paul 31 Yaoundé
--- info() ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9 entries, 0 to 8
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 nom 9 non-null object
1 age 9 non-null int64
2 ville 9 non-null object
dtypes: int64(1), object(2)
memory usage: 348.0+ bytes
--- describe() ---
age
count 9.000000
mean 37.555556
std 17.621798
min 22.000000
25% 25.000000
50% 31.000000
75% 45.000000
max 77.000000
Forme du DataFrame (shape): (9, 3)
Exercice 1
- Trouvez un fichier CSV simple en ligne (par exemple, le jeu de données “Titanic” de Kaggle).
- Chargez-le dans un DataFrame et utilisez les fonctions
head(),info()etdescribe()pour l’explorer.
4 Partie 3 : Sélection et Filtrage
4.1 Sélectionner des Colonnes
# Sélectionner une seule colonne (renvoie une Series)
noms = df['nom']
print(type(noms))
print(noms)
# Sélectionner plusieurs colonnes (renvoie un DataFrame)
details = df[['nom', 'ville']]
print(f"\n{details}")
# Ajouter une nouvelle colonne
df['genre'] = ['F', 'M', 'M', 'M', 'M', 'M', 'F', 'F', 'F']
print(f"\n{df}")<class 'pandas.core.series.Series'>
0 Alice
1 Bob
2 Charlie
3 David
4 Paul
5 Jean
6 Henriette
7 Amandla
8 Jeanne
Name: nom, dtype: object
nom ville
0 Alice Paris
1 Bob Lyon
2 Charlie Marseille
3 David Paris
4 Paul Yaoundé
5 Jean Mbouda
6 Henriette Bafoussam
7 Amandla Nancy
8 Jeanne Mbouda
nom age ville genre
0 Alice 25 Paris F
1 Bob 30 Lyon M
2 Charlie 22 Marseille M
3 David 35 Paris M
4 Paul 31 Yaoundé M
5 Jean 45 Mbouda M
6 Henriette 50 Bafoussam F
7 Amandla 23 Nancy F
8 Jeanne 77 Mbouda FQuelques Graphiques avec seaborn
# Charger la librairie
import matplotlib.pyplot as plt
import seaborn as sns
# Diagramme à barres
plt.figure()
sns.countplot(data=df, x='ville', hue='genre')
plt.xticks(rotation=45)
plt.show()
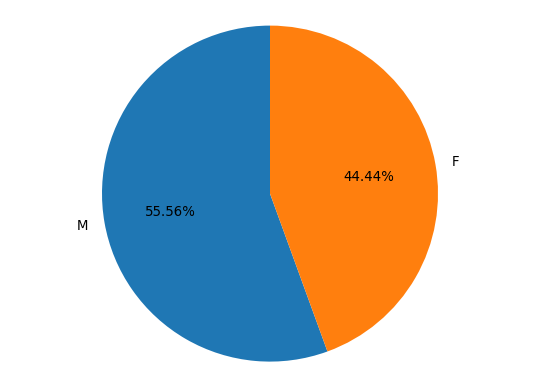
# Diagramme en secteurs
labels, counts = df['genre'].value_counts().index, df['genre'].value_counts().values
plt.figure()
plt.pie(counts, labels=labels, autopct='%1.2f%%', startangle=90)
plt.axis('equal')
plt.show()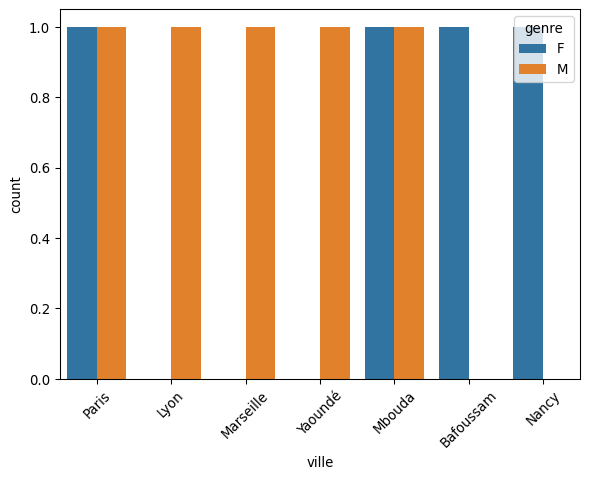
4.2 Filtrer des Lignes avec .loc et .iloc
C’est une distinction cruciale :
.loc: Filtre par label (le nom de l’index)..iloc: Filtre par position entière (l’index numérique, à partir de 0).
# Filtrer la ligne avec l'index 1 (deuxième ligne)
print("--- .loc[1] ---")
print(df.loc[1])
# Filtrer la troisième ligne par sa position
print("\n--- .iloc[2] ---")
print(df.iloc[2])--- .loc[1] ---
nom Bob
age 30
ville Lyon
genre M
Name: 1, dtype: object
--- .iloc[2] ---
nom Charlie
age 22
ville Marseille
genre M
Name: 2, dtype: object4.3 Filtrage Conditionnel
C’est ici que la puissance de Pandas commence à briller.
# Trouver toutes les personnes de plus de 25 ans
plus_de_25 = df[df['age'] > 25]
print(plus_de_25)
# Combiner des conditions : les personnes de Paris qui ont plus de 35 ans
parisiens_majeurs = df[(df['ville'] == 'Paris') & (df['age'] > 20)]
print(f"\n{parisiens_majeurs}") nom age ville genre
1 Bob 30 Lyon M
3 David 35 Paris M
4 Paul 31 Yaoundé M
5 Jean 45 Mbouda M
6 Henriette 50 Bafoussam F
8 Jeanne 77 Mbouda F
nom age ville genre
0 Alice 25 Paris F
3 David 35 Paris M4.4 Sélectionner ou Filtrer avec filter
print(f"Sélectionner la colonne 'nom':\n{df.filter(items=['nom'], axis=1)}")
print(f"\nFiltrer les colonnes 'nom' et 'age':\n{df.filter(items=['nom', 'age'], axis=1)}")
print(f"Sélectionner les colonnes se terminant par 'e':\n{df.filter(regex='e$', axis=1)}")
print(f"Filtrer les lignes 2 et 3: {df.filter(items=[1, 2], axis=0)}") Sélectionner la colonne 'nom':
nom
0 Alice
1 Bob
2 Charlie
3 David
4 Paul
5 Jean
6 Henriette
7 Amandla
8 Jeanne
Filtrer les colonnes 'nom' et 'age':
nom age
0 Alice 25
1 Bob 30
2 Charlie 22
3 David 35
4 Paul 31
5 Jean 45
6 Henriette 50
7 Amandla 23
8 Jeanne 77
Sélectionner les colonnes se terminant par 'e':
age ville genre
0 25 Paris F
1 30 Lyon M
2 22 Marseille M
3 35 Paris M
4 31 Yaoundé M
5 45 Mbouda M
6 50 Bafoussam F
7 23 Nancy F
8 77 Mbouda F
Filtrer les lignes 2 et 3: nom age ville genre
1 Bob 30 Lyon M
2 Charlie 22 Marseille M4.5 Filtrer avec query
La méthode query fonctionne à la manière de SQL.
print(f"Filtrer les lignes avec l'âge > 35:\n{df.query('age > 35')}")
print(f"Filtrer les filles âgées de plus 35 ans: {df.query('genre == "F" and age > 35')}")Filtrer les lignes avec l'âge > 35:
nom age ville genre
5 Jean 45 Mbouda M
6 Henriette 50 Bafoussam F
8 Jeanne 77 Mbouda F
Filtrer les filles âgées de plus 35 ans: nom age ville genre
6 Henriette 50 Bafoussam F
8 Jeanne 77 Mbouda F5 Partie 4 : Groupement et Agrégation
Le groupby est un processus “Split-Apply-Combine” (Diviser-Appliquer-Combiner) qui permet de répondre à des questions analytiques.
Pour cette partie, nous considérons les données des Penguins. Voici les variables du jeu de données:
bill_length_mm: Longueur du bec en mm.bill_depth_mm: Profondeur du bec en mm.flipper_length_mm: Longueur des becs en mm.body_mass_g: Massespecies: Espèceisland: Ilesex: Sexe
# Charger les données
import seaborn as sns
df = sns.load_dataset('penguins')
df.head()| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
# Nombre de données manquantes par variables
df.isna().sum()species 0
island 0
bill_length_mm 2
bill_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 11
dtype: int64# Suppression des lignes avec données manquantes
df = df.dropna()
df.isna().sum()species 0
island 0
bill_length_mm 0
bill_depth_mm 0
flipper_length_mm 0
body_mass_g 0
sex 0
dtype: int645.1 Fonctions d’Agrégation de Base
# Calculer la moyenne de la longueur du bec par espèce
1df.groupby('species')['bill_length_mm'].mean().reset_index()- 1
- Reinitialiser les indexes, ce qui permet d’avoir un DataFrame normal.
| species | bill_length_mm | |
|---|---|---|
| 0 | Adelie | 38.823973 |
| 1 | Chinstrap | 48.833824 |
| 2 | Gentoo | 47.568067 |
# Calculer le moyenne de la longueur du bec par espèce et par île
df.groupby(['species', 'island'])['bill_length_mm'].mean().reset_index()| species | island | bill_length_mm | |
|---|---|---|---|
| 0 | Adelie | Biscoe | 38.975000 |
| 1 | Adelie | Dream | 38.520000 |
| 2 | Adelie | Torgersen | 39.038298 |
| 3 | Chinstrap | Dream | 48.833824 |
| 4 | Gentoo | Biscoe | 47.568067 |
# Calculons la moyenne et la variance de la longueur du bec par espèce
1df.groupby('species')['bill_length_mm'].agg(['mean', 'var']).reset_index()- 1
-
La méthode
agg(ouaggregate) permet d’appliquer plusieurs fonctions d’aggrégation.
| species | mean | var | |
|---|---|---|---|
| 0 | Adelie | 38.823973 | 7.089421 |
| 1 | Chinstrap | 48.833824 | 11.150630 |
| 2 | Gentoo | 47.568067 | 9.647955 |
# Le même calcul avec des noms de colonnes personnalisés
df.groupby('species')['bill_length_mm'].agg(moyenne='mean', variance='var').reset_index()| species | moyenne | variance | |
|---|---|---|---|
| 0 | Adelie | 38.823973 | 7.089421 |
| 1 | Chinstrap | 48.833824 | 11.150630 |
| 2 | Gentoo | 47.568067 | 9.647955 |
# Calcul des moyennes de la logueur et la hauteur du bec par espèce
df.groupby('species')[['bill_length_mm', 'bill_depth_mm']].mean().reset_index()| species | bill_length_mm | bill_depth_mm | |
|---|---|---|---|
| 0 | Adelie | 38.823973 | 18.347260 |
| 1 | Chinstrap | 48.833824 | 18.420588 |
| 2 | Gentoo | 47.568067 | 14.996639 |
# Calcul de la moyenne de la longueur et de la médiane de la hauteur du bec par espèce
1df.groupby('species').agg({'bill_length_mm': 'mean', 'bill_depth_mm': 'median'}).reset_index()- 1
- Remarquez l’utilisation d’un dictionnaire.
| species | bill_length_mm | bill_depth_mm | |
|---|---|---|---|
| 0 | Adelie | 38.823973 | 18.40 |
| 1 | Chinstrap | 48.833824 | 18.45 |
| 2 | Gentoo | 47.568067 | 15.00 |
5.2 Fonctions d’Aggrégation Personnalisées
# Fonctions personnalisées
def etendu(x):
"""Calcule l'étendue (max - min) d'une série."""
return x.max() - x.min()
def iqr(x):
"""Calcule l'écart interquartile."""
return x.quantile(0.75) - x.quantile(0.25)
# Appliquer les fonctions personnalisées
custom_agg = df.groupby('species').agg(
etendue_longueur_bec=('bill_length_mm', etendu),
iqr_longueur_bec=('bill_length_mm', iqr),
etendue_masse=('body_mass_g', etendu)
).reset_index()
custom_agg| species | etendue_longueur_bec | iqr_longueur_bec | etendue_masse | |
|---|---|---|---|---|
| 0 | Adelie | 13.9 | 4.050 | 1925.0 |
| 1 | Chinstrap | 17.1 | 4.725 | 2100.0 |
| 2 | Gentoo | 18.7 | 4.250 | 2350.0 |
Explication du code ajouté :
Définition des fonctions :
etendu(x): Cette fonction prend uneSeriesPandas en entrée (x) et retourne la différence entre sa valeur maximale et sa valeur minimale.iqr(x): Cette fonction calcule l’écart interquartile, une mesure de dispersion robuste, en soustrayant le premier quartile (quantile 0.25) du troisième quartile (quantile 0.75).
Application avec
.agg():- Nous utilisons la même syntaxe
df.groupby(...).agg(...)que pour les fonctions de base. - Au lieu de passer une chaîne de caractères comme
'mean'ou'var', nous passons directement le nom de notre fonction personnalisée (ex:etendu,iqr). - Cela permet de calculer des statistiques très spécifiques pour chaque groupe défini par
groupby().
- Nous utilisons la même syntaxe
6 Partie 5 : Manipulation de Données
6.1 Créer une nouvelle colonne
Sur les données penguins, nous voulons créer une nouvelle, produit de la longueur et de la largeur du bec.
df['bill_area'] = df['bill_length_mm'] * df['bill_depth_mm']
df.head()| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | bill_area | |
|---|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male | 731.17 |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female | 687.30 |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female | 725.40 |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female | 708.31 |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | Male | 809.58 |
6.2 Gérer les données manquantes
# Créons un DataFrame avec des données manquantes
data_nan = {'A': [1, 2, np.nan, 4], 'B': [5, np.nan, np.nan, 2], 'C': [1, 2, 3, 4], 'D': ['a', 'b', 'a', np.nan]}
df_nan = pd.DataFrame(data_nan)
# Supprimer les lignes avec au moins une valeur manquante
print(df_nan.dropna())
# Remplacer les valeurs manquantes par une valeur (ex: la moyenne)
print("\n", df_nan['A'].fillna(value=df_nan['A'].mean()))
# Remplacer les valeurs manquantes par le mode (la valeur la plus fréquente)
print("\n", df_nan['D'].fillna(value=df_nan['D'].mode()[0])) A B C D
0 1.0 5.0 1 a
0 1.000000
1 2.000000
2 2.333333
3 4.000000
Name: A, dtype: float64
0 a
1 b
2 a
3 a
Name: D, dtype: object7 Partie 6 : Combiner DataFrames
7.1 Concaténation
# Concaténation verticale
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# Concaténation verticale
pd.concat([df1, df2], axis=0)| A | B | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 4 |
| 0 | 5 | 7 |
| 1 | 6 | 8 |
# Concaténation horizontale
pd.concat([df1, df2], axis=1)| A | B | A | B | |
|---|---|---|---|---|
| 0 | 1 | 3 | 5 | 7 |
| 1 | 2 | 4 | 6 | 8 |
8 Partie 7: Graphiques
8.1 Histogramme
import seaborn as sns
import matplotlib.pyplot as plt
# Données penguins
df = sns.load_dataset('penguins')
# Histogramme de la longueur du bec
sns.histplot(df['bill_length_mm'], kde=True)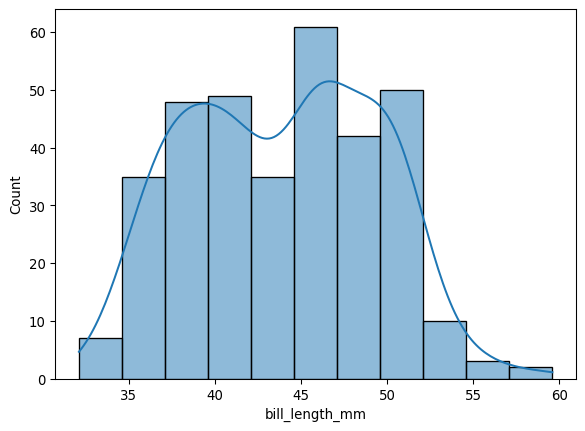
8.2 Diagramme à barres
# Diagramme en secteurs
labels, counts = df['species'].value_counts().index, df['species'].value_counts().values
plt.figure()
plt.pie(counts, labels=labels, autopct='%1.2f%%', startangle=90)
plt.show()
8.3 Nuage de points
plt.figure()
sns.scatterplot(data=df, x='bill_length_mm', y='bill_depth_mm', hue='species')
plt.show()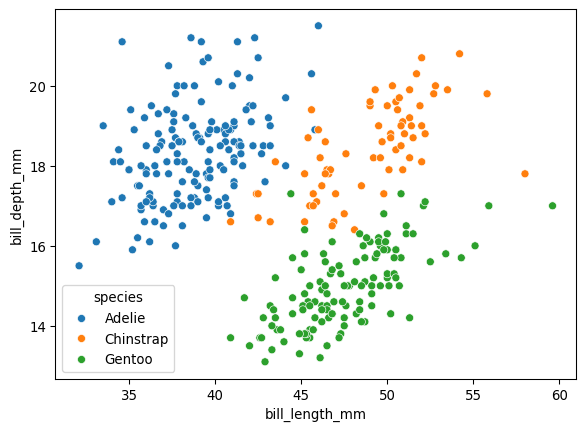
8.4 Boxplot
plt.figure()
sns.boxplot(data=df, x='species', y='bill_length_mm')
plt.show()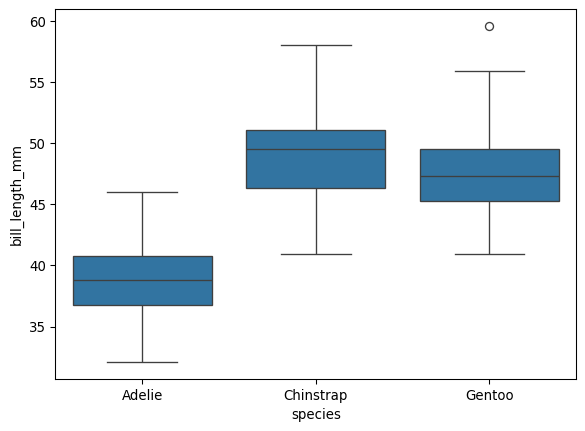
8.5 Violin
plt.figure()
sns.violinplot(data=df, x='species', y='bill_length_mm')
plt.show()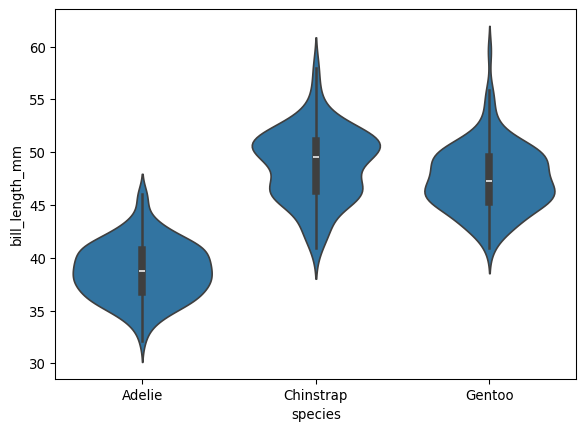
8.6 Error bar
plt.figure()
sns.barplot(data=df, x='species', y='bill_length_mm', errorbar='sd')
plt.show()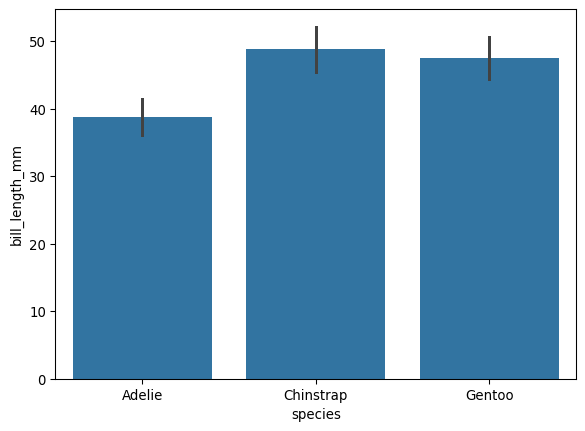
9 Partie 8: Données Temporelles
Pandas est exceptionnellement puissant pour la manipulation de données temporelles (time series).
9.1 Créer un Index Temporel
La première étape est souvent de s’assurer que les dates sont bien au format datetime et de les utiliser comme index du DataFrame.
# Créer un jeu de données temporelles d'exemple
dates = pd.to_datetime(pd.date_range(start='2023-01-01', periods=100, freq='D'))
data = {
'ventes': np.random.randint(50, 200, size=100)
}
df_temp = pd.DataFrame(data, index=dates)
print("Aperçu des données temporelles:")
print(df_temp.head())
print("\nType de l'index:", type(df_temp.index))Aperçu des données temporelles:
ventes
2023-01-01 104
2023-01-02 118
2023-01-03 120
2023-01-04 89
2023-01-05 129
Type de l'index: <class 'pandas.core.indexes.datetimes.DatetimeIndex'>9.2 Sélection et Filtrage Temporels
Avec un DatetimeIndex, la sélection devient très intuitive.
# Sélectionner une date spécifique
print("Ventes du 5 janvier 2023:\n", df_temp.loc['2023-01-05'])
# Sélectionner un mois entier
print("\nVentes de février 2023:\n", df_temp.loc['2023-02'])
# Sélectionner une plage de dates
print("\nVentes du 15 au 20 mars 2023:\n", df_temp.loc['2023-03-15':'2023-03-20'])Ventes du 5 janvier 2023:
ventes 129
Name: 2023-01-05 00:00:00, dtype: int64
Ventes de février 2023:
ventes
2023-02-01 154
2023-02-02 195
2023-02-03 165
2023-02-04 97
2023-02-05 161
2023-02-06 186
2023-02-07 135
2023-02-08 198
2023-02-09 175
2023-02-10 181
2023-02-11 74
2023-02-12 90
2023-02-13 126
2023-02-14 95
2023-02-15 103
2023-02-16 139
2023-02-17 121
2023-02-18 128
2023-02-19 86
2023-02-20 76
2023-02-21 119
2023-02-22 129
2023-02-23 127
2023-02-24 136
2023-02-25 102
2023-02-26 83
2023-02-27 189
2023-02-28 190
Ventes du 15 au 20 mars 2023:
ventes
2023-03-15 150
2023-03-16 151
2023-03-17 197
2023-03-18 91
2023-03-19 168
2023-03-20 919.3 Ré-échantillonnage (Resampling)
Le ré-échantillonnage permet de changer la fréquence des données (par exemple, passer de données quotidiennes à mensuelles).
# Ré-échantillonner pour obtenir la somme des ventes par mois
ventes_mensuelles = df_temp['ventes'].resample('ME').sum()
print("Somme des ventes par mois:\n", ventes_mensuelles)
# On peut aussi calculer la moyenne
moyenne_mensuelle = df_temp['ventes'].resample('ME').mean()
print("\nMoyenne des ventes par mois:\n", moyenne_mensuelle)
# Visualisation
moyenne_mensuelle.plot(kind='bar', title='Moyenne des ventes mensuelles')
plt.ylabel('Ventes moyennes')
plt.xlabel('Mois')
plt.xticks(rotation=45)
plt.show()Somme des ventes par mois:
2023-01-31 3262
2023-02-28 3760
2023-03-31 4052
2023-04-30 1308
Freq: ME, Name: ventes, dtype: int64
Moyenne des ventes par mois:
2023-01-31 105.225806
2023-02-28 134.285714
2023-03-31 130.709677
2023-04-30 130.800000
Freq: ME, Name: ventes, dtype: float64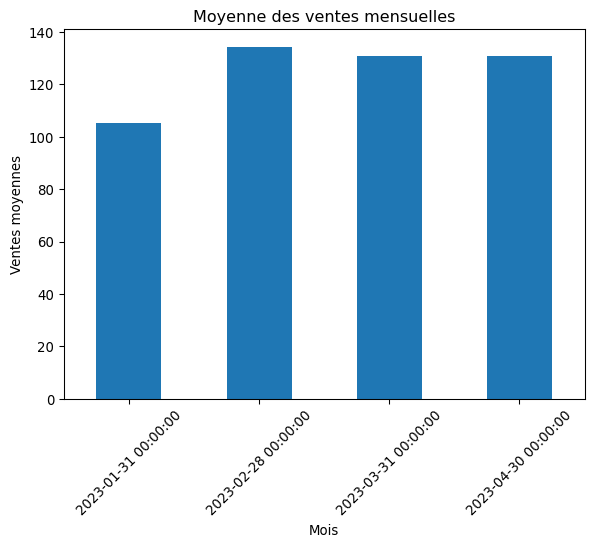
9.4 Fenêtres Glissantes (Rolling Windows)
Les fenêtres glissantes sont utiles pour calculer des statistiques sur une période mobile, comme une moyenne mobile.
# Calculer la moyenne mobile sur 7 jours
df_temp['moyenne_mobile_7j'] = df_temp['ventes'].rolling(window=7).mean()
print(df_temp.head(10))
# Visualisation
plt.figure(figsize=(14, 7))
plt.plot(df_temp.index, df_temp['ventes'], label='Ventes quotidiennes', alpha=0.5)
plt.plot(df_temp.index, df_temp['moyenne_mobile_7j'], label='Moyenne mobile sur 7 jours', color='red')
plt.title('Ventes Quotidiennes et Moyenne Mobile')
plt.legend()
plt.show() ventes moyenne_mobile_7j
2023-01-01 104 NaN
2023-01-02 118 NaN
2023-01-03 120 NaN
2023-01-04 89 NaN
2023-01-05 129 NaN
2023-01-06 80 NaN
2023-01-07 162 114.571429
2023-01-08 95 113.285714
2023-01-09 87 108.857143
2023-01-10 93 105.000000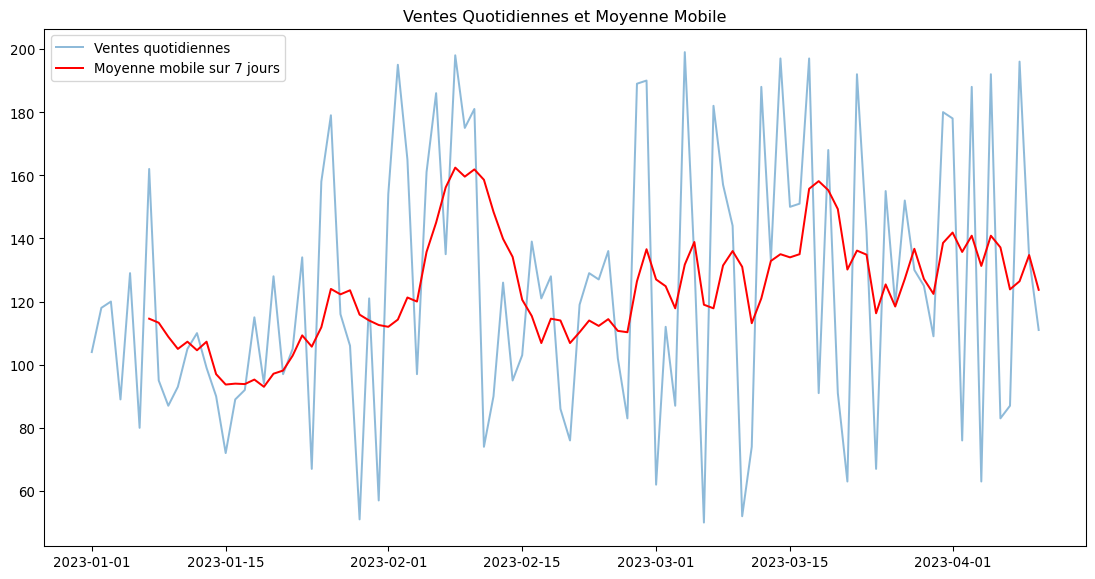
10 Conclusion
Félicitations ! Vous avez parcouru un large éventail des fonctionnalités de Pandas, de la manipulation de base à des sujets plus avancés comme la combinaison de DataFrames et l’analyse de séries temporelles. Vous disposez maintenant d’une base solide pour aborder la plupart des tâches de préparation et d’exploration de données en Python.
La maîtrise de Pandas est une étape essentielle. La prochaine étape naturelle est de combiner cette puissance de manipulation avec des bibliothèques de visualisation plus avancées pour créer des graphiques statistiques riches et informatifs. Nous explorerons cela en détail dans notre prochain chapitre sur Seaborn.
11 Exercices
Exercice 1 (Quiz)
Question 1
Quelle est la structure de données principale de Pandas, similaire à un tableau ou une feuille de calcul ?
Question 2
import pandas as pd
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
print(df['A'])Quel est le type de l’objet retourné par df['A'] ?
Question 3
Comment sélectionner toutes les lignes où la valeur de la colonne ‘age’ est supérieure à 30 dans un DataFrame df ?
Question 4
Quelle est la différence entre .loc et .iloc ?
Question 5
À quoi sert la méthode df.groupby('categorie').mean() ?
Question 6
Comment gérer les valeurs manquantes (NaN) dans une colonne ‘prix’ en les remplaçant par la moyenne de cette colonne ?
Question 7
Quelle fonction est utilisée pour lire un fichier CSV dans un DataFrame Pandas ?
Question 8
Comment ajouter une nouvelle colonne ‘bonus’ avec une valeur constante de 100 à un DataFrame df ?
Question 9
Que retourne la méthode df.info() ?
Question 10
import pandas as pd
s = pd.Series(['a', 'b', 'a', 'c', 'a', 'b'])
print(s.value_counts())Que va afficher ce code ?
Question 11
Quelle méthode utiliseriez-vous pour combiner deux DataFrames df1 et df2 verticalement (l’un en dessous de l’autre) ?
Question 12
import pandas as pd
import numpy as np
df = pd.DataFrame({'valeurs': [1, 4, 9, 16]})
df['racine_carree'] = df['valeurs'].apply(np.sqrt)Quel est le rôle de .apply(np.sqrt) dans ce code ?
Question 13
Comment trier un DataFrame df en fonction de la colonne ‘age’ par ordre décroissant ?
Question 14
Quelle est la bonne syntaxe pour supprimer la colonne ‘ville’ d’un DataFrame df et retourner un nouveau DataFrame sans cette colonne ?
Question 15
import pandas as pd
data = {'nom': ['Alice', 'Bob', 'Alice'], 'score': [85, 90, 85]}
df = pd.DataFrame(data)
df_unique = df.drop_duplicates()
print(len(df_unique))Que va afficher ce code ?
Question 16
Quelle est la fonction principale de pd.merge(df1, df2, on='id') ?
Question 17
Dans l’analyse de séries temporelles, que fait df['ventes'].resample('M').sum() ?
Question 18
À quoi sert la méthode .rolling(window=10).mean() sur une Series temporelle ?
Question 19
Quelle opération est effectuée par df.pivot_table(values='ventes', index='region', columns='annee', aggfunc='sum') ?
Question 20
Comment changer le type de la colonne ‘age’ d’un DataFrame df en float ?
Question 21
Comment sélectionner toutes les lignes d’un DataFrame df où la colonne ‘nom’ contient la sous-chaîne ‘li’ ?
Question 22
Après un df.groupby(['espece', 'ile']).mean(), quelle méthode permet de transformer le niveau d’index ‘ile’ en colonnes ?
Question 23
Quel est le principal avantage de convertir une colonne de type object avec peu de valeurs uniques en type category ?
Question 24
Quelle est la différence principale entre les méthodes .apply() et .applymap() sur un DataFrame ?
Question 25
Comment supprimer les lignes dupliquées en se basant sur la colonne ‘email’, en ne gardant que la dernière occurrence de chaque email ?
Exercice 2 (Analyse Approfondie des Survivants du Titanic) Contexte : Vous êtes un data analyst chargé d’explorer le célèbre jeu de données du Titanic pour en tirer des informations clés sur les survivants.
Étapes :
Chargement et Inspection Initiale :
- Importez
pandasetseaborn. - Chargez le jeu de données
titanicde Seaborn dans un DataFramedfavecsns.load_dataset('titanic'). - Utilisez
info()pour identifier les colonnes avec des données manquantes. - Utilisez
describe(include='all')pour obtenir un aperçu complet.
- Importez
Nettoyage et Préparation des Données :
- La colonne ‘age’ a des valeurs manquantes. Remplacer ces valeurs par l’âge médian de la colonne.
- La colonne ‘deck’ a trop de valeurs manquantes. Supprimez-la du DataFrame avec
df.drop(). - Créez une nouvelle colonne
is_alonequi estTruesi la personne n’a ni frère/sœur/époux (sibsp) ni parent/enfant (parch) à bord, etFalsesinon.
Analyse Exploratoire par Filtrage :
- Créez un DataFrame
survivantscontenant uniquement les passagers qui ont survécu (survived == 1). - Parmi les survivants, combien étaient des enfants de moins de 12 ans ?
- Quel était le tarif (
fare) le plus élevé payé par un passager de troisième classe (pclass == 3) qui n’a pas survécu ?
- Créez un DataFrame
Analyse par Groupement :
- Calculez le taux de survie moyen pour chaque classe (
pclass). - Calculez le taux de survie moyen en fonction du sexe (
sex) et de la classe (pclass) simultanément. Triez les résultats pour afficher les groupes avec le taux de survie le plus élevé en premier.
- Calculez le taux de survie moyen pour chaque classe (
Exercice 3 (Atelier Pratique : Exploration des Données Mondiales avec Gapminder) Contexte : Vous êtes un analyste de données chargé d’explorer le jeu de données Gapminder pour comprendre les tendances du développement mondial au XXe siècle. Ce jeu de données contient des informations sur l’espérance de vie, la population et le PIB par habitant pour 142 pays, de 1952 à 2007.
Objectif : Mettre en pratique vos compétences en manipulation de données avec Pandas pour répondre à une série de questions analytiques.
Étapes :
Chargement et Inspection Initiale :
- Chargez le jeu de données
gapminderen utilisantplotly.express(import plotly.express as px; df = px.data.gapminder()). - Affichez les 5 premières et les 5 dernières lignes.
- Utilisez
info()pour vérifier les types de données et les valeurs non nulles. - Utilisez
describe()pour obtenir un résumé statistique des variables numériques.
- Chargez le jeu de données
Exploration par Filtrage et Sélection :
- Créez un DataFrame
df_2007contenant uniquement les données pour l’année 2007. - Dans
df_2007, quel pays a l’espérance de vie (lifeExp) la plus élevée ? Et la plus faible ? (Indice : utilisez.sort_values()ou.nlargest()/.nsmallest()). - Sélectionnez les données pour un pays de votre choix (ex: ‘France’ ou ‘Cameroon’) et affichez-les.
- Filtrez le jeu de données complet pour n’afficher que les pays du continent africain (
Africa) avec une espérance de vie supérieure à 60 ans.
- Créez un DataFrame
Analyse par Groupement et Agrégation :
- Calculez l’espérance de vie moyenne et le PIB par habitant moyen pour chaque continent en 2007.
- Pour chaque continent, trouvez l’année où l’espérance de vie moyenne était la plus basse.
- Calculez la population mondiale totale pour chaque année disponible dans le jeu de données.
Création de Colonnes et Analyse Temporelle :
- Créez une nouvelle colonne
gdpqui représente le PIB total de chaque pays (pop*gdpPercap). - En utilisant cette nouvelle colonne, trouvez le PIB total pour chaque continent en 2007.
- Bonus : Pour un pays de votre choix, tracez l’évolution de son espérance de vie au fil du temps. (Indice : filtrez d’abord les données pour ce pays, puis utilisez
.plot(x='year', y='lifeExp')).
- Créez une nouvelle colonne