1 Introduction : Apprendre sans Professeur
Jusqu’à présent, tous nos projets de Machine Learning reposaient sur un principe fondamental : nous disposions de données étiquetées. Pour chaque observation \(x_i\), nous connaissions la “bonne réponse” \(y_i\). C’est le monde de l’apprentissage supervisé, où un “professeur” nous guide.
Mais que faire lorsque nous avons une montagne de données sans aucune étiquette ? Quand il n’y a pas de bonne réponse prédéfinie ?
Bienvenue dans le monde de l’apprentissage non supervisé. Ici, l’objectif n’est plus de prédire une cible, mais de découvrir la structure, les motifs et les relations cachés au sein des données elles-mêmes. C’est un voyage d’exploration et de découverte, où l’algorithme doit se débrouiller seul pour donner un sens au chaos apparent.
Ce post va vous introduire aux principaux types de problèmes que l’on peut résoudre avec l’apprentissage non supervisé.
2 Le Clustering : Regrouper les Similitudes
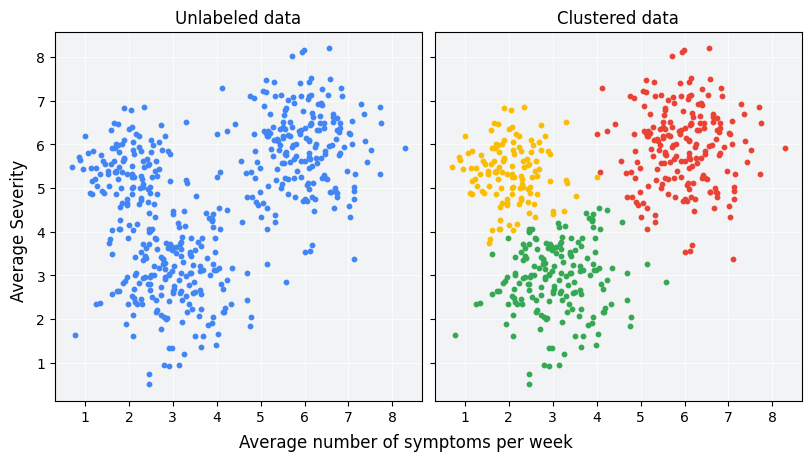
Le clustering est sans doute la tâche la plus connue de l’apprentissage non supervisé.
Le Problème Principal : Comment regrouper un ensemble de données en plusieurs “grappes” (ou clusters) de telle sorte que les observations à l’intérieur d’un même groupe soient très similaires les unes aux autres, et très différentes des observations des autres groupes ?
L’Analogie : Imaginez que l’on vous donne une caisse de fruits mélangés (pommes, oranges, bananes) sans vous dire ce qu’ils sont. Votre tâche est de les trier en piles homogènes en vous basant uniquement sur leurs caractéristiques : couleur, forme, taille, texture… C’est exactement ce que fait un algorithme de clustering.
Applications Courantes :
- Marketing : Segmenter une base de clients en différents profils pour des campagnes ciblées.
- Biologie : Regrouper des gènes ayant des expressions similaires.
- Urbanisme : Identifier des quartiers ayant des caractéristiques socio-économiques semblables.
Algorithmes Célèbres : K-Means, DBSCAN, Classification Ascendante Hiérarchique (CAH).
3 Les Règles d’Association : Trouver les Liaisons Fréquentes
Cette technique, au cœur du Data Mining, cherche à découvrir des relations intéressantes entre des variables dans de grands ensembles de données.
Le Problème Principal : Quelles sont les associations ou les co-occurrences les plus fréquentes dans nos données ?
L’Analogie : C’est le fameux problème du “panier de la ménagère” (market basket analysis). Un supermarché analyse des milliers de tickets de caisse pour répondre à la question : “Les clients qui achètent du pain ont-ils aussi tendance à acheter du lait ?”.
Le But : Découvrir des règles de la forme “Si {A} alors {B}”. Par exemple, la règle
{Couches} => {Bière}suggère que les clients qui achètent des couches sont susceptibles d’acheter aussi de la bière.Applications Courantes :
- Commerce : Optimisation du placement des produits en rayon, recommandations de produits (“Les clients qui ont acheté ceci ont aussi acheté…”).
- Médecine : Identifier des co-morbidités (quelles maladies apparaissent souvent ensemble ?).
Algorithmes Célèbres : Apriori, Eclat, FP-Growth.
4 La Réduction de Dimension : Simplifier sans Trahir
Nous vivons dans un monde de données à haute dimension (avec de très nombreuses variables). Travailler avec autant de variables peut être coûteux en calcul, difficile à visualiser et peut même nuire à la performance des modèles à cause de la “malédiction de la dimensionnalité”.
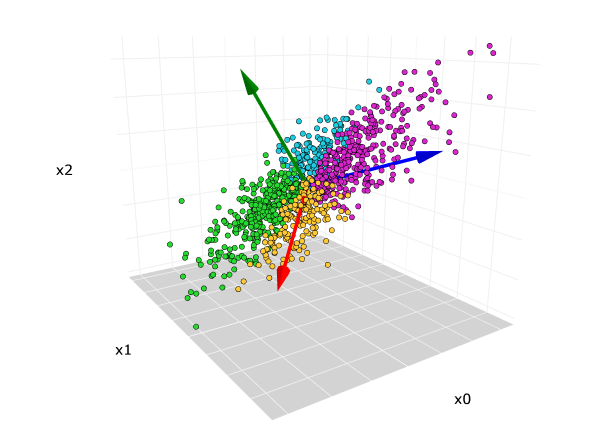
Le Problème Principal : Comment réduire le nombre de variables (dimensions) de notre jeu de données tout en perdant le moins d’information pertinente possible ?
L’Analogie : C’est comme créer une carte géographique en 2D à partir du globe terrestre en 3D. On perd l’information de l’altitude, mais on préserve l’essentiel des relations spatiales. Une autre analogie serait de résumer un livre de 500 pages en un synopsis de 2 pages : on garde l’intrigue principale en sacrifiant les détails.
Applications Courantes :
- Visualisation de données : Projeter des données à 100 dimensions sur un graphique en 2D ou 3D pour les explorer visuellement.
- Compression de données : Réduire la taille de stockage des données.
- Pré-traitement pour le Machine Learning : Améliorer la performance des modèles supervisés en éliminant le bruit et la redondance.
Algorithmes Célèbres : Analyse en Composantes Principales (ACP / PCA), t-SNE, UMAP.
5 La Détection d’Anomalies : Chercher l’Aiguille dans une Botte de Foin
Parfois, les points de données les plus intéressants ne sont pas ceux qui forment des groupes, mais ceux qui n’appartiennent à aucun groupe.
Le Problème Principal : Comment identifier les observations qui sont significativement différentes de la grande majorité des autres données ?
L’Analogie : C’est chercher une signature falsifiée parmi des milliers de signatures authentiques, ou détecter une transaction frauduleuse sur une carte de crédit parmi des millions de transactions légitimes.
Applications Courantes :
- Finance : Détection de fraudes bancaires.
- Cybersécurité : Détection d’intrusions réseau.
- Industrie : Maintenance prédictive en identifiant les mesures anormales d’un capteur sur une machine.
Algorithmes Célèbres : Isolation Forest, One-Class SVM.
6 Conclusion
L’apprentissage non supervisé est un domaine fascinant et essentiel de la science des données. Il nous fournit les outils pour explorer, comprendre et structurer des données brutes, souvent en préparation d’une modélisation supervisée. Que ce soit pour segmenter des clients, simplifier un problème complexe ou détecter une fraude, ces techniques transforment des données brutes en connaissances précieuses.