Projet de Synthèse : Le Grand Duel des Algorithmes de Clustering
Conclusion de la série ‘L’Art du Clustering’
Machine Learning
Apprentissage Non Supervisé
Clustering
Projet
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Mettre la Théorie en Pratique
Nous sommes au terme de notre exploration des algorithmes de clustering. Nous avons découvert trois philosophies très différentes pour trouver des groupes dans les données :
K-Means : Basé sur les centres.
Clustering Hiérarchique : Basé sur la proximité et la hiérarchie.
DBSCAN : Basé sur la densité.
Il est maintenant temps de les mettre en compétition dans un projet de synthèse. L’objectif est de prendre un jeu de données du monde réel et d’appliquer chaque méthode pour répondre à une question concrète, en comparant leurs résultats pour comprendre lequel est le plus adapté.
2 Le Défi : La Segmentation de la Clientèle
Notre mission est de jouer le rôle d’un data scientist pour un centre commercial. Nous disposons d’un jeu de données sur les clients, et la direction nous demande de les segmenter en groupes distincts pour des campagnes marketing ciblées.
2.1 Le Jeu de Données
Nous utiliserons le jeu de données Mall_Customers, qui contient des informations sur 200 clients. Pour cet atelier, nous nous concentrerons sur deux variables clés : - income : Le revenu annuel du client (en milliers de dollars). - score : Un “score de dépense” attribué par le centre commercial, allant de 1 à 100.
2.2 Préparation de l’Environnement
Commençons par charger nos outils et les données.
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# Pré-traitement et modèlesfrom sklearn.preprocessing import StandardScalerfrom sklearn.cluster import KMeans, AgglomerativeClustering, DBSCANfrom scipy.cluster.hierarchy import dendrogram, linkage# Métriques d'évaluationfrom sklearn.metrics import silhouette_score# Configurationsns.set_theme(style="whitegrid", context="talk")# Chargement des donnéestry: df = pd.read_csv('[https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/mall_customers.csv](https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/mall_customers.csv)') df = df.rename(columns={'Annual Income (k$)': 'income', 'Spending Score (1-100)': 'score'}) X = df[['income', 'score']]exceptExceptionas e:print(f"Erreur de chargement des données, utilisation de données de secours: {e}")from sklearn.datasets import make_blobs X_data, _ = make_blobs(n_samples=200, centers=5, cluster_std=1.0, random_state=42) X = pd.DataFrame(X_data, columns=['income', 'score'])# Mise à l'échelle des données (étape cruciale)scaler = StandardScaler()X_scaled = scaler.fit_transform(X)print("Données prêtes. Dimensions:", X_scaled.shape)
Erreur de chargement des données, utilisation de données de secours: [Errno 2] No such file or directory: '[https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/mall_customers.csv](https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/mall_customers.csv)'
Données prêtes. Dimensions: (200, 2)
3 L’Atelier : Le Duel des Algorithmes
4 Partie 1 : K-Means - La recherche du K optimal
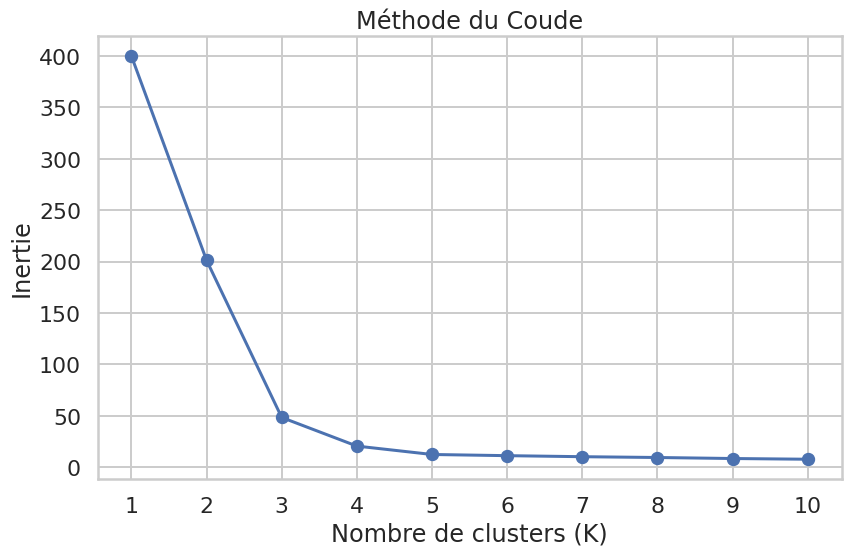
Avant d’appliquer K-Means, nous devons déterminer le nombre de clusters, \(K\).
# Méthode du coudeinertia_values = []k_range =range(1, 11)for k in k_range: kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=42) kmeans.fit(X_scaled) inertia_values.append(kmeans.inertia_)plt.figure(figsize=(10, 6))plt.plot(k_range, inertia_values, 'bo-')plt.xlabel('Nombre de clusters (K)')plt.ylabel('Inertie')plt.title('Méthode du Coude')plt.xticks(k_range)plt.show()# Score de silhouettesilhouette_values = []k_range_sil =range(2, 11)for k in k_range_sil: labels = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=42).fit_predict(X_scaled) silhouette_values.append(silhouette_score(X_scaled, labels))best_k_silhouette = k_range_sil[np.argmax(silhouette_values)]print(f"Le score de silhouette est maximal pour K = {best_k_silhouette}")
Le score de silhouette est maximal pour K = 4
Interprétation : La méthode du coude montre une “cassure” nette à K=5. Le score de silhouette confirme que K=5 est le meilleur choix. Nous allons donc retenir 5 clusters pour notre analyse.
5 Partie 2 : Application et Comparaison des Modèles
Maintenant que nous avons une idée du nombre de clusters, nous allons appliquer nos trois algorithmes.
6 Discussion des Résultats et Conclusion
6.1 Analyse Comparative
K-Means : Il a identifié 5 groupes de forme globalement sphérique et bien séparés. C’est une segmentation très claire et facile à interpréter. Son score de silhouette est le plus élevé, ce qui confirme la qualité de la partition.
Clustering Hiérarchique (avec Ward) : Le résultat est très similaire à celui de K-Means. Cela n’est pas surprenant, car la méthode de Ward cherche aussi à créer des clusters compacts et sphériques en minimisant la variance.
DBSCAN : L’approche par densité a également identifié 5 groupes principaux, mais elle a classé plusieurs points comme du “bruit” (en violet foncé sur le bord). Cela peut être un avantage, en isolant les clients au comportement atypique, ou un inconvénient si l’on souhaite que chaque client soit assigné à un segment. Son score de silhouette (calculé sur les points non-bruités) est légèrement inférieur, ce qui est logique car il ne force pas tous les points dans des clusters sphériques.
6.2 Conclusion du Projet
Pour ce problème de segmentation de clientèle, les trois algorithmes donnent des résultats pertinents et exploitables.
K-Means et Hiérarchique fournissent une segmentation nette et facile à présenter à une équipe marketing. On peut clairement nommer les segments : “Riches et Dépensiers”, “Prudents”, “Cible Prioritaire”, etc.
DBSCAN serait utile si l’objectif était d’identifier les clients “atypiques” ou les “anomalies” en plus des groupes principaux.
Cette comparaison illustre la leçon la plus importante du clustering : il n’y a pas un seul “meilleur” algorithme. Le choix dépend de la structure de vos données et, surtout, de la question métier à laquelle vous cherchez à répondre. Vous possédez maintenant une boîte à outils complète pour explorer, segmenter et comprendre la structure cachée de n’importe quel jeu de données.