DBSCAN - Détecter les Clusters de Formes Arbitraires et le Bruit
Machine Learning
Apprentissage Non Supervisé
Clustering
DBSCAN
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Changer de Paradigme
Jusqu’à présent, les algorithmes de clustering que nous avons étudiés (K-Means, Hiérarchique) reposent sur une notion de distance à un centre ou de proximité entre groupes. Cette approche fonctionne très bien pour trouver des clusters de forme compacte et sphérique, mais elle échoue lamentablement lorsque les données ont des structures plus complexes.
Imaginez que vous deviez séparer deux lunes entrelacées ou deux cercles concentriques. K-Means essaierait de trouver deux “centres” et tracerait une ligne droite entre eux, ce qui serait complètement faux.
Pour résoudre ce problème, nous devons changer de paradigme. Au lieu de penser en termes de “centre”, nous allons penser en termes de densité. C’est l’idée fondamentale de l’algorithme DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
2 La Logique de DBSCAN : La Connectivité par la Densité
L’intuition de DBSCAN est simple et élégante : > Un cluster est une région dense de l’espace, séparée des autres régions denses par des régions de faible densité.
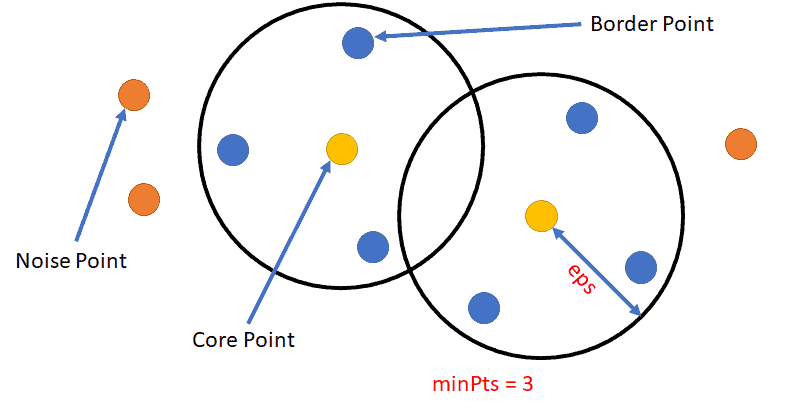
L’algorithme formalise cette idée en définissant trois types de points, basés sur deux hyperparamètres clés.
2.1 Les Deux Hyperparamètres
eps (\(\epsilon\)) : C’est un rayon de distance. Il définit le “voisinage” d’un point.
min_samples : C’est le nombre minimum de points qui doivent se trouver dans le voisinage d’un point (défini par eps) pour que ce dernier soit considéré comme étant dans une région dense.
2.2 La Typologie des Points
En fonction de ces deux paramètres, chaque point du jeu de données est classé dans l’une des trois catégories suivantes :
Point Cœur (Core Point) : Un point qui a au moins min_samples voisins (y compris lui-même) à l’intérieur de son rayon eps. Ces points sont au cœur des régions denses.
Point de Bordure (Border Point) : Un point qui n’est pas un point cœur (il a moins de min_samples voisins), mais qui se trouve dans le voisinage d’un point cœur. Ces points sont à la périphérie des clusters.
Point de Bruit (Noise Point / Outlier) : Un point qui n’est ni un point cœur, ni un point de bordure. Ces points sont isolés dans des régions de faible densité.
L’algorithme fonctionne alors en “connectant” les points cœurs qui sont voisins les uns des autres, et en y rattachant les points de bordure. Tout ce qui n’est pas connecté est considéré comme du bruit.
3 Avantages et Inconvénients
3.1 Avantages 👍
Trouve des clusters de formes arbitraires : C’est son plus grand atout.
N’a pas besoin de spécifier le nombre de clusters (\(K\)) : L’algorithme découvre le nombre de clusters par lui-même.
Robuste aux outliers : Il les identifie explicitement comme du bruit, au lieu de les forcer dans un cluster.
3.2 Inconvénients 👎
Difficulté avec des clusters de densités variables : Un eps et un min_samples qui fonctionnent bien pour un cluster dense peuvent ne pas fonctionner pour un cluster plus épars.
Sensibilité aux hyperparamètres : Le résultat dépend fortement du choix de eps et min_samples, qui ne sont pas toujours faciles à déterminer. (Une heuristique courante pour eps est d’utiliser un “k-distance graph”).
“Malédiction de la dimensionnalité” : Comme pour k-NN, dans un espace à très haute dimension, la notion de distance et de densité devient moins pertinente.
4 Atelier Pratique : Le Défi des Lunes
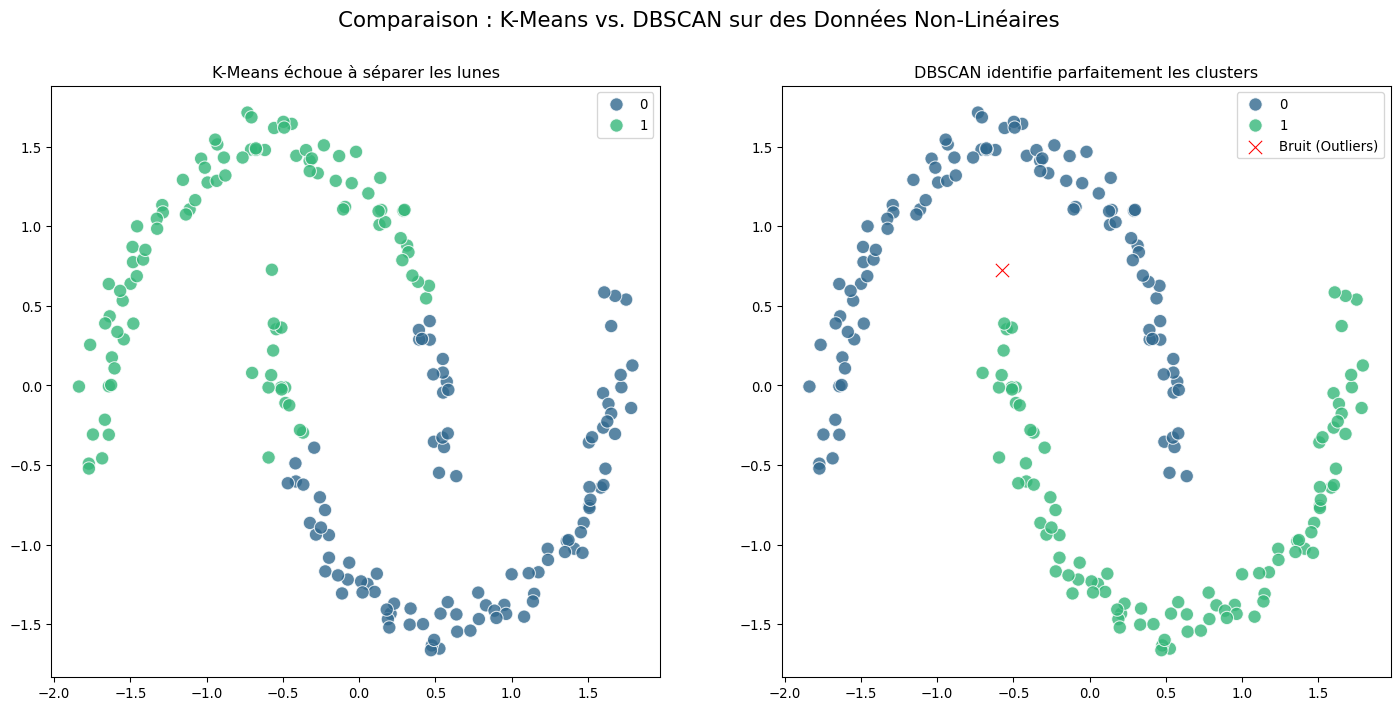
Pour voir la puissance de DBSCAN, nous allons l’appliquer à un jeu de données où K-Means est voué à l’échec : les “lunes” (make_moons).
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import make_moons, make_blobsfrom sklearn.preprocessing import StandardScalerfrom sklearn.cluster import KMeans, DBSCAN# 1. Générer les données "lunes"X_moons, y_moons = make_moons(n_samples=200, noise=0.05, random_state=42)# Mise à l'échellescaler = StandardScaler()X_moons_scaled = scaler.fit_transform(X_moons)# 2. Montrer l'échec de K-Meanskmeans = KMeans(n_clusters=2, n_init=10, random_state=42)y_kmeans = kmeans.fit_predict(X_moons_scaled)# 3. Appliquer DBSCAN# Le choix des paramètres est crucial. Après quelques tests, eps=0.3 semble bien fonctionner.dbscan = DBSCAN(eps=0.3, min_samples=5)y_dbscan = dbscan.fit_predict(X_moons_scaled)# 4. Visualisation comparativefig, axes = plt.subplots(1, 2, figsize=(18, 8))fig.suptitle("Comparaison : K-Means vs. DBSCAN sur des Données Non-Linéaires", fontsize=16)# Graphique K-Meanssns.scatterplot(x=X_moons_scaled[:, 0], y=X_moons_scaled[:, 1], hue=y_kmeans, palette='viridis', s=100, alpha=0.8, ax=axes[0])axes[0].set_title("K-Means échoue à séparer les lunes")# Graphique DBSCAN# On identifie les points de bruit (étiquette -1) pour les afficher différemmentnoise_points = y_dbscan ==-1core_samples =~noise_pointssns.scatterplot(x=X_moons_scaled[core_samples, 0], y=X_moons_scaled[core_samples, 1], hue=y_dbscan[core_samples], palette='viridis', s=100, alpha=0.8, ax=axes[1])sns.scatterplot(x=X_moons_scaled[noise_points, 0], y=X_moons_scaled[noise_points, 1], color='red', marker='x', s=100, label='Bruit (Outliers)', ax=axes[1])axes[1].set_title("DBSCAN identifie parfaitement les clusters")axes[1].legend()plt.show()# Afficher le nombre de clusters trouvés et le nombre de points de bruitn_clusters_ =len(set(y_dbscan)) - (1if-1in y_dbscan else0)n_noise_ =list(y_dbscan).count(-1)print(f"--- Résultats de DBSCAN ---")print(f"Nombre de clusters estimés: {n_clusters_}")print(f"Nombre de points de bruit estimés: {n_noise_}")
--- Résultats de DBSCAN ---
Nombre de clusters estimés: 2
Nombre de points de bruit estimés: 1
5 Conclusion
DBSCAN est un outil essentiel dans la boîte à outils du data scientist. Il représente une manière de penser le clustering qui est fondamentalement différente de K-Means ou des approches hiérarchiques.
En se basant sur la densité, il nous libère de l’hypothèse de clusters sphériques et nous permet de découvrir des structures complexes et d’isoler le bruit, ce qui est souvent plus proche de la réalité de nombreux jeux de données.
Et maintenant ?
Nous avons exploré trois grandes familles d’algorithmes de clustering. Mais une question demeure : comment savoir si le résultat de notre clustering est “bon” ? Comment le mesurer quantitativement, surtout quand on n’a pas d’étiquettes de vérité ? C’est ce que nous aborderons dans notre prochain et dernier article de cette série, dédié aux métriques d’évaluation du clustering.
6 Exercices
Exercise 1
Question 1
Quelle est l’idée fondamentale qui différencie DBSCAN de K-Means ?
Question 2
Quels sont les deux hyperparamètres principaux de l’algorithme DBSCAN ?
Question 3
Dans DBSCAN, qu’est-ce qu’un “Point Cœur” (Core Point) ?
Question 4
Comment DBSCAN gère-t-il les points de données qui n’appartiennent à aucun cluster ?
Question 5
Quel est le principal avantage de DBSCAN ?
Question 6
Quelle est l’une des principales limites de DBSCAN ?
Question 7
Un “Point de Bordure” (Border Point) est un point qui…
Question 8
Comment les clusters sont-ils formés dans l’algorithme DBSCAN ?
Question 9
Contrairement à K-Means, que découvre DBSCAN par lui-même ?
Question 10
Dans l’atelier pratique, pourquoi DBSCAN réussit-il là où K-Means échoue sur le jeu de données “lunes” ?