Une approche non-paramétrique et la quête du meilleur ‘k’
Machine Learning
Apprentissage Supervisé
Régression
Python
Scikit-learn
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Penser Autrement que par une Équation
Jusqu’à présent, tous nos modèles de régression (linéaire, polynomiale, régularisée) avaient un point commun : ils cherchaient à apprendre une équation mathématique fixe, avec des coefficients (\(\beta\)), pour modéliser la relation entre nos variables. Ces modèles sont dits paramétriques.
Mais que faire si la relation est si complexe qu’aucune équation simple ne peut la décrire ?
Nous allons aujourd’hui explorer une approche radicalement différente : la régression par k-plus proches voisins (k-NN). C’est un modèle non-paramétrique et basé sur les instances (instance-based).
Non-paramétrique : Il ne fait aucune hypothèse sur la forme de la fonction qui lie X et Y.
Basé sur les instances : Il n’apprend pas réellement une “fonction”. Il mémorise simplement l’intégralité du jeu de données d’entraînement.
Ce post va vous guider à travers l’intuition de ce modèle, l’importance cruciale de son seul hyperparamètre (k), et la méthode pour le choisir de manière optimale grâce à la validation croisée.
2 L’Intuition : “Dis-moi qui sont tes voisins, je te dirai qui tu es”
La logique du k-NN est incroyablement simple et intuitive. Elle est directement inspirée de la manière dont nous raisonnons dans la vie de tous les jours.
Imaginez que vous êtes un agent immobilier et que vous devez estimer le prix d’une nouvelle maison qui n’a jamais été sur le marché. Que faites-vous ? Vous n’allez pas résoudre une équation complexe. Vous allez regarder les prix de vente des maisons similaires (même surface, même nombre de chambres) dans le même quartier.
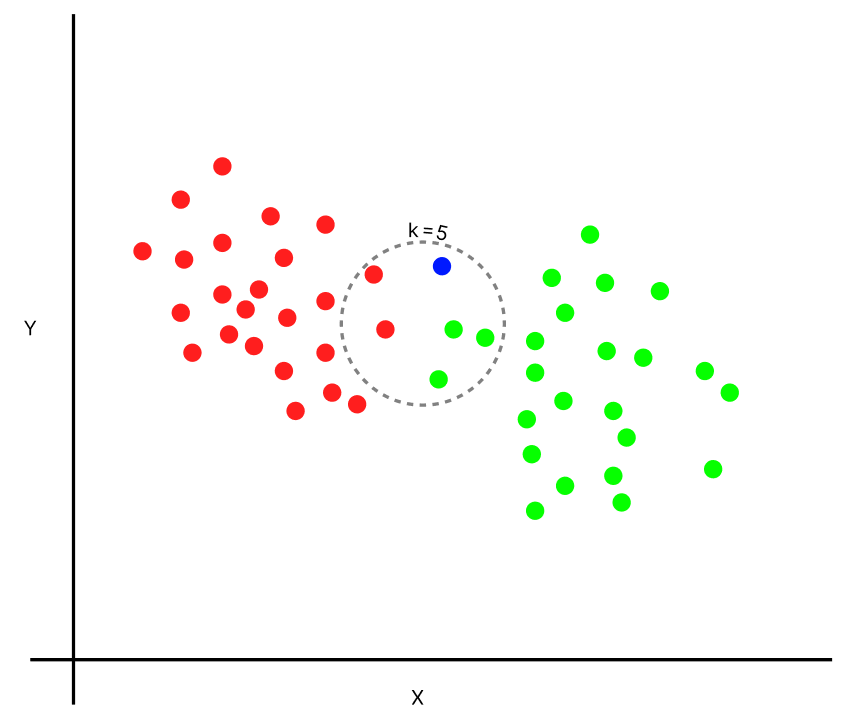
La régression \(k\)-NN fait exactement la même chose :
Le Mécanisme de Prédiction k-NN
Pour prédire la valeur d’une nouvelle observation x_new :
Le modèle recherche les k observations du jeu d’entraînement qui sont les plus “proches” de x_new dans l’espace des variables explicatives. La proximité est généralement mesurée par la distance euclidienne.
La prédiction pour x_new est simplement la moyenne des valeurs cibles (y) de ces k plus proches voisins.
\[\hat{y}_{\text{new}} = \frac{1}{|V_k(x_{\text{new}})|} \sum_{i \in V_k(x_{\text{new}})} y_i\] Où \(V_k(x_{\text{new}})\) est l’ensemble des indices des \(k\) plus proches voisins de \(x_{\text{new}}\).
3 Le Rôle Crucial de k : Le Compromis Biais-Variance
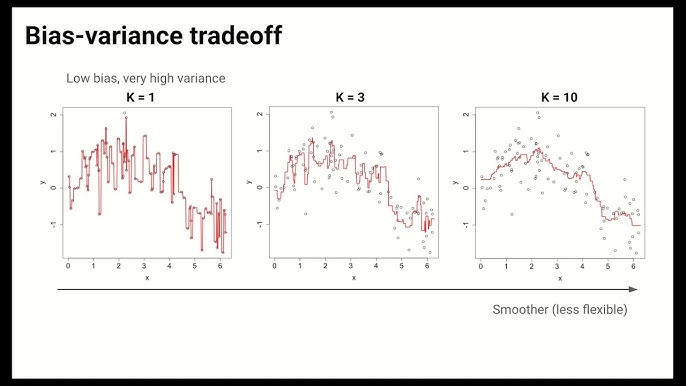
La simplicité du k-NN cache une question fondamentale : comment choisir la valeur de k ? Ce choix a un impact énorme sur le comportement du modèle et illustre parfaitement le compromis biais-variance.
3.1 Si k est petit (ex: k=1)
Comportement : Le modèle est extrêmement local et flexible. La prédiction pour un nouveau point est simplement la valeur de son plus proche voisin. Le modèle est très sensible au bruit.
Résultat :Variance élevée, biais faible. Le modèle est en surapprentissage (overfitting). Il épouse parfaitement les données d’entraînement mais généralisera mal.
3.2 Si k est grand (ex: k = nombre total d’échantillons)
Comportement : Le modèle est très global et lisse. La prédiction pour n’importe quel nouveau point sera la même : la moyenne de toutes les données d’entraînement. Le modèle ignore complètement les variations locales.
Résultat :Biais élevé, variance faible. Le modèle est en sous-apprentissage (underfitting).
L’objectif est donc de trouver la valeur de k “juste-milieu” qui minimise l’erreur de prédiction sur de nouvelles données.
4 Trouver le Meilleur k : Grid Search et Validation Croisée
Comment trouver ce k optimal ? On ne peut pas utiliser le jeu de test, car cela introduirait une fuite de données (data leakage) et notre évaluation finale serait faussement optimiste.
La solution standard est de combiner deux techniques :
La Validation Croisée (Cross-Validation) : Comme nous l’avons vu, c’est une méthode robuste pour estimer la performance d’un modèle en le formant et en le testant sur différentes parties des données d’entraînement.
La Recherche sur Grille (Grid Search) : C’est une méthode simple qui consiste à définir une “grille” de valeurs possibles pour k (ex: 1, 3, 5, …, 29) et à évaluer systématiquement le modèle pour chacune de ces valeurs.
GridSearchCV de Scikit-learn automatise ce processus. Pour chaque valeur de k dans notre grille, il effectue une validation croisée à K-blocs et calcule un score de performance moyen. À la fin, il nous indique quelle valeur de k a donné le meilleur score moyen.
5 Atelier Pratique : Prédire la Valeur de Maisons
Utilisons le jeu de données California Housing pour prédire le prix médian des maisons en Californie en fonction de diverses caractéristiques.
import pandas as pdimport numpy as npfrom sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsRegressorfrom sklearn.metrics import mean_squared_errorimport matplotlib.pyplot as plt# 1. Charger les donnéeshousing = fetch_california_housing()X, y = housing.data, housing.target# Pour un atelier plus rapide, on prend un sous-échantillonX_sample, _, y_sample, _ = train_test_split(X, y, train_size=5000, random_state=42)# 2. Diviser les données en entraînement et testX_train, X_test, y_train, y_test = train_test_split(X_sample, y_sample, test_size=0.2, random_state=42)# 3. Mettre les données à l'échelle (INDISPENSABLE pour k-NN)# k-NN est basé sur les distances, les variables doivent avoir la même échelle.scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 4. Mettre en place la recherche sur grilleprint("--- Lancement de la recherche du meilleur k via GridSearchCV ---")knn = KNeighborsRegressor()# Définir la grille des valeurs de k à tester (nombres impairs pour éviter les égalités)param_grid = {'n_neighbors': np.arange(1, 31, 2)}# Configurer GridSearchCV avec 5-fold cross-validation# Le score est l'erreur quadratique moyenne négative (plus elle est proche de 0, mieux c'est)grid_search = GridSearchCV(knn, param_grid, cv=5, scoring='neg_mean_squared_error')# 5. Lancer la recherche sur les données d'entraînementgrid_search.fit(X_train_scaled, y_train)# 6. Afficher les meilleurs résultatsprint("\n--- Résultats de la Recherche ---")print(f"Meilleur paramètre k trouvé : {grid_search.best_params_}")print(f"Meilleur score (MSE négatif) en validation croisée : {grid_search.best_score_:.4f}")# 7. Évaluer le modèle final sur le jeu de testprint("\n--- Évaluation du Modèle Final sur le Jeu de Test ---")best_k = grid_search.best_params_['n_neighbors']final_model = KNeighborsRegressor(n_neighbors=best_k)final_model.fit(X_train_scaled, y_train)y_pred = final_model.predict(X_test_scaled)mse_test = mean_squared_error(y_test, y_pred)rmse_test = np.sqrt(mse_test)print(f"Le modèle final avec k={best_k} a été entraîné.")print(f"Erreur Quadratique Moyenne (MSE) sur le test : {mse_test:.4f}")print(f"Racine de l'Erreur Quadratique Moyenne (RMSE) sur le test : {rmse_test:.4f}")print(f"Cela signifie qu'en moyenne, nos prédictions sont erronées d'environ {rmse_test*100000:.0f} $.")
--- Lancement de la recherche du meilleur k via GridSearchCV ---
--- Résultats de la Recherche ---
Meilleur paramètre k trouvé : {'n_neighbors': 13}
Meilleur score (MSE négatif) en validation croisée : -0.4870
--- Évaluation du Modèle Final sur le Jeu de Test ---
Le modèle final avec k=13 a été entraîné.
Erreur Quadratique Moyenne (MSE) sur le test : 0.4283
Racine de l'Erreur Quadratique Moyenne (RMSE) sur le test : 0.6545
Cela signifie qu'en moyenne, nos prédictions sont erronées d'environ 65448 $.
6 Conclusion
La régression k-NN est un outil d’une grande simplicité conceptuelle mais très puissant, surtout lorsque les relations dans les données sont complexes et non-linéaires.
Ce qu’il faut retenir :
C’est un modèle non-paramétrique qui prédit par moyenne des voisins.
Le choix de k est crucial et contrôle le compromis biais-variance.
La mise à l’échelle des variables est une étape obligatoire.
La validation croisée avec recherche sur grille (GridSearchCV) est la méthode standard et robuste pour trouver le meilleur k.
Cette méthodologie de recherche d’hyperparamètres est une compétence universelle en Machine Learning, que vous réutiliserez pour presque tous les modèles que vous apprendrez par la suite.