Prévenir le Surapprentissage : La Régression Régularisée (Ridge, Lasso)
Partie 3 de la série ‘Maîtriser la Régression’
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Le Dilemme du Modèle Trop Parfait
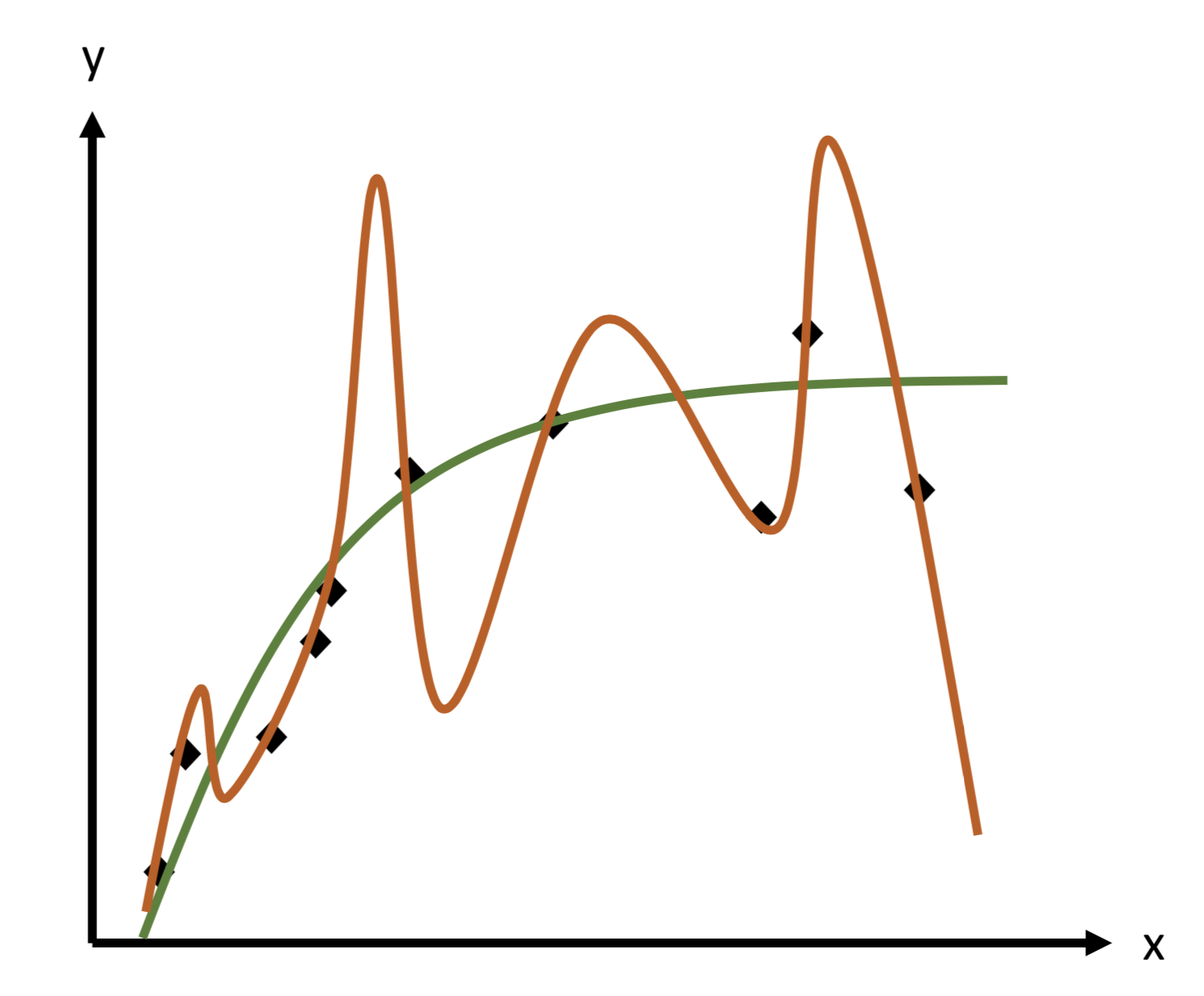
Dans les articles précédents, nous avons appris à construire des modèles de régression de plus en plus complexes. Mais la complexité a un coût. Un modèle avec de nombreuses variables, notamment des termes polynomiaux, peut devenir “trop parfait”. Il peut apprendre les moindres détails et le bruit de vos données d’entraînement au point de perdre sa capacité à généraliser sur de nouvelles données.
Ce phénomène a un nom : le surapprentissage (overfitting). C’est l’un des plus grands ennemis du data scientist.
Ce post explore une famille de techniques puissantes conçues pour combattre ce problème : la régression régularisée. Nous allons découvrir comment “discipliner” nos modèles pour les rendre plus robustes et plus fiables, en nous concentrant sur les deux méthodes les plus célèbres : Ridge et Lasso.
2 Les Problèmes à Résoudre
2.1 Le Surapprentissage (Overfitting)
Imaginez un étudiant qui prépare un examen.
L’étudiant qui comprend apprend les concepts clés et sait les appliquer à de nouveaux problèmes.
L’étudiant qui sur-apprend mémorise par cœur les réponses des exercices d’entraînement. Il aura 100% aux exercices qu’il a déjà vus, mais sera incapable de répondre à une nouvelle question.
Un modèle en surapprentissage est comme ce deuxième étudiant. Il est caractérisé par des coefficients de régression très grands et instables, qui tentent de suivre le bruit des données.
2.2 La Multicolinéarité
Un autre problème courant survient lorsque plusieurs de vos variables explicatives sont fortement corrélées entre elles (ex: taille et poids). Cela rend les estimations des coefficients par les moindres carrés très instables : de petits changements dans les données peuvent entraîner de grands changements dans les coefficients, les rendant difficiles à interpréter.
3 La Solution : Le Principe de Régularisation
L’idée de la régularisation est d’une simplicité élégante. Au lieu de chercher uniquement à minimiser l’erreur de prédiction (la somme des carrés des résidus), on va ajouter une pénalité à notre fonction de coût. Cette pénalité est conçue pour décourager le modèle d’adopter des coefficients trop grands.
Objectif de la Régression Régularisée :\[\text{Minimiser} \left( \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 + \text{Pénalité}(\beta) \right)\]
Cette pénalité agit comme une “laisse” sur les coefficients, les forçant à rester plus petits et plus stables. Le modèle doit maintenant trouver un compromis : bien ajuster les données, mais sans laisser les coefficients exploser.
4 Les Deux Types de Régularisation
La forme exacte de la pénalité donne naissance aux deux principaux types de régression régularisée.
4.1 La Régression Ridge (Pénalité L2)
La régression Ridge ajoute une pénalité proportionnelle à la somme des carrés des coefficients.
Ce qu’elle fait : Elle force les coefficients à se rétrécir (shrinkage) vers zéro. Aucun coefficient n’atteindra jamais exactement zéro, mais ils peuvent devenir très petits.
Le paramètre \(\lambda\) (ou alpha dans Scikit-learn) : C’est l’hyperparamètre de régularisation. Il contrôle la force de la pénalité.
Si \(\lambda = 0\), on retrouve la régression OLS standard.
Si \(\lambda \to \infty\), tous les coefficients tendent vers zéro.
Idéale pour : Gérer la multicolinéarité. En forçant les coefficients des variables corrélées à “partager le fardeau”, elle les rend plus stables.
4.2 La Régression Lasso (Pénalité L1)
La régression Lasso (Least Absolute Shrinkage and Selection Operator) utilise une pénalité proportionnelle à la somme des valeurs absolues des coefficients.
Ce qu’elle fait : Elle rétrécit également les coefficients, mais elle a une propriété remarquable : elle peut forcer certains coefficients à devenir exactement nuls.
La conséquence magique : En annulant les coefficients des variables les moins pertinentes, le Lasso effectue une sélection de variables automatique. C’est un outil extrêmement puissant pour simplifier un modèle.
Idéale pour : Construire des modèles parsimonieux et interprétables quand on suspecte que de nombreuses variables sont inutiles.
4.3 Un mot sur Elastic Net
Elastic Net est simplement une combinaison des pénalités Ridge et Lasso. Elle est utile dans les situations où il y a des groupes de variables fortement corrélées et où l’on souhaite tout de même réaliser une sélection de variables.
5 Prérequis Crucial : La Mise à l’Échelle des Données
Règle d’Or
Avant d’appliquer une régression régularisée, vous devez impérativement mettre vos variables numériques à la même échelle.
Pourquoi ? La pénalité est appliquée de la même manière à tous les coefficients. Si une variable salaire (en dizaines de milliers) et une variable age (en dizaines) ne sont pas sur la même échelle, la pénalité affectera leurs coefficients de manière complètement inéquitable.
La méthode la plus courante est la standardisation (ou Z-score), qui consiste à centrer chaque variable sur 0 et à la réduire à un écart-type de 1.
6 Atelier Pratique : Prédire le Diabète
Utilisons le jeu de données diabetes de Scikit-learn pour voir Ridge et Lasso en action. L’objectif est de prédire une mesure de la progression de la maladie un an après le début de l’étude.
import pandas as pdimport numpy as npfrom sklearn.datasets import load_diabetesfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LinearRegression, Ridge, Lassoimport matplotlib.pyplot as plt# 1. Charger les donnéesdiabetes = load_diabetes()X, y = diabetes.data, diabetes.targetfeature_names = diabetes.feature_namesdf = pd.DataFrame(X, columns=feature_names)# 2. Diviser les données en ensembles d'entraînement et de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. Mettre les données à l'échelle (Standardisation)scaler = StandardScaler()# IMPORTANT : On ajuste le scaler UNIQUEMENT sur les données d'entraînementX_train_scaled = scaler.fit_transform(X_train)# On applique la même transformation aux données de testX_test_scaled = scaler.transform(X_test)# 4. Entraîner les modèles# Modèle de base sans régularisationols = LinearRegression()ols.fit(X_train_scaled, y_train)# Modèle Ridge (alpha est notre lambda)ridge = Ridge(alpha=1.0)ridge.fit(X_train_scaled, y_train)# Modèle Lassolasso = Lasso(alpha=1.0)lasso.fit(X_train_scaled, y_train)# 5. Comparer les coefficientscoefficients = pd.DataFrame({'Feature': feature_names,'OLS': ols.coef_,'Ridge': ridge.coef_,'Lasso': lasso.coef_})print("--- Comparaison des Coefficients des Modèles ---")print(coefficients.round(2))# 6. Comparer les performances sur le jeu de testprint("\n--- Performance sur le Jeu de Test (R²) ---")print(f"OLS R²: {ols.score(X_test_scaled, y_test):.4f}")print(f"Ridge R²: {ridge.score(X_test_scaled, y_test):.4f}")print(f"Lasso R²: {lasso.score(X_test_scaled, y_test):.4f}")# Visualisation des coefficientscoefficients.plot(x='Feature', y=['OLS', 'Ridge', 'Lasso'], kind='bar', figsize=(15, 8))plt.title('Comparaison des Coefficients des Modèles de Régression')plt.ylabel('Valeur du Coefficient')plt.xticks(rotation=45)plt.grid(axis='y')plt.show()
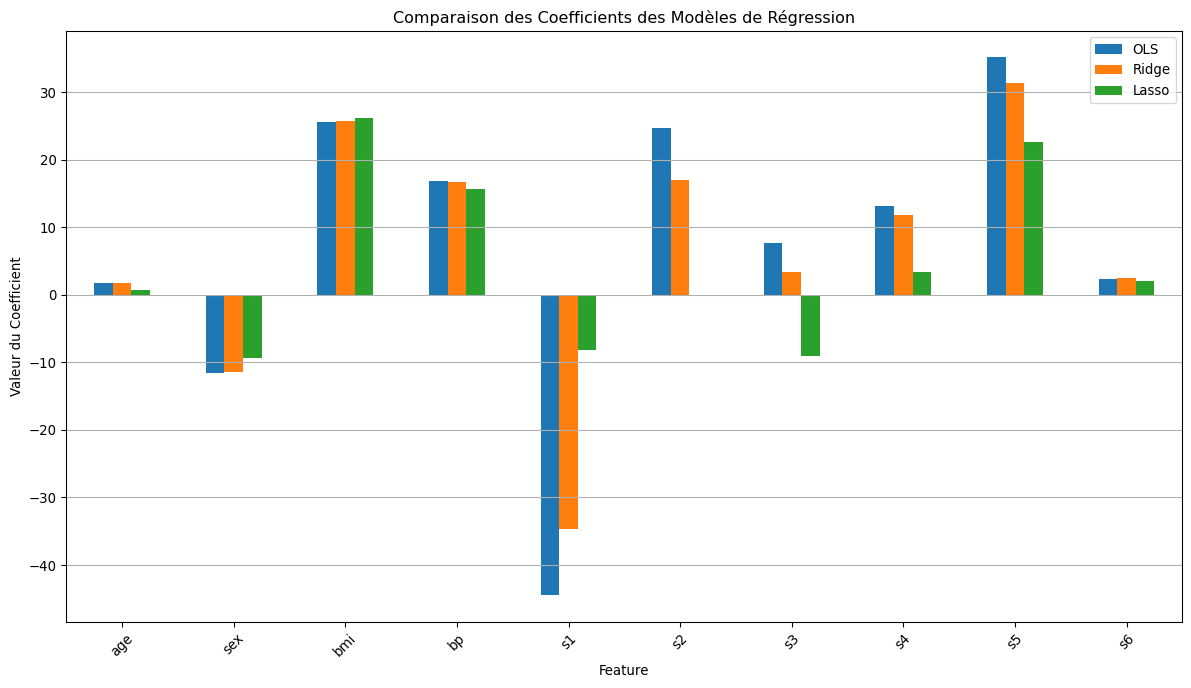
--- Comparaison des Coefficients des Modèles ---
Feature OLS Ridge Lasso
0 age 1.75 1.81 0.69
1 sex -11.51 -11.45 -9.30
2 bmi 25.61 25.73 26.22
3 bp 16.83 16.73 15.66
4 s1 -44.45 -34.67 -8.23
5 s2 24.64 17.05 -0.00
6 s3 7.68 3.37 -9.02
7 s4 13.14 11.76 3.42
8 s5 35.16 31.38 22.64
9 s6 2.35 2.46 2.10
--- Performance sur le Jeu de Test (R²) ---
OLS R²: 0.4526
Ridge R²: 0.4541
Lasso R²: 0.4669
6.1 Interprétation des Résultats
Coefficients :
Les coefficients OLS sont les plus grands en valeur absolue.
Les coefficients Ridge sont systématiquement plus petits que ceux de l’OLS. C’est l’effet de “shrinkage” en action.
Les coefficients Lasso sont encore plus intéressants : plusieurs d’entre eux (age, sex, s4) ont été réduits à exactement zéro. Le Lasso nous dit que, pour ce niveau de pénalité, ces variables ne sont pas utiles pour la prédiction.
Performance : Dans ce cas, les performances (R²) sur le jeu de test sont très similaires. Cependant, les modèles Ridge et Lasso sont plus parsimonieux et probablement plus robustes à de légères variations dans les données. Le Lasso nous a même offert un modèle plus simple avec seulement 7 variables au lieu de 10.
7 Conclusion
La régularisation n’est pas juste une technique avancée, c’est un outil essentiel dans la boîte à outils du data scientist moderne. Elle permet de construire des modèles plus stables, plus interprétables et plus performants sur des données nouvelles.
Utilisez Ridge lorsque vous avez de la multicolinéarité et que vous pensez que toutes vos variables sont potentiellement utiles.
Utilisez Lasso lorsque vous voulez un modèle plus simple et que vous suspectez que de nombreuses variables sont superflues.
En maîtrisant Ridge et Lasso, vous êtes mieux armé pour affronter les défis des jeux de données complexes du monde réel.
Et maintenant ?
Nous avons exploré en profondeur la prédiction de valeurs numériques. Mais que faire lorsque la cible n’est pas un nombre, mais une catégorie comme “Oui/Non” ou “Client/Prospect” ? Dans notre prochain article, nous ferons le saut vers la classification en introduisant l’un des modèles les plus fondamentaux et les plus utiles : la régression logistique.
8 Exercices
Exercise 1
Question 1
Quel est le principal problème que la régularisation cherche à résoudre ?
Question 2
Quelle est l’idée fondamentale de la régularisation ?
Question 3
Laquelle de ces affirmations décrit le mieux la régression Ridge (pénalité L2) ?
Question 4
La régression Lasso (pénalité L1) est particulièrement appréciée pour sa capacité à :
Question 5
Pourquoi est-il crucial de mettre les variables à l’échelle (ex: standardisation) avant d’appliquer une régression Ridge ou Lasso ?
Question 6
Dans les modèles Ridge et Lasso, que se passe-t-il si l’hyperparamètre de régularisation alpha (ou \(\lambda\)) est très proche de zéro ?
Question 7
Laquelle de ces techniques est la plus adaptée si vous suspectez que beaucoup de vos variables sont inutiles et que vous souhaitez un modèle simple et interprétable ?
Question 8
La régression Ridge est particulièrement efficace pour stabiliser les coefficients d’un modèle en présence de :
Question 9
Dans l’atelier pratique, le modèle Lasso a mis le coefficient de la variable sex à zéro. Comment interpréter ce résultat ?
Question 10
Par rapport aux coefficients d’un modèle OLS, ceux d’un modèle Ridge (avec alpha > 0) seront :