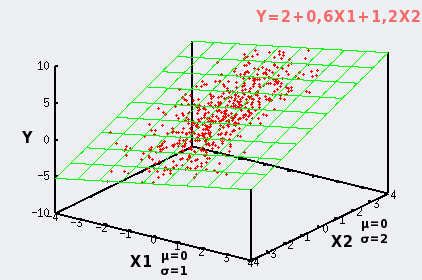
La Régression Linéaire Multiple : Le Modèle Phare de la Prédiction
Modélisation, Estimation par Moindres Carrés et Évaluation de la Performance
Machine Learning
Régression
Apprentissage Supervisé
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Au-delà de la Ligne Droite
Dans notre introduction au Machine Learning, nous avons défini la régression comme la tâche de prédire une valeur continue. Le cas le plus simple est la régression linéaire simple, où l’on prédit une variable cible \(Y\) à l’aide d’une seule variable explicative \(X\).
Cependant, la réalité est rarement si simple. Le prix d’une maison ne dépend pas seulement de sa surface, mais aussi du nombre de chambres, de l’âge du bâtiment, de sa localisation, etc. Pour construire des modèles plus réalistes et plus performants, nous devons utiliser plusieurs variables explicatives. C’est le domaine de la régression linéaire multiple.
Ce post va disséquer ce modèle fondamental. Nous allons :
Formaliser le modèle mathématique.
Comprendre comment on estime ses paramètres avec la méthode des moindres carrés.
Apprendre à évaluer sa qualité avec le coefficient de détermination \(R^2\).
Discuter des stratégies pour sélectionner les variables les plus pertinentes.
2 La Modélisation : L’Équation à Plusieurs Dimensions
L’objectif de la régression linéaire multiple est de modéliser une variable dépendante (ou cible) \(Y\) comme une combinaison linéaire de plusieurs variables explicatives (ou features) \(X_1, X_2, \dots, X_p\).
\(Y\) : La variable dépendante, celle que nous cherchons à prédire.
\(X_j\) : La \(j\)-ième variable explicative ou prédicteur.
\(\beta_0\) : L’ordonnée à l’origine (intercept). C’est la valeur attendue de \(Y\) lorsque toutes les variables explicatives sont nulles.
\(\beta_j\) : Le coefficient de régression associé à la variable \(X_j\). C’est le terme le plus important à interpréter.
Interprétation d’un coefficient \(\beta_j\)
\(\beta_j\) représente la variation moyenne de la variable \(Y\) pour une augmentation d’une unité de la variable \(X_j\), en maintenant toutes les autres variables explicatives (\(X_k\) pour \(k \neq j\)) constantes. C’est le concept de “toutes choses égales par ailleurs” (ceteris paribus).
\(\varepsilon\) : Le terme d’erreur (ou résidu). Il représente la partie de \(Y\) qui n’est pas expliquée par le modèle linéaire. Il capture les effets des variables non incluses, les erreurs de mesure et la variabilité aléatoire inhérente. On suppose généralement que \(\varepsilon\) suit une loi normale de moyenne 0 et de variance constante \(\sigma^2\).
En notation matricielle, pour un échantillon de \(n\) observations, le modèle se réécrit de manière compacte : \[ \mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon} \]
3 L’Estimation : La Méthode des Moindres Carrés Ordinaires (MCO)
Le modèle ci-dessus est théorique. En pratique, nous ne connaissons pas les vrais coefficients \(\beta_j\). Nous devons les estimer à partir de notre échantillon de données \(D_n=\left\{(x_i, y_i)\right\}_{i=1}^n\). Nous noterons ces estimations \(\hat{\beta}_j\).
Notre modèle prédit une valeur \(\hat{y}_i\) pour chaque observation \(x_i\) : \[ \hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_{i1} + \hat{\beta}_2 x_{i2} + \dots + \hat{\beta}_p x_{ip} \]
La méthode des Moindres Carrés Ordinaires (MCO), ou Ordinary Least Squares (OLS), consiste à trouver les coefficients \(\hat{\beta}_j\) qui minimisent la somme des carrés des erreurs de prédiction (les résidus).
On cherche donc à minimiser la Somme des Carrés des Résidus (RSS) : \[ \text{RSS} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \sum_{i=1}^{n} \left(y_i - (\hat{\beta}_0 + \sum_{j=1}^{p} \hat{\beta}_j x_{ij})\right)^2 \]
Sans entrer dans les détails du calcul différentiel, la solution à ce problème d’optimisation est unique et s’exprime élégamment en notation matricielle : \[ \hat{\boldsymbol{\beta}} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y} \] C’est cette formule qui est implémentée dans les fonctions .fit() des bibliothèques comme Scikit-learn ou statsmodels.
4 Évaluer la Qualité du Modèle : Le Coefficient de Détermination (\(R^2\))
Une fois notre modèle estimé, la question cruciale est : est-il bon ? Explique-t-il bien nos données ?
Pour répondre, on décompose la variance totale de notre variable cible \(Y\).
Somme Totale des Carrés (SST - Total Sum of Squares) : C’est la variance totale de \(Y\). Elle mesure la dispersion des observations \(y_i\) autour de leur moyenne \(\bar{y}\). \[ \text{SST} = \sum_{i=1}^{n} (y_i - \bar{y})^2 \]
Somme des Carrés des Résidus (SSE - Sum of Squared Errors) : C’est la même chose que la RSS. Elle représente la part de la variance totale qui n’est pas expliquée par notre modèle. C’est la variance “résiduelle”. \[ \text{SSE} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \]
Somme des Carrés de la Régression (SSR - Sum of Squared Regression) : C’est la part de la variance totale qui est expliquée par notre modèle. Elle mesure la dispersion des valeurs prédites \(\hat{y}_i\) autour de la moyenne \(\bar{y}\). \[ \text{SSR} = \sum_{i=1}^{n} (\hat{y}_i - \bar{y})^2 \]
Il existe une relation fondamentale : SST = SSR + SSE. La variance totale est la somme de la partie expliquée et de la partie non expliquée.
Le coefficient de détermination, \(R^2\), est simplement la proportion de la variance totale qui est expliquée par le modèle :
Un \(R^2 = 0.82\) signifie que 82% de la variabilité de la variable cible \(Y\) est expliquée par les variables explicatives incluses dans notre modèle.
Plus le \(R^2\) est proche de 1, meilleur est l’ajustement du modèle aux données.
5 Un Regard Critique : Le \(R^2\) Ajusté
Le \(R^2\) a un défaut majeur : il augmente mécaniquement (ou au mieux, stagne) chaque fois que vous ajoutez une nouvelle variable au modèle, même si cette variable est complètement inutile ! Cela peut nous pousser à construire des modèles inutilement complexes.
Le \(R^2\) ajusté corrige ce problème en pénalisant le modèle pour l’ajout de variables non pertinentes. Il prend en compte le nombre de variables explicatives (\(p\)) et la taille de l’échantillon (\(n\)).
Règle d’or : Pour comparer des modèles avec un nombre de variables différent, utilisez toujours le \(R^2\) ajusté. C’est un indicateur de performance plus honnête.
6 La Sélection de Variables : Construire un Modèle Parsimonieux
L’objectif n’est pas de créer le modèle avec le plus de variables possible, mais le modèle le plus parsimonieux : le modèle le plus simple qui explique le mieux les données (principe du rasoir d’Ockham).
Pourquoi ?
Interprétabilité : Un modèle avec 5 variables est plus facile à comprendre qu’un modèle avec 50.
Prévention du surapprentissage : Moins de variables signifie moins de risque de “mémoriser” le bruit des données d’entraînement.
Coût : Collecter et maintenir des données a un coût.
Plusieurs stratégies algorithmiques existent pour sélectionner les meilleures variables :
Sélection Ascendante (Forward Selection) : On part d’un modèle vide et on ajoute une par une les variables qui améliorent le plus le modèle, jusqu’à ce que l’amélioration ne soit plus significative.
Élimination Descendante (Backward Elimination) : On part du modèle complet (avec toutes les variables) et on retire une par une les variables les moins utiles, jusqu’à ce que la suppression d’une variable dégrade significativement le modèle.
Sélection Pas à Pas (Stepwise Selection) : Une combinaison des deux approches, qui ajoute et retire des variables à chaque étape.
Ces méthodes s’appuient sur des critères comme la p-value des coefficients, le \(R^2\) ajusté, ou des critères d’information comme l’AIC ou le BIC.
7 Conclusion
La régression linéaire multiple est un outil incroyablement puissant et flexible, qui constitue la base de nombreux modèles plus complexes en statistique et en Machine Learning. Vous savez maintenant comment formuler le modèle, comment ses paramètres sont estimés via les moindres carrés, et comment évaluer sa performance avec le \(R^2\) et le \(R^2\) ajusté.
Cependant, ce modèle repose sur des hypothèses importantes (linéarité, indépendance des erreurs, homoscédasticité, normalité des erreurs). La prochaine étape logique dans la maîtrise de la régression est d’apprendre à diagnostiquer si ces hypothèses sont respectées et que faire si ce n’est pas le cas.
8 Exercices
Exercise 1 (Atelier Pratique : Construction d’un Modèle de Prédiction de Ventes) Nous disposons d’un jeu de données sur la publicité, qui contient les budgets alloués à la publicité TV, radio et presse (newspaper) ainsi que les ventes (sales) correspondantes.
Objectif : Construire un modèle de régression linéaire multiple pour prédire les ventes en fonction des budgets publicitaires et interpréter ses résultats.
1. Chargement et Exploration des Données
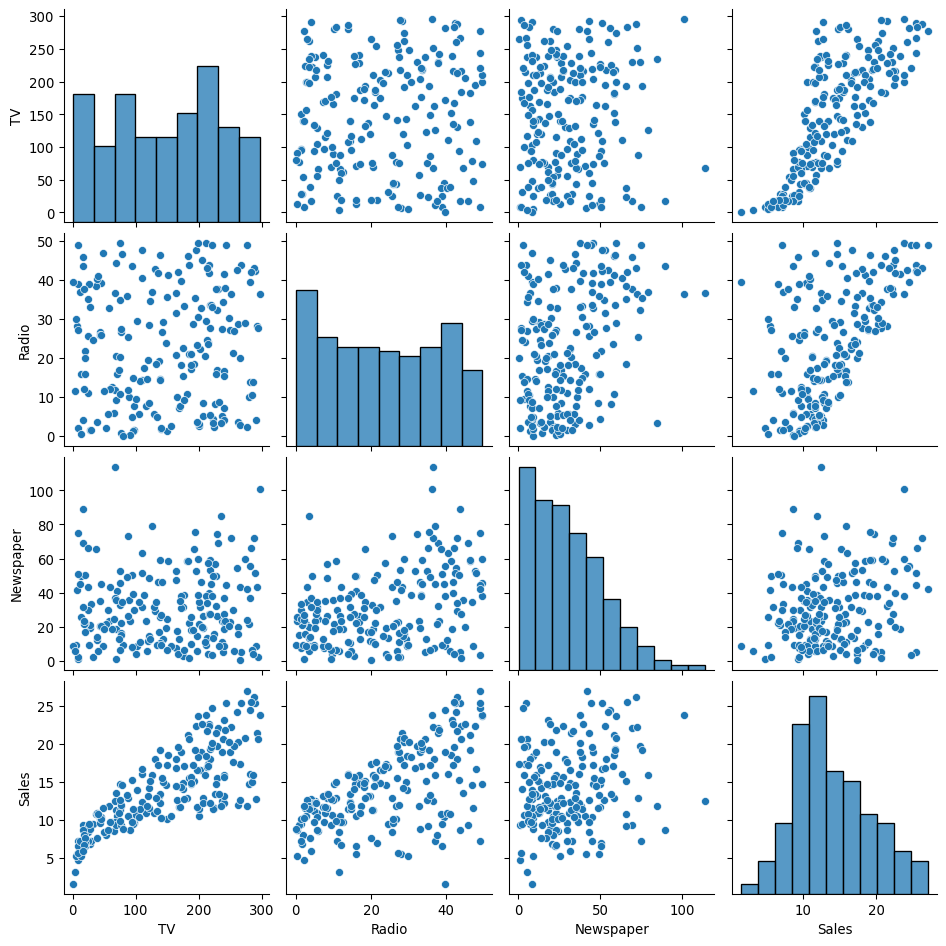
La première étape est de charger les données et de visualiser les relations entre les variables.
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport statsmodels.formula.api as smf# Charger les données depuis une URLurl ='https://raw.githubusercontent.com/JWarmenhoven/ISLR-python/master/Notebooks/Data/Advertising.csv'df = pd.read_csv(url, index_col=0)print("Aperçu des données :")print(df.head())# Visualiser les relations par pairesprint("\nVisualisation des relations :")sns.pairplot(df)plt.show()
Aperçu des données :
TV Radio Newspaper Sales
1 230.1 37.8 69.2 22.1
2 44.5 39.3 45.1 10.4
3 17.2 45.9 69.3 9.3
4 151.5 41.3 58.5 18.5
5 180.8 10.8 58.4 12.9
Visualisation des relations :
Premières Observations
Le pairplot nous montre que : - Il semble y avoir une forte relation linéaire positive entre les dépenses TV et les ventes. - La relation entre la radio et les ventes semble également positive, mais plus dispersée. - La relation entre la presse (newspaper) et les ventes est beaucoup moins claire.
2. Construction et Ajustement du Modèle
Nous allons utiliser la bibliothèque statsmodels, qui est excellente pour l’inférence statistique et fournit des résumés de modèle très détaillés. La syntaxe formule est très intuitive.
# Définir la formule du modèle : sales est expliquée par TV, radio et newspaperformula ='Sales ~ TV + Radio + Newspaper'# Créer et ajuster le modèle OLS (Ordinary Least Squares)model = smf.ols(formula, data=df).fit()# Afficher le résumé complet du modèleprint(model.summary())
Le tableau ci-dessus est une mine d’or d’informations. Analysons les points clés :
R-squared (R²) : 0.897. C’est une excellente valeur ! Cela signifie que 89.7% de la variabilité des ventes est expliquée par les budgets publicitaires dans notre modèle.
Adj. R-squared (R² ajusté) : 0.896. Très proche du R², ce qui indique que nous n’avons probablement pas inclus de variables inutiles.
Coefficients (coef) :
Intercept (\(\hat{\beta}_0\)) : 2.9389. C’est la base de nos ventes, si tous les budgets étaient à zéro.
TV (\(\hat{\beta}_1\)) : 0.0458. Pour chaque unité (disons 1000$) supplémentaire dépensée en pub TV, les ventes augmentent en moyenne de 0.0458 unités (disons 45.8 produits), en maintenant les budgets radio et presse constants.
radio (\(\hat{\beta}_2\)) : 0.1885. L’impact de la radio semble être le plus fort.
newspaper (\(\hat{\beta}_3\)) : -0.0010. Le coefficient est très proche de zéro et négatif, ce qui est surprenant.
P>|t| (p-value des coefficients) : C’est le test de significativité pour chaque variable.
Les p-values pour Intercept, TV et radio sont extrêmement faibles (0.000), bien en dessous de 0.05. Cela signifie que ces variables ont une contribution statistiquement significative au modèle.
La p-value pour newspaper est de 0.860, ce qui est très élevé. On ne peut pas rejeter l’hypothèse nulle que son coefficient est égal à zéro. En d’autres termes, une fois que l’on connaît les budgets TV et radio, le budget presse n’apporte pas d’information supplémentaire significative pour prédire les ventes.
4. Conclusion de l’Atelier
Nous avons construit un modèle de régression performant. L’analyse nous a montré que les investissements en TV et en radio sont des prédicteurs très significatifs des ventes. En revanche, l’investissement en presse, une fois les autres pris en compte, ne semble pas avoir d’impact statistiquement significatif.
Une étape suivante logique serait de construire un modèle plus simple, sans la variable newspaper, et de comparer son \(R^2\) ajusté à celui de notre modèle actuel.
Exercise 2
Question 1
Quel est l’objectif principal de la régression linéaire multiple ?
Question 2
Dans l’équation \(Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \varepsilon\), comment interprète-t-on le coefficient \(\beta_1\) ?
Question 3
La méthode des Moindres Carrés Ordinaires (MCO) cherche à trouver les coefficients qui minimisent :
Question 4
Un coefficient de détermination \(R^2\) de 0.85 signifie que :
Question 5
Pourquoi préfère-t-on souvent le \(R^2\) ajusté au \(R^2\) standard pour comparer des modèles ?
Question 6
Le principe de parcimonie (ou rasoir d’Ockham) en modélisation suggère de :
Question 7
Dans l’atelier pratique, la p-value associée au coefficient de Newspaper est de 0.860. Qu’est-ce que cela implique ?
Question 8
En se basant sur les résultats de l’atelier, quelle est l’interprétation correcte du coefficient de TV (0.0458) ?
Question 9
Quelle est la principale limite du \(R^2\) que le \(R^2\) ajusté cherche à corriger ?
Question 10
Au vu des résultats de l’atelier (p-values des coefficients), quelle serait la prochaine étape la plus logique pour améliorer le modèle ?