Forêt Aléatoire vs. Gradient Boosting : Lequel Choisir pour Votre Projet ?
Machine Learning
Apprentissage Supervisé
Forêts Aléatoires
Gradient Boosting
Comparaison
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction
Nous arrivons au terme de notre exploration des méthodes ensemblistes. Après avoir disséqué la sagesse parallèle des Forêts Aléatoires et l’apprentissage séquentiel du Gradient Boosting, il est temps de les mettre face à face. Dans ce duel, nous allons comparer leur philosophie, leur comportement en pratique et vous donner les clés pour choisir le bon champion pour votre projet.
2 Rappel des Philosophies : Deux Stratégies pour une Victoire 🧠 vs. 🚀
Avant le combat, un rappel de la stratégie de chaque concurrent :
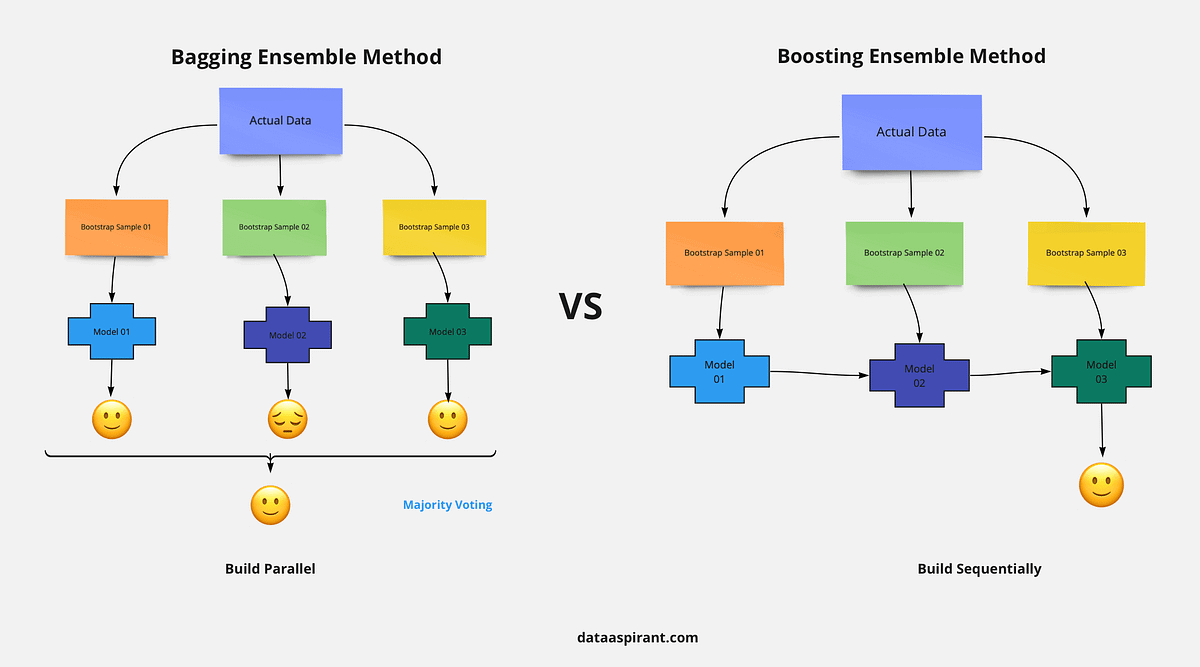
Forêt Aléatoire (RF) : La Force du Nombre.
Stratégie : Déployer une armée d’experts (des arbres de décision profonds) qui travaillent de manière indépendante et parallèle. Chaque expert est entraîné sur une vision légèrement différente des données.
Objectif : Réduire la variance. La décision finale, prise par vote majoritaire, lisse les prédictions extrêmes et rend le modèle stable et robuste.
Philosophie : La sagesse de la foule.
Gradient Boosting (GB) : L’Apprentissage par l’Erreur.
Stratégie : Construire une chaîne d’apprentis (des arbres de décision très simples) de manière séquentielle. Chaque apprenti se spécialise dans la correction des erreurs laissées par l’équipe qui le précède.
Objectif : Réduire le biais. Le modèle final est un super-spécialiste, construit itérativement pour s’ajuster au plus près des données.
Philosophie : L’amélioration continue.
3 Le “Bake-Off” : Comparaison sur le Terrain ⚔️
Mettons les deux algorithmes à l’épreuve sur le jeu de données wine. Le code ci-dessous entraîne les deux modèles et compare leur performance ainsi que les variables qu’ils jugent les plus importantes.
import pandas as pdfrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.metrics import classification_report, accuracy_scoreimport matplotlib.pyplot as plt# 1. Charger les donnéeswine = load_wine()X, y = wine.data, wine.targetfeature_names = wine.feature_namesX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 2. Entraîner et évaluer une Forêt Aléatoireprint("--- Performance de la Forêt Aléatoire ---")rf_clf = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)rf_clf.fit(X_train, y_train)y_pred_rf = rf_clf.predict(X_test)print(f"Accuracy: {accuracy_score(y_test, y_pred_rf):.4f}")print(classification_report(y_test, y_pred_rf, target_names=wine.target_names))# 3. Entraîner et évaluer un modèle de Gradient Boostingprint("\n--- Performance du Gradient Boosting ---")gb_clf = GradientBoostingClassifier(n_estimators=100, random_state=42)gb_clf.fit(X_train, y_train)y_pred_gb = gb_clf.predict(X_test)print(f"Accuracy: {accuracy_score(y_test, y_pred_gb):.4f}")print(classification_report(y_test, y_pred_gb, target_names=wine.target_names))# 4. Comparaison de l'importance des variablesrf_importances = pd.Series(rf_clf.feature_importances_, index=feature_names)gb_importances = pd.Series(gb_clf.feature_importances_, index=feature_names)fig, axes = plt.subplots(1, 2, figsize=(20, 8))fig.suptitle("Importance des Variables (Feature Importance)", fontsize=16)rf_importances.nlargest(10).plot(kind='barh', ax=axes[0], color='skyblue')axes[0].set_title("Forêt Aléatoire")axes[0].invert_yaxis()gb_importances.nlargest(10).plot(kind='barh', ax=axes[1], color='salmon')axes[1].set_title("Gradient Boosting")axes[1].invert_yaxis()plt.tight_layout(rect=[0, 0.03, 1, 0.95])plt.show()
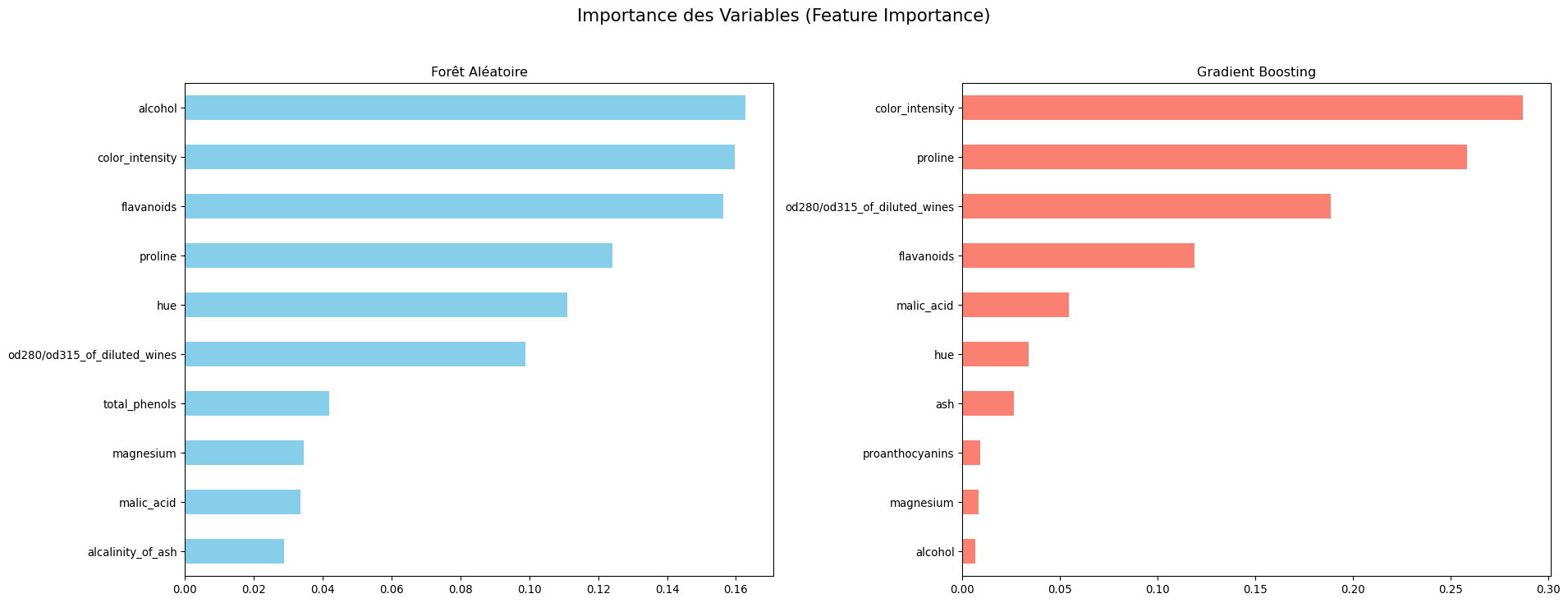
Comparaison de l’importance des variables entre la Forêt Aléatoire et le Gradient Boosting.
Analyse du Duel
Round 1 : Performance “Out-of-the-Box”. Sur ce jeu de données propre, les deux modèles sont excellents. La Forêt Aléatoire atteint même un score parfait. En général, la RF est connue pour être un modèle de base extrêmement solide avec très peu de réglages.
Round 2 : Importance des Variables. Les deux modèles s’accordent sur les variables les plus importantes (flavanoids, proline, color_intensity), mais les poids sont différents. La RF donne une vision “moyennée” et globale de l’importance. Le GB peut donner plus de poids à une variable qui, bien que moins importante globalement, s’est avérée cruciale pour corriger des erreurs spécifiques sur des cas difficiles.
Round 3 : Sensibilité au Tuning. C’est ici que la plus grande différence apparaît. La RF est robuste ; augmenter le nombre d’arbres améliore la performance jusqu’à un plateau, sans risque majeur de sur-apprentissage. Le GB est un pur-sang qui demande un réglage fin. Le compromis entre learning_rate et n_estimators est critique. Un mauvais réglage peut facilement mener au sur-apprentissage. Pour extraire les dernières gouttes de performance du GB, un travail de validation croisée et de recherche d’hyperparamètres est quasi indispensable.
4 Tableau Comparatif : Le Guide de Décision 🗺️
Caractéristique
Forêt Aléatoire (Random Forest)
Gradient Boosting
Vainqueur / Nuance
Vitesse d’entraînement
Rapide (les arbres sont construits en parallèle)
Lent (les arbres sont construits en séquence)
🏆 Forêt Aléatoire
Performance Maximale Potentielle
Très élevée
Souvent state-of-the-art (si bien réglé)
🏆 Gradient Boosting
Facilité de Tuning
Facile, peu d’hyperparamètres critiques (n_estimators)
Complexe, couple learning_rate/n_estimators est crucial
🏆 Forêt Aléatoire
Robustesse / Sur-apprentissage
Très robuste, faible risque de sur-apprentissage
Risque de sur-apprentissage plus élevé si mal réglé
🏆 Forêt Aléatoire
Performance “Out-of-the-Box”
Excellente, souvent le meilleur choix pour un baseline rapide
Bonne, mais nécessite souvent un tuning pour briller
🏆 Forêt Aléatoire
5 Conclusion : Le Bon Outil pour le Bon Problème ✅
Il n’y a pas de vainqueur absolu, seulement le bon outil pour la bonne tâche.
Choisissez la Forêt Aléatoire (Random Forest) si :
Vous avez besoin d’un modèle de base performant et fiable rapidement.
Vous préférez un algorithme facile à régler et robuste au sur-apprentissage.
Le temps de développement est une contrainte.
C’est votre premier essai sur un problème : c’est le couteau suisse du data scientist.
Choisissez le Gradient Boosting si :
Votre objectif est d’extraire chaque once de performance possible.
Vous êtes dans un contexte compétitif (ex: Kaggle) où même 0.1% de précision compte.
Vous avez le temps et les ressources pour effectuer une recherche d’hyperparamètres rigoureuse.
C’est le scalpel de précision pour finaliser un modèle de production.
En maîtrisant ces deux approches, vous êtes équipé pour affronter la grande majorité des problèmes de classification et de régression sur données tabulaires avec confiance et efficacité.