Gradient Boosting : Apprendre de ses Erreurs pour Atteindre l’Excellence
Machine Learning
Apprentissage Supervisé
Boosting
Gradient Boosting
Python
Author
Affiliation
Gemini
ENSPY & ESSFAR
Published
July 21, 2025
1 Introduction
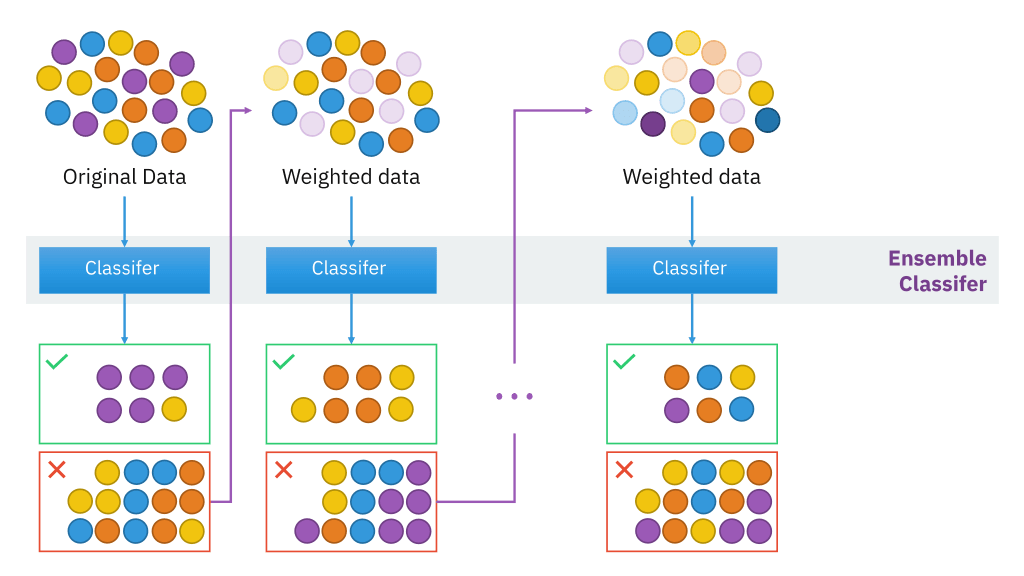
Après avoir exploré la puissance de la coopération parallèle avec les Forêts Aléatoires, nous changeons radicalement de philosophie. Bienvenue dans le monde du Boosting, où les modèles ne sont pas des experts indépendants, mais des apprentis qui apprennent séquentiellement les uns des autres pour construire ensemble un “super-modèle”.
2 Changement de Paradigme : De la Coopération à la Correction 🚶♂️→🏃♂️→🚀
Contrairement au Bagging qui vise à réduire la variance, le Boosting s’attaque principalement au biais. L’idée n’est pas de moyenner de nombreux modèles complexes, mais de construire un modèle final puissant en additionnant les contributions de nombreux modèles très simples (souvent des arbres de décision avec une ou deux profondeurs, appelés “stumps”).
La philosophie est la suivante : 1. On commence avec un premier modèle très simple qui fait des erreurs. 2. On entraîne un deuxième modèle, non pas sur les données brutes, mais en lui demandant de corriger les erreurs du premier. 3. On entraîne un troisième modèle pour corriger les erreurs restantes de l’ensemble des deux premiers. 4. … et ainsi de suite. Chaque nouveau modèle est un “spécialiste des faiblesses” de l’ensemble des modèles qui le précèdent.
3 Le Gradient Boosting : Une Généralisation Puissante 🧠
Si des algorithmes comme AdaBoost modifient les poids des observations pour se concentrer sur les erreurs, le Gradient Boosting adopte une approche plus directe et plus générale.
L’idée maîtresse est que chaque nouvel arbre est entraîné à prédire les erreurs résiduelles de l’ensemble des arbres précédents.
Imaginons un problème de régression simple où l’on veut prédire \(y\) :
Initialisation : On commence par une prédiction très simple, généralement la moyenne de la variable cible : \(F_0(x) = \bar{y}\). Cette première prédiction a évidemment une erreur.
Itération 1 :
On calcule les erreurs (les résidus) : \(r_1 = y - F_0(x)\).
On entraîne un premier arbre de décision faible (\(h_1\)) pour qu’il apprenne à prédire ces résidus \(r_1\).
On met à jour notre modèle global : \(F_1(x) = F_0(x) + \nu \cdot h_1(x)\).
Itération 2 :
On calcule les nouveaux résidus : \(r_2 = y - F_1(x)\).
On entraîne un deuxième arbre faible (\(h_2\)) pour qu’il apprenne à prédire ces nouveaux résidus \(r_2\).
On met à jour le modèle global : \(F_2(x) = F_1(x) + \nu \cdot h_2(x)\).
On répète ce processus \(M\) fois. Le modèle final est une somme additive :
\[ F_M(x) = \sum_{m=0}^{M} \nu \cdot h_m(x) \]
3.1 Le Rôle Crucial du Taux d’Apprentissage (Learning Rate)
Le paramètre \(\nu\) (prononcé “nu”) est le taux d’apprentissage (learning rate). C’est un facteur (généralement petit, ex: 0.1) qui pondère la contribution de chaque nouvel arbre. Il joue un rôle de régularisation essentiel :
En ralentissant l’apprentissage, on empêche le modèle de corriger trop brutalement ses erreurs et de tomber dans le sur-apprentissage.
Un learning_rate plus faible nécessite un plus grand nombre d’arbres (n_estimators) pour atteindre une bonne performance, mais le modèle final sera généralement plus robuste.
4 Les Champions du Gradient Boosting : XGBoost, LightGBM, CatBoost 🏆
Le Gradient Boosting est si puissant qu’il a donné naissance à des bibliothèques ultra-optimisées qui dominent les compétitions de Machine Learning sur données tabulaires.
4.1 XGBoost (eXtreme Gradient Boosting) : Le Roi de la Régularisation
L’innovation majeure de XGBoost est d’intégrer la régularisation directement dans sa fonction objectif. Au lieu de simplement minimiser l’erreur, il minimise une fonction qui pénalise aussi la complexité des arbres.
La fonction objectif à minimiser pour construire le \(t\)-ième arbre est : \[ \text{Obj}^{(t)} = \sum_{i=1}^{n} l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t) \] où \(l\) est la fonction de perte (ex: erreur quadratique) et \(\Omega(f_t)\) est le terme de régularisation.
Ce terme de régularisation est la clé : \[ \Omega(f_t) = \gamma T + \dfrac{1}{2}\lambda \sum_{j=1}^{T} w_j^2 \]
\(T\) est le nombre de feuilles dans l’arbre. Le paramètre \(\gamma\) contrôle la pénalité sur le nombre de feuilles, agissant comme un mécanisme d’élagage.
\(w_j\) est le score (ou poids) de la feuille \(j\). Le paramètre \(\lambda\) applique une régularisation L2 sur ces poids, ce qui empêche les prédictions d’être trop extrêmes et rend le modèle plus stable.
En bref, XGBoost ne cherche pas seulement à bien prédire, il cherche à le faire avec les arbres les plus simples possible.
4.2 LightGBM (Light Gradient Boosting Machine) : Le Champion de la Vitesse
Développé par Microsoft, LightGBM se concentre sur l’efficacité et la vitesse d’entraînement, souvent sans compromis sur la performance. Il y parvient grâce à deux techniques principales :
Gradient-based One-Side Sampling (GOSS) : L’idée est que les observations avec de petits gradients (celles qui sont déjà bien prédites) contribuent peu à l’apprentissage. GOSS conserve toutes les observations avec de grands gradients (les “mauvais élèves”) et échantillonne aléatoirement une petite partie de celles avec de faibles gradients. Cela accélère considérablement la recherche de la meilleure division.
Exclusive Feature Bundling (EFB) : Dans les jeux de données à haute dimensionnalité (souvent sparse), de nombreuses variables sont mutuellement exclusives (par exemple, elles ne prennent jamais de valeurs non nulles simultanément). EFB regroupe intelligemment ces variables en une seule, réduisant le nombre de caractéristiques à analyser.
De plus, LightGBM utilise une stratégie de croissance d’arbre leaf-wise (par la feuille), contrairement à la croissance level-wise (par niveau) de XGBoost. Il choisit de développer la feuille qui promet la plus grande réduction de perte, ce qui converge plus rapidement vers un bon modèle, mais peut être plus sujet au surapprentissage sur de petits jeux de données.
4.3 CatBoost (Categorical Boosting) : Le Spécialiste des Données Catégorielles
Développé par Yandex, CatBoost excelle dans un domaine où les autres algorithmes nécessitent un pré-traitement minutieux : les variables catégorielles.
Son innovation majeure est une méthode de target encoding améliorée appelée Ordered Boosting. Le target encoding classique (remplacer une catégorie par la moyenne de la variable cible pour cette catégorie) est sujet à la “fuite de la cible” (target leakage), car l’information de la cible d’une observation est utilisée pour créer une de ses propres caractéristiques.
CatBoost résout ce problème en calculant les statistiques de manière ordonnée. Pour chaque observation, il calcule la statistique de la cible en utilisant uniquement les observations qui la précèdent dans une permutation aléatoire du jeu de données. Cela garantit que l’information de la cible ne “fuit” pas, rendant l’encodage beaucoup plus robuste.
CatBoost utilise également des arbres de décision symétriques (ou “oblivious”), où le même critère de division est appliqué à tous les nœuds d’un même niveau. Ces arbres sont moins complexes, plus rapides à entraîner et agissent comme une forme de régularisation naturelle.
5 Atelier Pratique : Gradient Boosting en Action avec Scikit-learn
Utilisons l’implémentation de base de Scikit-learn pour voir le Gradient Boosting en action sur le jeu de données wine.
from sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.metrics import accuracy_score, classification_report# 1. Charger les donnéeswine = load_wine()X, y = wine.data, wine.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 2. Entraîner le modèle Gradient Boosting# Les hyperparamètres clés sont :# - n_estimators : le nombre d'arbres séquentiels# - learning_rate : le poids de la contribution de chaque arbre# - max_depth : la profondeur maximale de chaque arbre faiblegb_clf = GradientBoostingClassifier( n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)gb_clf.fit(X_train, y_train)# 3. Évaluer la performancey_pred_gb = gb_clf.predict(X_test)acc_gb = accuracy_score(y_test, y_pred_gb)print(f"--- Performance du Gradient Boosting ---")print(f"Accuracy: {acc_gb:.4f}\n")print(classification_report(y_test, y_pred_gb, target_names=wine.target_names))
Analyse : Le modèle est déjà très performant. En pratique, la clé pour en extraire le maximum est de régler finement les hyperparamètres, notamment le couple learning_rate et n_estimators. Un learning_rate plus bas (ex: 0.01) demanderait plus d’n_estimators (ex: 500 ou 1000) pour converger, mais produirait souvent un modèle plus généralisable.
6 Conclusion : La Quête de la Performance Maximale
Le Boosting, et en particulier ses implémentations modernes comme XGBoost, LightGBM et CatBoost, est une technique d’une puissance redoutable. En construisant un modèle fort à partir d’une séquence de modèles faibles qui se corrigent mutuellement, il est capable d’atteindre des niveaux de performance que peu d’autres algorithmes peuvent égaler sur des données structurées.
Maintenant que nous avons exploré les deux grandes philosophies ensemblistes, il est temps de les mettre face à face. Dans notre prochain et dernier article, nous organiserons le duel : Forêt Aléatoire contre Gradient Boosting. Lequel choisir, et quand ?
7 Exercices
Exercise 1
Question 1
Quelle est la principale différence de philosophie entre le Bagging et le Boosting ?
Question 2
Dans l’algorithme du Gradient Boosting pour la régression, que cherche à prédire chaque nouvel arbre de décision faible ?
Question 3
Quel est le rôle du paramètre learning_rate (taux d’apprentissage) ?
Question 4
Quelle est l’innovation majeure de XGBoost qui le distingue du Gradient Boosting standard ?
Question 5
Quel algorithme est particulièrement réputé pour sa vitesse d’entraînement grâce à des techniques comme GOSS et EFB ?
Question 6
Quelle est la spécialité de l’algorithme CatBoost ?
Question 7
Si vous diminuez le learning_rate d’un modèle de Gradient Boosting, comment devriez-vous ajuster le n_estimators pour potentiellement obtenir un meilleur modèle ?
Question 8
La croissance d’arbre “leaf-wise” (par la feuille), utilisée par LightGBM, est généralement :
Question 9
Dans l’équation de la fonction objectif de XGBoost, que représente le terme \(\gamma T\) ?
Question 10
Le problème de “target leakage” (fuite de la cible) est un risque associé à certaines méthodes d’encodage des variables catégorielles. Quel algorithme a été spécifiquement conçu pour contrer ce problème ?
Question 11
Quel est le but principal de la technique de Boosting ?
Question 12
Comment la prédiction finale est-elle construite dans un modèle de Gradient Boosting ?
Question 13
Qu’est-ce qu’un “stump” (ou souche) dans le contexte des algorithmes de Boosting ?
Question 14
Dans la fonction objectif de XGBoost, quel est le rôle du terme \(\frac{1}{2}\lambda \sum_{j=1}^{T} w_j^2\) ?
Question 15
Quelle est la caractéristique principale des “arbres symétriques” (oblivious trees) utilisés par CatBoost ?
Question 16
Pourquoi les algorithmes de Boosting utilisent-ils généralement des “apprenants faibles” (weak learners) comme des arbres de décision peu profonds ?
Question 17
Le terme “Gradient” dans “Gradient Boosting” fait référence à :
Question 18
Pour quel type de données les algorithmes comme XGBoost, LightGBM et CatBoost sont-ils le plus souvent considérés comme l’état de l’art ?
Question 19
Quelle est une stratégie de réglage courante et efficace pour un modèle de Gradient Boosting ?
Question 20
Outre sa fonction objectif régularisée, quel est un autre avantage pratique majeur de XGBoost ?