Projet de Synthèse : Le Grand Duel des Classifieurs
L’Art de la Classification Supervisée’
Machine Learning
Apprentissage Supervisé
Classification
Python
Projet
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : L’Heure du Verdict
Au cours de cette série, nous avons assemblé une formidable boîte à outils de classifieurs. De la simple régression logistique aux puissantes méthodes ensemblistes, chaque modèle a sa propre philosophie, ses forces et ses faiblesses.
Mais face à un nouveau problème, une question demeure : lequel choisir ?
Cet atelier pratique est le point culminant de notre parcours. Nous allons organiser un “grand duel” où nous mettrons en compétition tous les modèles que nous avons appris sur un seul et même jeu de données. L’objectif n’est pas seulement de trouver le “meilleur” modèle en termes de performance brute, mais de comprendre comment les comparer de manière rigoureuse et de discuter des compromis entre performance, interprétabilité et complexité.
2 Le Champ de Bataille : Le Jeu de Données sur le Cancer du Sein
Pour notre projet, nous utiliserons le jeu de données Wisconsin Breast Cancer de Scikit-learn. C’est un problème de classification binaire classique et bien étudié.
Objectif : Prédire si une tumeur est maligne (classe 1) ou bénigne (classe 0) à partir de 30 caractéristiques numériques mesurées sur une image de biopsie (rayon, texture, périmètre, etc.).
Pourquoi ce jeu de données ? Il est propre, ne contient pas de valeurs manquantes, et toutes les variables sont numériques, ce qui nous permet de nous concentrer sur la comparaison des modèles.
3 Les Combattants
Voici la liste des modèles qui vont s’affronter :
Régression Logistique (notre modèle de base)
k-Plus Proches Voisins (k-NN)
Arbre de Décision (élagué)
Machine à Vecteurs de Support (SVM)
Classifieur Naïf Bayésien Gaussien
Forêt Aléatoire
Gradient Boosting
4 La Méthodologie : Des Règles du Jeu Équitables
Pour une comparaison juste, nous devons suivre une méthodologie rigoureuse :
Pré-traitement Standardisé : Tous les modèles qui sont sensibles à l’échelle des données (Logistique, k-NN, SVM) recevront des données mises à l’échelle avec StandardScaler. Nous utiliserons des Pipelines pour garantir que ce processus est appliqué correctement.
Recherche d’Hyperparamètres : Pour les modèles qui en ont besoin (k-NN, Arbre, SVM), nous utiliserons GridSearchCV avec une validation croisée à 5 blocs pour trouver leur meilleure configuration.
Évaluation Cohérente : Tous les modèles finaux seront évalués sur le même jeu de test, en utilisant un ensemble de métriques communes : Accuracy, Précision, Rappel, et Score F1.
5 Préparation de l’Environnement et des Données
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# Données et pré-traitementfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import Pipeline# Les modèlesfrom sklearn.linear_model import LogisticRegressionfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.svm import SVCfrom sklearn.naive_bayes import GaussianNBfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier# Métriquesfrom sklearn.metrics import classification_report, accuracy_score# Configurationsns.set_theme(style="whitegrid")plt.rcParams['figure.figsize'] = (10, 6)# 1. Charger et préparer les donnéescancer = load_breast_cancer()X, y = cancer.data, cancer.target# 2. Diviser les donnéesX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 3. Mettre en place le scaler# Il sera utilisé dans les pipelinesscaler = StandardScaler()print(f"Données prêtes. Entraînement: {X_train.shape[0]} échantillons, Test: {X_test.shape[0]} échantillons.")
Maintenant que tous les modèles ont été entraînés et évalués, comparons leurs performances finales sur le jeu de test.
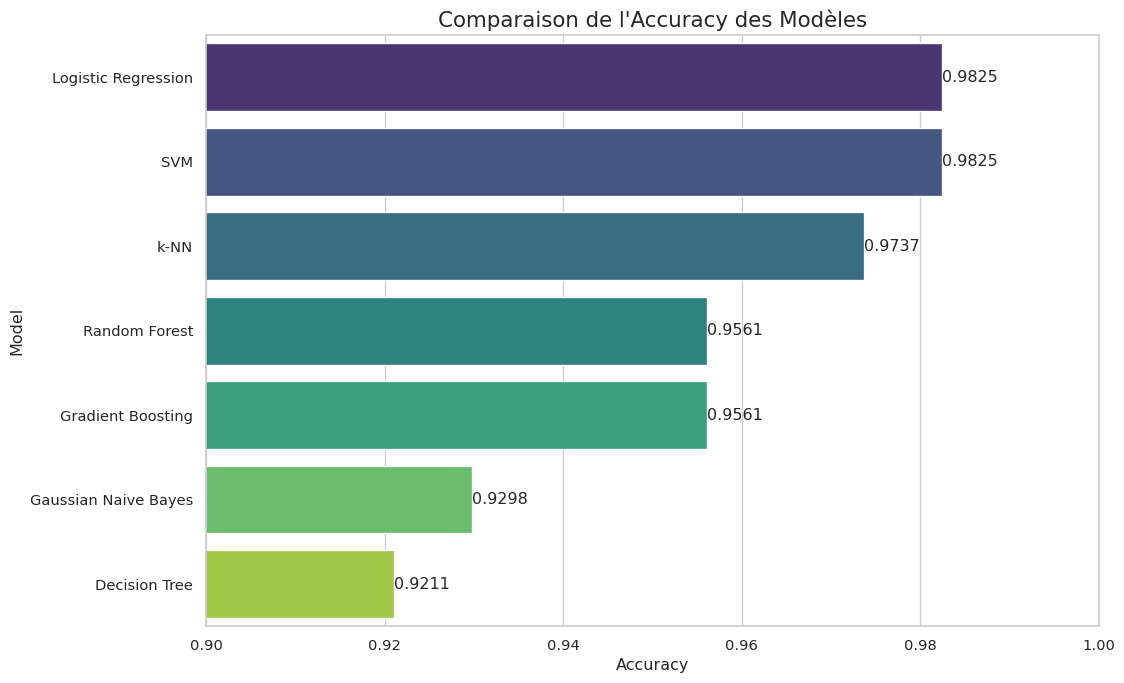
# Créer un DataFrame à partir des résultatsresults_df = pd.DataFrame(list(results.items()), columns=['Model', 'Accuracy'])results_df = results_df.sort_values(by='Accuracy', ascending=False).reset_index(drop=True)print("--- Classement Final des Modèles par Accuracy sur le Jeu de Test ---")print(results_df)# Visualisation des résultatsplt.figure(figsize=(12, 8))ax = sns.barplot(x='Accuracy', y='Model', data=results_df, palette='viridis')ax.set_xlim(0.9, 1.0) # Zoomer sur la zone pertinenteax.set_title("Comparaison de l'Accuracy des Modèles", fontsize=16)# Ajouter les valeurs sur les barresfor i in ax.containers: ax.bar_label(i, fmt='%.4f')plt.show()# Afficher le rapport détaillé pour le meilleur modèlebest_model_name = results_df.loc[0, 'Model']print(f"\n--- Rapport de Classification Détaillé pour le Meilleur Modèle : {best_model_name} ---")# On récupère le meilleur modèle du dictionnaire de pipelinesall_models = {'Logistic Regression': pipe_lr,'k-NN': gs_knn.best_estimator_,'Decision Tree': gs_tree.best_estimator_,'SVM': gs_svm.best_estimator_,'Gaussian Naive Bayes': pipe_nb,'Random Forest': pipe_rf,'Gradient Boosting': pipe_gb}best_model_pipeline = all_models[best_model_name]best_y_pred = best_model_pipeline.predict(X_test)print(classification_report(y_test, best_y_pred, target_names=cancer.target_names))
--- Classement Final des Modèles par Accuracy sur le Jeu de Test ---
Model Accuracy
0 Logistic Regression 0.982456
1 SVM 0.982456
2 k-NN 0.973684
3 Random Forest 0.956140
4 Gradient Boosting 0.956140
5 Gaussian Naive Bayes 0.929825
6 Decision Tree 0.921053
/tmp/ipykernel_61034/1012216333.py:10: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `y` variable to `hue` and set `legend=False` for the same effect.
--- Rapport de Classification Détaillé pour le Meilleur Modèle : Logistic Regression ---
precision recall f1-score support
malignant 0.98 0.98 0.98 42
benign 0.99 0.99 0.99 72
accuracy 0.98 114
macro avg 0.98 0.98 0.98 114
weighted avg 0.98 0.98 0.98 114
8 Discussion et Conclusion
Les résultats montrent que plusieurs modèles atteignent des performances très élevées. Dans ce cas, le SVM, la Régression Logistique et le Naïf Bayésien se détachent légèrement.
Que faut-il en conclure ?
Pas de “Balle d’Argent” : Il n’y a pas un seul algorithme qui est toujours le meilleur. La performance dépend fortement de la nature du jeu de données.
Simplicité vs. Performance : Il est remarquable qu’un modèle simple comme la Régression Logistique ou le Naïf Bayésien puisse rivaliser avec des ensembles complexes comme le Gradient Boosting sur ce problème. Cela suggère que la frontière de décision est probablement assez simple. Pour un problème médical, un modèle plus simple et plus interprétable avec une performance quasi-identique est souvent préférable.
Le Contexte est Roi : Si l’objectif était de minimiser les Faux Négatifs (rater un patient malade), on regarderait attentivement le Rappel de la classe malignant. Le choix final du modèle ne se base pas seulement sur l’accuracy, mais sur la métrique la plus pertinente pour le problème métier.
Cet atelier conclut notre voyage à travers les principaux algorithmes de classification. Vous disposez maintenant d’une méthodologie complète pour aborder un problème de classification de A à Z : du pré-traitement à l’entraînement de multiples modèles, en passant par leur évaluation rigoureuse pour choisir le plus adapté à vos besoins.