La Classification par Arbre de Décision : L’Interprétabilité au Pouvoir
Machine Learning
Apprentissage Supervisé
Classification
Python
Scikit-learn
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Décider comme un Humain
Après avoir exploré des modèles qui apprennent des équations (régression logistique) ou qui se basent sur la similarité (k-NN), nous allons maintenant découvrir une famille de modèles qui raisonnent d’une manière beaucoup plus proche de la pensée humaine : les arbres de décision.
Un arbre de décision est un modèle de classification (et de régression) qui prédit la valeur d’une variable cible en apprenant des règles de décision simples, inférées à partir des données. Sa grande force est son interprétabilité : le modèle final peut être visualisé sous la forme d’un organigramme, rendant le processus de décision totalement transparent.
Ce post vous guidera à travers la construction de ces arbres, le critère qu’ils utilisent pour poser les “bonnes” questions, et la manière de les “élaguer” pour éviter leur principal défaut : le surapprentissage.
2 L’Intuition : Un Jeu de “Qui est-ce ?”
Imaginez que vous deviez deviner si un passager du Titanic a survécu. Vous pourriez poser une série de questions :
Le passager était-il un homme ou une femme ?
Si c’est une femme, elle a plus de chances de survivre.
Si c’est un homme, était-il un enfant ?
Si oui, ses chances de survie augmentent.
Si c’est un homme adulte, dans quelle classe voyageait-il ?
En 3ème classe, ses chances sont très faibles.
Un arbre de décision fonctionne exactement de cette manière. Il apprend la meilleure séquence de questions (ou “divisions”) à poser pour séparer les données en groupes aussi “purs” que possible en termes de classe cible.
Image d’un diagramme d’arbre de décision simple pour la classification
3 La Construction de l’Arbre : Comment Choisir la Meilleure Question ?
L’algorithme de construction, appelé partition binaire récursive, cherche à chaque étape la division qui maximise la “pureté” des nœuds enfants. Mais comment mesurer cette pureté ? On utilise une métrique d’impureté.
L’objectif est de trouver la division qui résulte en la plus grande réduction d’impureté. Deux critères sont principalement utilisés :
3.1 L’Impureté de Gini
L’indice de Gini mesure la probabilité de mal classer une observation si on l’étiquetait au hasard, en suivant la distribution des étiquettes dans le nœud.
Pour un nœud donné, l’impureté de Gini est : \[ G = 1 - \sum_{k=1}^{K} p_k^2 \] Où \(p_k\) est la proportion d’observations de la classe \(k\) dans le nœud.
Un nœud pur (toutes les observations de la même classe) a un Gini de 0.
Un nœud avec une impureté maximale (répartition 50/50 dans un cas binaire) a un Gini de 0.5.
3.2 L’Entropie
Issue de la théorie de l’information, l’entropie mesure le niveau de “désordre” ou d’incertitude dans un nœud. \[ H = - \sum_{k=1}^{K} p_k \log_2(p_k) \]
Un nœud pur a une entropie de 0.
Un nœud avec une impureté maximale a une entropie de 1 (dans un cas binaire).
En pratique, les deux critères donnent des résultats très similaires. Scikit-learn utilise l’indice de Gini par défaut.
4 Le Surapprentissage et la Nécessité de l’Élagage
Comme pour la régression, si on laisse un arbre grandir sans contrainte, il va créer des règles ultra-spécifiques pour classer parfaitement chaque point du jeu d’entraînement. Il va sur-apprendre le bruit et ne pas bien généraliser.
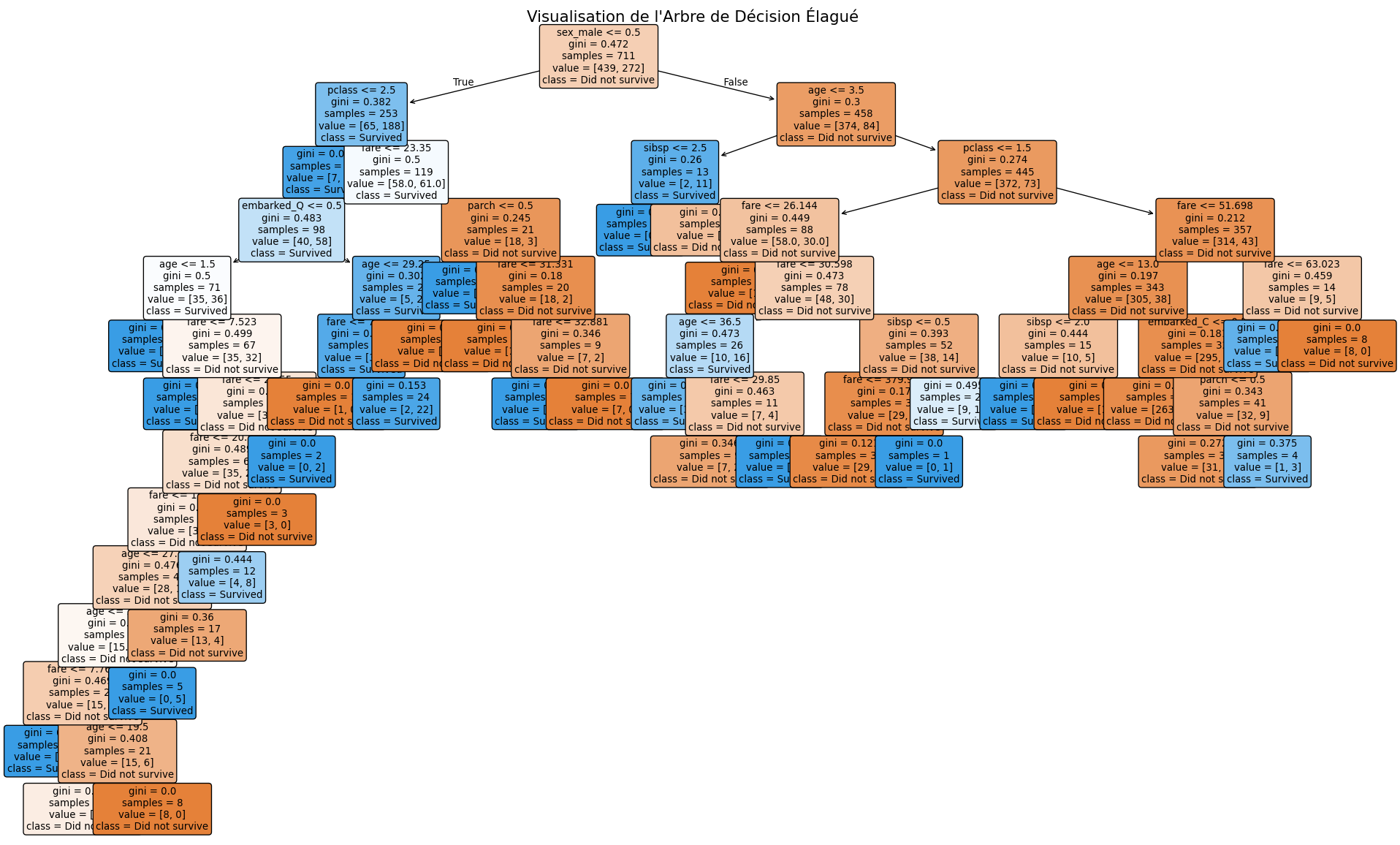
La solution est l’élagage (pruning). La méthode la plus efficace est l’élagage par complexité de coût, que nous avons déjà vue en régression. On fait pousser un arbre complet, puis on “taille” les branches qui apportent le moins d’information, en utilisant un paramètre de complexité ccp_alpha pour trouver le meilleur compromis entre simplicité et performance.
5 Atelier Pratique : Prédire la Survie sur le Titanic
Utilisons le célèbre jeu de données du Titanic pour construire un classifieur par arbre de décision et trouver sa complexité optimale grâce à l’élagage.
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.tree import DecisionTreeClassifier, plot_treefrom sklearn.preprocessing import OneHotEncoderfrom sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelineimport matplotlib.pyplot as pltimport seaborn as sns# --- 1. Charger et préparer les données depuis Seaborn ---print("--- Chargement et préparation des données Titanic ---")titanic = sns.load_dataset('titanic')# Sélection des variables et de la cible# On retire les colonnes redondantes ou avec trop de valeurs manquantes pour cet exempleX = titanic.drop(['survived', 'alive', 'who', 'adult_male', 'deck', 'embark_town', 'class'], axis=1)y = titanic['survived']# Gérer les valeurs manquantes de manière simple# Pour l'âge, on remplace par la médianeX['age'].fillna(X['age'].median(), inplace=True)# Pour 'embarked', on supprime les 2 lignes où la valeur est manquanteX.dropna(subset=['embarked'], inplace=True)# On s'assure que y est aligné avec X après la suppressiony = y[X.index] print("Données prêtes. Dimensions de X:", X.shape)# --- 2. Définir le pipeline de pré-traitement ---# On identifie les colonnes numériques et catégorielles à utilisernumeric_features = ['pclass', 'age', 'sibsp', 'parch', 'fare']categorical_features = ['sex', 'embarked']# Créer un transformateur pour encoder les variables catégorielles# Le reste des colonnes (numériques) sera laissé tel quel ('passthrough')preprocessor = ColumnTransformer( transformers=[ ('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features) ], remainder='passthrough')# --- 3. Diviser les données avant toute modélisation ---X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# --- 4. Entraîner un arbre complet pour montrer le surapprentissage ---# On crée un pipeline pour enchaîner le pré-traitement et le modèlefull_tree_pipeline = Pipeline(steps=[ ('preprocessor', preprocessor), ('classifier', DecisionTreeClassifier(random_state=42))])full_tree_pipeline.fit(X_train, y_train)print(f"\n--- Arbre de Décision Complet ---")print(f"Score sur l'entraînement: {full_tree_pipeline.score(X_train, y_train):.4f}")print(f"Score sur le test: {full_tree_pipeline.score(X_test, y_test):.4f}")print("Observation: Le score très élevé sur l'entraînement et plus faible sur le test est un signe de surapprentissage.")# --- 5. Trouver le chemin d'élagage et le meilleur alpha ---print("\n--- Recherche de l'Alpha Optimal par Validation Croisée ---")# On doit d'abord transformer les données d'entraînement pour obtenir le cheminX_train_transformed = preprocessor.fit_transform(X_train)# On utilise un classifieur temporaire pour trouver les alphas possiblespath_finder_clf = DecisionTreeClassifier(random_state=42)path = path_finder_clf.cost_complexity_pruning_path(X_train_transformed, y_train)ccp_alphas = path.ccp_alphas[:-1] # On retire le dernier alpha trivialalpha_scores = []for alpha in ccp_alphas: pipeline_pruning = Pipeline(steps=[ ('preprocessor', preprocessor), ('classifier', DecisionTreeClassifier(random_state=42, ccp_alpha=alpha)) ])# On utilise la validation croisée sur l'ensemble d'entraînement score = cross_val_score(pipeline_pruning, X_train, y_train, cv=5, scoring='accuracy') alpha_scores.append(np.mean(score))# On récupère le meilleur alphabest_alpha = ccp_alphas[np.argmax(alpha_scores)]print(f"Meilleur alpha trouvé : {best_alpha:.6f}")# --- 6. Entraîner et évaluer l'arbre élagué final ---pruned_pipeline = Pipeline(steps=[ ('preprocessor', preprocessor), ('classifier', DecisionTreeClassifier(random_state=42, ccp_alpha=best_alpha))])pruned_pipeline.fit(X_train, y_train)print("\n--- Arbre Élagué Optimal ---")print(f"Score sur l'entraînement: {pruned_pipeline.score(X_train, y_train):.4f}")print(f"Score sur le test: {pruned_pipeline.score(X_test, y_test):.4f}")print("Observation: Les scores sont maintenant plus proches. Le modèle généralise mieux.")# --- 7. Visualiser l'arbre élagué ---# On récupère les noms des features après la transformation OneHotEncoder# et on les combine avec les noms des features numériquesfeature_names_transformed =list(pruned_pipeline.named_steps['preprocessor'].named_transformers_['cat'].get_feature_names_out(categorical_features))feature_names_transformed.extend(numeric_features)plt.figure(figsize=(25, 15))plot_tree(pruned_pipeline.named_steps['classifier'], feature_names=feature_names_transformed, class_names=['Did not survive', 'Survived'], filled=True, rounded=True, fontsize=10)plt.title("Visualisation de l'Arbre de Décision Élagué", fontsize=16)plt.show()
--- Chargement et préparation des données Titanic ---
/tmp/ipykernel_58266/3834774650.py:22: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
Données prêtes. Dimensions de X: (889, 8)
--- Arbre de Décision Complet ---
Score sur l'entraînement: 0.9845
Score sur le test: 0.7697
Observation: Le score très élevé sur l'entraînement et plus faible sur le test est un signe de surapprentissage.
--- Recherche de l'Alpha Optimal par Validation Croisée ---
Meilleur alpha trouvé : 0.002110
--- Arbre Élagué Optimal ---
Score sur l'entraînement: 0.8987
Score sur le test: 0.7584
Observation: Les scores sont maintenant plus proches. Le modèle généralise mieux.
6 Conclusion
Les arbres de décision sont des outils fantastiques, non seulement pour la prédiction, mais surtout pour la compréhension. Leur principal avantage est leur transparence : on peut expliquer chaque prédiction en suivant un chemin logique.
Cependant, leur tendance à sur-apprendre et leur instabilité (un petit changement dans les données peut créer un arbre très différent) sont des faiblesses importantes. La technique de l’élagage est essentielle pour les rendre robustes.
Et maintenant ?
Nous avons vu comment construire et discipliner un seul arbre. Mais que se passerait-il si nous pouvions combiner la sagesse de centaines d’arbres différents ? C’est l’idée derrière les méthodes ensemblistes. Dans notre prochain article, nous explorerons les Forêts Aléatoires (Random Forests), qui exploitent cette idée pour créer des modèles parmi les plus performants qui soient.