Les Machines à Vecteurs de Support (SVM) : Trouver la Frontière Optimale
Machine Learning
Apprentissage Supervisé
Classification
Python
Scikit-learn
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Au-delà de la “Bonne” Frontière
Jusqu’à présent, nos classifieurs (régression logistique, arbres) ont cherché une “bonne” frontière pour séparer les classes. Mais s’il existe une infinité de frontières possibles, comment être sûr de choisir la meilleure ?
C’est la question à laquelle répondent les Machines à Vecteurs de Support (SVM - Support Vector Machines). L’idée fondamentale du SVM n’est pas seulement de trouver une ligne qui sépare les données, mais de trouver la frontière optimale, celle qui est la plus éloignée possible de toutes les observations.
Les SVM sont des modèles très puissants, particulièrement efficaces dans les espaces de grande dimension et lorsque le nombre de variables est supérieur au nombre d’observations.
2 L’Intuition : La Marge Maximale
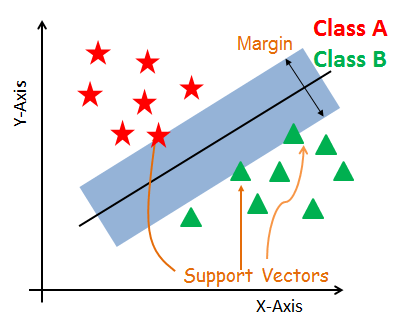
Imaginez que les points de vos deux classes sont des clous plantés sur une planche. Le but du SVM est de trouver une règle (une ligne droite, ou hyperplan en dimension supérieure) qui sépare les deux groupes de clous, tout en étant la plus épaisse possible sans toucher aucun clou.
Cette “épaisseur” de la règle est appelée la marge. Le SVM est donc un classifieur à marge maximale.
Hyperplan de séparation : La ligne centrale qui sépare les classes.
Marge : La “zone de sécurité” de chaque côté de l’hyperplan.
Vecteurs de support : Ce sont les observations qui se trouvent exactement sur le bord de la marge. Ce sont les seuls points qui “supportent” ou définissent l’hyperplan. Si on déplaçait n’importe quel autre point, la frontière ne changerait pas. Si on déplace un vecteur de support, la frontière bouge.
3 La Gestion des Cas Non Séparables : La Marge Douce
Le monde réel est rarement parfait. Que se passe-t-il si les données ne sont pas parfaitement séparables par une ligne droite ?
Le SVM “à marge dure” (hard-margin) échouerait. C’est pourquoi on utilise en pratique le SVM à marge douce (soft-margin). L’idée est d’autoriser le modèle à faire quelques erreurs de classification (des points qui violent la marge ou qui se retrouvent du mauvais côté de l’hyperplan) en échange d’une marge globalement plus large et plus robuste.
Ce compromis est contrôlé par un hyperparamètre crucial, noté C (le paramètre de régularisation) :
C élevé : Le modèle est très strict. Il essaie de classer correctement chaque point, ce qui peut conduire à une marge plus étroite et à du surapprentissage.
C faible : Le modèle est plus permissif. Il privilégie une marge plus large, même si cela signifie mal classer quelques points d’entraînement. Cela conduit à un modèle plus généralisable.
4 Au-delà de la Ligne : L’Astuce du Noyau (Kernel Trick)
Et si les données ne sont pas du tout séparables par une ligne, même avec une marge douce ?
C’est là qu’intervient l’idée la plus puissante des SVM : l’astuce du noyau (kernel trick).
L’idée est de projeter les données dans un espace de plus grande dimension où elles deviendraient linéairement séparables. Imaginez que vous jetez vos points en l’air : vus d’en haut, vous pourriez peut-être tracer un plan qui les sépare parfaitement.
L’astuce du noyau permet de réaliser cette opération de manière très efficace, sans jamais avoir à calculer explicitement les coordonnées des points dans cet espace de grande dimension. On utilise une fonction noyau qui calcule la similarité entre les points comme s’ils étaient dans cet espace supérieur.
Noyaux les plus courants :
linear : Le SVM standard sans transformation.
poly : Pour des frontières polynomiales.
rbf (Radial Basis Function) : Le plus populaire et le plus flexible. Il peut créer des frontières de décision extrêmement complexes. Il est contrôlé par un autre hyperparamètre, gamma, qui définit l’influence d’une seule observation.
5 Le Problème d’Optimisation du SVM
Derrière l’intuition géométrique élégante du SVM se cache un problème d’optimisation mathématique bien défini.
5.1 Marge Dure (Hard Margin)
Dans le cas d’un SVM à marge dure (données parfaitement séparables), l’objectif est de trouver l’hyperplan (défini par son vecteur normal w et son biais b) qui maximise la marge tout en classant correctement tous les points.
Formulation :
\[
\begin{aligned}
& \underset{w, b}{\text{minimiser}} & &\frac{1}{2} ||w||^2 \\
& \text{sous contrainte} & & y_i(w^T x_i + b) \geq 1, \quad \text{pour tout } i = 1, \dots, n
\end{aligned}
\]
\(\frac{1}{2} ||w||^2\) : Minimise la norme du vecteur w, ce qui maximise la marge (la marge est inversement proportionnelle à ||w||).
\(y_i(w^T x_i + b) \geq 1\) : Contraintes assurant que tous les points sont correctement classés et en dehors de la marge.
5.2 Marge Douce (Soft Margin)
Dans le cas plus réaliste où les données ne sont pas parfaitement séparables, on introduit des variables de relâchement \(\xi_i\) pour permettre quelques erreurs.
Formulation :
\[
\begin{aligned}
& \underset{w, b, \xi}{\text{minimiser}} & & \frac{1}{2} ||w||^2 + C \sum_{i=1}^{n} \xi_i \\
& \text{sous contrainte} & & y_i(w^T x_i + b) \geq 1 - \xi_i, \quad \text{pour tout } i = 1, \dots, n \\
& & & \xi_i \geq 0, \quad \text{pour tout } i = 1, \dots, n
\end{aligned}
\]
6 Atelier Pratique : Détecter le Cancer du Sein
Utilisons le jeu de données breast_cancer de Scikit-learn pour construire un classifieur SVM capable de distinguer les tumeurs malignes des tumeurs bénignes.
import pandas as pdimport numpy as npfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVCfrom sklearn.pipeline import Pipelinefrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplayimport matplotlib.pyplot as plt# 1. Charger les donnéescancer = load_breast_cancer()X, y = cancer.data, cancer.targetfeature_names = cancer.feature_namestarget_names = cancer.target_names# 2. Diviser les donnéesX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 3. Créer un Pipeline (mise à l'échelle + modèle)# La mise à l'échelle est cruciale pour les SVMpipeline = Pipeline([ ('scaler', StandardScaler()), ('svm', SVC(probability=True, random_state=42)) # probability=True pour pouvoir calculer l'AUC plus tard])# 4. Mettre en place la recherche sur grille pour trouver les meilleurs hyperparamètresprint("--- Lancement de la recherche des meilleurs hyperparamètres (C, kernel, gamma) ---")# Définir la grille des paramètres à testerparam_grid = {'svm__C': [0.1, 1, 10, 100],'svm__gamma': [1, 0.1, 0.01, 0.001],'svm__kernel': ['rbf', 'linear']}# Configurer GridSearchCV avec 5-fold cross-validationgrid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='accuracy', verbose=1, n_jobs=-1)# 5. Lancer la recherchegrid_search.fit(X_train, y_train)# 6. Afficher les meilleurs résultatsprint("\n--- Résultats de la Recherche ---")print(f"Meilleurs paramètres trouvés : {grid_search.best_params_}")print(f"Meilleur score d'accuracy en validation croisée : {grid_search.best_score_:.4f}")# 7. Évaluer le modèle final sur le jeu de testprint("\n--- Évaluation du Modèle Final sur le Jeu de Test ---")best_model = grid_search.best_estimator_y_pred = best_model.predict(X_test)print("--- Matrice de Confusion ---")cm = confusion_matrix(y_test, y_pred)disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=target_names)disp.plot(cmap=plt.cm.Blues)plt.show()print("\n--- Rapport de Classification ---")print(classification_report(y_test, y_pred, target_names=target_names))
--- Lancement de la recherche des meilleurs hyperparamètres (C, kernel, gamma) ---
Fitting 5 folds for each of 32 candidates, totalling 160 fits
--- Résultats de la Recherche ---
Meilleurs paramètres trouvés : {'svm__C': 10, 'svm__gamma': 0.01, 'svm__kernel': 'rbf'}
Meilleur score d'accuracy en validation croisée : 0.9802
--- Évaluation du Modèle Final sur le Jeu de Test ---
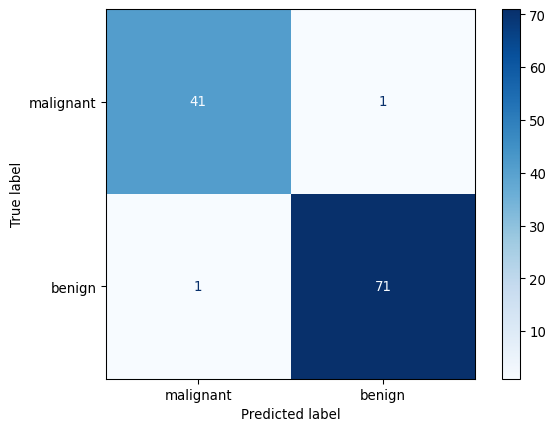
--- Matrice de Confusion ---
Les Machines à Vecteurs de Support sont des classifieurs extrêmement puissants et polyvalents.
Ce qu’il faut retenir :
Leur objectif est de trouver la marge maximale entre les classes.
L’hyperparamètre C contrôle le compromis entre une marge large et la classification correcte des points d’entraînement.
L’astuce du noyau (notamment rbf) leur permet de gérer des relations non-linéaires complexes.
La mise à l’échelle des données est une étape indispensable.
Bien qu’ils soient parfois plus lents à entraîner et moins interprétables que les arbres de décision, leur performance dans les espaces de grande dimension en fait un outil de choix pour de nombreux problèmes, de la bio-informatique à la reconnaissance d’images.
Et maintenant ?
Nous avons vu une série de modèles individuels très performants. Mais comment atteindre le niveau supérieur de performance? En faisant collaborer plusieurs modèles! Dans notre prochain article, nous plongerons dans le monde des méthodes ensemblistes, en commençant par les célèbres Forêts Aléatoires.
8 Exercices
Exercise 1
Question 1 : Objectif Principal du SVM
Quel est l’objectif fondamental d’une Machine à Vecteurs de Support (SVM) ?
Question 2 : Vecteurs de Support
Que sont les “vecteurs de support” dans un modèle SVM ?
Question 3 : Rôle de l’Hyperparamètre C
Dans un SVM à marge douce, à quoi sert l’hyperparamètre de régularisation C ?
Question 4 : Impact d’un C faible
Un choix de C faible dans un SVM conduit généralement à :
Question 5 : L’Astuce du Noyau (Kernel Trick)
Quelle est l’idée principale de l’astuce du noyau (kernel trick) ?
Question 6 : Noyau RBF
Quel est le noyau le plus populaire et le plus flexible, capable de créer des frontières de décision très complexes ?
Question 7 : Prérequis Essentiel
Quelle étape de pré-traitement est particulièrement cruciale avant d’entraîner un modèle SVM ?
Question 8 : Rôle de l’Hyperparamètre gamma
Dans un SVM avec un noyau RBF, que contrôle l’hyperparamètre gamma ?
Question 9 : Avantage Principal des SVM
Dans quel scénario les SVM sont-ils particulièrement réputés pour être efficaces ?
Question 10 : Pipeline dans l’Atelier
Dans l’atelier pratique, pourquoi est-il judicieux d’utiliser un Pipeline Scikit-learn ?
Question 11 : SVM à Marge Dure
Un SVM à marge dure (hard-margin SVM) est approprié lorsque :
Question 12 : Interprétabilité
Comparé à un arbre de décision, un modèle SVM est généralement :
Question 13 : Classification Binaire vs Multi-classes
Les SVM sont intrinsèquement des classifieurs binaires. Comment sont-ils généralement étendus pour gérer des problèmes de classification multi-classes ?
Question 14 : Sensibilité aux Outliers
Comment un SVM à marge dure réagit-il à la présence d’outliers (valeurs aberrantes) ?
Question 15 : Temps d’Entraînement
Comparé à des modèles comme la régression logistique ou les arbres de décision, le temps d’entraînement d’un SVM peut être :
Question 16 : probability=True dans SVC
Dans l’atelier pratique, pourquoi a-t-on mis probability=True lors de l’instanciation de SVC ?
Question 17 : n_jobs=-1 dans GridSearchCV
Que signifie n_jobs=-1 dans la configuration de GridSearchCV ?
Question 18 : Application des SVM
Les SVM sont particulièrement efficaces pour des tâches comme :
Question 19 : Relation entre C et Marge
Si vous augmentez la valeur de C, que se passe-t-il généralement avec la marge ?
Question 20 : Hyperplan
Dans un espace à 3 dimensions, l’hyperplan de séparation d’un SVM est :