La Classification par k-Plus Proches Voisins (k-NN) : Décider par Similarité
Machine Learning
Apprentissage Supervisé
Classification
Python
Scikit-learn
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Apprendre sans Modèle
Dans les posts précédents, le classifieur estimé repose sur l’estimation d’un paramètre: ces modèles sont dit paramétriques.
Dans ce post, nous allons explorer une approche complètement différente : la classification par k-plus proches voisins (k-NN). C’est un modèle non-paramétrique et basé sur les instances (instance-based). On l’appelle parfois un “apprenant paresseux” (lazy learner), car il ne construit pas de modèle explicite pendant la phase d’entraînement. En fait, la phase d’entraînement consiste simplement à mémoriser toutes les données !
La prédiction se fait au dernier moment, en se basant sur un principe d’une simplicité et d’une intuition redoutables : la similarité.
2 L’Intuition : Le Vote du Voisinage
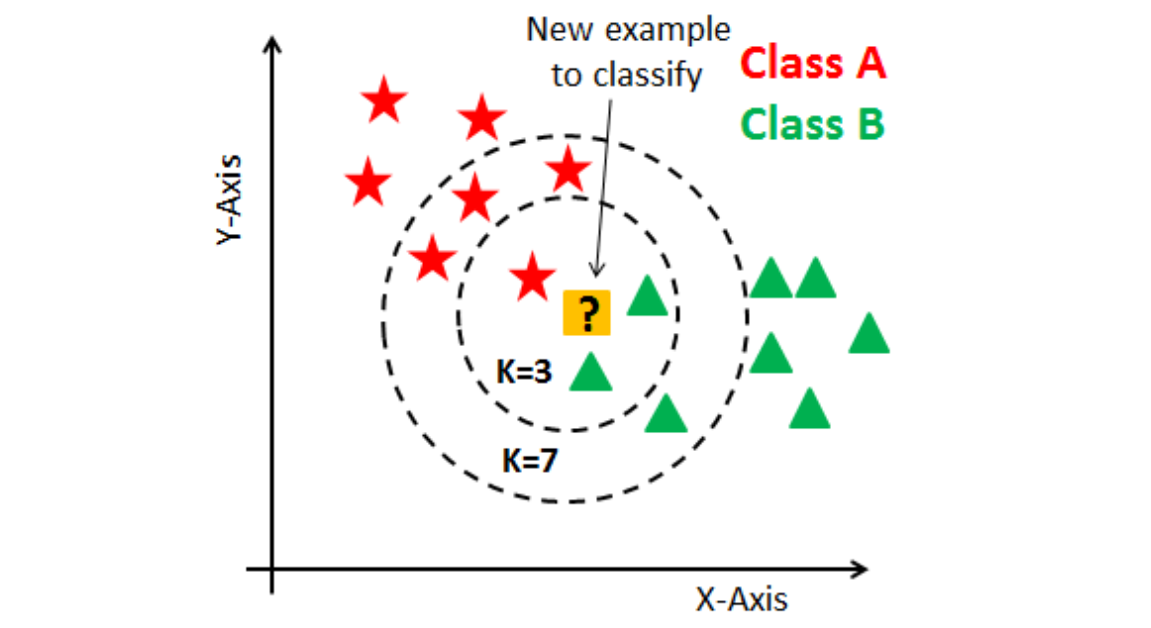
L’algorithme k-NN est basé sur l’adage “Dis-moi qui sont tes amis, je te dirai qui tu es”.
Pour classifier une nouvelle observation x_new dont on ne connaît pas l’étiquette :
Le modèle mesure la distance entre x_new et toutes les autres observations du jeu de données d’entraînement.
Il identifie les k observations les plus proches (ses “k plus proches voisins”).
Il organise un vote à la majorité : la classe la plus représentée parmi ces k voisins est assignée comme prédiction pour x_new.
3 La Mécanique du k-NN
3.1 La Mesure de Distance
La “proximité” est le plus souvent calculée à l’aide de la distance euclidienne, que vous connaissez bien : \[ d(a, b) = \sqrt{\sum_{i=1}^{p} (a_i - b_i)^2} \] Où \(p\) est le nombre de variables explicatives.
3.2 Prérequis Crucial : La Mise à l’Échelle des Variables
Puisque le k-NN est entièrement basé sur les distances, il est extrêmement sensible à l’échelle de vos variables. Une variable avec une grande échelle (ex: un salaire en dizaines de milliers) pèsera beaucoup plus lourd dans le calcul de la distance qu’une variable avec une petite échelle (ex: un âge en dizaines), même si cette dernière est plus importante.
Règle d’Or
Avant d’utiliser le k-NN, vous devez impérativement mettre vos variables numériques à la même échelle, par exemple en utilisant la standardisation (StandardScaler).
3.3 Le Choix de k : Le Compromis Biais-Variance
Comme pour la régression k-NN, le choix de l’hyperparamètre k est fondamental et contrôle le compromis biais-variance.
Si k est petit (ex: k=1) : Le modèle est très sensible au bruit. La frontière de décision sera très complexe et s’adaptera aux particularités locales des données d’entraînement. C’est le cas d’une variance élevée et d’un biais faible (surapprentissage).
Si k est grand : Le modèle devient plus lisse et moins sensible aux variations locales. La frontière de décision sera beaucoup plus simple. C’est le cas d’un biais élevé et d’une variance faible (sous-apprentissage).
Notre objectif est donc de trouver le k optimal qui équilibre ce compromis, généralement via une recherche sur grille avec validation croisée.
4 Atelier Pratique : Classifier les Fleurs d’Iris
Utilisons le jeu de données classique iris pour classifier les fleurs en trois espèces (setosa, versicolor, virginica) en fonction de la longueur et de la largeur de leurs sépales et pétales.
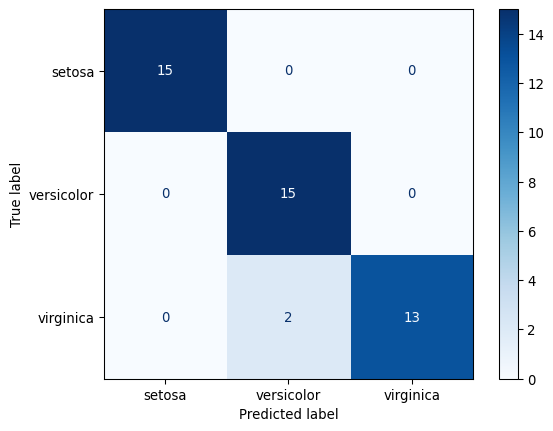
import pandas as pdimport numpy as npfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.pipeline import Pipelinefrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplayimport matplotlib.pyplot as plt# 1. Charger les donnéesiris = load_iris()X, y = iris.data, iris.targetfeature_names = iris.feature_namestarget_names = iris.target_names# 2. Diviser les donnéesX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 3. Créer un Pipeline pour le pré-traitement et le modèle# C'est la meilleure pratique : le pipeline s'assure que la mise à l'échelle# est ajustée sur le train set et appliquée au test set, évitant les fuites de données.pipeline = Pipeline([ ('scaler', StandardScaler()), ('knn', KNeighborsClassifier())])# 4. Mettre en place la recherche sur grille pour trouver le meilleur kprint("--- Lancement de la recherche du meilleur k via GridSearchCV ---")# Définir la grille des valeurs de k à tester# On préfixe le nom du paramètre par le nom de l'étape dans le pipeline ('knn__')param_grid = {'knn__n_neighbors': np.arange(1, 26)}# Configurer GridSearchCV avec 5-fold cross-validation# Le score par défaut pour la classification est l'accuracygrid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='accuracy')# 5. Lancer la recherche sur les données d'entraînementgrid_search.fit(X_train, y_train)# 6. Afficher les meilleurs résultatsprint("\n--- Résultats de la Recherche ---")print(f"Meilleur paramètre k trouvé : {grid_search.best_params_}")print(f"Meilleur score d'accuracy en validation croisée : {grid_search.best_score_:.4f}")# 7. Évaluer le modèle final sur le jeu de testprint("\n--- Évaluation du Modèle Final sur le Jeu de Test ---")best_model = grid_search.best_estimator_y_pred = best_model.predict(X_test)print("--- Matrice de Confusion ---")cm = confusion_matrix(y_test, y_pred)disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=target_names)disp.plot(cmap=plt.cm.Blues)plt.show()print("\n--- Rapport de Classification ---")print(classification_report(y_test, y_pred, target_names=target_names))
--- Lancement de la recherche du meilleur k via GridSearchCV ---
--- Résultats de la Recherche ---
Meilleur paramètre k trouvé : {'knn__n_neighbors': 14}
Meilleur score d'accuracy en validation croisée : 0.9714
--- Évaluation du Modèle Final sur le Jeu de Test ---
--- Matrice de Confusion ---
La classification k-NN est un excellent outil de base, facile à comprendre et souvent étonnamment efficace, surtout pour des problèmes avec des frontières de décision complexes et non-linéaires.
Naturellement non-paramétrique, il peut s’adapter à n’importe quelle forme de distribution.
Inconvénients :
Coût de prédiction élevé : Il doit calculer les distances avec toutes les données d’entraînement pour chaque nouvelle prédiction, ce qui est très lent sur de grands jeux de données.
Sensible aux variables non pertinentes : Si vous avez de nombreuses variables inutiles, elles vont “polluer” le calcul de distance et dégrader la performance.
“Malédiction de la dimensionnalité” : Dans un espace à très haute dimension, la notion de “proximité” perd son sens, et les performances du k-NN s’effondrent.
Et maintenant ?
Nous avons vu un modèle qui apprend une équation (Régression Logistique) et un modèle qui apprend par similarité (k-NN). Dans notre prochain article, nous allons explorer une troisième voie, peut-être la plus intuitive de toutes : la classification par arbre de décision, qui apprend en posant une série de questions.
6 Exercices
Exercise 1
Question 1 : Principe Fondamental du k-NN
Comment l’algorithme k-NN classifie-t-il une nouvelle observation ?
Question 2 : Nature du Modèle
Pourquoi le k-NN est-il souvent qualifié d’"apprenant paresseux" (lazy learner) ?
Question 3 : Prérequis Essentiel
Quelle est l’étape de pré-traitement la plus cruciale avant d’utiliser un classifieur k-NN ?
Question 4 : Impact d’un k faible
Un choix de k très petit (ex: k=1) dans un modèle k-NN conduit généralement à :
Question 5 : Impact d’un k élevé
Que se passe-t-il si vous choisissez une valeur de k très grande ?
Question 6 : Méthode de Recherche pour k
Quelle est la méthode standard et robuste pour trouver la valeur optimale de k ?
Question 7 : Principal Inconvénient
Quel est l’un des inconvénients majeurs de l’algorithme k-NN ?
Question 8 : Rôle du Pipeline
Dans l’atelier pratique, pourquoi est-il recommandé d’utiliser un Pipeline Scikit-learn ?
Question 9 : La Malédiction de la Dimensionnalité
Comment la “malédiction de la dimensionnalité” affecte-t-elle le k-NN ?
Question 10 : k-NN pour la Régression
Si on utilisait k-NN pour un problème de régression (prédire une valeur numérique), comment la prédiction finale serait-elle calculée ?
Question 11 : Distance Euclidienne
Quelle est la formule de la distance euclidienne entre deux points \(a = (a_1, a_2, ..., a_p)\) et \(b = (b_1, b_2, ..., b_p)\) ?
Question 12 : Standardisation
Pourquoi la standardisation (par exemple avec StandardScaler) est-elle particulièrement importante pour k-NN ?
Question 13 : Compromis Biais-Variance
Comment le choix de k influence-t-il le compromis biais-variance dans k-NN ?
Question 14 : Apprentissage Supervisé
Le k-NN est un algorithme d’apprentissage supervisé. Qu’est-ce que cela signifie ?
Question 15 : Frontière de Décision
Comment décririez-vous la frontière de décision d’un classifieur k-NN ?
Question 16 : Données d’Entraînement
Que fait le k-NN pendant la phase d’entraînement ?
Question 17 : Sensibilité au Bruit
Un modèle k-NN avec un k très petit est-il sensible au bruit dans les données ?
Question 18 : Utilisation de stratify dans train_test_split
Dans l’exemple de code, pourquoi utilise-t-on stratify=y lors de la division des données avec train_test_split ?
Question 19 : scoring='accuracy' dans GridSearchCV
Que signifie scoring='accuracy' dans la configuration de GridSearchCV ?
Question 20 : Cas d’Utilisation Idéal
Dans quel type de situation le k-NN est-il particulièrement bien adapté ?