La Simplicité Trompeuse du Classifieur Naïf Bayésien
Quand une hypothèse ‘naïve’ mène à des résultats puissants
Machine Learning
Apprentissage Supervisé
Classification
Statistiques
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : La Puissance de la Probabilité
Dans notre exploration des classifieurs, nous avons vu des modèles qui cherchent des frontières géométriques (SVM) ou qui posent des questions (Arbres de Décision). Nous allons maintenant revenir à une approche purement probabiliste, en nous appuyant sur l’un des théorèmes les plus célèbres des statistiques : le théorème de Bayes.
Le classifieur naïf bayésien (Naive Bayes Classifier) est un modèle génératif, tout comme l’Analyse Discriminante Gaussienne (GDA). Il cherche à modéliser la distribution des données pour chaque classe. Cependant, il y parvient en faisant une hypothèse de travail audacieuse, “naïve”, mais qui le rend incroyablement rapide et efficace, notamment dans des domaines comme la classification de texte.
Ce post va décortiquer ce modèle, mettre en lumière son hypothèse fondamentale, et montrer comment ses différentes variantes (Gaussienne, Bernoulli, etc.) s’adaptent à différents types de données.
2 Le Fondement : Le Théorème de Bayes
Rappelons-nous la règle de décision du classifieur de Bayes optimal : pour une nouvelle observation \(x\), on choisit la classe \(k\) qui maximise la probabilité a posteriori\(P(Y=k | X=x)\).
Le théorème de Bayes nous donne un moyen de calculer cette probabilité : \[\underbrace{P(Y=k | X=x)}_{\text{Postérieur}} = \dfrac{\overbrace{p(x | Y=k)}^{\text{Vraisemblance}} \times \overbrace{P(Y=k)}^{\text{A Priori}}}{\underbrace{p(x)}_{\text{Évidence}}}\]
Puisque le dénominateur \(p(x)\) est le même pour toutes les classes, la règle de décision se simplifie : \[\hat{y} = \underset{k \in \mathcal{Y}}{\operatorname{argmax}} \left( p(x | Y=k) \times P(Y=k) \right)\]
Le défi est de calculer la vraisemblance\(p(x | Y=k)\). Si nos données ont \(p\) variables explicatives \(X=(X_1, X_2, \dots, X_p)\), cela signifie que nous devons estimer la probabilité jointe de toutes ces variables, ce qui est extrêmement difficile. C’est là que la “naïveté” entre en jeu.
Pour rendre le calcul de la vraisemblance possible, le classifieur naïf bayésien fait une hypothèse très forte :
L’Hypothèse d’Indépendance Conditionnelle
Les variables explicatives (\(X_j\)) sont mutuellement indépendantes, conditionnellement à la classe (\(Y=k\)).
En d’autres termes, pour une classe donnée, la valeur d’une variable ne nous donne aucune information sur la valeur d’une autre variable.
Example 1 Si nous savons qu’un email est un spam (classe \(Y=k\)), la présence du mot “viagra” (\(X_1\)) est indépendante de la présence du mot “gratuit” (\(X_2\)).
Cette hypothèse est presque toujours fausse dans le monde réel (les mots “viagra” et “gratuit” sont probablement corrélés dans les spams !). Cependant, c’est cette simplification qui fait la force du modèle.
Grâce à cette hypothèse, la vraisemblance jointe devient un simple produit des vraisemblances individuelles : \[p(x | Y=k) = p(x_1, \dots, x_p | Y=k) = \prod_{j=1}^{p} p(x_j | Y=k)\] Le calcul devient alors trivial : il suffit d’estimer la distribution de chaque variable, pour chaque classe, de manière indépendante.
4 Les Différentes Saveurs de Naïf Bayésien
Le type de classifieur naïf bayésien que l’on utilise dépend de l’hypothèse que l’on fait sur la distribution de chaque \(p(x_j | Y=k)\).
Gaussian Naive Bayes : Utilisé lorsque les variables explicatives sont continues. On suppose que pour chaque classe \(k\), la distribution de chaque variable \(X_j\) suit une loi Normale (Gaussienne). Le modèle n’a qu’à estimer la moyenne et la variance de chaque variable pour chaque classe.
Multinomial Naive Bayes : Le champion de la classification de texte. Il est utilisé lorsque les variables représentent des comptes discrets (ex: le nombre d’occurrences de chaque mot dans un document). On suppose que les comptes de mots suivent une loi multinomiale.
Bernoulli Naive Bayes : Similaire au précédent, mais utilisé lorsque les variables sont binaires (0 ou 1), indiquant la présence ou l’absence d’une caractéristique (ex: “le mot ‘gagnant’ est-il présent dans l’email ?”). On suppose que chaque variable suit une loi de Bernoulli.
Autres : Il existe des variantes pour d’autres types de distributions, comme la loi de Poisson pour des données de comptage plus générales.
5 Atelier Pratique : Détecter les SMS Spams
La classification de texte est le domaine de prédilection du Naïf Bayésien. Nous allons construire un filtre anti-spam pour des SMS en utilisant le modèle Multinomial Naive Bayes.
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import Pipelinefrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplayimport matplotlib.pyplot as plt# 1. Charger les données# Le jeu de données est une collection de SMS étiquetés comme 'ham' (légitime) ou 'spam'.try:# Essayez de charger depuis une URL fiable df = pd.read_csv('https://raw.githubusercontent.com/justmarkham/pycon-2016-tutorial/master/data/sms.tsv', sep='\t', header=None, names=['label', 'message'])except:# Solution de secours si l'URL est inaccessibleprint("Impossible de charger depuis l'URL, utilisation de données locales simulées.") data = {'label': ['ham', 'spam', 'ham', 'ham', 'spam'], 'message': ['Go until jurong point, crazy..', 'Free entry in 2 a wkly comp', 'U dun say so early hor...', 'Nah I dont think he goes to usf', 'FreeMsg Hey there darling its been 3 weeks']} df = pd.DataFrame(data)# Convertir les étiquettes en format numériquedf['label_num'] = df['label'].map({'ham': 0, 'spam': 1})# 2. Définir les variables et la cibleX = df['message']y = df['label_num']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 3. Créer le Pipeline de Modélisation# Le pipeline va enchaîner deux étapes :# a) CountVectorizer : Transforme le texte en un vecteur de comptes de mots (Bag-of-Words).# b) MultinomialNB : Le classifieur naïf bayésien.text_clf_pipeline = Pipeline([ ('vect', CountVectorizer()), ('clf', MultinomialNB()),])# 4. Entraîner le modèleprint("--- Entraînement du Classifieur Naïf Bayésien ---")text_clf_pipeline.fit(X_train, y_train)print("Entraînement terminé.\n")# 5. Évaluation du modèley_pred = text_clf_pipeline.predict(X_test)print("--- Matrice de Confusion ---")cm = confusion_matrix(y_test, y_pred)disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Ham', 'Spam'])disp.plot(cmap=plt.cm.Blues)plt.show()print("\n--- Rapport de Classification ---")print(classification_report(y_test, y_pred, target_names=['Ham', 'Spam']))# 6. Tester avec de nouvelles phrasesprint("\n--- Test sur de nouvelles phrases ---")new_sms = ["Congratulations! You've won a $1,000 Walmart gift card. Go to [http://bit.ly/claim-yours](http://bit.ly/claim-yours) to claim now.","Hey, are we still on for dinner tonight at 8pm?","URGENT! Your mobile number has won a 2,000 bonus prize. Call 09061743811 to claim."]predictions = text_clf_pipeline.predict(new_sms)print(pd.DataFrame({'Message': new_sms, 'Prédiction': ['Spam'if p ==1else'Ham'for p in predictions]}))
--- Entraînement du Classifieur Naïf Bayésien ---
Entraînement terminé.
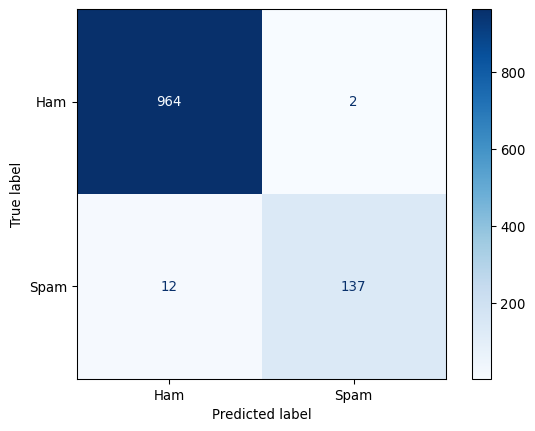
--- Matrice de Confusion ---
--- Rapport de Classification ---
precision recall f1-score support
Ham 0.99 1.00 0.99 966
Spam 0.99 0.92 0.95 149
accuracy 0.99 1115
macro avg 0.99 0.96 0.97 1115
weighted avg 0.99 0.99 0.99 1115
--- Test sur de nouvelles phrases ---
Message Prédiction
0 Congratulations! You've won a $1,000 Walmart g... Spam
1 Hey, are we still on for dinner tonight at 8pm? Ham
2 URGENT! Your mobile number has won a 2,000 bon... Spam
6 Conclusion
Le classifieur naïf bayésien est un exemple parfait de la puissance de la simplicité.
Avantages :
Extrêmement rapide à entraîner et à prédire.
Fonctionne très bien avec un grand nombre de variables (haute dimension), comme en classification de texte.
Nécessite relativement peu de données d’entraînement.
Fournit des probabilités directes.
Inconvénients :
Son hypothèse d’indépendance est sa principale faiblesse. Si les variables sont fortement corrélées, sa performance peut être limitée.
Il peut être sensible aux “mots” ou caractéristiques qu’il n’a jamais vus dans une classe (problème du zéro-fréquence, souvent géré par un lissage).
Malgré sa “naïveté”, il reste un excellent modèle de base (baseline) pour tout problème de classification, et un champion incontesté dans le domaine du traitement du langage naturel.
Et maintenant ?
Nous avons exploré une large gamme de classifieurs, chacun avec sa propre philosophie. Il est temps de mettre toutes ces connaissances en commun ! Dans notre dernier post de cette série, nous réaliserons un projet de synthèse où nous comparerons tous les modèles que nous avons appris sur un seul et même problème pour voir comment ils se comportent et comment choisir le meilleur en fonction du contexte.
7 Exercices
Exercise 1
Question 1 : Approche du Modèle
Quelle est l’approche fondamentale du classifieur Naïf Bayésien ?
Question 2 : L’Hypothèse ‘Naïve’
Quelle est l’hypothèse “naïve” qui donne son nom au classifieur Naïf Bayésien ?
Question 3 : Conséquence de l’Hypothèse
Quel est le principal avantage pratique de l’hypothèse d’indépendance conditionnelle ?
Question 4 : Gaussian Naive Bayes
Dans quel cas utiliseriez-vous un classifieur Gaussian Naive Bayes ?
Question 5 : Multinomial Naive Bayes
Quel est le cas d’usage par excellence du Multinomial Naive Bayes ?
Question 6 : Bernoulli Naive Bayes
Le Bernoulli Naive Bayes est le plus adapté lorsque les variables représentent :
Question 7 : Règle de Décision
Comment le classifieur Naïf Bayésien prend-il sa décision finale pour une nouvelle observation \(x\) ?
Question 8 : CountVectorizer
Dans l’atelier pratique sur les SMS, quel est le rôle de CountVectorizer ?
Question 9 : Avantages
Parmi les propositions suivantes, laquelle est un avantage majeur du Naïf Bayésien ?
Question 10 : Inconvénients
Quelle est une faiblesse connue du classifieur Naïf Bayésien ?
Question 11 : Modèle Génératif
Le Naïf Bayésien est un modèle “génératif”. Qu’est-ce que cela signifie ?
Question 12 : Cas Idéal
Que se passerait-il si l’hypothèse “naïve” d’indépendance conditionnelle était parfaitement vraie dans la réalité ?
Question 13 : Problème du Zéro-Fréquence
Qu’est-ce que le “problème du zéro-fréquence” dans le contexte du Multinomial Naive Bayes pour le texte ?
Question 14 : Lissage de Laplace
Comment le problème du zéro-fréquence est-il généralement résolu ?
Question 15 : Estimation de la Probabilité a Priori
Comment la probabilité a priori \(P(Y=k)\) est-elle généralement estimée à partir des données d’entraînement ?
Question 16 : Estimation de la Vraisemblance
Pour une caractéristique catégorielle couleur et une classe spam, comment la vraisemblance \(P(\text{couleur=Rouge} | Y=\text{spam})\) est-elle estimée ?
Question 17 : Performance sur le Texte
Pourquoi le Naïf Bayésien fonctionne-t-il souvent bien pour la classification de texte, même si l’hypothèse d’indépendance est fausse ?
Question 18 : Rôle du Pipeline
Dans l’atelier sur les SMS, quel est le principal avantage d’utiliser un Pipeline ?
Question 19 : Comparaison avec GDA
Le Naïf Bayésien et l’Analyse Discriminante Gaussienne (GDA) sont deux modèles génératifs. Quelle est une différence fondamentale ?
Question 20 : Règle de Décision MAP
La règle de décision du Naïf Bayésien consiste à choisir la classe \(k\) qui maximise la probabilité a posteriori \(P(Y=k | X=x)\). C’est équivalent à maximiser :