L’Analyse Discriminante Gaussienne : Modéliser pour Classifier
Une approche générative avec LDA et QDA
Machine Learning
Apprentissage Supervisé
Classification
Statistiques
Python
Author
Affiliation
Wilson Toussile
ENSPY & ESSFAR
1 Introduction : Une Nouvelle Façon de Penser la Classification
Jusqu’à présent, les classifieurs que nous avons étudiés (Régression Logistique, SVM) cherchent à apprendre directement une frontière de décision entre les classes. Ce sont des modèles discriminatifs.
Aujourd’hui, nous allons explorer une approche différente, plus statistique : l’Analyse Discriminante Gaussienne (GDA). C’est un modèle génératif. Au lieu de se demander “où se situe la frontière ?”, un modèle génératif se demande : “Comment les données de chaque classe ont-elles été générées ?”.
L’idée est de modéliser la distribution de probabilité de chaque classe séparément. Ensuite, pour classifier une nouvelle observation, on utilise le théorème de Bayes pour déterminer de quelle distribution elle a le plus de chances de provenir.
2 Modélisation et Estimation des Paramètres
L’hypothèse fondamentale de la GDA est que les données de chaque classe \(k\) sont générées par une distribution Normale (ou Gaussienne) multi-dimensionnelle. Le modèle est donc défini par les paramètres de ces distributions.
2.1 Les Paramètres du Modèle
Pour chaque classe \(Y\in \{1, \dots, K\}\), le modèle est caractérisé par :
La probabilité a priori\(P(Y=k) = \pi_k\) : la probabilité qu’une observation appartienne à la classe $, avant même de regarder ses caractéristiques.
La distribution conditionnelle\((X\mid Y=k) \sim \mathcal{N}(\mu_k, \Sigma_k)\) : la distribution des variables explicatives $ pour les observations de la classe $. Elle est définie par :
Un vecteur de moyenne\(\mu_k\), qui représente le centre de la classe \(k\).
Une matrice de covariance\(\Sigma_k\), qui décrit la dispersion et l’orientation des données de la classe \(k\).
La densité de probabilité (la vraisemblance) d’une observation $ pour la classe $ est donc : \[ p(x|Y=k; \mu_k, \Sigma_k) = \dfrac{1}{(2\pi)^{d/2} |\Sigma_k|^{1/2}} \exp\left(-\frac{1}{2} (x-\mu_k)^T \Sigma_k^{-1} (x-\mu_k)\right) \] où \(d\) est le nombre de variables (dimensions).
2.2 Estimation des Paramètres par Maximum de Vraisemblance (MLE)
L’algorithme “apprend” en estimant ces paramètres à partir du jeu de données d’entraînement. Les estimateurs du maximum de vraisemblance sont très intuitifs :
Probabilité a priori : \(\hat{\pi}_k = \frac{n_k}{n}\) (la proportion d’observations de la classe $).
Moyenne : \(\hat{\mu}_k = \frac{1}{n_k} \sum_{i: y_i=k} x_i\) (la moyenne empirique des observations de la classe $).
Covariance : \(\hat{\Sigma}_k = \frac{1}{n_k} \sum_{i: y_i=k} (x_i - \hat{\mu}_k)(x_i - \hat{\mu}_k)^T\) (la matrice de covariance empirique de la classe $).
2.3 Fonctions Discriminantes et Règle de Décision
Pour classifier une nouvelle observation \(, on utilise la règle de Bayes pour trouver la classe qui maximise la probabilité *a posteriori* (Y=k|X=x)\). Pour simplifier les calculs, on maximise son logarithme. On définit ainsi la fonction discriminante\(\delta_k(x)\):
\[ \delta_k(x) = \log(p(x|Y=k)) + \log(P(Y=k)) \]
En remplaçant par la densité gaussienne et les paramètres estimés, et en ignorant les termes constants qui sont les mêmes pour toutes les classes, on obtient : \[ \delta_k(x) = -\frac{1}{2} \log|\hat{\Sigma}_k| - \frac{1}{2} (x-\hat{\mu}_k)^T \hat{\Sigma}_k^{-1} (x-\hat{\mu}_k) + \log(\hat{\pi}_k) \]
La règle de classification est alors simplement de choisir la classe qui a le plus grand score : \[\hat{y} = \underset{k \in \{1, \dots, K\}}{\operatorname{argmax}} \ \delta_k(x)\]
3 Les Deux Saveurs de GDA : LDA vs. QDA
La différence cruciale entre les deux types d’analyse discriminante réside dans l’hypothèse que l’on fait sur les matrices de covariance \(\Sigma_k\).
3.1 Analyse Discriminante Linéaire (LDA - Linear Discriminant Analysis)
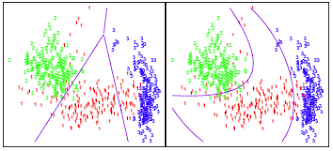
Hypothèse Forte : Toutes les classes partagent la même matrice de covariance (\(\Sigma_k = \Sigma\) pour tout \(k\)). On suppose que toutes les “cloches” ont la même forme et la même orientation, seul leur centre (\(\mu_k\)) change.
Conséquence : La frontière de décision entre deux classes est toujours une ligne droite (ou un hyperplan). C’est un classifieur linéaire.
Quand l’utiliser ? Quand on a peu de données (estimer une seule matrice de covariance est plus facile) ou quand on a des raisons de croire que la dispersion des classes est similaire. C’est un modèle avec un biais plus élevé mais une variance plus faible (moins de risque de surapprentissage).
Hypothèse Faible : Chaque classe a sa propre matrice de covariance\(\Sigma_k\). Chaque “cloche” peut avoir une forme et une orientation différentes.
Conséquence : La frontière de décision est quadratique (une parabole, une ellipse, une hyperbole). C’est un classifieur beaucoup plus flexible.
Quand l’utiliser ? Quand on a suffisamment de données pour estimer chaque matrice de covariance de manière fiable et qu’on pense que les classes ont des formes différentes. C’est un modèle avec un biais plus faible mais une variance plus élevée.
4 Atelier Pratique : LDA vs. QDA sur les Vins
Utilisons le jeu de données wine pour classifier des vins en trois cépages différents à partir de leurs caractéristiques chimiques.
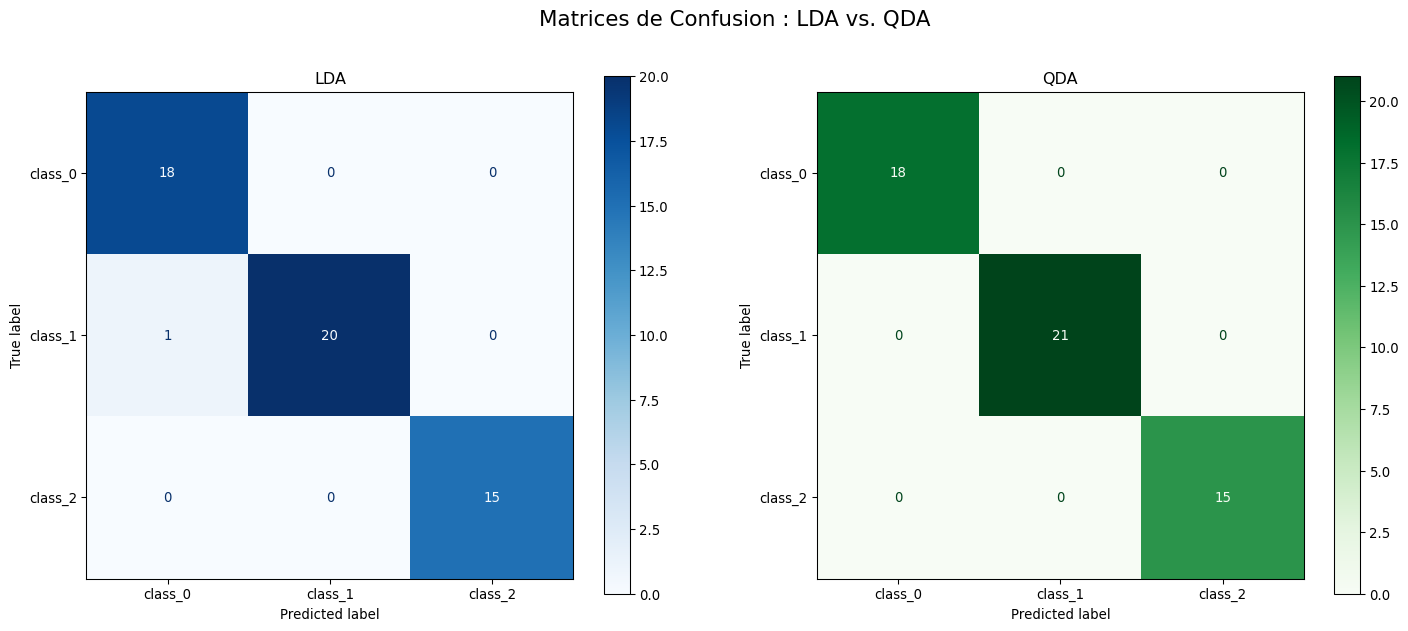
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysisfrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay# 1. Charger les donnéeswine = load_wine()X, y = wine.data, wine.targettarget_names = wine.target_names# 2. Diviser les données et les mettre à l'échelleX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 3. Entraîner et évaluer le modèle LDAprint("--- Analyse Discriminante Linéaire (LDA) ---")lda = LinearDiscriminantAnalysis()lda.fit(X_train_scaled, y_train)y_pred_lda = lda.predict(X_test_scaled)print("Rapport de Classification pour LDA:")print(classification_report(y_test, y_pred_lda, target_names=target_names))# 4. Entraîner et évaluer le modèle QDAprint("\n--- Analyse Discriminante Quadratique (QDA) ---")qda = QuadraticDiscriminantAnalysis()qda.fit(X_train_scaled, y_train)y_pred_qda = qda.predict(X_test_scaled)print("Rapport de Classification pour QDA:")print(classification_report(y_test, y_pred_qda, target_names=target_names))# 5. Visualisation des matrices de confusionfig, axes = plt.subplots(1, 2, figsize=(18, 7))fig.suptitle("Matrices de Confusion : LDA vs. QDA", fontsize=16)cm_lda = confusion_matrix(y_test, y_pred_lda)disp_lda = ConfusionMatrixDisplay(confusion_matrix=cm_lda, display_labels=target_names)disp_lda.plot(ax=axes[0], cmap=plt.cm.Blues)axes[0].set_title("LDA")cm_qda = confusion_matrix(y_test, y_pred_qda)disp_qda = ConfusionMatrixDisplay(confusion_matrix=cm_qda, display_labels=target_names)disp_qda.plot(ax=axes[1], cmap=plt.cm.Greens)axes[1].set_title("QDA")plt.show()
Dans cet exemple, les deux modèles obtiennent des performances quasi parfaites. Le QDA fait une erreur de moins que le LDA, ce qui suggère que sa plus grande flexibilité a pu capturer une subtilité dans la forme des classes. Cependant, sur un jeu de données plus bruité ou avec moins d’observations, le LDA pourrait s’avérer plus robuste.
5 Conclusion
L’Analyse Discriminante Gaussienne est un outil puissant qui offre une perspective différente sur la classification.
Elle est générative, ce qui signifie qu’elle modélise la distribution de chaque classe.
LDA est un classifieur linéaire, simple et robuste, idéal quand les données sont peu nombreuses.
QDA est un classifieur quadratique, plus flexible et puissant, mais qui nécessite plus de données.
Leur principale faiblesse est leur hypothèse de normalité. Si vos données sont très loin d’être gaussiennes, d’autres modèles comme les SVM ou les Forêts Aléatoires seront probablement plus performants.
Et maintenant ?
Nous avons maintenant exploré une large gamme de classifieurs, des modèles discriminatifs aux modèles génératifs. Il est temps de voir comment la combinaison de plusieurs modèles peut nous amener à un niveau de performance encore supérieur. Dans notre prochain article, nous plongerons dans le monde des méthodes ensemblistes et des célèbres Forêts Aléatoires.
6 Exercices
Exercise 1
Question 1 : Approche du Modèle GDA
Quelle est l’approche fondamentale d’un modèle génératif comme l’Analyse Discriminante Gaussienne (GDA) ?
Question 2 : Hypothèse Fondamentale
Quelle est l’hypothèse principale de l’Analyse Discriminante Gaussienne sur les données ?
Question 3 : Différence entre LDA et QDA
Quelle est la différence essentielle entre l’Analyse Discriminante Linéaire (LDA) et l’Analyse Discriminante Quadratique (QDA) ?
Question 4 : Forme de la Frontière de Décision
En raison de son hypothèse sur la covariance, quelle est la forme de la frontière de décision créée par un modèle LDA ?
Question 5 : Estimation des Paramètres
Comment les paramètres du modèle GDA (moyennes, covariances, probabilités a priori) sont-ils estimés à partir des données d’entraînement ?
Question 6 : Règle de Classification
Comment un modèle GDA entraîné classifie-t-il une nouvelle observation \(x\) ?
Question 7 : Biais et Variance
En termes de compromis biais-variance, comment se positionne LDA par rapport à QDA ?
Question 8 : Choix du Modèle
Dans quel scénario est-il souvent préférable d’utiliser LDA plutôt que QDA ?
Question 9 : Flexibilité de QDA
La capacité de QDA à créer des frontières de décision quadratiques provient de son hypothèse selon laquelle :
Question 10 : Estimateur de la Moyenne
L’estimateur du maximum de vraisemblance pour le vecteur de moyenne d’une classe \(k\), noté \(\hat{\mu}_k\), est simplement :
Question 11 : Avantages des Modèles Génératifs
Quel est un avantage potentiel des modèles génératifs (comme GDA) par rapport aux modèles discriminatifs (comme la régression logistique) ?
Question 12 : Impact de l’Hypothèse de Normalité
Que se passe-t-il si l’hypothèse de normalité des données n’est pas respectée pour un modèle GDA ?
Question 13 : Nombre de Paramètres
Comparé à LDA, QDA estime un plus grand nombre de paramètres. Qu’est-ce que cela implique ?
Question 14 : Probabilité a priori
Dans le contexte de GDA, que représente la probabilité a priori \(\pi_k = P(Y=k)\) ?
Question 15 : Matrice de Covariance
La matrice de covariance \(\Sigma_k\) pour une classe \(k\) décrit :
Question 16 : Scalabilité
Comment se comporte GDA en termes de scalabilité avec un grand nombre de caractéristiques (dimensions) ?
Question 17 : Utilisation en Réduction de Dimensionnalité
En dehors de la classification, LDA est également souvent utilisé pour :
Question 18 : Sensibilité aux Outliers
Les modèles GDA sont-ils sensibles aux valeurs aberrantes (outliers) ?
Question 19 : Comparaison avec Régression Logistique
Quelle est une différence clé entre la régression logistique et LDA/QDA en termes d’approche ?
Question 20 : Cas d’Égalité de Covariance
Si les matrices de covariance de toutes les classes sont identiques, quel modèle est théoriquement le plus approprié ?