1 Introduction : Le Pont entre Régression et Classification
Après avoir posé les bases de la classification, il est temps de construire notre premier modèle. Et quoi de mieux pour commencer que le prolongement naturel de la régression linéaire ? La régression logistique.
Ne vous laissez pas tromper par son nom : malgré le mot “régression”, c’est un algorithme de classification. C’est le modèle de référence pour tout problème de classification binaire, grâce à sa simplicité, son interprétabilité et son efficacité.
L’objectif de la régression logistique n’est pas de prédire une valeur numérique, mais de modéliser la probabilité qu’une observation appartienne à une classe particulière (généralement la classe “1” ou “positive”).
2 Le Problème : Pourquoi ne pas utiliser la Régression Linéaire ?
Une première idée pour un problème de classification binaire (avec des étiquettes 0 et 1) pourrait être d’utiliser une régression linéaire standard. C’est une très mauvaise idée pour deux raisons principales :
Des Prédictions Incohérentes : Une droite de régression peut produire des prédictions en dehors de l’intervalle [0, 1]. Que signifierait une probabilité de 1.3 (130%) ou de -0.2 (-20%) ? C’est absurde.
Violation des Hypothèses : Le modèle linéaire suppose que les erreurs suivent une loi normale, ce qui n’est pas du tout le cas pour une variable qui ne peut prendre que deux valeurs.
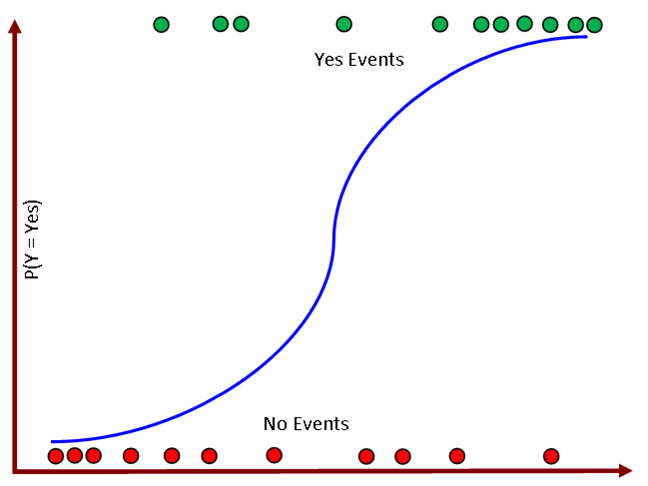
Il nous faut donc une fonction qui “écrase” la sortie de l’équation linéaire pour la contraindre à rester entre 0 et 1.
3 La Solution : La Fonction Sigmoïde
La régression logistique résout ce problème en utilisant une fonction de transformation appelée fonction logistique ou sigmoïde, notée \(\sigma\).
Cette fonction a la forme d’un “S” et transforme n’importe quel nombre réel en une valeur comprise entre 0 et 1. \[ \sigma(z) = \dfrac{1}{1 + e^{-z}} = \dfrac{e^z}{1+e^z} \] Le modèle de régression logistique modélise donc la probabilité de la classe positive, \(P(Y=1|X)\), de la manière suivante :
On calcule un score linéaire, comme en régression linéaire : \(z = \beta_0 + \beta_1 X_1 + \dots + \beta_p X_p\).
On passe ce score à travers la fonction sigmoïde pour obtenir une probabilité : \[P(Y=1|X=x) = \sigma(z) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_1 + \dots+x_p)}}=\dfrac{e^{\beta_0+\beta_1x_1+\dots+\beta_px_p}}{1+e^{\beta_0+\beta_1x_1+\dots+\beta_px_p}}\]
4 Interpréter les Coefficients : Le Monde des “Odds Ratios”
L’interprétation des coefficients \(\beta\) est moins directe qu’en régression linéaire. Ils n’agissent pas directement sur la probabilité, mais sur une transformation de celle-ci : le log-odds.
En inversant la fonction sigmoïde, on obtient le logit : \[\text{logit}(p) = \ln\left(\dfrac{p}{1-p}\right) = \beta_0 + \beta_1 x_1 + \dots\] Le terme \(\dfrac{p}{1-p}\) est appelé la cote (odds).
Un coefficient \(\beta_j\) représente le changement du log-odds pour une augmentation d’une unité de \(x_j\). Ce n’est pas très intuitif.
Pour une interprétation plus parlante, on calcule l’odds ratio en prenant l’exponentielle du coefficient : \(e^{\beta_j}\).
Interprétation de l’Odds Ratio
Un odds ratio \(e^{\beta_j} = 1.5\) signifie qu’une augmentation d’une unité de la variable \(x_j\)multiplie la cote de l’événement par 1.5 (soit une augmentation de \(50\%\) de la cote), toutes choses égales par ailleurs.
5 Atelier Pratique : Prédire la Survie sur le Titanic
Utilisons le jeu de données classique du Titanic pour construire un modèle qui prédit si un passager a survécu (survived).
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler, OneHotEncoderfrom sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinefrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import classification_report, confusion_matrix, roc_auc_score, RocCurveDisplay# 1. Charger et préparer les donnéestitanic = sns.load_dataset('titanic')# Définir les variables et la cibleX = titanic.drop('survived', axis=1)y = titanic['survived']# Gérer les valeurs manquantes de manière simple pour cet exemple# Pour l'âge, on remplace par la médianeX['age'].fillna(X['age'].median(), inplace=True)# Pour 'embarked' et 'deck', on les retire car plus complexes à gérerX.drop(['embarked', 'deck', 'embark_town', 'alive'], axis=1, inplace=True)# 2. Définir le pré-traitement# On sépare les colonnes numériques et catégoriellesnumeric_features = ['pclass', 'age', 'sibsp', 'parch', 'fare']categorical_features = ['sex', 'who', 'adult_male', 'alone']# Créer un pipeline de pré-traitement# Les variables numériques seront mises à l'échelle# Les variables catégorielles seront transformées en variables muettes (dummy)preprocessor = ColumnTransformer( transformers=[ ('num', StandardScaler(), numeric_features), ('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features) ])# 3. Diviser les donnéesX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 4. Créer et entraîner le modèle via un Pipeline# Le pipeline enchaîne le pré-traitement et le modèle, ce qui est une bonne pratiquelog_reg_pipeline = Pipeline(steps=[('preprocessor', preprocessor), ('classifier', LogisticRegression(random_state=42))])log_reg_pipeline.fit(X_train, y_train)print("Modèle de Régression Logistique entraîné.\n")# 5. Évaluation du modèley_pred = log_reg_pipeline.predict(X_test)print("--- Matrice de Confusion ---")cm = confusion_matrix(y_test, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.ylabel('Vraie étiquette')plt.xlabel('Étiquette prédite')plt.show()print("\n--- Rapport de Classification ---")print(classification_report(y_test, y_pred))# Calcul et affichage de l'AUCy_pred_proba = log_reg_pipeline.predict_proba(X_test)[:, 1]auc_score = roc_auc_score(y_test, y_pred_proba)print(f"\nScore AUC: {auc_score:.4f}")RocCurveDisplay.from_estimator(log_reg_pipeline, X_test, y_test)plt.title('Courbe ROC')plt.show()
/tmp/ipykernel_55009/2570304811.py:21: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
Modèle de Régression Logistique entraîné.
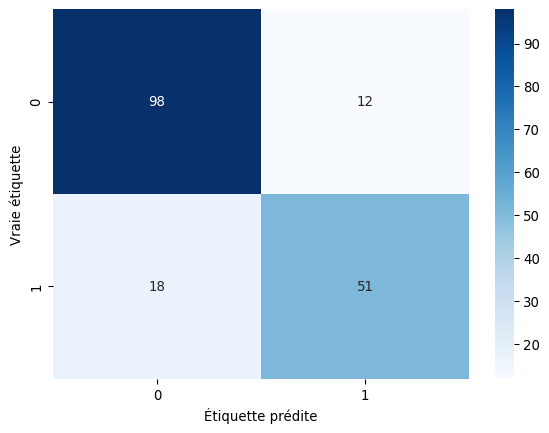
--- Matrice de Confusion ---
Matrice de Confusion : Elle nous montre exactement où le modèle se trompe (les faux positifs et faux négatifs).
Rapport de Classification : Il nous donne la précision, le rappel et le score F1 pour chaque classe. On peut voir que le modèle est raisonnablement performant, avec un score F1 équilibré.
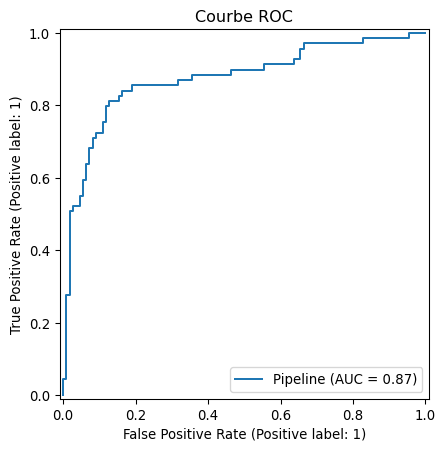
Score AUC : Un score de 0.86 est très bon, indiquant que le modèle a une excellente capacité à distinguer les passagers qui ont survécu de ceux qui n’ont pas survécu.
6 Conclusion
La régression logistique est un outil fondamental, rapide, et étonnamment puissant. Elle sert de modèle de référence (baseline) dans presque tous les projets de classification. Sa force réside dans son interprétabilité : on peut non seulement prédire une classe, mais aussi comprendre l’influence de chaque variable sur la probabilité de cette classe.
Et maintenant ?
La régression logistique, comme la régression linéaire, trace une frontière de décision linéaire entre les classes. Mais que faire si les données ne sont pas séparables par une simple ligne ? Dans notre prochain article, nous explorerons une approche complètement différente et non-paramétrique : la classification par k-plus proches voisins (k-NN).