
1 Qu’est-ce que le Machine Learning ?
Après avoir passé du temps à utiliser les statistiques pour expliquer et comprendre des phénomènes passés, nous allons maintenant changer d’objectif. Le Machine Learning (ML), ou apprentissage automatique, se concentre sur un but différent : prédire l’avenir ou prendre des décisions en se basant sur des données.
Le Machine Learning est un sous-domaine de l’intelligence artificielle qui donne aux ordinateurs la capacité d’apprendre à partir de données sans être explicitement programmés.
Au lieu d’écrire des règles fixes (ex: SI l'email contient "gagnant" ET "loterie" ALORS c'est un spam), on fournit à un algorithme des milliers d’exemples d’emails déjà classés comme “spam” ou “non spam”, et on le laisse découvrir lui-même les règles et les motifs.
2 Lien avec d’Autres Disciplines
Le ML n’est pas né de rien. Il se situe au carrefour de plusieurs domaines que vous connaissez :
- Statistiques : C’est le socle théorique du ML. Des concepts comme la probabilité, les distributions, les tests d’hypothèses et la régression sont fondamentaux. La grande différence est l’objectif : les statistiques cherchent souvent à inférer et expliquer, tandis que le ML cherche à prédire avec la meilleure précision possible.
- Intelligence Artificielle (IA) : L’IA est le domaine plus large qui vise à créer des machines capables de simuler l’intelligence humaine. Le ML est la technique la plus courante et la plus efficace pour atteindre cet objectif aujourd’hui.
- Data Mining : Très proche du ML, le Data Mining se concentre sur la découverte de motifs inconnus dans de grands ensembles de données (knowledge discovery). Le ML utilise souvent ces mêmes motifs pour construire des modèles prédictifs.
3 Typologie des Modèles de Machine Learning
Tous les problèmes de ML ne sont pas les mêmes. La manière dont un algorithme apprend dépend crucialement du type de données dont on dispose. On distingue principalement deux grandes familles.
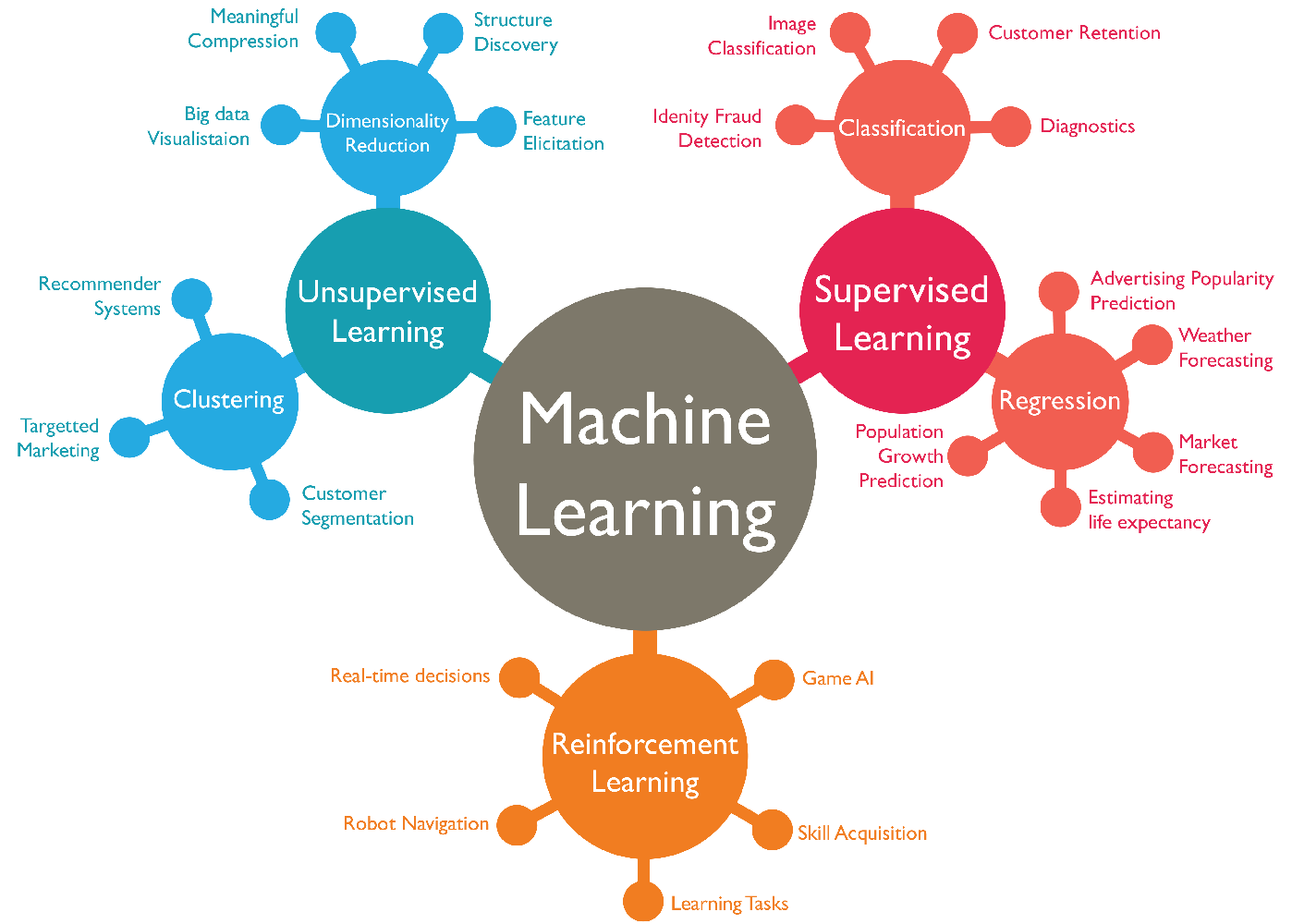
3.1 Apprentissage Supervisé (Supervised Learning)
C’est le cas le plus courant. L’analogie est celle d’un élève qui apprend avec un professeur. On fournit à l’algorithme des données étiquetées (ou “labellisées”), c’est-à-dire que pour chaque exemple, on connaît déjà la réponse correcte.
Le but est d’apprendre une fonction qui associe une entrée X à une sortie y.
L’apprentissage supervisé se divise en deux catégories :
Régression : Quand la sortie
yque l’on veut prédire est une valeur continue.- Exemples : Prédire le prix d’une maison, le chiffre d’affaires du mois prochain, la température de demain.
Classification : Quand la sortie
yest une catégorie (une étiquette).- Exemples : Prédire si un email est un spam ou non (2 classes), si une image contient un chat, un chien ou un oiseau (3 classes), si un client va résilier son abonnement (oui/non).
3.2 Apprentissage Non Supervisé (Unsupervised Learning)
Ici, il n’y a pas de professeur. On fournit à l’algorithme des données non étiquetées, et son but est de découvrir lui-même la structure cachée ou les motifs dans ces données.
- Clustering (ou partitionnement) : Regrouper les données en “clusters” ou “grappes” homogènes.
- Exemples : Segmenter des clients en différents groupes marketing, regrouper des articles de presse par sujet.
- Réduction de Dimension : Simplifier les données en réduisant le nombre de variables, tout en conservant le maximum d’information.
- Exemples : Visualiser des données très complexes en 2D ou 3D, compresser des données.
3.3 Apprentissage par Renforcement (Reinforcement Learning)
Ici, l’approche est différente. On ne donne ni étiquettes, ni structure à découvrir. On place un agent (un programme) dans un environnement où il peut effectuer des actions.
- Pour chaque action, l’agent reçoit une récompense (positive) ou une punition (négative).
- L’objectif de l’agent est d’apprendre par essais et erreurs la meilleure stratégie (la “politique”) pour maximiser ses récompenses sur le long terme.
C’est le paradigme utilisé pour entraîner des IA à jouer à des jeux (échecs, Go) ou à piloter des robots.
3.4 Autres Types d’Apprentissage
Le monde du ML est en constante évolution. Voici d’autres paradigmes importants :
Semi-supervisé : Un mélange des deux mondes, utilisé quand on a beaucoup de données mais peu d’étiquettes (car l’étiquetage coûte cher).
Auto-supervisé (Self-supervised) : Une approche très moderne et puissante, notamment pour les modèles de langage comme GPT. L’algorithme crée lui-même ses propres étiquettes à partir des données brutes. Par exemple, en prenant une phrase, il masque un mot et essaie de le deviner. Les données non étiquetées deviennent ainsi une source inépuisable d’apprentissage.
4 Le Cycle de Vie d’un Projet de Machine Learning
Un projet de ML n’est pas juste l’application d’un algorithme. C’est un processus itératif et structuré.
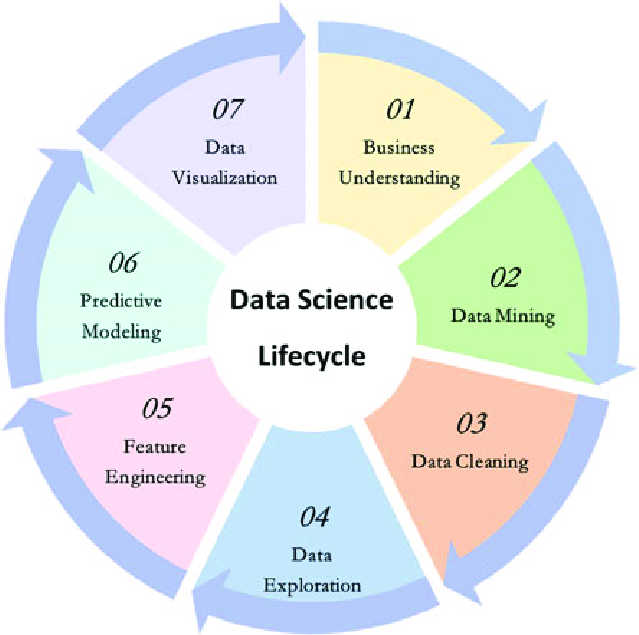
Chaque étape est cruciale et itérative :
4.1 1. Compréhension du Problème (Business Understanding)
C’est l’étape la plus importante. Avant d’écrire une seule ligne de code, il faut définir clairement l’objectif métier. Quel problème cherchons-nous à résoudre ? Comment le modèle sera-t-il utilisé pour créer de la valeur ? Cette phase implique des discussions avec les parties prenantes pour définir le périmètre et les métriques de succès.
4.2 2. Collecte et Préparation des Données
Une fois le problème défini, nous avons besoin de données. Celles-ci peuvent provenir de bases de données (SQL), d’API, de fichiers (CSV) ou du web. Cette étape est souvent la plus chronophage (le fameux “80% du travail”) et inclut :
- Nettoyage : Gérer les valeurs manquantes, corriger les erreurs, supprimer les doublons.
- Feature Engineering : Créer de nouvelles variables pertinentes à partir des données existantes.
- Transformation : Encoder les variables catégorielles, mettre à l’échelle les variables numériques.
4.3 3. Analyse Exploratoire des Données (EDA)
Les données sont propres, il faut maintenant les comprendre. L’EDA consiste à utiliser des statistiques et des visualisations pour résumer les caractéristiques principales des données, découvrir des motifs, repérer des anomalies et tester des hypothèses initiales.
4.4 4. Modélisation (Modeling)
C’est ici que l’apprentissage a lieu.
- Sélection de l’algorithme : En fonction du problème (régression, classification), on choisit un ou plusieurs algorithmes candidats (ex: Régression Linéaire, Forêt Aléatoire).
- Division des données : On sépare les données en un jeu d’entraînement (training set) et un jeu de test (testing set) pour évaluer la performance du modèle sur des données qu’il n’a jamais vues.
- Entraînement : On “entraîne” le modèle sur les données d’entraînement pour qu’il apprenne les motifs.
4.5 5. Évaluation (Evaluation)
Le modèle est-il performant ? On utilise le jeu de test pour mesurer sa performance avec des métriques appropriées (ex: exactitude, précision, R²). Si le résultat n’est pas satisfaisant, on retourne aux étapes précédentes (plus de données, de meilleures features, un autre modèle).
4.6 6. Déploiement (Deployment)
Un modèle n’est utile que s’il est utilisé. Le déploiement consiste à intégrer le modèle dans un système de production (via une API, une application web, etc.) pour qu’il puisse faire des prédictions sur de nouvelles données.
4.7 7. Suivi et Maintenance (Monitoring & Maintenance)
Le monde change, et les données aussi. La performance d’un modèle peut se dégrader avec le temps (“model drift”). Il est essentiel de surveiller ses prédictions en production et de le ré-entraîner périodiquement avec de nouvelles données.
5 Outils et Bibliothèques Essentiels en Python
Pour mettre tout cela en pratique, l’écosystème Python offre une suite d’outils exceptionnels :
- Pandas : Indispensable pour la manipulation et le nettoyage des données sous forme de DataFrames.
- NumPy : La base pour tous les calculs numériques et matriciels.
- Matplotlib & Seaborn : Essentiels pour la visualisation des données, une étape clé de l’exploration et de la communication des résultats.
- Scikit-learn : LA bibliothèque de référence pour le Machine Learning “classique”. Elle offre une collection impressionnante d’algorithmes de pré-traitement, de modélisation et d’évaluation, avec une interface très cohérente (
.fit(),.predict()).
Pour le Deep Learning, les frameworks les plus populaires sont TensorFlow (développé par Google) et PyTorch (développé par Meta/Facebook).
6 Conclusion
Vous avez maintenant une vue d’ensemble du monde du Machine Learning. Vous comprenez sa philosophie, les différents types de problèmes que l’on peut résoudre, le processus à suivre et les outils à utiliser. Le ML est un domaine vaste et passionnant, mais qui repose sur des principes logiques et une méthodologie structurée.
7 Exercices
Exercise 1
Quelle est la définition principale du Machine Learning ?
Un modèle qui prédit le prix d’un appartement en fonction de sa surface est un exemple de :
Quelle est la caractéristique principale de l’apprentissage supervisé ?
Segmenter les clients d’un supermarché en groupes homogènes en fonction de leurs habitudes d’achat est une tâche de :
Quelle est l’étape la plus cruciale et initiale du cycle de vie d’un projet de Machine Learning ?
Pourquoi divise-t-on les données en un jeu d’entraînement et un jeu de test ?
L’apprentissage par renforcement est le plus adapté pour :
Quelle bibliothèque Python est considérée comme LA référence pour les algorithmes de Machine Learning classiques (régression, classification, clustering…) ?
L’étape de “Feature Engineering” fait partie de quelle phase du cycle de vie ?
Détecter si une transaction par carte de crédit est frauduleuse ou non est un problème de :